js十大排序算法详解
十大经典算法导图
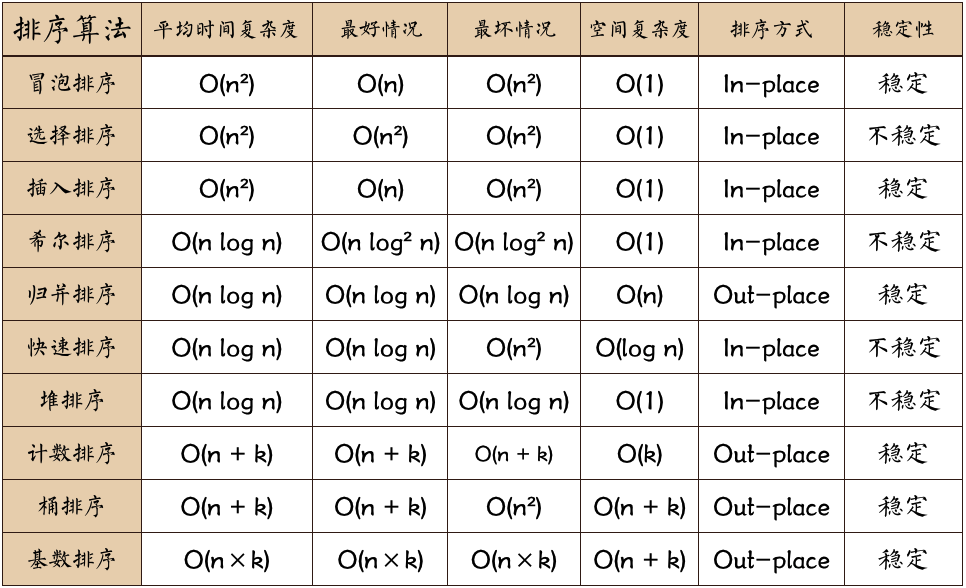
图片名词解释:
n: 数据规模
k:“桶”的个数
In-place: 占用常数内存,不占用额外内存
Out-place: 占用额外内存
1.冒泡排序
1.1 原始人冒泡排序
function bubbleSort3(arr3) {
var low = 0;
var high= arr.length-1; //设置变量的初始值
var tmp,j;
console.time('3.改进后冒泡排序耗时');
while (low < high) {
var pos1 = 0,pos2=0;
for (let i= low; i< high; ++i) { //正向冒泡,找到最大者
if (arr[i]> arr[i+1]) {
tmp = arr[i]; arr[i]=arr[i+1];arr[i+1]=tmp;
pos1 = i ;
}
}
high = pos1;// 记录上次位置
for (let j=high; j>low; --j) { //反向冒泡,找到最小者
if (arr[j]<arr[j-1]) {
tmp = arr[j]; arr[j]=arr[j-1];arr[j-1]=tmp;
pos2 = j;
}
}
low = pos2; //修改low值
}
console.timeEnd('3.改进后冒泡排序耗时');
return arr3;
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(bubbleSort3(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50] ;
既然每次记录位置可以减少计算,两头算双管齐下也能减少计算,那么思考,如果每次记录位置而且还两头算是不是会更加省事呢?(根据1.2,1.3自创)
但是冒泡排序也有弊端,就是两种极端的情况,一种是数据本来就是正序,那做的就是无用功,另外一种就是反序,不想理你。。。具体怎么弊端想想也就知道了
冒泡排序动图演示
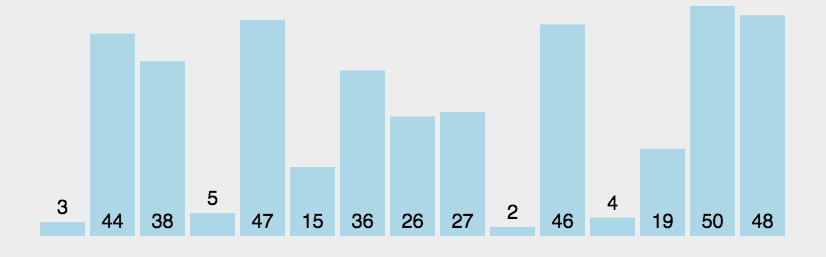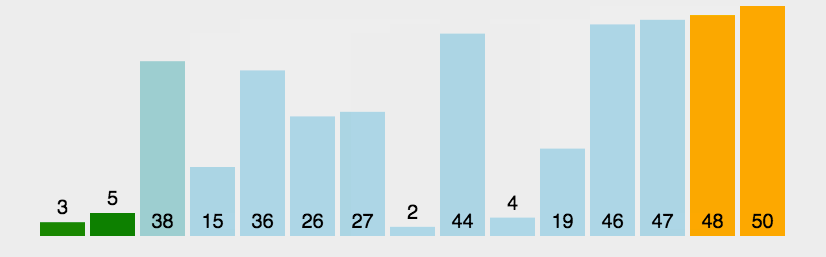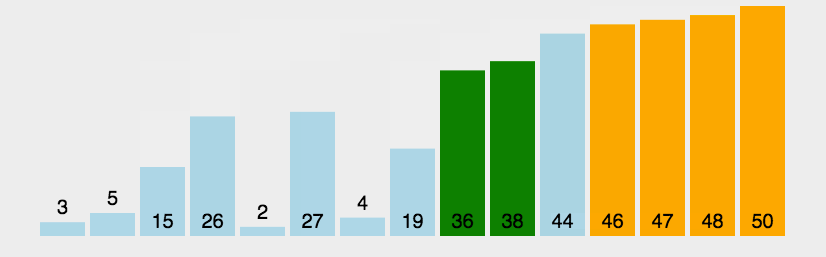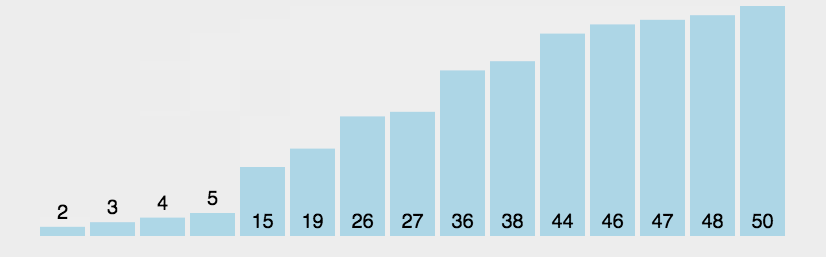
