pythonNet day04
多任务编程
意义:充分利用计算机的资源提高程序的运行效率
定义:通过应用程序利用计算机多个核心,达到同时执行多个任务的目的
实施方案: 多进程、多线程
并行:多个计算机核心并行的同时处理多个任务
并发:内核在多个任务间不断切换,达到好像内核在同时处理多个任务的运行效果
进程:程序在计算机中运行一次的过程
程序:是一个可执行文件,是静态的,占有磁盘,不占有计算机运行资源
进程:进程是一个动态的过程描述,占有CPU内存等计算机资源的,有一定的生命周期
* 同一个程序的不同执行过程是不同的进程,因为分配的计算机资源等均不同
父子进程 : 系统中每一个进程(除了系统初始化进程)都有唯一的父进程,可以有0个或多个子进
程。父子进程关系便于进程管理。
进程
CPU时间片:如果一个进程在某个时间点被计算机分配了内核,我们称为该进程在CPU时间片上。
PCB(进程控制块):存放进程消息的空间
进程ID(PID):进程在操作系统中的唯一编号,由系统自动分配
进程信息包括:进程PID,进程占有的内存位置,创建时间,创建用户. . . . . . . .
进程特征:
- 进程是操作系统分配计算机资源的最小单位
- 每一个进程都有自己单独的虚拟内存空间
- 进程间的执行相互独立,互不影响
进程的状态
1、三态
- 就绪态:进程具备执行条件,等待系统分配CPU
- 运行态:进程占有CPU处理器,处于运行状态
- 等待态:进程暂时不具备运行条件,需要阻塞等待,让出CPU
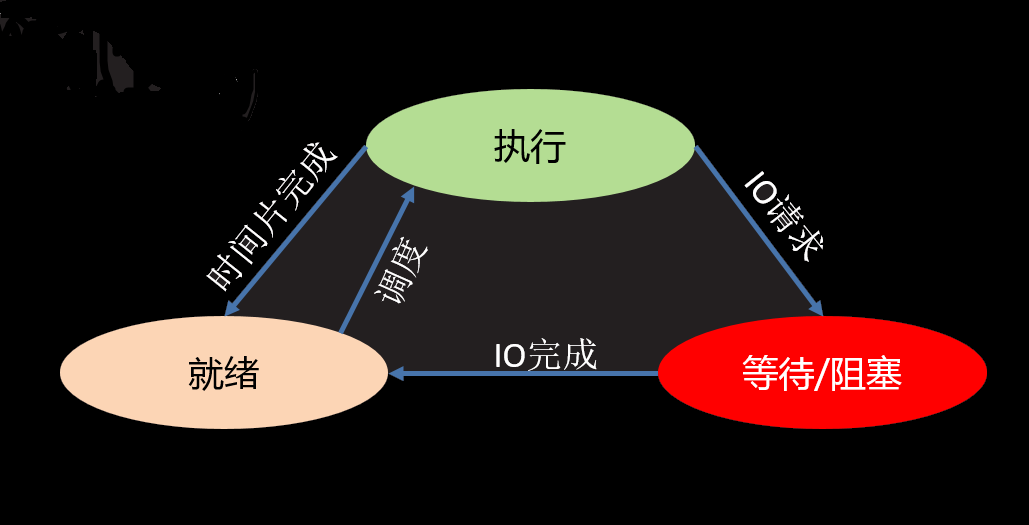
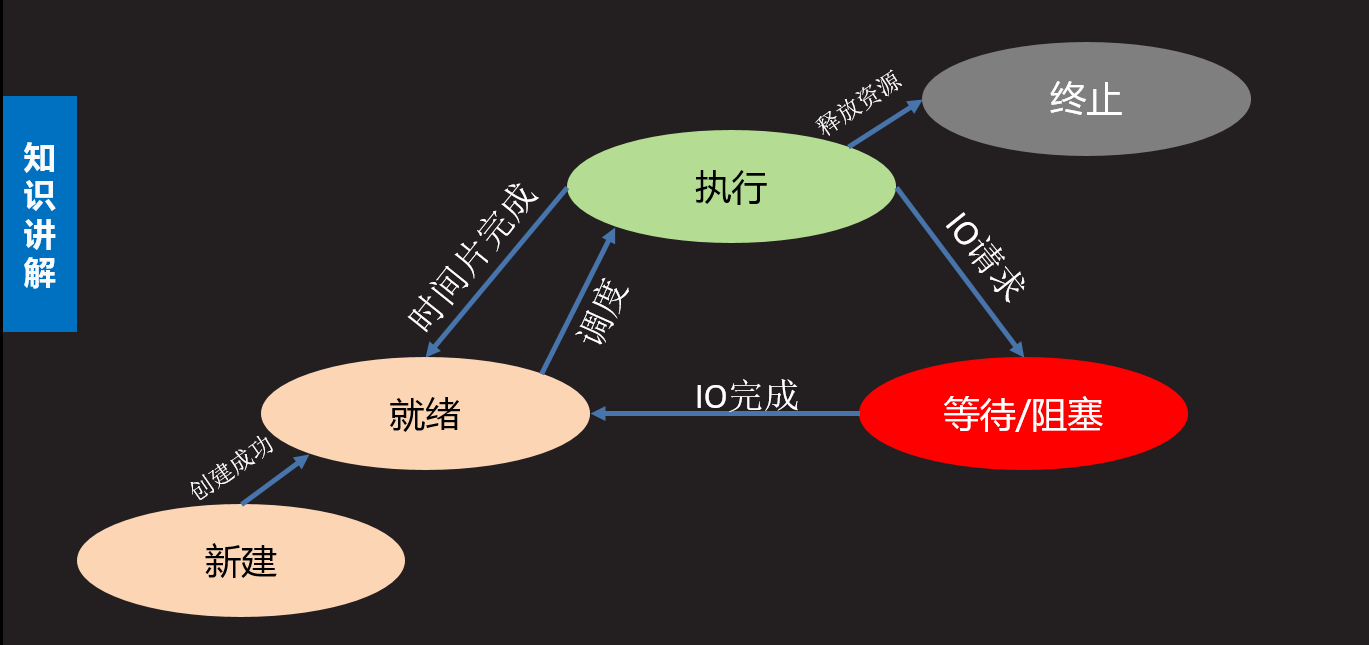
