Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的、高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地。这里的日志是一个统称,泛指文件、操作记录等许多数据。
一、Flume基础理论
1.1 常见的分布式日志收集系统

Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。 Chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。而 Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
1.2 Flume的数据流模型
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume传输的数据的基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event 从 Source 流向 Channel,再到 Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
1.3 Flume的三大核心组件
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另一个地方,如图1所示。
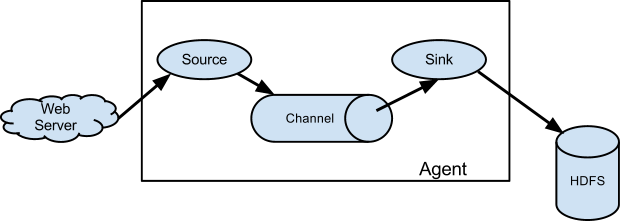
图1 Flume数据流模型
一个flume系统可以由一个或多个agent组成,多个agent只要做一些简单的配置就可以串在一起,比如将两个agent(foo、bar)串在一起工作,只要将bar的source(入口)接在foo的sink(出口)上就可以了。如图2所示。
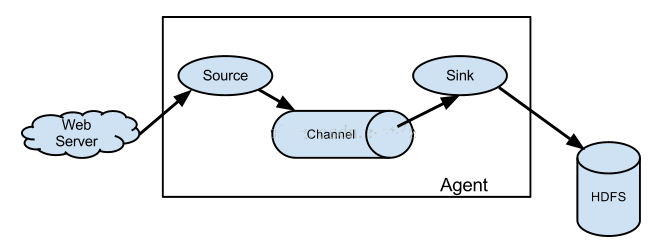
图2 多级Agent连接模型
图3则展示了将4个agent串在一起,agent1、agent2和agent3都是获取web服务器的数据,然后将各自获得到的数据统一地发送给agent4,最后由agent4将收集到的数据存储在hdfs里面。
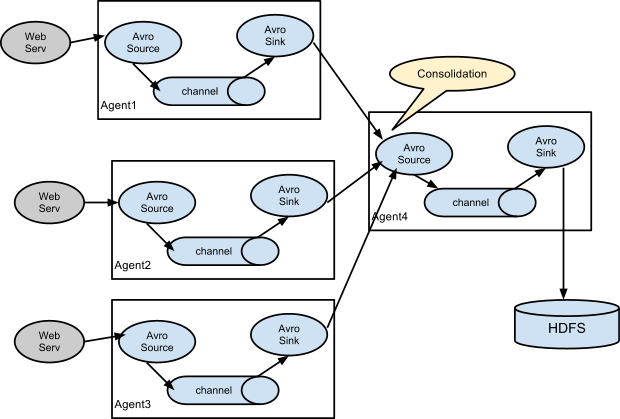
图3 多对一的合并模型
(1)什么是Agent?
Flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地。
(2)三大核心组件
①Source:专用于收集日志,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等。
②Channel:专用于临时存储数据,可以存放在memory、jdbc、file、数据库、自定义等。其存储的数据只有在sink发送成功之后才会被删除。
③Sink:专用于把数据发送到目的地点,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义等。
理解Source、Channel与Sink:
source为水源,是aent获取数据的入口;
channel为管道,是数据(由resource获得)流动的通道,主要作用是用来传输和存储数据;
sink为水槽,用来接收channel传入的数据并将数据输出到指定地方。
大家可以把agent看作一个水管,source就是水管的入口,sink就是水管的出口,把数据当作水来看,数据流也就意味着水流。数据由source获得流经channel,最后传给sink。如图1就演示了一个完整的agent流程,由webserver获取数据,数据经channel流向sink,最后由sink将数据存储在hdfs里面。
1.3 Flume的可靠性保证
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume使用事务性的方式保证传送Event整个过程的可靠性。Sink必须在Event被存入Channel后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把Event从Channel中remove掉。这样数据流里的event无论是在一个agent里还是多个agent之间流转,都能保证可靠,因为以上的事务保证了event会被成功存储起来。而Channel的多种实现在可恢复性上有不同的保证。也保证了event不同程度的可靠性。比如Flume支持在本地保存一份文件channel作为备份,而memory channel将event存在内存queue里,速度快,但丢失的话无法恢复。
二、Flume基础实践
2.1 Flume基本安装
(1)下载flume的安装包,这里选择的是1.4.0版本的,我已经将其上传到了网盘中(http://pan.baidu.com/s/1kTEFUfX)