2.选择排序
插入排序的原理其实很好理解,可以类比选择排序。选择排序时在两个空间进行,等于说每次从旧的空间选出最值放到新的空间,而插入排序则是在同一空间进行。
function binaryInsertionSort(array) {
console.time('二分插入排序耗时:');
for (var i = 1; i < array.length; i++) {
var key = array[i], left = 0, right = i - 1;
while (left <= right) {
var middle = parseInt((left + right) / 2);
if (key < array[middle]) {
right = middle - 1;
} else {
left = middle + 1;
}
}
for (var j = i - 1; j >= left; j--) {
array[j + 1] = array[j];
}
array[left] = key;
}
console.timeEnd('二分插入排序耗时:');
return array;
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(binaryInsertionSort(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50];
二分法插入排序第一遍读下去,一脸懵逼,写的是什么鬼,仔细琢磨一下却别有一番风味,听小编慢慢讲下去,首先外层循环没什么疑问,就是简单的遍历一遍数组,那么先看while循环,left和right两个变量可以简单的类比3.1中的已排序的首末两个位置,然后选取未排序的第一个值和已排序的中间位置的值进行比较,这样的话也就是在最坏的情况下每层循环也只是计算了已排序的序列长度的一半的次数,简而言之就是在无限逼近left和right值,找到未排序第一个值应该在的位置。
还是以梁山排名为例子,在宋江没有到梁上之前,每个上梁上的人跟已经排过名的从大往小进行比较,然后找到自己的位置,在老大宋江来之后,后续人慢慢多了,然后宋老大就订了条规矩,就是每个新来的人和已排过名次的位于中间名次的好汉进行比较,胜了往前一位比较,败了往后一位比较,然后找到自己的位置。好了,while循环解释完毕,那么下面又多了一条for循环,这又是什么鬼?