2、五态(增加新建态和终止态)
- 新建态:创建一个新的进程,获取资源的过程
- 终止态:进程结束释放资源的过程
查看进程树: pstree
查看父进程PID: ps -ajx
linux查看进程命令: ps -aux
有一列为STAT为进程的状态
D 等待态 (不可中断等待)(阻塞)
S 等待态 (可中断等待)(睡眠)
T 等待态 (暂停状态)
R 运行态 (就绪态运行态)
Z 僵尸态
+ 前台进程(能在终端显示出现象的)
< 高优先级
N 低优先级
l 有多线程的
s 会话组组长
os.fork创建进程
pid = os.fork()
功能:创建一个子进程
返回值:创建成功在原有的进程中返回子进程的PID,在子进程中返回0;创建失败返回一个负数
父子进程通常会根据fork返回值的差异选择执行不同的代码(使用if结构)
import os
from time import sleep pid = os.fork() if pid < 0:
print("创建进程失败") #子进程执行部分
elif pid == 0:
print("新进程创建成功") #父进程执行部分
else:
sleep(1)
print("原来的进程") print("程序执行完毕") # 新进程创建成功
# 原来的进程
# 程序执行完毕
- 子进程会复制父进程全部代码段(包括fork前的代码)但是子进程仅从fork的下一句开始执行
- 父进程不一定先执行(进程之间相互独立,互不影响)
- 父子进程各有自己的属性特征,比如:PID号PCB内存空间
- 父进程fork之前开辟的空间子进程同样拥有,但是进程之间相互独立,互不影响.
