网络爬虫第三次作业——多线程、scrapy框架
作业①:
1)单/多线程爬取网站图片实验
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网http://www.weather.com.cn。分别使用单线程和多线程的方式爬取。
以下按自己的编码风格复现书本代码
- 单线程
程序主要思路:
A(获取指定网页字符内容) -->B(从中筛选出所有图像url)
B --> C(逐一对图像url进行预处理:拼接,去重)
C --> D(逐一下载相应的图片到本地images子文件中)
D --> E(将下载的Url信息在控制台输出)
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request # 可换用requests
import os
import time
import warnings
warnings.filterwarnings("ignore") # 在控制台屏蔽警告
class ThreadSpiderImages(object):
'''单线程爬取指定网站图片类'''
def __init__(self,start_url):
'''共同属性是UA头以及url'''
self.url = start_url
self.headers = {
"User-Agent": "Mozilla/5.0"
}
def get_html_text(self):
'''获取指定url的网页字符串'''
req = urllib.request.Request(self.url, headers=self.headers)
html = urllib.request.urlopen(req)
html_text = html.read()
dammit = UnicodeDammit(html_text, ["utf-8","gbk"]) # 猜测文档编码
html_text = dammit.unicode_markup
return html_text
def extract_imageurls(self,images):
'''
从解析出的bs4ResultSet对象中提取图像url信息,
返回图像urls
'''
urls = []
for image in images:
try:
src = image["src"] # 图像文件的src地址
url = urllib.request.urljoin(self.url, src) # 构建完整url
if url not in urls: # url去重
urls.append(url)
print(url)
except Exception as err:
print(err)
return urls
def download(self,urls):
'''下载urls中每个url对应的图像'''
count = 0
dirname = "images"
current_path = os.getcwd()
if not os.path.exists(dirname): # 如果文件夹不存在则创建
os.makedirs(dirname)
print("{}文件夹创建在{}".format(dirname, current_path))
try:
for url in urls:
pos = url[::-1].index(".") + 1 # 找到最后一个.在第几个位置(注意下标从0开始)
ext = url[-pos:] # 后缀名
# 将下载的图像文件存入当前文件夹下的images文件夹
filename = str(count) + ext
filepath = dirname + "\\" + filename
try:
urllib.request.urlretrieve(url, filepath)
except:
default_ext = '.jpg' # 将异常图片格式转化为默认格式.jpg
print("将{}图片格式转化为{}图片格式存储".format(ext,default_ext))
filename = str(count) + default_ext
filepath = dirname + "\\" + filename
urllib.request.urlretrieve(url, filepath)
print("download "+filename)
count += 1
except Exception as err:
print(err)
if __name__ == "__main__":
start = time.clock()
start_url = "http://www.weather.com.cn/weather/101280601.shtml" # 指定网站
spider = ThreadSpiderImages(start_url)
try:
html_text = spider.get_html_text()
soup = BeautifulSoup(html_text, "html.parser")
images = soup.select("img") # 选择图像文件
urls = spider.extract_imageurls(images)
spider.download(urls)