不要着急,待小编与你慢慢道来,看不懂没关系,先看循环体,循环体的意思就是把前一个值给后一个,然后看循环条件是从i-1的位置从后往前依次将前一个元素的值给后一个,先不要管i-1是谁,先问 i 是谁,i 不就是未排序的第一个元素么,不就是我们拿来对已进行排序的元素么,简而言之不就是新上梁山的好汉么,那么从left值开始到 i-1 的位置依次将前一个元素的值给后一个无非就是空出 left 的位置,left 的位置不就是新上梁上好汉的位置!
插入排序法动图:
4.希尔排序
希尔排序,直接上图;

像这个算法看图理解起来并不是很难,就像比赛一样,1-6一组,2-7一组,每差5为一组进行比较,之后再每差2为一组进行比较,最后就是两两比较,有点类似冒泡算法,但又比冒泡多了一层增量的概念。起初小编看到这个导图的时候感觉编程挺简单的,无非就是改变一下增量,这有何难?人呐,都是眼高手低,废话不多说直接看代码:
其实代码并不难理解,小编就不详解了。
配上动图加深印象:
6.快速排序
3.1 抽象版快速排序
function quickSort(array, left, right) {
console.time('1.快速排序耗时');
if (left < right) {
var x = array[right], i = left - 1, temp;
for (var j = left; j <= right; j++) {
if (array[j] <= x) {
i++;
temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
console.log(array) ;
console.log(left,i) ;
quickSort(array, left, i - 1);
console.log(array)
console.log(i,right)
quickSort(array, i + 1, right);
}
console.timeEnd('1.快速排序耗时');
console.log(array)
return array;
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(quickSort(arr,0,arr.length-1));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50];
看完代码一脸懵逼,这是人写的么?瞬间觉得自己弱爆了,连别人代码都看不懂,更别说自己写了,别着急,一点点拆分看。
先看一个疑问点,函数中的参数有三个,第一个数组,没得说;第二个是左值,第三个是右值;好,到这里先分析结束,首先给读者一种什么感觉,就是这个排序算法是从左右两端依次逼近完成排序的,那么对于这个猜想对不对呢?
接着看,if条件语句中判断left < right,这没得说,就是从左到右排序的,而且if 如果不成立直接结束本层循环了,那如果满足条件呢,直接进入for循环,而且在进入for循环之前先记录了一个本次循环的末尾值,又设置一个i ,还有一个空变量,都分别又是什么意思呢?
接着看,for循环遍历本层循环,然后依次和末尾值进行比较,那么可想而知,这个变量x无非就是个基数,好了,算法的亮点来了,就是 i 值,如果本层循环某个元素大于本层循环的基数,那么置换两者的位置,那么 i 的作用就是计数的作用,而 temp 就是作为交换暂时存储的介质,然后这样下来就是把每次本层循环的最大值放到了最后,这样下来在quickSort(array, left, i - 1);不断递归循环之后,该数组的右边最小值大于左边的最大值(这里的左边和右边不一定等分),而且左边的顺序已经排好了,然后同理排右边的部分,这样下来函数结束之后就完成了排序。(暂时小编能理解的大概就是这种程度了,不当之处,还望博友指点一二)
3.2 形象版快速排序
var quickSort2 = function(arr) {
console.time('2.快速排序耗时');
if (arr.length <= 1) { return arr; }
var pivotIndex = Math.floor(arr.length / 2);
var pivot = arr.splice(pivotIndex, 1)[0];
console.log(pivot)
var left = [];
var right = [];
for (var i = 0; i < arr.length; i++){
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
console.timeEnd('2.快速排序耗时');
return quickSort2(left).concat([pivot], quickSort2(right));
};
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(quickSort2(arr));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50];
看完第一种写法之后,有种放弃的念头,不要着急,慢慢拨开迷雾你能感受到快速排序的奇特之处。
废话不多说直接看代码,第二种开始还能理解,哦,原来和第一种写法类似,第二种则是选择中中间数作为基数进行比较,然后再遍历比较,把比中间值小的放在left数组,把比中间值大的放在right数组中,这种写法再简单不过了,而看到后面return quickSort2(left).concat([pivot], quickSort2(right)); 这是什么鬼?是不是写错了,怎么感觉那么不对劲呢?不要怀疑经典,拆分代码看,哦,原来是不断把数组细分化,分到数组长度为1的最小单位,然后再把左右两个数组拼凑起来,试想每层基循环都有左右两个长度为1的数组,且左数组元素比右数组元素值小,而基循环的基数又是两基数组元素的中间数,那这不就比较完了吗,把三者拼凑起来不正是排序后的序列么,使用递归依次类推形成最后的数组。就是这么简单,完毕。
