万字长文:ELK(V7)部署与架构分析
ELK(7版本)部署与架构分析
1、ELK的背景介绍与应用场景
在项目应用运行的过程中,往往会产生大量的日志,我们往往需要根据日志来定位分析我们的服务器项目运行情况与BUG产生位置。一般情况下直接在日志文件中tailf、 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量过大、文本搜索太慢、如何多维度查询。这就需要对服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统往往是一种分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,所以构建一套集中式日志系统,可以提高定位问题的效率。 一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据,服务日志与系统日志。
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据,持久化数据。
- 分析-可以支持 UI 分析,界面化定制查看日志操作。
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。是目前主流的一种日志系统。
2、ELK简介:
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。其中后来新增了一个FileBeat。
即ELK主要由Elasticsearch(搜索)、Logstash(收集与分析)和Kibana(展示)三部分组件组成;
其中各组件说明如下:
Filebeat:轻量级数据收集引擎。早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。如果用它来对服务器进行日志收集,将加重服务器的负载。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计,所以filebeat作为一个轻量级的日志收集处理工具(Agent),它可以用来替代Logstash,由于其占用资源少,所以更适合于在各个服务器上搜集日志后传输给Logstash,这也是官方推荐的一种做法。【收集日志】
Logstash:数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。【对日志进行过滤、分析】
Elasticsearch:分布式搜索引擎。是基于Lucene的开源分布式搜索服务器,具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。【搜集、分析、存储数据】
Kibana:可视化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。【图形化展示日志】
结合以上,常见的日志系统架构图如下:
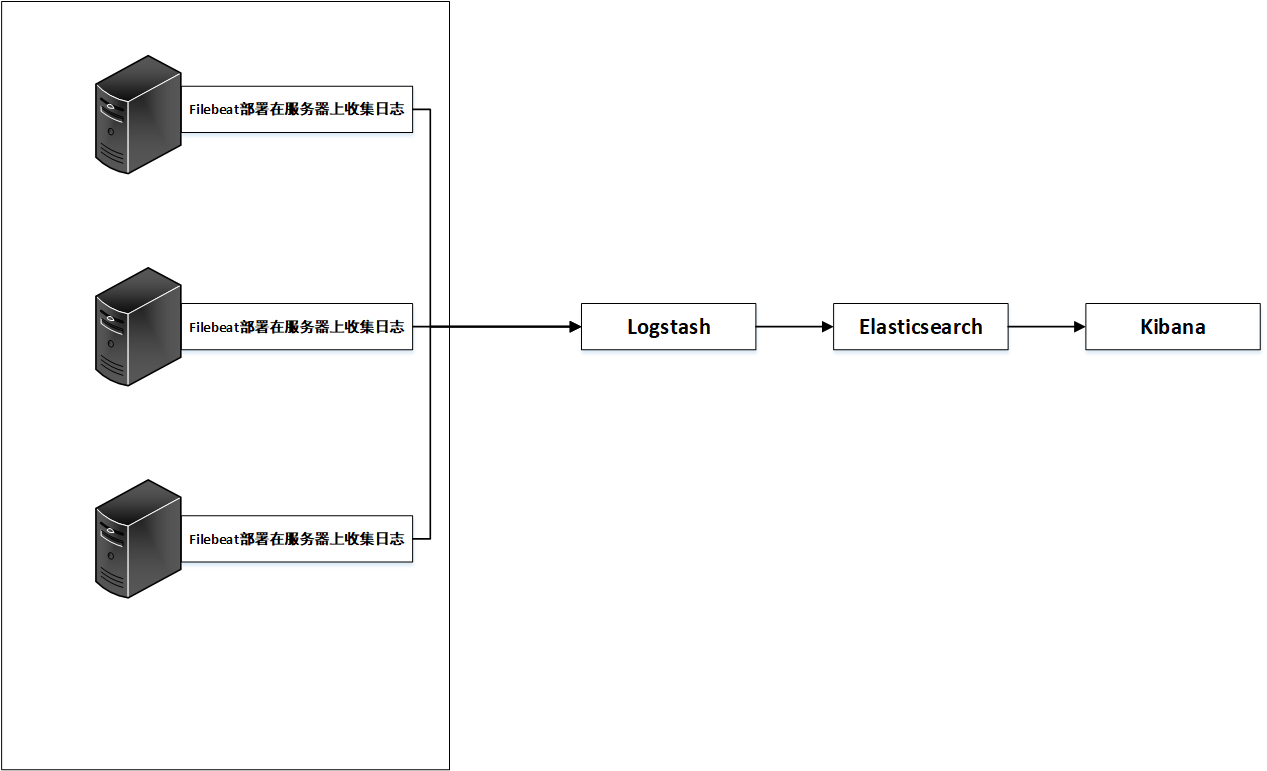
如上图所示,日志文件分别由filebeat在服务器上进行收集,收集的日志文件汇总到logstash上并对文件数据进行过滤、分析、丰富、统一格式等操作,然后发送到Elasticsearch,进一步对日志进行结构化检索和分析,并存储下来,最后由kibana进行展示。
这只是日志系统的一种最初级结构,生产环境中需要对此结构进行进一步的优化。
3、ELK系统的部署(配置将在生产环境架构中进行说明)
环境:CentOS7.5部署ELK 7版本
准备工作: CentOS7.5
elasticsearch7, logstash7, kibana7
关闭防火墙和SELinux并更新yum源(非必须):yum -y update
本次分布式部署的ELK版本为2019年五月份左右最新发布的版本,更新了许多新特性,后面将详细说明。在安装上面本次极大简化了安装步骤,可以源码,组件安装,本次采用YUM+插件docker安装,能达到相同的效果。
3.1 Filebeat安装与配置
#!/bin/bash
# 安装Filebeat
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat >/etc/yum.repos.d/elk-elasticsearch.repo<<EOF
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum -y install filebeat
systemctl enable filebeat
systemctl start filebeat
3.2 整套软件:elasticsearch,Logstash,Kibana和Filebeat的安装(分开部署请分别安装三个组件)
1. java环境(7版本自带Java)
yum -y install java
2. 导入elasticsearch PGP key文件
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
3. 配置yum源
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
4. yum -y install elasticsearch logstash kibana
##########关于安装环境,也可以参照以下二种方式,也比较简便#################
----即通过RPM包的方式,此处给出Filebeat的方式,其他组件雷同
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.0-x86_64.rpm