except Exception as err:
print(err)
end = time.clock()
print('Running time: %s Seconds' % (end - start))
运行结果部分截图:

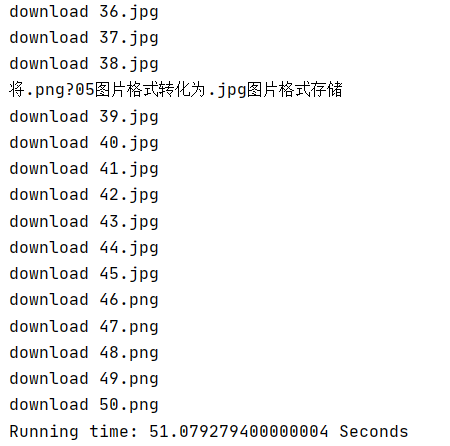
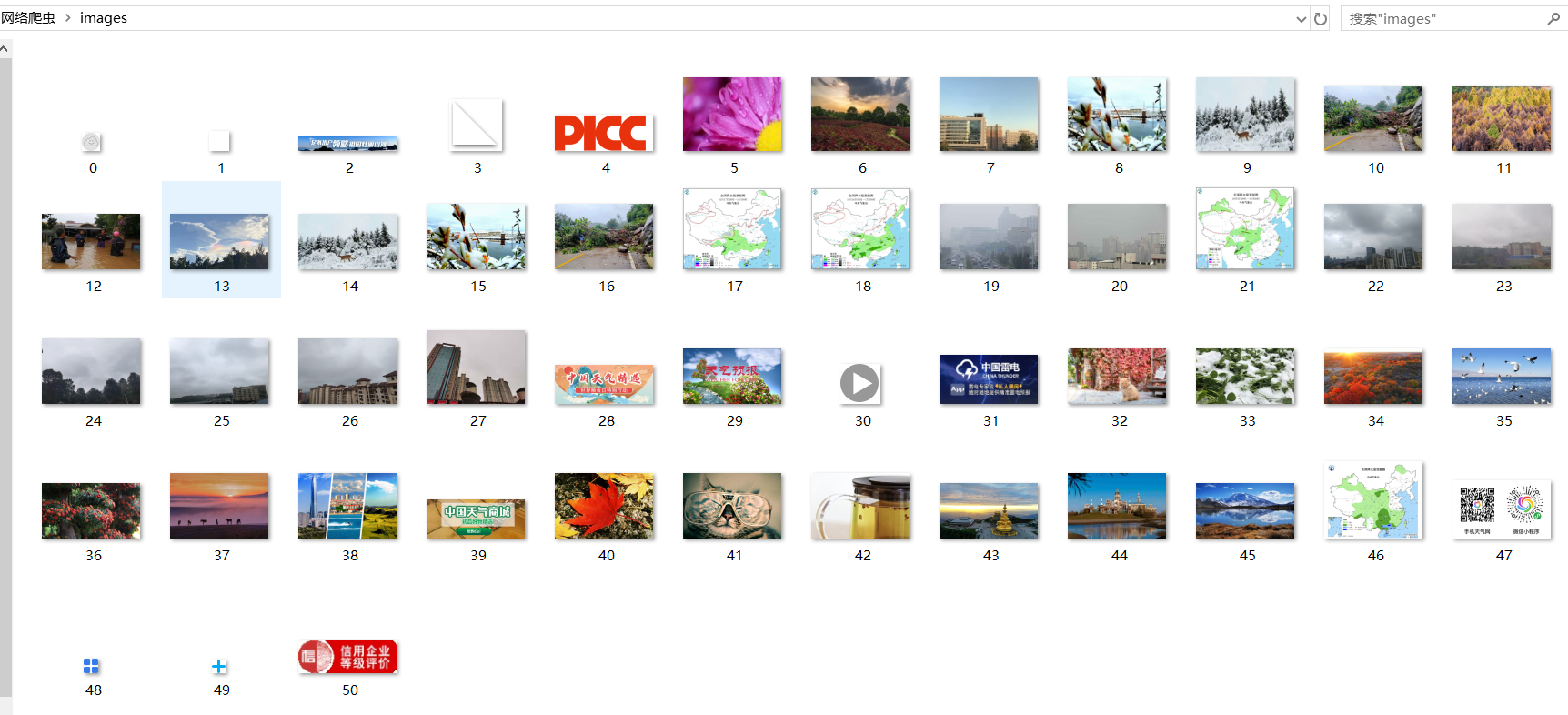
- 多线程
程序主要思路基本上同单线程,差别仅在于多线程中为每一个图像url创建线程对象,逐一以download函数为目标启动线程
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request # 可换用requests
import os
import threading
import time
import warnings
warnings.filterwarnings("ignore")
class ThreadsSpiderImages(object):
'''多线程爬取指定网站图片类'''
def __init__(self,start_url):
'''共同属性是UA头以及url'''
self.url = start_url
self.headers = {
"User-Agent": "Mozilla/5.0"
}
def get_html_text(self):
'''获取指定url的网页字符串'''
req = urllib.request.Request(self.url, headers=self.headers)
html = urllib.request.urlopen(req)
html_text = html.read()
dammit = UnicodeDammit(html_text, ["utf-8","gbk"]) # 猜测文档编码
html_text = dammit.unicode_markup
return html_text
def extract_imageurls(self,images):
'''
从解析出的bs4ResultSet对象中提取图像url信息,
返回图像urls
'''
urls = []
for image in images:
try:
src = image["src"] # 图像文件的src地址
url = urllib.request.urljoin(self.url, src) # 构建完整url
if url not in urls: # url去重
urls.append(url)
print(url)
except Exception as err:
print(err)
return urls
def threads_download(self,urls):
'''根据图像urls启用多线程download'''
global count
try:
for url in urls:
count += 1 # 确保count不重,唯一的count操作
T = threading.Thread(target=self.download,args=(url,)) # 逐一(每个url)创建线程对象
T.setDaemon(False) # True则为守护线程,若设置守护线程,一旦主线程执行完毕,子线程都得结束
T.start() # 逐一启动线程
threads.append(T)
except Exception as err:
print(err)
def download(self,url):
'''下载指定url对应的图像'''
dirname = "images"
if not os.path.exists(dirname): # 如果文件夹不存在则创建
os.makedirs(dirname)
current_path = os.getcwd()
print("{}文件夹创建在{}".format(dirname, current_path))
try:
pos = url[::-1].index(".") + 1 # 找到最后一个.在第几个位置(注意下标从0开始)
ext = url[-pos:] # 后缀名
# 将下载的图像文件存入当前文件夹下的images文件夹
filename = str(count) + ext
filepath = dirname + "\\" + filename
try:
urllib.request.urlretrieve(url, filepath)
except:
default_ext = '.jpg'
print("将{}图片格式转化为{}图片格式存储".format(ext,default_ext))
filename = str(count) + default_ext
filepath = dirname + "\\" + filename
urllib.request.urlretrieve(url, filepath)
print("download "+filename)
except Exception as err:
print(err)
if __name__ == "__main__":
start = time.clock()