配上一个动图,第一次看可能会很懵逼,配合代码多看几遍或许能明白其巧妙之处。
7.堆排序
这种排序方式呢,理论性太强,看动图的时候满脸写着懵逼,多看几遍似乎明白了编者的意图,但是要把这种理论的概念写成代码却不容易,且看代码:
function heapSort(array) {
console.time('堆排序耗时');
//建堆
var heapSize = array.length, temp;
for (var i = Math.floor(heapSize / 2) - 1; i >= 0; i--) {
heapify(array, i, heapSize);
}
//堆排序
for (var j = heapSize - 1; j >= 1; j--) {
temp = array[0];
array[0] = array[j];
array[j] = temp;
console.log(array)
heapify(array, 0, --heapSize);
}
console.timeEnd('堆排序耗时');
return array;
}
function heapify(arr, x, len) {
var l = 2 * x + 1, r = 2 * x + 2, largest = x, temp;
if (l < len && arr[l] > arr[largest]) {
largest = l;
}
if (r < len && arr[r] > arr[largest]) {
largest = r;
}
if (largest != x) {
temp = arr[x];
arr[x] = arr[largest];
arr[largest] = temp;
console.log(arr)
heapify(arr, largest, len);
}
}
var arr=[91,60,96,13,35,65,46,65,10,30,20,31,77,81,22];
console.log(heapSort(arr));//[10, 13, 20, 22, 30, 31, 35, 46, 60, 65, 65, 77, 81, 91, 96];
这种算法有两个难点,一是建堆,而是堆排序。首先明白什么是堆,堆其实可以这么理解,类似金字塔,一层有一个元素,两层有两个元素,三层有四个元素,每层从数组中取元素,从左到右的顺序放到堆相应的位置上,也就是说每一层元素个数为2n-1 ;(n 代表行数),这就完成了建堆。
那么想,堆排序中最后一位不就是2n-m(n代表总行数,m代表差多少位不到完成堆的位数),那该元素的父级是谁,2n-1-m/2,2n-1-m/2是谁?拿总位数除以2就知道了,没错就是数组的中间值,这也是编者为什么从中间值入手的原因了。
而对于 l = 2*x +1 与 r = 2*x+2 ,不正是每个父级元素对应的子堆么,每一层的堆排序都能够把本层的最大值剔除出来,这样当所有 层循环结束之后,序列也就完成了。
这一点小编觉得和归并排序有点类似,都是细分到最小单元,从最小单元比较,但是同归并排序有两大点不同,一是堆排序并不像归并那么无序,只是一味的平分数组,而堆排序则是按原始序列排出金字塔式的结构,把最大值一层层往上冒,冒到金字塔最顶端的时候把它踢出来,这样达到排序的效果。
附动图,不多看几遍是看不出来什么门道的:

8.计数排序
计数排序就是遍历数组记录数组下的元素出现过多次,然后把这个元素找个位置先安置下来,简单点说就是以原数组每个元素的值作为新数组的下标,而对应小标的新数组元素的值作为出现的次数,相当于是通过下标进行排序。
看代码:
function countingSort(array) {
var len = array.length,
B = [],
C = [],
min = max = array[0];
console.time('计数排序耗时');
for (var i = 0; i < len; i++) {
min = min <= array[i] ? min : array[i];
max = max >= array[i] ? max : array[i];
C[array[i]] = C[array[i]] ? C[array[i]] + 1 : 1;
console.log(C)
}
// 计算排序后的元素下标
for (var j = min; j < max; j++) {
C[j + 1] = (C[j + 1] || 0) + (C[j] || 0);
console.log(C)
}
for (var k = len - 1; k >= 0; k--) {
B[C[array[k]] - 1] = array[k];
C[array[k]]--;
console.log(B)
}
console.timeEnd('计数排序耗时');
return B;
}
var arr = [2, 2, 3, 8, 7, 1, 2, 2, 2, 7, 3, 9, 8, 2, 1, 4, 2, 4, 6, 9, 2];
console.log(countingSort(arr)); //[1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 4, 4, 6, 7, 7, 8, 8, 9, 9];
这种算法的亮点就是在于利用下标存数据,利用数据存出现的次数。然后这种算法还有一个亮点就是第二个循环,计算排序后的下标,也就是说在这个地方已经把每个元素对应在排序后的数组的位置已经确定了,在第三个循环中只需要安插在对应的位置即可!