sudo rpm -vi filebeat-7.0.0-x86_64.rpm
----Logstash实例另一种方式(优先采用)
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.0.0.rpm
yum install -y java
yum install -y logstash-7.0.0.rpm
服务启动前必看,由于配置文件在下一章节给出,此处是前提准备,等配置完成后再启动
3.3 关于elasticsearch需要重点关注的地方
1.elasticsearch在分词方面,需要添加中文分词的插件。在其安装代码的plugins目录,即/usr/share/elasticsearch/plugins,需要增加中文分词插件。
[root@192-168-108-35 plugins]# ll
total 3192
[root@192-168-108-35 plugins]# pwd
/usr/share/elasticsearch/plugins
[root@192-168-108-35 plugins]# wget https://codeload.github.com/medcl/elasticsearch-analysis-ik/tar.gz/v7.0.0
下载后重启时需要删除插件源文件,否则报错如下:
Caused by: java.nio.file.FileSystemException: /usr/share/elasticsearch/plugins/v7.0.0/plugin-descriptor.properties: Not a directory
所以安装完成后必须删除源文件v7.0.0
2.elasticsearch服务的启动问题与前提准备
-- 首先在安装完毕后会生成很多文件,包括配置文件日志文件等等,下面几个是最主要的配置文件路径
/etc/elasticsearch/elasticsearch.yml # els的配置文件
/etc/elasticsearch/jvm.options # JVM相关的配置,内存大小等等
/etc/elasticsearch/log4j2.properties # 日志系统定义
/usr/share/elasticsearch # elasticsearch 默认安装目录
/var/lib/elasticsearch # 数据的默认存放位置
-- 创建用于存放数据与日志的目录
数据文件会随着系统的运行飞速增长,所以默认的日志文件与数据文件的路径不能满足我们的需求,那么手动创建日志与数据文件路径。
mkdir -p /data/elkdata
mkdir -p /data/elklogs
-- JVM配置 (7.0版本针对此做出优化,可以基本保障溢出问题,但最好设置一下)
由于Elasticsearch是Java开发的,所以可以通过/etc/elasticsearch/jvm.options配置文件来设定JVM的相关设定。如果没有特殊需求按默认即可。
不过其中还是有两项最重要的-Xmx1g与-Xms1gJVM的最大最小内存。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身。
vim /etc/elasticsearch/jvm.options # JVM最大、最小使用内存
-Xms1g
-Xmx1g
-- 使用ROOT账户执行命令
elasticsearch的相关配置已经完成,下面需要启动elasticsearch集群。但是由于安全的考虑,elasticsearch不允许使用root用户来启动,所以需要创建一个新的用户,并为这个账户赋予相应的权限来启动elasticsearch集群。
创建ES运行用户
# 创建用户组 group add elk
# 创建用户并添加至用户组 useradd elk -g elk
# (可选)更改用户密码
passwd elasticsearch
同时修改ES目录权限, 以下操作都是为了赋予es用户操作权限,
-- 安装源码文件目录
[root@192-168-108-35 share]# chown -R elk :elk /usr/share/elasticsearch/
[root@192-168-108-35 share]# chown -R elk :elk /var/log/elasticsearch/
[root@192-168-108-35 share]# chown -R elk :elk /data
-- 运行常见的报错信息
[1]文件数目不足
# 修改系统配置文件属性
# vim /etc/security/limits.conf 添加
elk soft memlock unlimited
elk hard memlock unlimited
elk soft nofile 65536
elk hard nofile 131072
退出用户重新登录,使配置生效
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改
3. 启动elasticsearch服务
前台启动服务
# 需切换为es用户
su elk
# 启动服务(当前的路径为:/usr/share/elasticsearch/)
./bin/elasticsearch
后台运行ES
可以加入-p 命令 让es在后台运行, -p 参数 记录进程ID为一个文件
# 设置后台启动
./bin/elasticsearch -p ./elasticsearch-pid -d
一般情况下,直接执行一下命令即可