start_url = "http://www.weather.com.cn/weather/101280601.shtml" # 指定网站
spider = ThreadsSpiderImages(start_url)
count = 0
threads = []
try:
html_text = spider.get_html_text()
soup = BeautifulSoup(html_text, "html.parser")
images = soup.select("img") # 选择图像文件
urls = spider.extract_imageurls(images)
spider.threads_download(urls)
for t in threads: # 主线程中等待所有子线程退出
t.join()
except Exception as err:
print(err)
end = time.clock()
print('Running time: %s Seconds' % (end - start))
运行结果:
基本与单线程运行结果一致,特殊之处在于运行时间“Running time”的大幅缩短以及由于多线程并发的不确定性导致下载的图片编号乱序
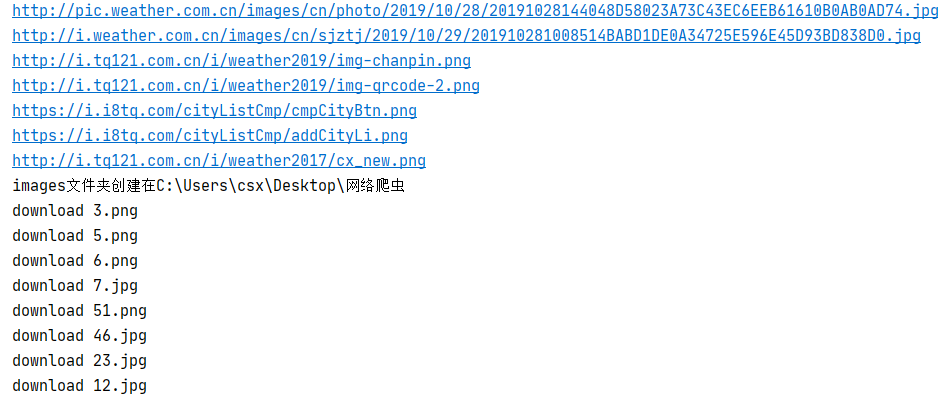
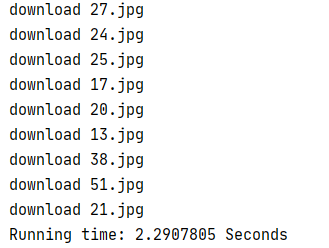
2)心得体会:
这次实验关键在于多线程在IO密集型任务方面的应用。与单线程执行下载任务对比,可以体会到多线程爬取程序由于可以有多个文件在同时下载,互不干扰,效率和可靠性都明显比单线程爬取程序高。具体实现时主要使用threading模块。
作业②:
1)scrapy框架复现实现
要求:使用scrapy框架复现作业①。
框架复现主要思路:
A(在items模块确定要获取的数据项目item) -->B(在spider模块确定入口函数start_requests和回调/解析函数parse)
B --> C(在pipelines模块编写数据管道处理类处理item)
C --> D(设置配置文件settings.py)
D --> E(使用scrpy中专门的命令scrapy crawl执行爬虫程序)
代码:
- items.py(数据项目类)
import scrapy
class ImageItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
pass
- SpiderImage.py(spiders文件夹下的爬虫程序)
import scrapy
from scrapy.selector import Selector
import warnings
warnings.filterwarnings("ignore")
import sys
sys.path.append("..") # 为导入上级目录中的模块
from items import ImageItem # items模块在上级目录中
class ScrapySpiderImages(scrapy.Spider):
'''爬取指定网站图像类'''
name = "threadsSpiderImages" # 唯一标识这个爬虫
allowed_domains = ["http://www.weather.com.cn"] # 允许爬虫的域名列表,若不定义,则不做限制
start_urls = ["http://www.weather.com.cn/weather/101280601.shtml"] # 开始爬虫的url列表,可用用start_requests()函数代替
# 设置settings中的值,优先级高于settings.py
custom_settings = {
# 下载延迟的秒数,用来限制访问的频率,默认为0,没有延时
'DOWNLOAD_DELAY': 0.3,
# 是否遵守robots协议,默认为True
'ROBOTSTXT_OBEY': False
}
def parse(self,response):
try:
html = response.body.decode() # 返回网页字符内容
selector = Selector(text=html) # 装载文档
images = selector.xpath("//img/@src").extract() # 获取所有图像文件url,以列表形式返回
threads = []
urls = []
for url in images:
if url not in urls:
urls.append(url)
item = ImageItem()
item["image_url"] = url
yield item
except Exception as err:
print(err)
- pipelines.py(数据管道处理类)
import os
import urllib
class ThreadSpiderImagePipeline(object):
# 定义类变量,它的值将在这个类的所有实例之间共享
count = 0
dirname = "images"
def process_item(self, item, spider):
if not os.path.exists(ThreadSpiderImagePipeline.dirname): # 如果文件夹不存在则创建