其实这里小编还另外一种算法,没有上面那种复杂,小编感觉更容易理解,仅供参考:
function countingSort(array) {
var len = array.length,
B = [],
C = [],
min = max = array[0];
console.time('计数排序耗时');
for (var i = 0; i < len; i++) {
min = min <= array[i] ? min : array[i];
max = max >= array[i] ? max : array[i];
C[array[i]] = C[array[i]] ? C[array[i]] + 1 : 1;
}
for (var k = 0; k <len; k++) {
var length = C[k];
for(var m = 0 ;m <length ; m++){
B.push(k);
}
}
console.timeEnd('计数排序耗时');
return B;
}
var arr = [2, 2, 3, 8, 7, 1, 2, 2, 2, 7, 3, 9, 8, 2, 1, 4, 2, 4, 6, 9, 2];
console.log(countingSort(arr)); //[1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 4, 4, 6, 7, 7, 8, 8, 9, 9];
思想主要是既然我们已经根据下标进行排序了,C数组的下标对应的数值就是该下标出现的次数,那何不吧该次数作为二层循环的长度遍历一遍直接推送到新得数组中呢?
附动图便于理解:
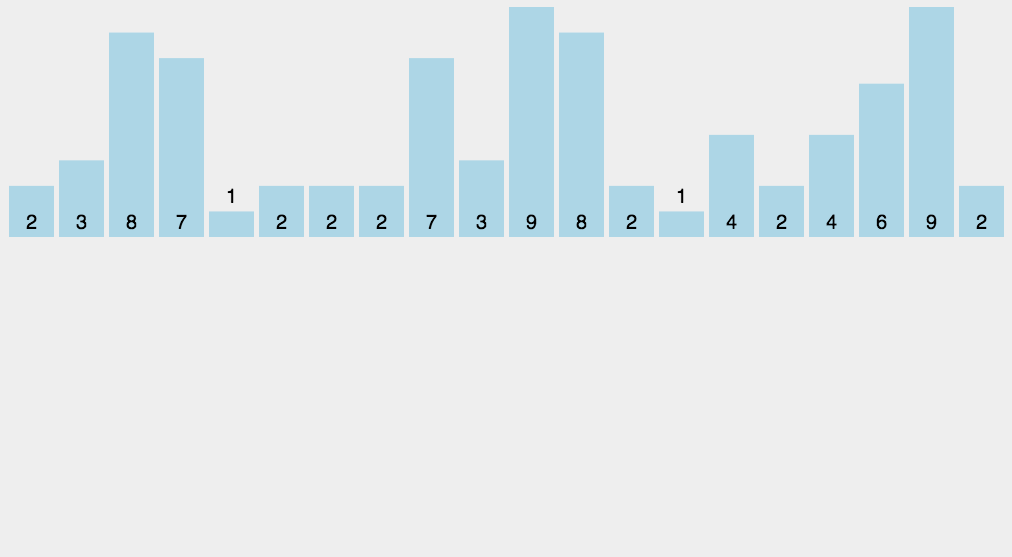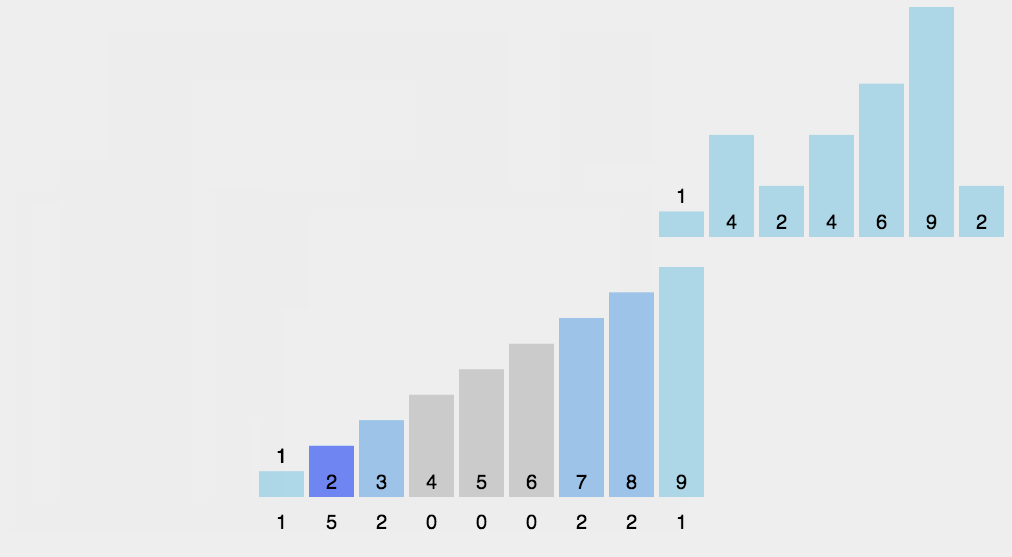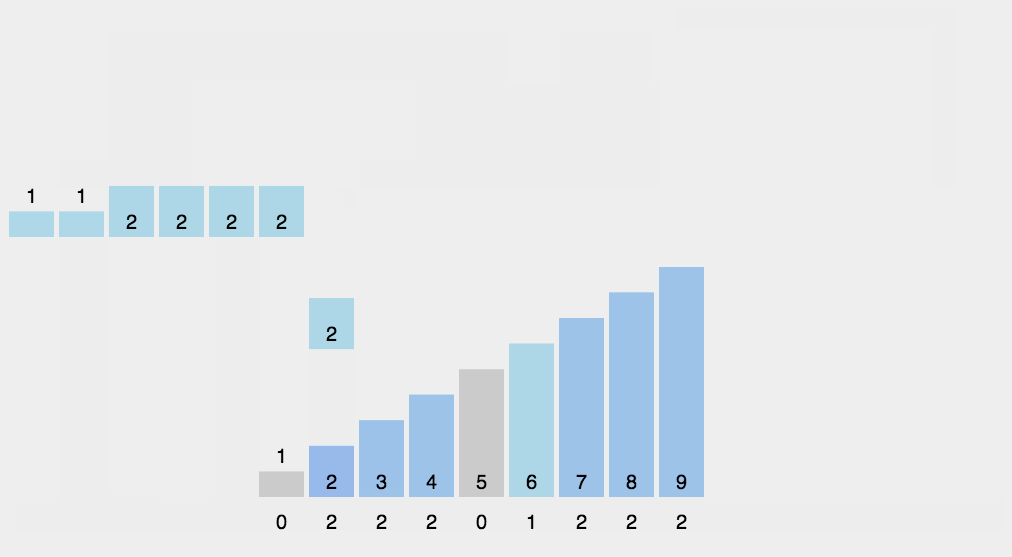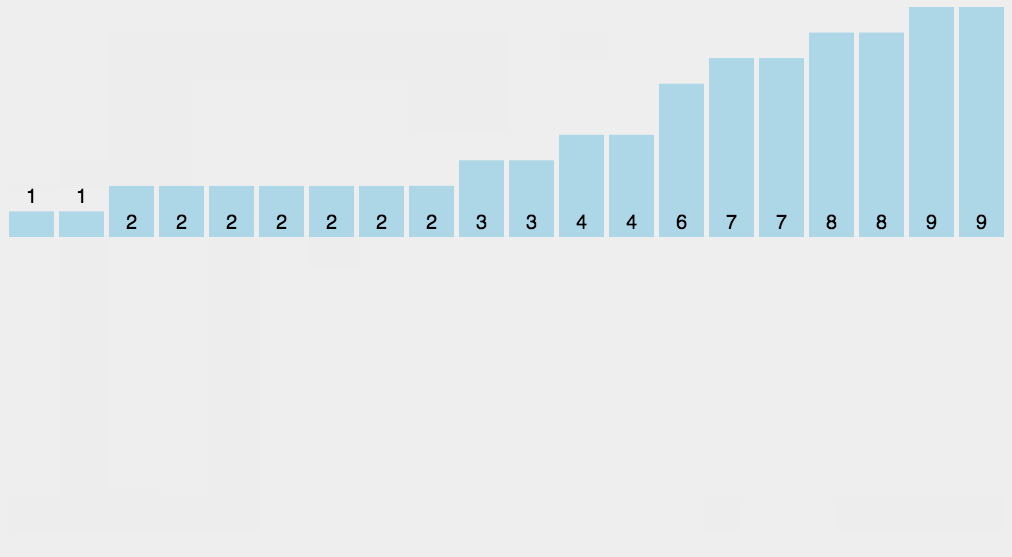
9. 桶排序