(2)解压缩bin与src包,并重命名
Step1.解压缩两个包
tar -zvxf libs/apache-flume-1.4.0-bin.tar.gz
tar -zvxf libs/apache-flume-1.4.0-src.tar.gz
Step2.将源码包拷贝到bin目录中
cp -ri apache-flume-1.4.0-src/* apache-flume-1.4.0-bin/
Step3.【可选】重命名为flume
mv apache-flume-1.4.0-bin flume
2.2 Flume基本配置
本次实践示例Source来自Spooling Directory,Sink流向HDFS。监控/root/edisonchou文件目录下的文件,一旦有新文件,就立刻将文件内容通过agent流向HDFS的hdfs://hadoop-master:9000/testdir/edisonchou文件中。在这之前,我们需要对flume进行基本的配置。
首先,进入flume的conf目录下,新建一个example.conf,其对三大核心组件的配置如下:
(1)配置source
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/root/edisonchou
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
(2)配置channel
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/root/edisonchou_tmp/123
agent1.channels.channel1.dataDirs=/root/edisonchou_tmp/
(3)配置sink
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop-master:9000/testdir/edisonchou
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
2.3 监控指定目录测试
(1)启动hadoop,老命令:start-all.sh
(2)新建文件夹/root/edisonchou,并在HDFS中新建目录/testdir/edisonchou
(3)在flume目录中执行以下命令启动示例agent
bin/flume-ng agent -n agent1 -c conf -f conf/example.conf -Dflume.root.logger=DEBUG,console

出现上图所示时,说明agent启动成功了。
(4)新开一个SSH连接,在该连接中新建一个文件test,随便写点内容,然后将其移动到/root/edisonchou目录中,这时再查看上一个连接中的控制台信息如下,可以发现以下几点信息:
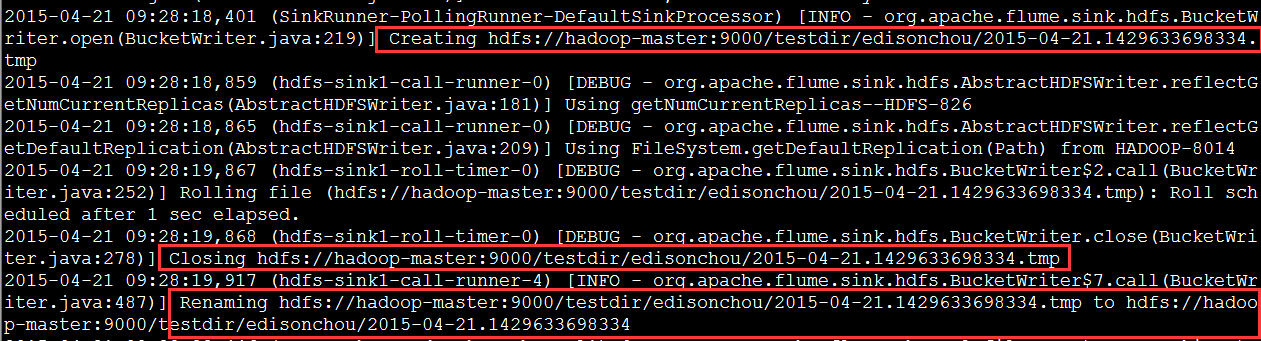
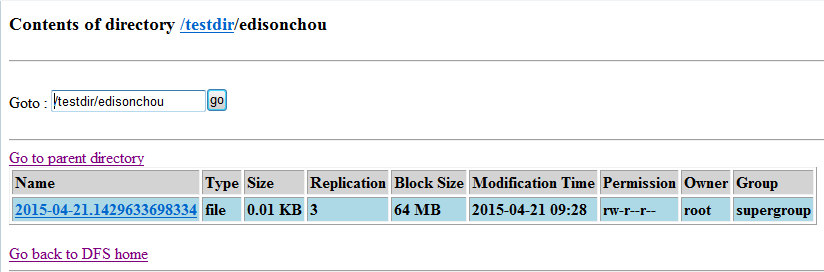
可以发现,当我们向监控目录/root/edisonchou中新增一个文件时,agent立即向HDFS写入了这个文件,其中经历了大概三步:创建、关闭、重命名。在重命名步骤中,主要是将.tmp后缀移除。下图展示了我们向监控目录加入的文件test已经通过agent加入了HDFS中:
参考资料
(1)hanlong,《Flume—开源分布式日志收集系统》:http://www.cnblogs.com/hanganglin/articles/4224928.html
(2)windcarp,《Flume采集处理日志文件》:http://www.cnblogs.com/windcarp/p/3872578.html
(3)我的小人生,《Flume 1.4的介绍及使用》:http://www.cnblogs.com/fuhaots2009/p/3473122.html
(4)残夜,《Flume日志收集》:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html
(5)sandyfog,《Flume的概述和简单实例》:http://www.cnblogs.com/sandyfog/p/3795967.html
(6)apache,《flume文档》:http://flume.apache.org/documentation.html
Hadoop学习笔记—19.Flume框架学习的更多相关文章
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Hadoop学习笔记—15.HBase框架学习(基础知识篇)
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型,它存储的是 ...