父子进程的变量域
import os
from time import sleep a = 1
pid = os.fork()
if pid < 0:
print("创建进程失败")
elif pid == 0:
print("子进程")
print("a = ",a)
a = 10000
print("a = ",a)
else:
sleep(1)
print("父进程")
print("parent a :",a) # a = 1 # 子进程
# a = 1
# a = 10000
# 父进程
# parent a : 1
进程ID和退出函数
os.getpid() 获取当前进程的PID号
返回值:返回PID号
os.getppid() 获取父类进程的进程号
返回值:返回PID号
import os pid = os.fork() if pid < 0:
print("Error")
elif pid == 0:
print("Child PID:", os.getpid()) #
print("Get parent PID:", os.getppid()) #
else:
print("Get child PID:", pid) #
print("Parent PID:", os.getpid()) #
os._exit(status) 退出进程
参数:进程的退出状态 整数
sys.exit([status]) 退出进程
参数:默认为0 整数则表示退出状态;符串则表示退出时打印内容
sys.exit([status])可以通过捕获SystemExit异常阻止退出
import os,sys # os._exit(0) # 退出进程
try:
sys.exit("退出")
except SystemExit as e:
print("退出原因:",e) # 退出原因: 退出
孤儿和僵尸
孤儿进程
父进程先于子进程退出,此时子进程就会变成孤儿进程
孤儿进程会被系统指定的进程收养,即系统进程会成为该孤儿进程新的父进程。孤儿进程退出时该父进程会处理退出状态
僵尸进程
子进程先与父进程退出,父进程没有处理子进程退出状态,此时子进程成为僵尸进程
僵尸进程已经结束,但是会滞留部分PCB信息在内存,大量的僵尸会消耗系统资源,应该尽量避免
如何避免僵尸进程的产生
父进程处理子进程退出状态
pid, status = os.wait()
功能:在父进程中阻塞等待处理子进程的退出
返回值: pid 退出的子进程的PID号
status 子进程的退出状态
import os, sys pid = os.fork() if pid < 0:
print("Error")
elif pid == 0:
print("Child process", os.getpid()) # Child process 27248
sys.exit(1)
else:
pid, status = os.wait() # 阻塞等待子进程退出
print("pid : ", pid) # pid : 27248
# 还原退出状态
print("status:", os.WEXITSTATUS(status)) # status: 1
while True:
pass
创建二级子进程
- 父进程创建子进程等待子进程退出
- 子进程创建二级子进程,然后马上退出
- 二级子进程成为孤儿,处理具体事件
import os
from time import sleep def fun1():
sleep(3)
print("第一件事情") def fun2():
sleep(4)
print("第二件事情") pid = os.fork() if pid < 0:
print("Create process error")
elif pid == 0: # 子进程
pid0 = os.fork() # 创建二级进程
if pid0 < 0:
print("创建二级进程失败")
elif pid0 == 0: # 二级子进程
fun2() # 做第二件事
else: # 二级进程
os._exit(0) # 二级进程退出
else:
os.wait()
fun1() # 做第一件事 # 第一件事情
# 第二件事情
通过信号处理子进程退出
原理: 子进程退出时会发送信号给父进程,如果父进程忽略子进程信号, 则系统就会自动处理子进程退出。
方法: 使用signal模块在父进程创建子进程前写如下语句 :
import signal
signal.signal(signal.SIGCHLD,signal.SIG_IGN)
特点 : 非阻塞,不会影响父进程运行。可以处理所有子进程退出
Multiprocessing创建进程
步骤:
- 需要将要做的事情封装成函数
- multiprocessing.Process创建进程,并绑定函数
- start启动进程
- join回收进程
p = multiprocessing.Process(target, [name], [args], [kwargs])
创建进程对象
参数:
- target : 要绑定的函数名
- name : 给进程起的名称 (默认Process-1)
- args: 元组 用来给target函数传参
- kwargs : 字典 用来给target函数键值传参
p.start()
功能 : 启动进程 自动运行terget绑定函数。此时进程被创建
p.join([timeout])
功能: 阻塞等待子进程退出,最后回收进程
参数: 超时时间
multiprocessing的注意事项:
- 使用multiprocessing创建进程子进程同样复制父进程的全部内存空间,之后有自己独立的空间,执行上互不干扰
- 如果不使用join回收可能会产生僵尸进程
- 一般父进程功能就是创建子进程回收子进程,所有事件交给子进程完成
