hive 搭建
Hive
hive是简历再hadoop上的数据库仓库基础架构,它提供了一系列的工具,可以用来进行数据提取转化
加载(ETL),这是一种可以存储,查询和分析存储再hadoop种的大规模数据机制,hive定义了简单的类sql
查询语音,称为QL,它允许熟悉sql的用户查询数据,同时, 这个语言也允许熟悉mapreduce开发者的开发
自定义的mapper和 reducer 来处理内建的mapper和reducer无法完成的复杂的分析工作
数据库:关系型数据库 和 非关系型数据库 可以实时进行增删改查操作
数据仓库: 存放大量数据,可以对仓库里数据,进行计算和分析,弱点:不能实时更新,删除
Hive 是sql解析引擎,它将sql语句转译成M/R job,然后再haoop上执行
Hive的表其实你一直HDFS的目录/文件夹,按表名把文件夹分开,如果是分区表,则分区值是子文件夹,
可以直接在M/R job里使用这些数据
Hive的系统架构
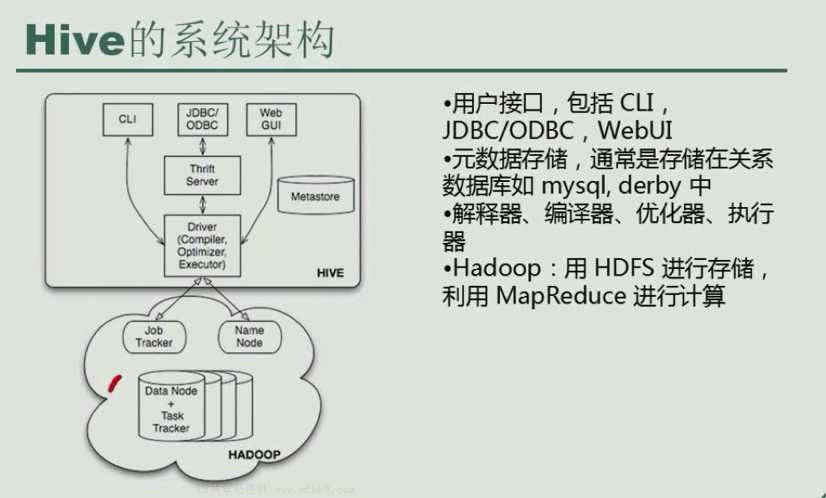
用户接口主要有三个: CLI , ODBC/JDBC . WebUI
1 cli, 即shell 命令行
2. JDBC/ODBC 是Hive的java
3. WEBUI是通过浏览器访问Hive
Hive 将元数据存储再数据库中的 metastore,并没有保存计算的数据,要计算的数据都保存在hdfs中,只保存的表的信息,表的名字,表有几个列,这个表处理的那条数据,表的描述信息, 目前只支持mysql、derby
Hive中的元数据包括表的名字, 表的列和分区及其属性,表的属性,表的数据所在目录等
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、 编译、优化以及查询计划的生成,
生成的查询计划存储再HDDS中, 并在随后在mapreduce调用执行。
Hive的数据存储再HDFS中,大部分的查询由mapreduce完成。
Hive 既要依赖 hdfs,也要依赖yarn
derby数据库不支持多个连接
cd /data/hive/bin
./hive
hive>show databases
hive>show tables
hive>create table student(id int,name string)
hive>show create table student
cat /root/1.txt
1 feng
2 su
3 li
空行
#hive从本地加载/root/1.txt,并且导入到sutdent表中
hive>load data local inpath '/root/1.txt' into table student
查询student表数据,显示4行数据,但是都为NULL, 因为列与列之间没有分隔符, 显示2列,是应为,创建表时,有2列。
hive> select * from student;
NULL NULL
NULL NULL
NULL NULL
NULL NULL
统计student 行总数,调用mapreduce。
hive> select count(*) from student;
创建 teacher, 以\t 为分隔符。
hive>create table teacher (id bigint,name string) row format delimited fields terminated by '\t'
hive>show create table teacher
hive>select * from teacher;
hive>seley * from teacher order by id desc;
创建库
hive>create database feng;
hive>use feng;
hive>show tables;
hive>create table user (id int, name string)
metastore 保存的位置,在/data/hive/bin 目录下 derby数据名称 metastore_db,
如果metastore_db 再当前路径下只支持一个连接,
在那个目录下 运行的 hive命令,就在那个目录下 生成metastore_db,不同路径下的metastore_db,显示的库不同。
使用mysql作为 meastore 存储路径
1 删除derby 在hdfs生成的库删除
hdfs dfs rm -rf /user/hive
2. 配置hive
[root@hive1 conf]# vim hive-env.sh
HADOOP_HOME=/data/hadoop
[root@hive1 conf]# cp hive-default.xml.template hive-site.xml
<!--
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://ns1/hive/warehousedir</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://ns1/hive/scratchdir</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive/logs</value>
</property>
-->
<!--连接192.168.20.131 mysql数据库,如果hive没有,则创建 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.20.131:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!--mysql odbc驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--mysql 用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--mysql 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///data/hive/lib/hive-hbase-handler-2.1.0.jar ,file:///data/hive/lib/protobuf-java-2.5.0.jar,file:///data/hive/lib/hbase-client-1.1.1.jar,file:///data/hive/lib/hbase-common-1.1.1.jar,file:///data/hive/lib/zookeeper-3.4.6.jar</value>
</property>
<!--
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.20.96:9083</value>
</property>
-->
在 Hive 中创建表之前需要使用以下 HDFS 命令创建 /tmp 和 /user/hive/warehouse (hive-site.xml 配置文件中属性项 hive.metastore.warehouse.dir 的默认值) 目录并给它们赋写权限
[root@hive1 ~]# hadoop fs -mkdir -p /hive/scratchdir
[root@hive1 ~]# hadoop fs -mkdir /tmp
[root@hive1 ~]# hadoop fs -ls /hive
[root@hive1 ~]# hadoop fs -chmod -R g+w /hive/
[root@hive1 ~]# hadoop fs -chmod -R g+w /tmp
拷贝 odbc驱动
cp mysql-connector-java-5.1.40-bin.jar /data/hive/lib