./bin/elasticsearch -d
结束进程
# 查看运行的pid,并查杀 cat /tmp/elasticsearch-pid && echo
kill -SIGTERM {pid}
# 暴力结束进程(另一种方式)
kill -9 `ps -ef |grep elasticsearch|awk '{print $2}' `
验证一下服务是否正常
curl -i "http://192.168.60.200:9200"
4.安装elasticsearch-head插件(支持前端界面查看数据)
安装docker镜像或者通过github下载elasticsearch-head项目都是可以的,1或者2两种方式选择一种安装使用即可
【1】使用docker的集成好的elasticsearch-head
# docker run -p 9100:9100 mobz/elasticsearch-head:5
docker容器下载成功并启动以后,运行浏览器打开http://localhost:9100/
【2】使用git安装elasticsearch-head
# yum install -y npm
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
检查端口是否起来
netstat -antp |grep 9100
浏览器访问测试是否正常
http://IP:9100/
【注意】由于elasticsearch-head:5镜像对elasticsearch的7版本适配性未经检测。这里也推荐推荐另外一个镜像lmenezes/cerebro,下载后执行
docker run -d -p 9000:9000 lmenezes/cerebro
就可以在9000端口查看了。

最后,filebeat logstash kibana可以在配置文件后,正常启动,如果需要切换用户的话,也可以参照上面。本次这三个组件全部默认用root用户启动。由于分开部署,与ES互不影响。
附:kafka三节点集群搭建
环境准备
1.zookeeper集群环境,本次采用Kafka自带的Zookeeper环境。
kafka是依赖于zookeeper注册中心的一款分布式消息对列,所以需要有zookeeper单机或者集群环境。
2.三台服务器:
192.168.108.200 ELK-kafka-cluster
192.168.108.165 ELK-kafka-salve1
192.168.108.103 ELK-kafka-salve2
3.下载kafka安装包
在 http://kafka.apache.org/downloads 中下载,目前最新版本的kafka已经到2.2.0,这里下载的是kafka_2.11-2.2.0.tgz
安装kafka集群
1.上传压缩包到三台服务器解压缩到/opt/目录下
tar -zxvf kafka_2.11-2.2.0.tgz -C /opt/
ls -s kafka_2.11-2.2.0 kafka
2.修改 server.properties (/opt/kafka/config目录下)
############################# Server Basics #############################
######################## Socket Server Settings ########################
listeners=PLAINTEXT://192.168.108.200:9092
advertised.listeners=PLAINTEXT://192.168.108.200:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
log.dirs=/var/log/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
######################## Internal Topic Settings #########################
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
######################### Log Retention Policy ########################
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
zookeeper.connect=192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
delete.topic.enable=true
######################## Group Coordinator Settings ##########################
group.initial.rebalance.delay.ms=0
3.拷贝两份到192.168.108.165和192.168.108.103
[root@192.168.108.165 config]# cat server.properties
listeners=PLAINTEXT://192.168.108.165:9092
advertised.listeners=PLAINTEXT://192.168.108.165:9092
[root@k8s-n3 config]# cat server.properties