- multiprocessing创建的子进程无法使用ptint
import multiprocessing as mp
from time import sleep
import os a = 1 def fun():
sleep(2)
print("子进程事件",os.getpid())
global a
a = 10000
print("a = ",a) p = mp.Process(target = fun) # 创建进程对象
p.start() # 启动进程
sleep(3)
print("这是父进程")
p.join() # 回收进程
print("parent a:",a) # 子进程事件 5434
# a = 10000
# 这是父进程
# parent a: 1 Process(target)
multiprocessing进程属性
p.name 进程名称
p.pid 对应子进程的PID号
p.is_alive() 查看子进程是否在生命周期
p.daemon 设置父子进程的退出关系
如果等于True则子进程会随父进程的退出而结束,就不用使用 join(),必须要求在start()前设置
进程池
引言:如果有大量的任务需要多进程完成,而任务周期又比较短且需要频繁创建。此时可能产生大量进程频繁创建销毁的情况,消耗计算机资源较大,这个时候就需要进程池技术
进程池的原理:创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件全都处理完毕统一销毁。增加进程的重复利用,降低资源消耗。
1.创建进程池,在池内放入适当数量的进程
from multiprocessing import Pool
Pool(processes) 创建进程池对象
- 参数:进程数量
- 返回 : 指定进程数量,默认根据系统自动判定
2.将事件封装函数,放入到进程池
pool.apply_async(fun,args,kwds) 将事件放入进程池执行
参数:
- fun 要执行的事件函数
- args 以元组为fun传参
- kwds 以字典为fun传参
返回值 :
- 返回一个事件对象 通过get()属性函数可以获取fun的返回值
3.关闭进程池
pool.close() 关闭进程池,无法再加入事件
4.回收进程
pool.join() 回收进程池
from multiprocessing import Pool
from time import sleep,ctime pool = Pool(4) # 创建进程池
# 进程池事件
def worker(msg):
sleep(2)
print(msg)
return ctime() # 向进程池添加执行事件
for i in range(4):
msg = "Hello %d"%i # r 代表func事件的一个对象
r = pool.apply_async(func=worker,args=(msg,)) pool.close() # 关闭进程池
pool.join() # 回收进程池 # Hello 3
# Hello 2
# Hello 0
# Hello 1
进程间通信(IPC)
由于进程间空间独立,资源无法共享,此时在进程间通信就需要专门的通信方法。
进程间通信方法 : 管道 消息队列 共享内存 信号信号量 套接字
管道通信(Pipe)
通信原理:在内存中开辟管道空间,生成管道操作对象,多个进程使用同一个管道对象进行读写即可实现通信
from multiprocessing import Pipe
fd1, fd2 = Pipe(duplex = True)
- 功能:创建管道
- 参数:默认表示双向管道,如果为False 表示单向管道
- 返回值:表示管道两端的读写对象;如果是双向管道均可读写;如果是单向管道fd1只读 fd2只写
fd.recv()
- 功能 : 从管道获取内容
- 返回值:获取到的数据,当管道为空则阻塞
fd.send(data)
- 功能: 向管道写入内容
- 参数: 要写入的数据
注意:
- multiprocessing中管道通信只能用于父子关系进程中
- 管道对象在父进程中创建,子进程通过父进程获取
from multiprocessing import Pipe, Process fd1, fd2 = Pipe() # 创建管道,默认双向管道
def fun1():
data = fd1.recv() # 从管道获取消息
print("管道2传给管道1的数据", data)
inpu = "跟你说句悄悄话"
fd1.send(inpu) def fun2():
fd2.send("肥水不流外人天")
data = fd2.recv()
print("管道1传给管道2的数据", data) p1 = Process(target=fun1)
P2 = Process(target=fun2) p1.start()
P2.start() p1.join()
P2.join()
# 管道2传给管道1的数据 肥水不流外人天
# 管道1传给管道2的数据 跟你说句悄悄话
消息队列
从内存中开辟队列结构空间,多个进程可以向队列投放消息,在取出来的时候按照先进先出顺序取出
q = Queue(maxsize = 0)
创建队列对象
- maxsize :默认表示系统自动分配队列空间;如果传入正整数则表示最多存放多少条消息
- 返回值 : 队列对象
q.put(data,[block,timeout])
向队列中存入消息
- data:存放消息(python数据类型)
- block:默认为True表示当前队列满的时候阻塞,设置为False则表示非阻塞
- timeout:当block为True表示超时时间
返回值:返回获取的消息
q.get([block,timeout])
从队列取出消息
- 参数:block 设置是否阻塞 False为非阻塞;timeout 超时检测
