Spark2.2(三十九):如何根据appName监控spark任务,当任务不存在则启动(任务存在当超过多久没有活动状态则kill,等待下次启动)
业务需求
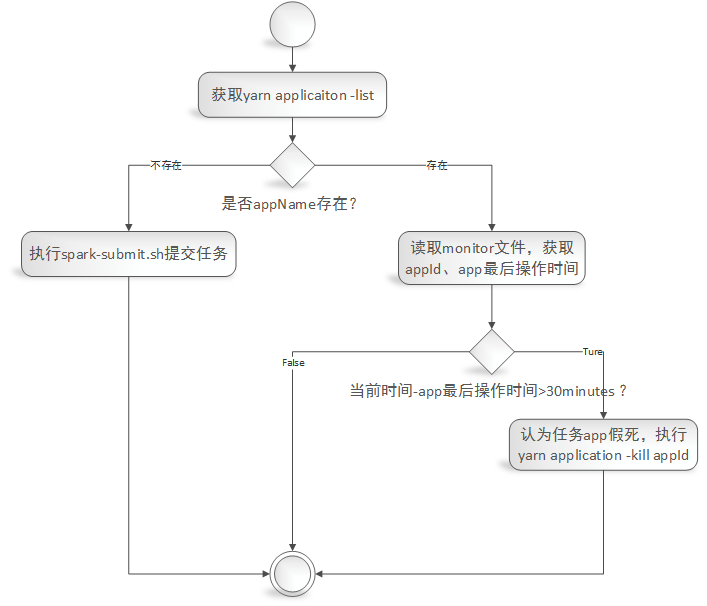
实现一个根据spark任务的appName来监控任务是否存在,及任务是否卡死的监控。
1)给定一个appName,根据appName从yarn application -list中验证任务是否存在,不存在则调用spark-submit.sh脚本来启动任务;
2)如果任务存在yarn application -list中,则读取‘监控文件(监控文件内容包括:appId,最新活动时间)’,从监控文件中读取出最后活动的日期,计算当前日期与app的最后活动日期相差时间为X,如果X大于30minutes(认为任务处于假死状态[再发布环境发现有的任务DAG抛出OOM,导致app的executor和driver依然存在,当时不执行任务调度,程序卡死。具体错误详情请参考《https://issues.apache.org/jira/browse/SPARK-26452》]),则执行yarn application -kill appId(杀掉任务),等待下次监控脚本执行时重启任务。
监控实现
脚本
#/bin/sh
#LANG=zh_CN.utf8
#export LANG
export SPARK_KAFKA_VERSION=0.10
export LANG=zh_CN.UTF-
# export env variable
if [ -f ~/.bash_profile ];
then
source ~/.bash_profile
fi
source /etc/profile myAppName='myBatchTopic' #这里指定需要监控的spark任务的appName,注意:这名字重复了会导致监控失败。
apps='' for app in `yarn application -list`
do
apps=${app},$apps
done
apps=${apps%?} if [[ $apps =~ $myAppName ]];
then
echo "appName($myAppName) exists in yarn application list"
#)运行 hadop fs -cat /目录/appName,读取其中最后更新日期;(如果文件不存在,则跳过等待文件生成。)
monitorInfo=$(hadoop fs -cat /user/dx/streaming/monitor/${myAppName})
LD_IFS="$IFS"
IFS=","
array=($monitorInfo)
IFS="$OLD_IFS"
appId=${array[]}
monitorLastDate=${array[]}
echo "loading mintor information 'appId:$appId,monitorLastUpdateDate:$monitorLastDate'" current_date=$(date "+%Y-%m-%d %H:%M:%S")
echo "loading current date '$current_date'" #)与当前日期对比:
# 如果距离当前日期相差小于30min,则不做处理;
# 如果大于30min则kill job,根据上边yarn application -list中能获取对应的appId,运行yarn application -kill appId
t1=`date -d "$current_date" +%s`
t2=`date -d "$monitorLastDate" +%s`
diff_minute=$(($(($t1-$t2))/))
echo "current date($current_date) over than monitorLastDate($monitorLastDate) $diff_minute minutes"
if [ $diff_minute -gt ];
then
echo 'over then 30 minutes'
$(yarn application -kill ${appId})
echo "kill application ${appId}"
else
echo 'less than 30 minutes'
fi
else
echo "appName($myAppName) not exists in yarn application list"
#./submit_x1_x2.sh abc TestRestartDriver #这里指定需要启动的脚本来启动相关任务
$(nohup ./submit_checkpoint2.sh >> ./output.log >& &)
fi
监控脚本业务流程图:
监控文件生成
我这里程序是spark structured streaming,因此可以注册sparkSesssion的streams()的query的监听事件
sparkSession.streams().addListener(new GlobalStreamingQueryListener(sparkSession。。。))
在监听事件中实现如下:
public class GlobalStreamingQueryListener extends StreamingQueryListener {
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(GlobalStreamingQueryListener.class);
private static final String monitorBaseDir = "/user/dx/streaming/monitor/";
private SparkSession sparkSession = null;
private LongAccumulator triggerAccumulator = null;
public GlobalStreamingQueryListener(SparkSession sparkSession, LongAccumulator triggerAccumulator) {
this.sparkSession = sparkSession;
this.triggerAccumulator = triggerAccumulator;
}
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
// sparkSession.sql("select * from " +