os.makedirs(ThreadSpiderImagePipeline.dirname)
current_path = os.getcwd()
print("{}文件夹创建在{}".format(ThreadSpiderImagePipeline.dirname, current_path))
ThreadSpiderImagePipeline.count += 1
try:
image_url = item["image_url"]
print(image_url) # 在控制台输出url信息
pos = image_url[::-1].index(".") + 1 # 找到最后一个.在第几个位置(注意下标从0开始)
ext = image_url[-pos:] # 后缀名
filename = str(ThreadSpiderImagePipeline.count) + ext
filepath = ThreadSpiderImagePipeline.dirname + "\\" + filename
try:
urllib.request.urlretrieve(image_url, filepath)
except:
default_ext = '.jpg'
print("将{}图片格式转化为{}图片格式存储".format(ext, default_ext))
filename = str(ThreadSpiderImagePipeline.count) + default_ext
filepath = ThreadSpiderImagePipeline.dirname + "\\" + filename
urllib.request.urlretrieve(image_url, filepath)
except Exception as err:
print(err)
return item
- settings.py(配置文件)
BOT_NAME = 'ThreadSpiderImage'
SPIDER_MODULES = ['ThreadSpiderImage.spiders']
NEWSPIDER_MODULE = 'ThreadSpiderImage.spiders'
ROBOTSTXT_OBEY = True
CONCURRENT_ITEMS = 100
CONCURRENT_REQUESTS = 50 # 由Scrapy下载器执行的并发(即同时)请求的最大数量
DEFAULT_REQUEST_HEADERS = {
'User-Agent':"Mozilla/5.0",
}
ITEM_PIPELINES = {
'ThreadSpiderImage.pipelines.ThreadSpiderImagePipeline': 300, # 数值一般0-1000,数值越小优先级越高
}
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl threadsSpiderImages -s LOG_ENABLED=False"
cmdline.execute(command.split())
由于只是用scrapy框架复现作业①代码,所以运行结果基本同作业①(没有打印运行时间和下载的图片名称)

但试着使用了一下threading模块,发现速度还是提升了不少。
由于scrapy是异步执行框架,自己只编写了spiders文件夹下的ThreadSpider.py文件,其余模块(items,pipelines,settings)采用默认配置,name与上述代码一致,但由于两份代码不在同一项目中所以没有影响。
- ThreadSpider.py(spiders文件夹下)
import scrapy
from scrapy.selector import Selector
import urllib
import os
import threading
import time
import warnings
warnings.filterwarnings("ignore")
class ScrapySpiderImages(scrapy.Spider):
'''多线程爬取指定网站图片'''
name = "threadsSpiderImages"
allowed_domains = ["http://www.weather.com.cn"] # 允许爬虫的域名列表,若不定义,则不做限制
start_urls = ["http://www.weather.com.cn/weather/101280601.shtml"] # 开始爬虫的url列表,可用用start_requests()函数代替
# 设置settings中的值,优先级高于settings.py
custom_settings = {
# 下载延迟的秒数,用来限制访问的频率,默认为0,没有延时
'DOWNLOAD_DELAY': 0.3,
# 是否遵守robots协议,默认为True
'ROBOTSTXT_OBEY': False
}
def parse(self,response):
'''回调函数'''
global count
global threads
count = 0
threads = []
start = time.clock()
try:
html = response.body.decode() # 返回网页字符内容
selector = Selector(text=html) # 装载文档
images = selector.xpath("//img/@src").extract() # 获取所有图像文件url,以列表形式返回
urls = self.pretreat_imageurls(images)
self.threads_download(urls)
for t in threads: # 主线程中等待所有子线程退出
t.join()
except Exception as err:
print(err)
end = time.clock()
print('Running time: %s Seconds' % (end - start))
def pretreat_imageurls(self,images):
'''从解析出的bs4ResultSet对象中提取图像url信息'''
urls = []
for url in images:
try:
if url not in urls: # url去重
urls.append(url)
print(url)
except Exception as err:
print(err)
return urls
def threads_download(self,urls):
'''根据图像urls启用多线程download'''
global count
try:
for url in urls:
count += 1 # 确保count不重,唯一的count操作
T = threading.Thread(target=self.download,args=(url,)) # 逐一(每个url)创建线程对象
T.setDaemon(False) # True则为守护线程,若设置守护线程,一旦主线程执行完毕,子线程都得结束
T.start() # 逐一启动线程
threads.append(T)
except Exception as err:
print(err)
def download(self, url):
'''下载指定url对应的图像'''
dirname = "images"
if not os.path.exists(dirname): # 如果文件夹不存在则创建
os.makedirs(dirname)
current_path = os.getcwd()
print("{}文件夹创建在{}".format(dirname, current_path))
try:
pos = url[::-1].index(".") + 1 # 找到最后一个.在第几个位置(注意下标从0开始)
ext = url[-pos:] # 后缀名
# 将下载的图像文件存入当前文件夹下的images文件夹
filename = str(count) + ext
filepath = dirname + "\\" + filename
try:
urllib.request.urlretrieve(url, filepath)
except:
default_ext = '.jpg'
print("将{}图片格式转化为{}图片格式存储".format(ext, default_ext))
filename = str(count) + default_ext
filepath = dirname + "\\" + filename
urllib.request.urlretrieve(url, filepath)
print("download " + filename)
except Exception as err:
print(err)
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl threadsSpiderImages -s LOG_ENABLED=False"
cmdline.execute(command.split())
运行结果部分截图:(其余部分与作业①中多线程结果基本相同)
可以看出scapy框架+多线程爬取图片的运行效率比单纯的scapy框架以及不在scapy框架下实现的多线程明显要更高,由此对“scrapy是多线程的,不需要再设置了”的说法表示怀疑。
2)心得体会:
本次实验重点在于对scrapy整体框架的理解和把握。scrapy是一个快速、功能强大的爬虫框架,而非函数功能库。程序入口为spiders,出口为ItemPipeline。引用一张表格帮助理解scrapy整体框架。

总的来说自己利用scrapy框架编写爬虫的整体过程是:1、确定起始url作为函数入口。2、确定要编写数据项目类items。3、在spiders下的爬虫程序中导入设计好数据项目类,在parse方法中进行获取。4、编写数据管道处理类,处理爬虫程序推送过来的item对象。5、使用scrapy中专门命令scrapy crawl执行爬虫程序。(注:创建scrapy项目是采用命令“scrapy startproject projectname”的形式)
作业③
1)scrapy框架爬取股票信息实验
要求:使用scrapy框架爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
(这里选择东方财富网)