listeners=PLAINTEXT://192.168.108.103:9092
advertised.listeners=PLAINTEXT://192.168.108.103:9092
然后添加环境变量 在/etc/profile 中添加
export ZOOKEEPER_HOME=/opt/kafka
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile 重载生效
4.修改zookeeper.properties:
1、设置连接参数,添加如下配置
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
2、设置broker Id的服务地址
server.0=192.168.108.200:2888:3888
server.1=192.168.108.165:2888:3888
server.2=192.168.108.103:2888:3888
总结就在Kafka源码目录的/kafka/config/zookeeper.properties文件设置如下
- dataDir=/opt/zookeeper # 这时需要在/opt/zookeeper文件夹下,新建myid文件,把broker.id填写进去,本次本节点为0。
- # the port at which the clients will connect
- clientPort=2181
- # disable the per-ip limit on the number of connections since this is a non-production config
- maxClientCnxns=100
- tickTime=2000
- initLimit=10
- syncLimit=5
- server.0=192.168.108.200:2888:3888
- server.1=192.168.108.165:2888:3888
- server.2=192.168.108.103:2888:3888
然后在zookeeper数据目录添加id配置(dataDir=/opt/zookeeper)
在zookeeper.properties的数据目录中创建myid文件
在各台服务的zookeeper数据目录添加myid文件,写入服务broker.id属性值,如这里的目录是/usr/local/zookeeper/data
第一台broker.id为0的服务到该目录下执行:echo 0 > myid
[root@192-168-108-165 kafka]# cd /opt/zookeeper/
[root@192-168-108-165 zookeeper]# ls
myid version-2
[root@192-168-108-165 zookeeper]# cat myid
1
[root@192-168-108-165 zookeeper]#
集群启动
集群启动:cd /opt/kafka
先分别启动zookeeper
kafka使用到了zookeeper,因此你要首先启动一个zookeeper服务,如果你没有zookeeper服务。kafka中打包好了一个简洁版的单节点zookeeper实例。
kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
前台启动:bin/zookeeper-server-start.sh config/zookeeper.properties
[root@192-168-108-200 ~]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 5197 root 98u IPv6 527171 0t0 TCP *:eforward (LISTEN)
可以看到已经启动
后台启动:bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
再分别启动kafka
前台启动:bin/kafka-server-start.sh config/server.properties
[root@192-168-108-200 ~]# lsof -i:9092
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 5519 root 157u IPv6 528511 0t0 TCP 192-168-108-200:XmlIpcRegSvc (LISTEN)
java 5519 root 167u IPv6 528515 0t0 TCP 192-168-108-200:XmlIpcRegSvc->192.168.108.191:56656 (ESTABLISHED)
java 5519 root 169u IPv6 528516 0t0 TCP 192-168-108-200:XmlIpcRegSvc->192.168.108.187:49368 (ESTABLISHED)
java 5519 root 176u IPv6 528096 0t0 TCP 192-168-108-200:48062->192-168-108-200:XmlIpcRegSvc (ESTABLISHED)
java 5519 root 177u IPv6 528518 0t0 TCP 192-168-108-200:XmlIpcRegSvc->192-168-108-200:48062 (ESTABLISHED)