一看到这个名字就会觉得奇特,几个意思,我排序还要再准备几个桶不成?还真别说,想用桶排序还得真准备几个桶,但是此桶非彼桶,这个桶是用来装数据用的。其实桶排序和计数排序还有点类似,计数排序是找一个空数组把值作为下标找到其位置,再把出现的次数给存起来,这似乎看似很完美,但也有局限性,不用小编说相信读者也能明白,既然计数是把原数组的值当做下标来看待,那么该值必然是整数,那假如出现小数怎么办?这时候就出现了一种通用版的计数排序——桶排序。
小编觉得桶排序可以这么理解,它是以步长为分隔,将最相近数据分隔在一起,然后再在一个桶里排序。好了,现在有个概念,步长是什么玩意?这么来说吧,比如在知道十位的情况下48和36有比较的必要吗?显然没有,十位就把你干下去了,还比什么?那在这里可以简单的把步长理解为10,桶排序就是这样,先把同一级别的分到一组,由同一级别的元素进行排序。
代码实现:
function bucketSort(array, num) {
if (array.length <= 1) {
return array;
}
var len = array.length, buckets = [], result = [], min = max = array[0], space, n = 0;
var index = Math.floor(len / num) ;
while(index<2){
num--;
index = Math.floor(len / num) ;
}
console.time('桶排序耗时');
for (var i = 1; i < len; i++) {
min = min <= array[i] ? min : array[i];
max = max >= array[i] ? max : array[i];
}
space = (max - min + 1) / num; //步长
for (var j = 0; j < len; j++) {
var index = Math.floor((array[j] - min) / space);
if (buckets[index]) { // 非空桶,插入排序
var k = buckets[index].length - 1;
while (k >= 0 && buckets[index][k] > array[j]) {
buckets[index][k + 1] = buckets[index][k];
k--;
}
buckets[index][k + 1] = array[j];