程序主要思路:
A(根据设计好的url模板生成指定板块多页的urls列表作为入口) -->B(将存储每页股票信息的列表对象作为要获取的数据项目item)
B --> C(设计回调函数parse使其获取并返回上述item)
C --> D(编写数据管道处理类中的process_item函数格式化展示item数据并存储)
D --> E(配置项目对应的settings.py文件)
代码:
- items.py(数据项目类)
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
infos = scrapy.Field()
pass
- ScapyStockSpider.py(spiders文件夹下的爬虫程序)
import scrapy
import re
import sys
sys.path.append("..") # 为导入上级目录中的模块
from items import StockItem # items模块在上级目录中
class ScrapySpiderImages(scrapy.Spider):
name = "scapySpiderStock"
def start_requests(self):
urls = ["http://5.push2.eastmoney.com/api/qt/clist/get?pn={0:d}&pz=20&po=1&np=1\
&fltt=2&invt=2&fid=f3&fs={1}&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18"\
.format(page,self.get_fs("沪深A股")) for page in range(1,6)] # 指定爬取板块为沪深A股,循环爬取前五页
# return [scrapy.Request(url=url,callback=self.parse) for url in urls]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse) # 效率考量
def parse(self,response):
html = response.body.decode()
info = self.extract_infos(html)
item = StockItem(infos=info)
yield item
def get_fs(self,name):
'''根据板块名称返回板块部分代码号'''
fs_type = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80"
} # 东方财富网行情中心的板块变化体现在fs字段,通过f12抓包可得以上编码,其余板块依此类推
return fs_type[name]
def extract_infos(self,html):
'''从所有网页字符内容中提取所需信息范围,返回列表类型,元素为字典'''
pattern = "\[(.*?)\]"
infos = re.compile(pattern,re.S).findall(html)[0] # 所有信息一次被匹配,findall方法返回的列表中有且只有一个字符串元素
return list(eval(infos)) # eval返回该字符串所代表的python对象(元组),为便于后续操作再将元组转化为列表
- pipelines.py(数据管道处理类)
from itemadapter import ItemAdapter
from prettytable import PrettyTable
from wcwidth import wcswidth
from openpyxl import Workbook
class StockPipeline:
num = 1 # num为序号
dic = {
"股票代码": 'f12', "股票名称": 'f14', "最新报价": 'f2', "涨跌幅": 'f3',
"涨跌额": 'f4', "成交量": 'f5', "成交额": 'f6', "振幅": 'f7',
"最高": 'f15', "最低": 'f16', "今开": 'f17', "昨收": 'f18'
} # json网页中的字典键值对应含义
titles = ["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额",
"成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
wb = Workbook()
ws = wb.active
save_path = 'stock.xlsx'
def process_item(self, item, spider):
infos = item['infos']
datas = self.get_datas(infos)
for data in datas: # datas是generator的可循环对象
self.show_data(data) # 格式化展示数据
if data[0] == 1:
StockPipeline.ws.append(StockPipeline.titles)
StockPipeline.ws.append(data)