从 Hive 2.1 版本开始, 我们需要先运行 schematool 命令来执行初始化操作
[root@hive1 bin]# ./schematool -dbType mysql -initSchema
[root@hive1 bin]# chown -R hadoop.hadoop /data/hive
[root@hive1 data]# su - hadoop
[hadoop@hive1 bin]$ ./hive
启动成功
hive> create table people (id int,name string)
mysql中保存表的信息, hdfs 创建一个people文件夹
192.168.20.131 mysql 保存的元数据信息 mysql中显示结果
root@localhost:hive>select * from columns_v2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | id | int | 0 |
| 1 | NULL | name | string | 1 |
+-------+---------+-------------+-----------+-------------+
2 rows in set (0.00 sec)
root@localhost:hive>select * from tbls
-> ;
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| 1 | 1479804678 | 1 | 0 | hadoop | 0 | 1 | name | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
1 row in set (0.00 sec)
指向了 hdfs 路径
root@localhost:hive>select * from sds
-> ;
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+
| SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID |
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+
| 1 | 1 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://ns1/user/hive/warehouse/name | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 1 |
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+
hive 搭建的更多相关文章
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
- Hive搭建与简单使用
hive搭建与简单使用(1) 标签(空格分隔): hive,mysql hive相当于编译器的组件,他并不存储数据,元数据存储在mysql中,数据则存放在hdfs中,通过hive,可以利用sql语句对 ...
- 基于Docker搭建大数据集群(六)Hive搭建
基于Docker搭建大数据集群(六)Hive搭建 前言 之前搭建的都是1.x版本,这次搭建的是hive3.1.2版本的..还是有一点细节不一样的 Hive现在解析引擎可以选择spark,我是用spar ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 数据,我们知道这是一个以店铺为维度的切分数据,非常适合目前 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- Spark入门到精通--(第九节)环境搭建(Hive搭建)
上一节搭建完了Hadoop集群,这一节我们来搭建Hive集群,主要是后面的Spark SQL要用到Hive的环境. Hive下载安装 下载Hive 0.13的软件包,可以在百度网盘进行下载.链接: h ...
- 将hive搭建到spark上
1. 首先搭建好spark和hive,参见相关文档 2. 在spark/conf下创建hive-site.xml <configuration> <property> < ...
- CentOS下Hive搭建
目录 1. 前言 2. MySQL安装 2.1 更换yum下载源 2.2 开启MySQL远程登录 3. Hive安装 3.1 下载Hive 3.2 安装Hive和更改配置文件 4. MySQL驱动包的 ...
- hive搭建配置
下载cd /data0/software/hivewget http://mirror.bit.edu.cn/apache/hive/hive-0.12.0/hive-0.12.0-bin.tar.g ...
随机推荐
- tomcat 常用优化配置
1.精简Tomcat和配置文件 1.删除不需要的管理应用和帮助应用,提高tomcat安全性. # 删除webapps下所有文件 # rm –fr $CATALINA_HOME/webapps/* # ...
- Android 笔记 day3
短信发送器 电脑弱爆了,开第二个emulater要10min!!! 顺便学会查看API文档 package com.example.a11; import java.util.*; import an ...
- 浏览器-07 chromium 渲染1
Chromium 软件渲染 软件渲染就是利用CPU,根据一定的算法来计算生成网页的内容; Chromium都是用软件渲染的技术来完成页面的绘制工作(除非强行打开硬件加速绘制); 软件渲染基础和架构 R ...
- 桶装水 送水 消费充值PDA会员管理系统 介绍
桶装水 送水 消费充值PDA会员管理系统 介绍 主要功能:会员管理临时开卡.新增会员.修改会员.删除会员场馆管理仓管信息管理.租凭信息管理会员卡管理会员卡类型设置.会员发卡.会员信息管理.体验用户发卡 ...
- 数位DP GYM 100827 E Hill Number
题目链接 题意:判断小于n的数字中,数位从高到低成上升再下降的趋势的数字的个数 分析:简单的数位DP,保存前一位的数字,注意临界点的处理,都是套路. #include <bits/stdc++. ...
- 纯CSS完成tab实现5种不同切换对应内容效果
很常用的一款特效纯CSS完成tab实现5种不同切换对应内容效果 实例预览 下载地址 实例代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ...
- [转]webpack进阶构建项目(一)
阅读目录 1.理解webpack加载器 2.html-webpack-plugin学习 3.压缩js与css 4.理解less-loader加载器的使用 5.理解babel-loader加载器 6.理 ...
- div垂直居中的几种方法
CSS教程:div垂直居中的N种方法[转](原文地址:http://www.cnblogs.com/chuncn/archive/2008/10/09/1307321.html) 在说到这个问题的时候 ...
- [BZOJ4407]于神之怒加强版
BZOJ挂了... 先把程序放上来,如果A了在写题解吧. #include<cstdio> #include<algorithm> #define N 5000010 #def ...
- Java直接(堆外)内存使用详解
本篇主要讲解如何使用直接内存(堆外内存),并按照下面的步骤进行说明: 相关背景-->读写操作-->关键属性-->读写实践-->扩展-->参考说明 希望对想使用直接内存的朋 ...