} else { //空桶,初始化
buckets[index] = [];
buckets[index].push(array[j]);
}
}
while (n < num) {
result = result.concat(buckets[n]);
n++;
}
console.timeEnd('桶排序耗时');
return result;
}
var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
console.log(bucketSort(arr,4));//[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50];
但是这边有个坑点,就是桶的数量不能过多,也就说说至少两个桶!为什么?你试下就知道了!
附图理解:
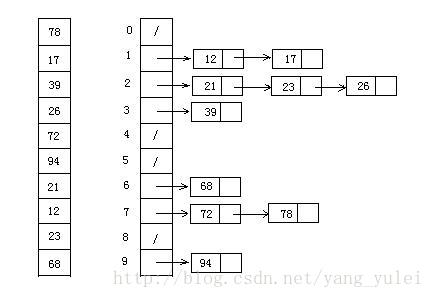
10.基数排序
其实基数排序和桶排序挺类似的,都是找一个容器把属于同一类的元素装起来,然后进行排序。可以把基数排序类比成已知该序列的最高位,然后以除去相对来说的最低位(可能是个位,可能是十位)剩余的位数为桶数,这样一来步长就是10或者100了。但是基数排序相对桶排序又有多了一个亮点,那就是基数排序是先排最低位(个位),把最低位一致的放在一个桶里,然后依次取出,再进一位(十位),把十位相同的再放到一个桶里,然后再取出,这样经过两次重排序就能得到百位以内的排序序列了,百位,千位也是如此。

基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
参考文章:http://blog.damonare.cn/ 十大经典排序算法总结(javascript描述)
js十大排序算法详解的更多相关文章
- [ 转载 ] js十大排序算法:冒泡排序
js十大排序算法:冒泡排序 http://www.cnblogs.com/beli/p/6297741.html
- js 十大排序算法 All In One
js 十大排序算法 All In One 快速排序 归并排序 选择排序 插入排序 冒泡排序 希尔排序 桶排序 堆排序(二叉树排序) 基数排序 计数排序 堆排序(二叉树排序) https://www.c ...