StockPipeline.wb.save(StockPipeline.save_path)
return item
def get_datas(self,infos):
'''从单页所需信息范围中提取数据存为列表'''
for info in infos: # infos为列表,info为字典
info = self.format_data(info)
data = [StockPipeline.num] # 初始化为序号
StockPipeline.num += 1 # 序号递增
for value in StockPipeline.dic.values(): # 顺序存入列表
data.append(info[value])
yield data # 等待调用循环抽取
def format_data(self,info):
'''将不符合题目格式的原始量格式化'''
# pending_format = ["涨跌幅","成交量","成交额"]
try: # 实际运行过程可能会出现数据缺失的情况
info[StockPipeline.dic["涨跌幅"]] = str(info[StockPipeline.dic["涨跌幅"]]) + "%" # 更改为百分数形式
info[StockPipeline.dic["成交量"]] = str('%.2f' %(info[StockPipeline.dic["成交量"]]/1e4))+ "万" # 保留两位小数+单位
info[StockPipeline.dic["成交额"]] = str('%.1f' %(info[StockPipeline.dic["成交额"]]/1e8))+ "亿" # 保留一位小数+单位
except:
print("相应数据缺失")
finally:
return info
# def show_data(self,data,shownum=20):
# '''展现结果,格式化输出所提取的数据'''
# StockPipeline.pt.add_row(data)
# if StockPipeline.num == shownum:
# print(StockPipeline.pt)
def show_data(self,data):
if data[0] == 1: # 第一次打印标题
pat = "{0:^2}\t{1:^7}\t{2:^7}\t{3:^7}\t{4:^7}\t{5:^7}\t{6:^7}\t{7:^7}\t{8:^7}\t{9:^7}\t{10:^7}\t{11:^7}\t{12:^7}"
titles = StockPipeline.titles
print(pat.format(titles[0],titles[1],titles[2],titles[3],titles[4],titles[5],\
titles[6],titles[7],titles[8],titles[9],titles[10],titles[11],titles[12]))
pat = "{0:^3}\t{1:^8}\t{2:^8}\t{3:^8}\t{4:^8}\t{5:^8}\t{6:^8}\t{7:^8}\t{8:^8}\t{9:^8}\t{10:^8}\t{11:^8}\t{12:^8}"
print(pat.format(data[0], data[1], data[2], data[3], data[4], data[5], \
data[6], data[7], data[8], data[9], data[10], data[11], data[12]))
- settings.py(配置文件)
BOT_NAME = 'stock'
SPIDER_MODULES = ['stock.spiders']
NEWSPIDER_MODULE = 'stock.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'stock.pipelines.StockPipeline': 300,
}
DEFAULT_REQUEST_HEADERS = {
'User-Agent':"Mozilla/5.0",
}
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl scapySpiderStock -s LOG_ENABLED=False"
cmdline.execute(command.split())
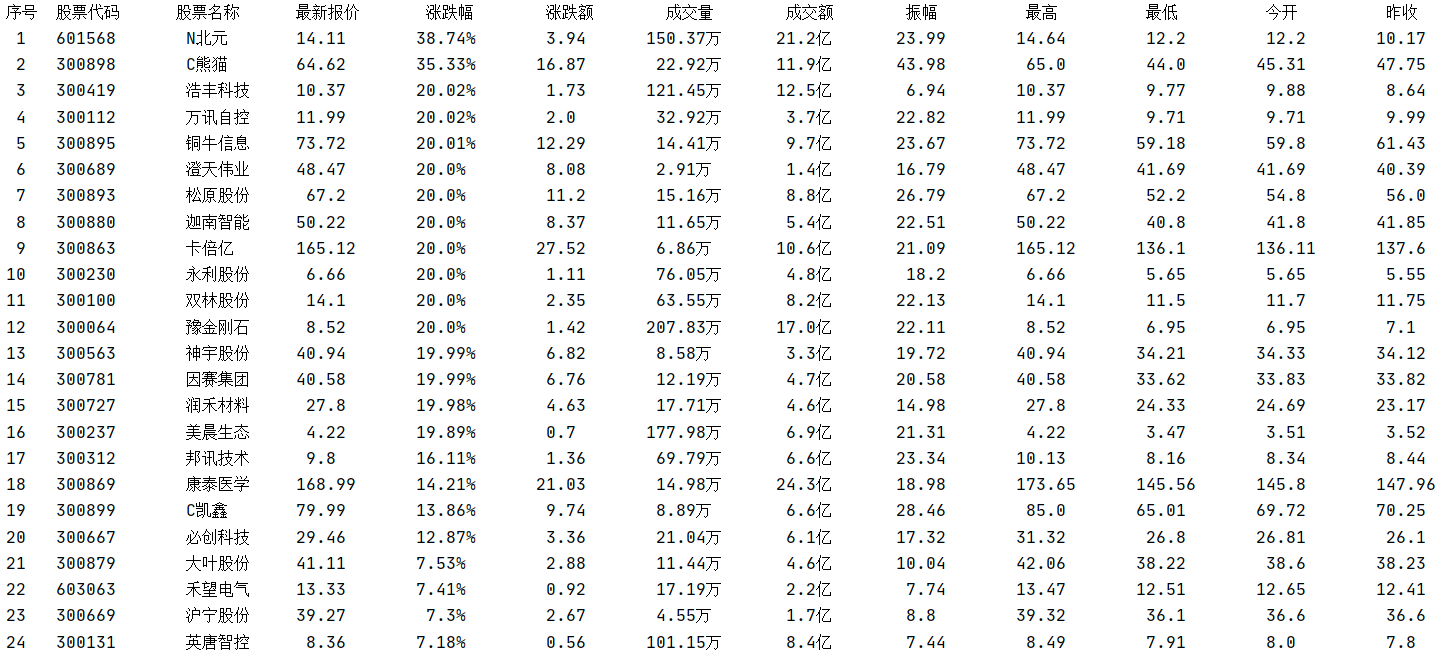
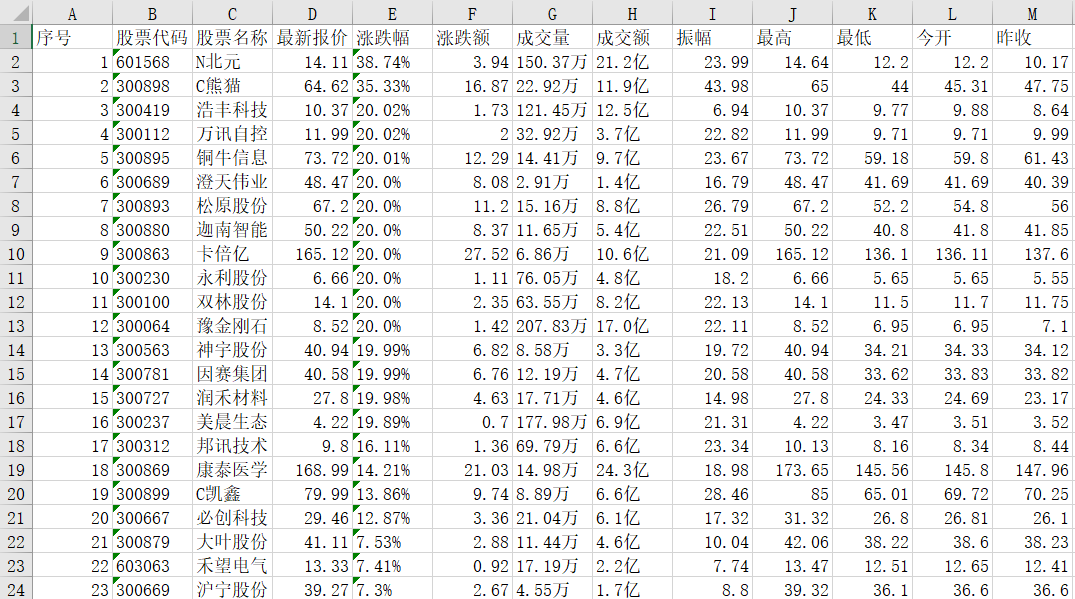
运行结果部分截图:
控制台输出
excel保存
2)心得体会:
这次实验重点依然是scrapy框架的使用。我学会了如何编写scrapy框架的各个模块使其相互配合来完成任务。以及如何在pipelines模块中进行规范的数据展示以及数据存储(excel存储可利用openpyxl中的Workbook)。
但在使用scrapy框架的过程中其实也有以下疑惑:
1、scrapy框架中的parse_item方法和process_item方法都可以用来处理数据,那么应该选取什么样的策略在两个方法中分配数据处理的工作量?是单纯让parse_items尽可能少做数据处理还是说尽可能均衡工作量?