- 返回值: 返回获取到的内容
q.full() 判断队列是否为满
q.empty() 判断队列是否为空
q.qsize() 判断当前队列有多少消息
q.close() 关闭队列
from multiprocessing import Process, Queue
from time import sleep
from random import randint # 创建消息队列
q = Queue(3) # 请求进程
def request():
for i in range(2):
x = randint(0, 100)
y = randint(0, 100)
q.put((x, y)) # 处理进程
def handle():
while True:
sleep(1)
try:
x, y = q.get(timeout=2)
except:
break
else:
print("%d + %d = %d" % (x, y, x + y)) p1 = Process(target=request)
p2 = Process(target=handle)
p1.start()
p2.start()
p1.join()
p2.join()
# 12 + 61 = 73
# 69 + 48 = 117
共享内存
在内存中开辟一段空间,存储数据,对多个进程可见,每次写入共享内存中的数据会覆盖之前的内容,效率高,速度快
from multiprocessing import Value, Array
obj = Value(ctype,obj)
功能:开辟共享内存空间
参数:ctype 字符串 要转变的c的数据类型,对比类型对照表
obj 共享内存的初始化数据
返回:共享内存对象
from multiprocessing import Process,Value
import time
from random import randint # 创建共享内存
money = Value('i', 5000) # 修改共享内存
def man():
for i in range(30):
time.sleep(0.2)
money.value += randint(1, 1000) def girl():
for i in range(30):
time.sleep(0.15)
money.value -= randint(100, 800) m = Process(target=man)
g = Process(target=girl)
m.start()
g.start()
m.join()
g.join() print("一月余额:", money.value) # 获取共享内存值
# 一月余额: 4264
obj = Array(ctype,obj)
功能:开辟共享内存
参数:ctype 要转化的c的类型
obj 要存入共享的数据
如果是列表 将列表存入共享内存,要求数据类型一致
如果是正整数 表示开辟几个数据空间
from multiprocessing import Process, Array # 创建共享内存
# shm = Array('i',[1,2,3])
# shm = Array('i',3) # 表示开辟三个空间的列表
shm = Array('c',b"hello") #字节串 def fun():
# 共享内存对象可迭代
for i in shm:
print(i)
shm[0] = b'H' p = Process(target=fun)
p.start()
p.join() for i in shm: # 子进程修改,父进程中也跟着修改
print(i) print(shm.value) # 打印字节串 b'Hello'
信号量(信号灯集)
通信原理:给定一个数量对多个进程可见。多个进程都可以操作该数量增减,并根据数量值决定自己的行为。
from multiprocessing import Semaphore
sem = Semaphore(num)
创建信号量对象
- 参数 : 信号量的初始值
- 返回值 : 信号量对象
sem.acquire() 将信号量减1 当信号量为0时阻塞
sem.release() 将信号量加1
sem.get_value() 获取信号量数量
from multiprocessing import Process, Semaphore sem = Semaphore(3) # 创建信号量,最多允许3个任务同时执行 def rnewu():
sem.acquire() # 每执行一次减少一个信号量
print("执行任务.....执行完成")
sem.release() # 执行完成后增加信号量 for i in range(3): # 有3个人想要执行任务
p = Process(target=rnewu)
p.start()
p.join()
pythonNet day04的更多相关文章
- python学习菜单
一.python简介 二.python字符串 三.列表 四.集合.元组.字典 五.函数 六.python 模块 七.python 高阶函数 八.python 装饰器 九.python 迭代器与生成器 ...
- Spring day04笔记(SVN讲解和回顾昨天知识)
spring day03回顾 事务管理 基于xml配置 1.配置事务管理器 jdbc:DataSourceTransactionManager hibernate:HibernateTransacti ...
- day04 Java Web 开发入门
day04 Java Web 开发入门 1. web 开发相关介绍 2. web 服务器 3. Tomcat服务器启动的问题 4. Tomcat目录结构 5. Web应用程序(虚拟目录映射,缺省web ...