- JS中常见排序算法详解
本文将详细介绍在JavaScript中算法的用法,配合动图生动形象的让你以最快的方法学习算法的原理以及在需求场景中的用途. 有句话怎么说来着: 雷锋推倒雷峰塔,Java implements Java ...
- js十大排序算法收藏
十大经典算法排序总结对比 转载自五分钟学算法&https://www.cnblogs.com/AlbertP/p/10847627.html 一张图概括: 主流排序算法概览 名词解释: n: ...
- js十大排序算法
排序算法说明: (1)对于评述算法优劣术语的说明 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面:不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面: 内排序:所有排 ...
- js十大排序算法:冒泡排序
排序算法说明: (1)对于评述算法优劣术语的说明 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面:不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面: 内排序:所有排 ...
- JavaScript的9大排序算法详解
一.插入排序 1.算法简介 插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法.它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入. ...
- 【Java学习笔记之十一】Java中常用的8大排序算法详解总结
分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排序(直接选择排序.堆排序) 4)归并排序 5)分配排序(基数排序) 所需辅助空间最多:归并排序 所需辅助空 ...
- 使用 js 实现十大排序算法: 快速排序
使用 js 实现十大排序算法: 快速排序 QuickSort 快速排序 /** * * @author xgqfrms * @license MIT * @copyright xgqfrms * @c ...
随机推荐
- 安装office自定义项,安装期间出错
由于安装vs2013,导致excel打开时出现问题 [解决方案] 开始菜单-excel图标处,右键快捷菜单-以管理员身份运行-新建空白工作簿 文件-选项-加载项-管理中选择COM加载项,转到-删除Lo ...
- HTTP协议和SOCKS5协议
HTTP协议和SOCKS5协议 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们平时上网的时候基本上是离不开浏览器的,尤其是搜索资料的时候,那么这个浏览器是如何工作的呢?用的又是 ...
- Unity做AR
Unity做AR呢这里借助了高通的AR包 这里是视频教程 http://www.tudou.com/programs/view/dnvEbIubNzI/ 这里是结果演示 http://www.tu ...
- Oracle导出数据中的prompt,set feedback 等是什么意思
prompt 显示后面的提示,相当于一般的操作系统命令echo,输出后面的信息Importing table t_testset feedback off 1.set feedback 有三种方式: ...
- mysql优化问题汇总
sql优化-->分区-->分表-->垂直分库-->水平分库-->读写分离 分区 关于分区的博客推荐这个:https://blog.csdn.net/youzhouliu/ ...
- java基础面试题常出现(一)
1.”==“和equals方法的区别? 1. ==操作符,对于基本数据类型变量,比较的是两个值是否相等,而对于引用类型,比较的是引用的内存的首地址,即引用同一个对象.1 Obeject的equal ...
- git初学 常用命令
初学备忘: MAC 下 clone 项目的时候 记得 sudo -s 输入密码 获得 管理员权限,普通权限看不到 .babelrc 等 点开头的文件 ____——____——____——____ ...
- Python官方操作Excel文档
xlwt 1.3.0 Downloads ↓ Library to create spreadsheet files compatible with MS Excel 97/2000/XP/2003 ...
- Python中str()和repr()函数的区别
在 Python 中要将某一类型的变量或者常量转换为字符串对象通常有两种方法,即 str() 或者 repr() . 区别与使用函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供 ...
- 参数在一个线程中各个函数之间互相传递的问题(ThreadLocal)
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源. 一个ThreadLocal变量虽然是 ...