- Hadoop学习笔记—15.HBase框架学习(基础实践篇)
一.HBase的安装配置 1.1 伪分布模式安装 伪分布模式安装即在一台计算机上部署HBase的各个角色,HMaster.HRegionServer以及ZooKeeper都在一台计算机上来模拟. 首先 ...
- Hadoop学习笔记—16.Pig框架学习
一.关于Pig:别以为猪不能干活 1.1 Pig的简介 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换 ...
- Hadoop学习笔记—17.Hive框架学习
一.Hive:一个牛逼的数据仓库 1.1 神马是Hive? Hive 是建立在 Hadoop 基础上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储. ...
- tornado学习笔记19 Tornado框架分析
19.1 Http服务器请求处理流程图 (1) 调用HTTPServer的bind方法,绑定Socket的监听端口号: (2) 调用HTTPServer的listen方法,初始化一个listen so ...
- Android 学习笔记之AndBase框架学习(七) SlidingMenu滑动菜单的实现
PS:努力的往前飞..再累也无所谓.. 学习内容: 1.使用SlidingMenu实现滑动菜单.. SlidingMenu滑动菜单..滑动菜单在绝大多数app中也是存在的..非常的实用..Gith ...
- Android 学习笔记之AndBase框架学习(六) PullToRefrech 下拉刷新的实现
PS:Struggle for a better future 学习内容: 1.PullToRefrech下拉刷新的实现... 不得不说AndBase这个开源框架确实是非常的强大..把大部分的东西 ...
- Android 学习笔记之AndBase框架学习(五) 数据库ORM..注解,数据库对象映射...
PS:好久没写博客了... 学习内容: 1.DAO介绍,通用DAO的简单调度过程.. 2.数据库映射关系... 3.使用泛型+反射+注解封装通用DAO.. 4.使用AndBase框架实现对DAO的调用 ...
随机推荐
- 剑指Offer-【面试题06:重建二叉树】
package com.cxz.question6; /* * 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字. * 例如:前序遍历序列 ...
- 第三十三篇:使用uiresImporter生成uires.idx及skin.xml
在SOUI中,使用uires.idx这个文件来记录程序中使用的所有资源文件. 此外绘制对象(ISkinObj)则一般放在skin.xml中描述. 要向一个界面中增加一个新的图片,在没有uiresImp ...
- Add Indexer to DynamicJson
/*-------------------------------------------------------------------------- * DynamicJson * ver 1.2 ...
- ssh 使用
svn 删除所有的 .svn文件 find . -name .svn -type d -exec rm -fr {} \; linux之cp/scp命令+scp命令详解 注意:本篇以后设涉及到的@后面 ...
- 浩瀚PDA开单器-结束手工开单模式【百货、商超】PDA安卓智能手持POS 进销存管理系统移动收银管理软件
移动销售终端:先进的跨平台技术,支持智能PDA等移动终端提供移动销售开单.移动POS.移动查询货品.移动盘点等功能. 移动开单器的操作说明 第一步:选客户 Ø 用户在空白开单主页左划屏幕 ...
- 苹果mac电脑中brew的安装使用及卸载详细教程
brew 又叫Homebrew,是Mac OSX上的软件包管理工具,能在Mac中方便的安装软件或者卸载软件, 只需要一个命令, 非常方便 brew类似ubuntu系统下的apt-get的功能 安装br ...
- NAIPC-2016
A. Fancy Antiques 爆搜+剪枝. #include <bits/stdc++.h> using namespace std ; typedef pair < int ...
- SVG文件:从Illustrator导文件到Web
可缩放矢量图形(SVG)是早在1998年就已经有的一种矢量图像格式.它总是和Web一起发展,但是直到现在才开始赶上Web发展的步伐.如今我们已经不能否认SVG和Web的相关性,所以让我们来学习一下从I ...
- Bootstrap 简洁、直观、强悍的前端开发框架,让web开发更迅速、简单。
Bootstrap 简洁.直观.强悍的前端开发框架,让web开发更迅速.简单.
- jQuery的加法运算.
jQuery的加法运算. 加法运算 ?想必大家听到这都会不屑了,加法运算这是多么简单的运算.然而有的时候在jQuery也让人挺头疼的. 常规的是: var num1 = 123; var num2=1 ...