// queryProgress.progress().name()).show();
triggerAccumulator.add(1);
System.out.println("Trigger accumulator value: " + triggerAccumulator.value());
logger.info("minitor start .... ");
try {
if (HDFSUtility.createDir(monitorBaseDir)) {
logger.info("Create monitor base dir(" + monitorBaseDir + ") success");
} else {
logger.info("Create monitor base dir(" + monitorBaseDir + ") fail");
}
} catch (IOException e) {
logger.error("An error was thrown while create monitor base dir(" + monitorBaseDir + ")");
e.printStackTrace();
}
// spark.app.id application_1543820999543_0193
String appId = this.sparkSession.conf().get("spark.app.id");
// spark.app.name myBatchTopic
String appName = this.sparkSession.conf().get("spark.app.name");
String mintorFilePath = (monitorBaseDir.endsWith(File.separator) ? monitorBaseDir : monitorBaseDir + File.separator) + appName;
logger.info("The application's id is " + appId);
logger.info("The application's name is " + appName);
logger.warn("If the appName is not unique,it will result in a monitor error");
try {
HDFSUtility.overwriter(mintorFilePath, appId + "," + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
} catch (IOException e) {
logger.error("An error was thrown while write info to monitor file(" + mintorFilePath + ")");
e.printStackTrace();
}
logger.info("minitor stop .... ");
}
}
HDFSUtility.java中方法如下:
public class HDFSUtility {
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(HDFSUtility.class);
/**
* 当目录不存在时,创建目录。
*
* @param dirPath
* 目标目录
* @return true-創建成功;false-失敗。
* @throws IOException
* */
public static boolean createDir(String dirPath) throws IOException {
FileSystem fs = null;
Path dir = new Path(dirPath);
boolean success = false;
try {
fs = FileSystem.get(new Configuration());
if (!fs.exists(dir)) {
success = fs.mkdirs(dir);
} else {
success = true;
}
} catch (IOException e) {
logger.error("create dir (" + dirPath + ") fail:", e);
throw e;
} finally {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return success;
}
/**
* 覆盖文件写入信息
*
* @param filePath
* 目标文件路径
* @param content
* 被写入内容
* @throws IOException
* */
public static void overwriter(String filePath, String content) throws IOException {
FileSystem fs = null;
// 在指定路径创建FSDataOutputStream。默认情况下会覆盖文件。
FSDataOutputStream outputStream = null;
Path file = new Path(filePath);
try {
fs = FileSystem.get(new Configuration());
if (fs.exists(file)) {
System.out.println("File exists(" + filePath + ")");
}
outputStream = fs.create(file);
outputStream.write(content.getBytes());
} catch (IOException e) {
logger.error("write into file(" + filePath + ") fail:", e);
throw e;
} finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Spark2.2(三十九):如何根据appName监控spark任务,当任务不存在则启动(任务存在当超过多久没有活动状态则kill,等待下次启动)的更多相关文章
- Spark2.3(三十六):根据appName验证某个app是否在运行
具体脚本 #/bin/sh #LANG=zh_CN.utf8 #export LANG export SPARK_KAFKA_VERSION=0.10 export LANG=zh_CN.UTF- # ...