2、scrapy框架中多线程到底是如何实现的?我在作业②中实现多线程的方法是否规范?

网络爬虫第三次作业——多线程、scrapy框架的更多相关文章
- python 全栈开发,Day137(爬虫系列之第4章-scrapy框架)
一.scrapy框架简介 1. 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前S ...
- [Python]网络爬虫(三):异常的处理和HTTP状态码的分类
先来说一说HTTP的异常处理问题. 当urlopen不能够处理一个response时,产生urlError. 不过通常的Python APIs异常如ValueError,TypeError等也会同时产 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python网络爬虫实战(三)照片定位与B站弹幕
之前两篇已经说完了如何爬取网页以及如何解析其中的数据,那么今天我们就可以开始第一次实战了. 这篇实战包含两个内容. * 利用爬虫调用Api来解析照片的拍摄位置 * 利用爬虫爬取Bilibili视频中的 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- 【网络爬虫】【python】网络爬虫(三):模拟登录——伪装浏览器登录爬取过程
一.关于抓包分析和debug Log信息 模拟登录访问需要设置request header信息,对于这个没有概念的朋友可以参见本系列前面的java版爬虫中提到的模拟登录过程,主要就是添加请求头requ ...
- python 网络爬虫(三)
一.网站地图爬虫 在一个简单的爬虫中,我们将使用实例网站 robots.txt 文件中发现的网站地图来下载所有网站,为了解析网站地图,我们将会使用一个简单的正则表达式,从<loc>标签中提 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
随机推荐
- @RequestParam,@RequestBody,@ResponseBody,@PathVariable注解的一点小总结
一.前提知识: http协议规定一次请求对应一次响应,根据不同的请求方式,请求的内容会有所不同: 发送GET请求是没有请求体的,参数会直接拼接保留到url后一并发送: 而POST请求是带有请求体的,带 ...
- Go 分支流程
if/else 基本使用 if/else应该是每个编程语言中都具备的基本分支结构. 需要注意的是if||else与{要放在同一行上,否则会抛出异常. 另外,当多个else if出现时,不同分支只会执行 ...
- 第一个随笔 Just For Test, Nothing Else
第一个随笔 Just For Test, Nothing Else 注册了第一个博客,希望以后能添加点什么吧
- Ubuntu通过Apache安装WebDav
使用KeePass保存密码,在个人服务器上安装WebDav协议. # 安装Apache2服务器 sudo aptitude install -y apache2 # 开启Apache2中对WebDav ...
- Android和CraigDJ
下载HTML source - 46.8 KB 下载APK - 8.1 MB Introduction 大家好,欢迎来到我的Android应用程序项目! 我必须承认,我仍然对原生安卓环境几乎一无所知 ...
- Oracle 和 MySQL 在显示数据库名和表名的区别
Oracle 显示数据库名和表名 Oracle 查看表名: select table_name from user_tables; select table_name from dba_tables; ...
- linux 中 eclipse 开发 c/c++ 多线程程序,添加 libpthread.a 库支持
导入头文件 在 linux 中开发多线程程序,在使用到 pthread 系列函数的文件中,需要导入头文件: #include <pthread.h> 链接 libpthread.a 在编译 ...
- 踩坑 Pycharm 2020.1.1 安装/ JetBrains破解/ anacode配置
引言 网上的办法试了很多,通常不能解决问题,还会引发一些负效应,选取了一个试了两天终于成功的方案记录一下备用. Pycharm安装 https://www.jetbrains.com/pycharm/ ...
- 利用HDFS实现ElasticSearch7.2容灾方案
利用HDFS实现ElasticSearch7.2容灾方案 目录 利用HDFS实现ElasticSearch7.2容灾方案 前言 快照版本兼容 备份集群 HDFS文件系统 软件下载 JDK环境 配置系统 ...
- day37 Pyhton 网络编程04
# tcp协议和udp协议的选择问题 # tcp # 大量的连续的数据 传递文件\发送邮件 # 文件的传递 # 下载电影 # udp # 短消息类 社交软件 # qq 微信 # 在线播放视频 快会丢帧 ...