Hadoop(2)--hdfs
 Hadoop(2)
Hadoop(2)
Hadoop底层封装的的是HDFS和MapReduce两种框架
在Hdfs中采用的是主从结构(Madter-slaver)就像领导和员工一样,领导负责整个公司的管理工作,而员工就负责向领导汇报工作以及完成领导分发的任务
在HDFS中,NameNode(Master)就负责对整个集群中节点的管理以及维护文件系统树以及文件目录。而DataNode分布在不同的机架上,就像是员工分布在公司别的不同部门一样,在客户端或者领导NameNode的调度下,存储并检索数据块,并定期向NameNode发送所存储的数据块的列表,报告自己的情况,可以让NameNode随时掌握整个集群的资源情况。
概念解释
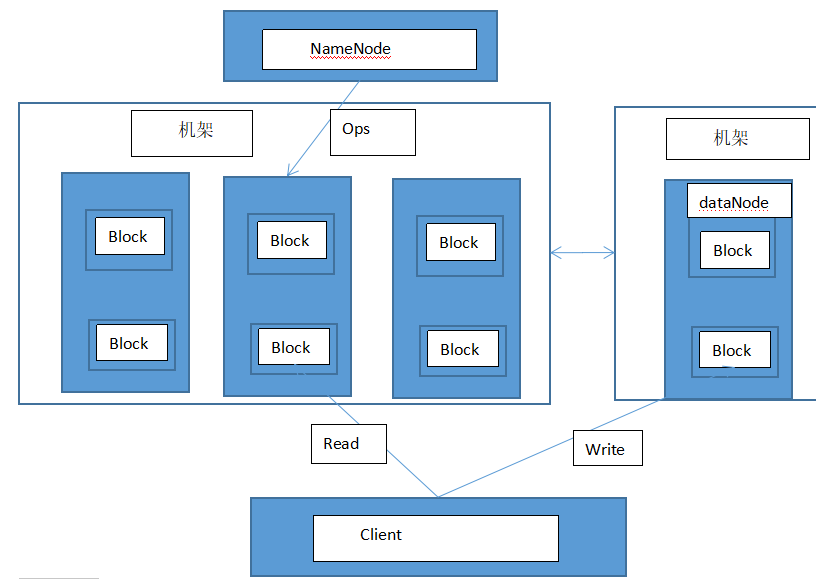
机架:HDFS集群主要是由分布在不同机架上的多个机架的DataNode组成的,相同机架上的机器之间通过TCP协议进行相应的连接(7077端口),不同机架上的节点通过交换机进行通信,HDFS会通过机架感知策略感知每一个DataNode所属的机架,使用副本放置策略来改进数据的可靠性、可用性和网络带宽的利用率
机架感知策咯:在源码中就是通过判断机架中各个节点与NameNode节点的距离进行判断
分别为0(同一个节点的不同块上)、1(同一个机架的不同节点上)、3(同一个机房的不同机架上)、4(不同的机房)
副本放置策略:为了防止数据意外丢失,就像我们会对手机中的数据在电脑上进行备份一样,我们也会在节点上对数据进行一个备份,默认的是3个备份,
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本就随机放在集群的node里
通过这一策略,当发生意外断电等情况的时候还在其余的机架或者几点上进行了数据的存储,可以去其他的数据放置处重新获得数据进行计算,尽量的减少了数据丢失的可能
心跳:在Hdfs中,节点之间通过TCP协议进行通信,DataNode每3s向NameNode发送一个心跳,每10次心跳之后向NameNode发送一个数据块报告自己的信息,通过这些信息,NameNode能够在发生意外之后可以重新创建元数据,并确保每个数据块有足够的副本
元数据:存储在NameNode中,是文件系统中的文件和目录的属性信息,当NameNode启动的时候会创建fsimage和edit.log两个文件(fsimage存储的是文件metadata信息,不包括文件块的位置信息(位置信息是NameNode存放在内存中),edit文件存放是的文件系统的所有更新操作的路径,他们两个都是经过序列化的,当NameNode失败之后,文件metadata信息可以加载fsimage到内存中,在editlog中应用相应的操作)当遇到checkpoint进行触发后,secondaryNameNode会定时的将fsimage和editlog进行合并更新,NameNode就可以随时掌握集群的状态信息,
Client:就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
Client 可以通过一些命令来访问 HDFS。
HDFS读写操作:
1、读操作:

|
1、client向namenode请求下载文件
2、Namenode会判断client是否有权向,如果有权限的话会将datanode的元数据信息返回给client
3、Client按照距离和顺序去读取datanode中的block,当datanode发生异常的话会进行记录并上传给datanode节点,剩余的数据读取会略过这个节点bi
4、读取block之后通过append将block整合成一个完整的文件进行使用
读文件的方法:
1、HDFS API
2、HDFS Client Cmd:
Hdfs dfs -get [ignorecrc] [-crc] <src> <localdst>
2、写操作:
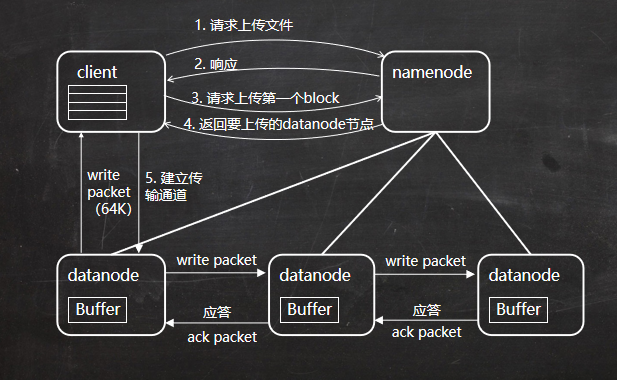
1、client向namenode发送请求,请求上传文件
2、Namenode会检查常见的文件是否存在以及client是否有操作权限并对client进行响应
3、当客户端开始上传文件的时候会将文件写个成多个packet并在内部已dataqueue的形式进行管理,并向namenode申请blocks进行存储
4、namenode获取适合存储的datanode列表,并根据replicationi进行列表大小的设定
5、建立传输通道将packet写入到datanode当中,在第一个datanode存储packet之后,通过管道将其传送给下一个datanode直到最后一个datanode
6、最后一个datanode存储成功后会返回一个ack packet队列,在pipeline中返回到客户端,当ack成功返回客户端之后,相应的packet会从dataqueue中删除
7、依次进行,直至所有的数据传输完毕
Hadoop(2)--hdfs的更多相关文章