- python day04笔记总结
2019.4.1 S21 day04笔记总结 昨日内容补充 1.解释器/编译器 1.解释型语言.编译型语言 2.解释型:写完代码后提交给解释器,解释器将代码一行行执行.(边接收边解释/实时解释) 常用 ...
- Python基础(函数部分)-day04
写在前面 上课第四天,打卡: 加勒比海盗今天上映:端午节公司发的粽子很有范! 一.函数的基本概念 - 函数是什么? 函数,就是一个'锤子',一个具有特定功能的'锤子',使用者可以在适当的时候使用这个 ...
- Python之路PythonNet,第四篇,网络4
pythonnet 网络4 select 支持水平触发 poll 支持水平触发 epoll epoll 也是一种IO多路复用的方式,效率比select和poll 要高一点: epol ...
- Python之路PythonNet,第三篇,网络3
pythonnet 网络3 udp 通信 recvfrom sendtofork 多进程并发threading 多线程并发socketserver 系统模块 套接字的属性 setsockopt g ...
- Python之路PythonNet,第二篇,网络2
pythonnet 网络2 问题: 什么是七层模型tcp 和udp区别三次握手和四次挥手************************************************** tcp ...
- Python之路PythonNet,第一篇,网络1
pythonnet 网络1 ARPAnet(互联网雏形)---> 民用 ISO(国际标准化组织)--->网络体系结构标准 OSI模型 OSI : 网络信息传输比较复杂需要很多功能协同 ...
随机推荐
- 创建 shiny 应用程序
R 本身是一个优秀的数据分析和数据可视化平台.然而,我们通常不会将 R 和分析脚本提供给客户,让客户自己运行.数据分析的结果不仅可以在 HTML 网页.PDF 文档或 Word 文档中显示,还可以呈现 ...
- 《图解Http》 2-6章: 基础,报文,状态码,首部。
HTTP协议和Cookie 是stateless协议,自身不对请求和响应之间的通信状态进行保存.但随着技术发展,为了实现保存状态的功能,引入了Cookie技术. Cookie在请求和响应报文中写入信息 ...
- Android 之低版本高版本实现沉浸式状态栏
沉浸式状态栏确切的说应该叫做透明状态栏.一般情况下,状态栏的底色都为黑色,而沉浸式状态栏则是把状态栏设置为透明或者半透明. 沉浸式状态栏是从android Kitkat(Android 4.4)开始出 ...
- 理解 Ruby Symbol (Ruby中的冒号)
http://blog.csdn.net/besfanfei/article/details/7966850 一直不明白:的作用 直到看到这篇文章 豁然开朗 处理符号相比字符串,占用更少的资源
- jstack工具介绍
一.使用场景 当一个java应用CPU的使用比较高或者到达100%以上的时候,需要分析代码哪里有问题.这时候可以使用jstack命令 二.怎么使用 先使用命令ps –ef |grep keyword ...
- angular学习笔记系列一
首先我们要明确一点,angular在web应用的角色,在传统的多页面web应用程序中,服务器根据输出数据和html模板渲染好页面所需的html输出到页面(所谓的服务器装配程序),随着单页面应用程序和a ...
- Sonar在ant工程中读取单元测试和覆盖率报告
虽然sonar支持ant工程的构建,但目前最大的不足是无法在分析过程中产生单元测试和覆盖率报告,这样在sonar面板上覆盖率板块就始终没有数据.但幸运的是,sonar可以读取已经生成好的报告,让报告的 ...
- idea如何热部署(转)
IntelliJ IDEA 怎么热部署,每次修改java文件就得重启tomcat 原文链接:http://blog.csdn.net/dandandeshangni/article/details/ ...
- window和Linux下Redis的安装及运行
Window篇 Redis的官方目前公开的版本分为三个类别Stable.Beta和Unstable.这些版本一般只是针对Linux.Unix内核的系统,虽然官方的不支持Window系统,但是微软开源 ...
- python多任务的导包问题
多线程的使用: import threading def func(x): print(x) t= threading.Thread(target=func,args=(12,)) # 线程启动 t. ...