- NeHe OpenGL教程 第三十九课:物理模拟
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- Java进阶(三十九)Java集合类的排序,查找,替换操作
Java进阶(三十九)Java集合类的排序,查找,替换操作 前言 在Java方向校招过程中,经常会遇到将输入转换为数组的情况,而我们通常使用ArrayList来表示动态数组.获取到ArrayList对 ...
- Gradle 1.12用户指南翻译——第三十九章. IDEA 插件
本文由CSDN博客万一博主翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- SQL注入之Sqli-labs系列第三十八关、第三十九关,第四十关(堆叠注入)
0x1 堆叠注入讲解 (1)前言 国内有的称为堆查询注入,也有称之为堆叠注入.个人认为称之为堆叠注入更为准确.堆叠注入为攻击者提供了很多的攻击手段,通过添加一个新 的查询或者终止查询,可以达到修改数据 ...
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式 我们自定义一个main.py来作为启动文件 main.py #!/usr/bin/en ...
- centos shell编程5 LANMP一键安装脚本 lamp sed lnmp 变量和字符串比较不能用-eq cat > /usr/local/apache2/htdocs/index.php <<EOF重定向 shell的变量和函数命名不能有横杠 平台可以用arch命令,获取是i686还是x86_64 curl 下载 第三十九节课
centos shell编程5 LANMP一键安装脚本 lamp sed lnmp 变量和字符串比较不能用-eq cat > /usr/local/apache2/htdocs/ind ...
- “全栈2019”Java第三十九章:构造函数、构造方法、构造器
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- WPF,Silverlight与XAML读书笔记第三十九 - 可视化效果之3D图形
原文:WPF,Silverlight与XAML读书笔记第三十九 - 可视化效果之3D图形 说明:本系列基本上是<WPF揭秘>的读书笔记.在结构安排与文章内容上参照<WPF揭秘> ...
随机推荐
- Python 线程和进程
一.什么是线程 1.线程是操作系统能够进行运算调度的最小单位.它被包含在进程中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务 ...
- jdk 生成证书
1.生成客户端的私钥,客户端的证书 1)keytool -genkey -alias clientkey -keystore kclient.keystore -validity 36500 2) ...
- 20165319第五周java学习笔记
教材内容总结 1.String类和StringBuffer类都覆盖了toString方法,都是返回字符串. 所以带不带toString效果是一样的. 2.instanceOf运算符可以用来判断某个对象 ...
- Cygwin命令
Cygwin是一个用于在Windows上模拟Linux环境的软件. 通过cygwin,可以在windows环境下使用linux的程序,像find.tar等一些工具也可以在windows下使用,让我们可 ...
- poj 3685 Matrix 【二分】
<题目链接> 题目大意: 给你一个n*n的矩阵,这个矩阵中的每个点的数值由 i2 + 100000 × i + j2 - 100000 × j + i × j 这个公式计算得到,N( ...
- PAT (Advanced Level) Practise 1001 解题报告
GiHub markdown PDF 问题描述 解题思路 代码 提交记录 问题描述 A+B Format (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判 ...
- 最详细的Vuex教程
什么是Vuex? vuex是一个专门为vue.js设计的集中式状态管理架构.状态?我把它理解为在data中的属性需要共享给其他vue组件使用的部分,就叫做状态.简单的说就是data中需要共用的属性. ...
- Java -- 内部类(二)
在上一篇博客Java --内部类(一)中已经提过了,java中的内部类主要有四种:成员内部类.局部内部类.匿名内部类.静态内部类. 该文主要介绍这几种内部类. 成员内部类 成员内部类也是最普通的内部类 ...
- pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库. 可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现 本文也是基于这篇文章代码基础上实现 ...
- centos 7 之nginx
环境信息 [root@node1 ~]# cat /etc/redhat-release CentOS Linux release (Core) [root@node1 ~]# uname -r -. ...