- hadoop(三)HDFS 文件系统
Hadoop 附带了一个名为 HDFS(Hadoop 分布式文件系统)的分布式文件系统,专门 存储超大数据文件,为整个 Hadoop 生态圈提供了基础的存储服务. 本章内容: 1) HDFS 文件系统 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- Hadoop(七)HDFS容错机制详解
前言 HDFS(Hadoop Distributed File System)是一个分布式文件系统.它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞 ...
- hadoop(五)HDFS原理剖析
一.HDFS的工作机制 工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能 力,形成一定的集群运维能力PS:很多不是真正理解 hadoop 工作原理的人会常常觉得 HDF ...
- hadoop(四)HDFS的核心设计
一.hadoop心跳机制(heartbeat) 1. Hadoop 是 Master/Slave 结构, Master 中有 NameNode 和 ResourceManager, Slave 中有 ...
- hadoop(三)HDFS基础使用
一.HDFS前言 1. 设计思想 分而治之:将大文件,大批量文件,分布式的存放于大量服务器上.以便于采取分而治之的方式对海量数据进行运算分析 2. 在大数据系统架构中的应用 ...
- Hadoop(四)HDFS的高级API操作
一 HDFS客户端环境准备 1.1 jar包准备 1)解压hadoop-2.7.6.tar.gz到非中文目录 2)进入share文件夹,查找所有jar包,并把jar包拷贝到_lib文件夹下 3)在全部 ...
- Hadoop(三)HDFS读写原理与shell命令
一 HDFS概述 1.1 HDFS产生背景 随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
随机推荐
- Android端访问服务器核心代码
- Caused by: java.lang.ClassNotFoundException: org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter
严重: StandardWrapper.Throwableorg.springframework.beans.factory.BeanCreationException: Error creating ...
- 猿创|有赞的zan framework安装与使用[2]
下载并安装comoser curl -sS https://getcomposer.org/installer | php 结果各种超时 不能忍,打开迅雷下载installer:https://get ...
- scrum 第二次冲刺
scrum 第二次冲刺 1.本周工作 本周正式开始了开发工作.首先设计了类图,建好了数据库,将整个小组的分工传到了禅道上,我主要负责后台的挂号操作. 本周分工如下: 首先搭建好了ssm框架,其中遇到了 ...
- MAVEN本地下载、安装
1. 安装jdk (此处版本选择1.7以上) 此处不做安装说明!!! 2.Eclipse.配置及安装 此处不做安装说明!!! 3.maven安装包(此处选择apache-maven-3.5.2-bin ...
- Linux下apt-get的软件一般安装路径
apt-get安装目录和安装路径:apt-get 下载后,软件所在路径是:/var/cache/apt/archivesubuntu 默认的PATH为PATH=/home/brightman/bin: ...
- Jmeter 登陆性能测试
1.打开Jmeter,新建一个线程组:测试计划--添加--Threads(users)---线程组 如图: 2.首先要添加一个HTTP默认请求,为什么要添加这个呢? 如果要测试的系统域名或者IP地址是 ...
- UnitySendMessage
SendMessage查找的方法是在自身当中去查找 SendMessageUpwards查找的方法是在自身和父类中去查找,如果父类还有父类,继续查找,知道找到根节点为止. BroadcastMessa ...
- mybatis学习记录五——动态sql
8 动态sql 8.1 什么是动态sql mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接.组装. 8.2 需求 用户信息综合查询列表 ...
- html5中event获取data和class
获取data和class var tare=$(e.relatedTarget).data("id");var tar=event.target;console.log(tare) ...