java 5519 root 178u IPv6 528097 0t0 TCP 192-168-108-200:XmlIpcRegSvc->192.168.108.187:49370 (ESTABLISHED)
后台启动:bin/kafka-server-start.sh -daemon config/server.properties
服务启动脚本
cd /opt/kafka
kill -9 `ps -ef |grep kafka|awk '{print $2}' `
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
bin/kafka-server-start.sh -daemon config/server.properties
Zookeeper+Kafka集群测试
/opt/kafka/bin
1.创建topic:
kafka-topics.sh --create --zookeeper 192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 --replication-factor 3 --partitions 3 --topic test
2.显示topic
kafka-topics.sh --describe --zookeeper 192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 --topic test
[root@192-168-108-200 bin]# kafka-topics.sh --describe --zookeeper 192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 --topic tyun
Topic:tyun PartitionCount:3 ReplicationFactor:3 Configs:
Topic: tyun Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: tyun Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: tyun Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
PartitionCount:partition个数
ReplicationFactor:副本个数
Partition:partition编号,从0开始递增
Leader:当前partition起作用的broker.id
Replicas: 当前副本数据所在的broker.id,是一个列表,排在最前面的其作用
Isr:当前kakfa集群中可用的broker.id列表

3.列出topic
kafka-topics.sh --list --zookeeper 192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181
test
创建 producer(生产者);
kafka-console-producer.sh --broker-list 192.168.108.200:9092 --topic test
hello
创建 consumer(消费者)
kafka-console-consumer.sh --bootstrap-server 192.168.108.200:9092 --topic test --from-beginning
hello
4.查看写入kafka集群中的消息(重要命令,判断日志是否写入Kafka的重要依据)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.108.200:9092 --topic tiops --from-beginning
5.删除 Topic----命令标记删除后,再次删除对应的数据目录
bin/kafka-topics.sh --delete --zookeeper master:2181,slave1:2181,slave2:2181 --topic topic_name
若 delete.topic.enable=true
直接彻底删除该 Topic。
若 delete.topic.enable=false
如果当前 Topic 没有使用过即没有传输过信息:可以彻底删除。
如果当前 Topic 有使用过即有过传输过信息:并没有真正删除 Topic 只是把这个 Topic 标记为删除(marked for deletion),重启 Kafka Server 后删除。
注:delete.topic.enable=true 配置信息位于配置文件 config/server.properties 中(较新的版本中无显式配置,默认为 true)。
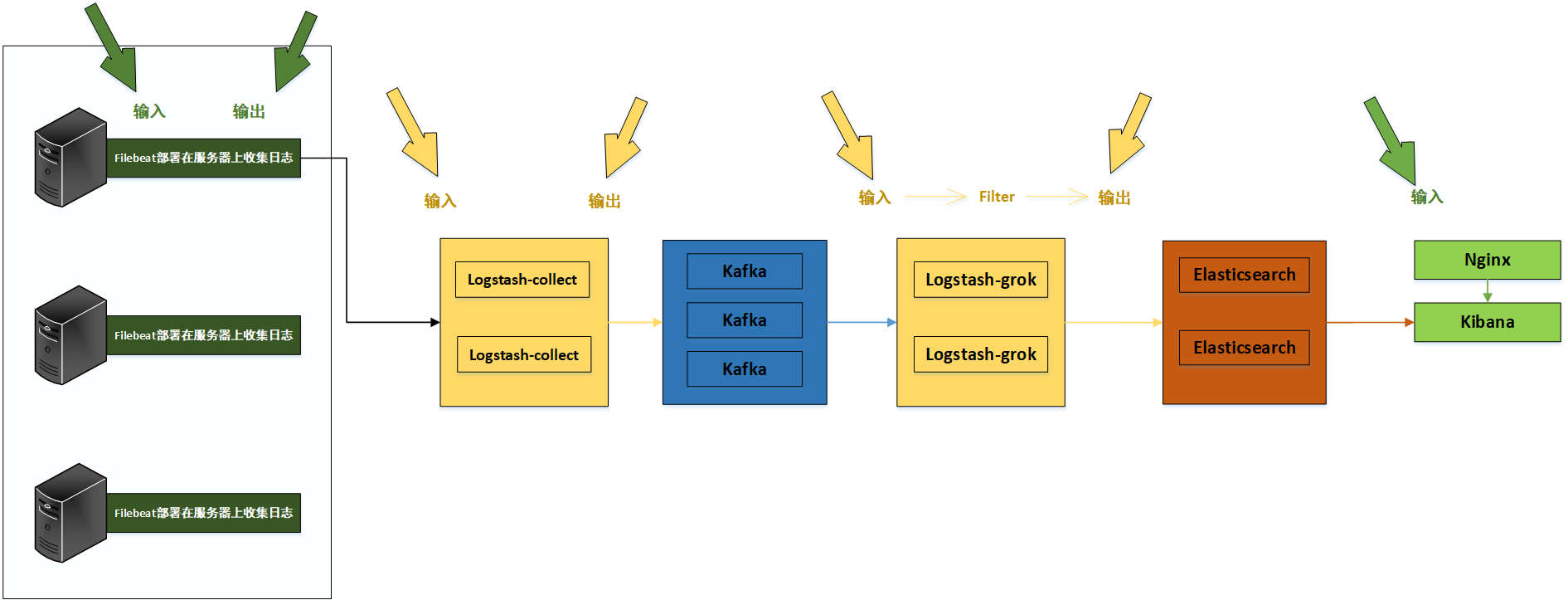
4. 日志系统架构解析

整个系统一共含有10台主机(filebeat部署在客户端,不计算在内),其中Logstash有四台,Elasticsearch有二台,Kafka集群三台,kibana一台并配置Nginx代理。
架构解释:
(1)首先用户通过nginx代理访问ELK日志统计平台,这里的Nginx可以设置界面密码。
(2)Nginx将请求转发到kibana
(3)kibana到Elasticsearch中去获取数据,这里的Elasticsearch是两台做的集群,日志数据会随机保存在任意一台Elasticsearch服务器。
(4)Logstash1从Kafka中取出数据并发送到Elasticsearch中。
(5)Kafka服务器做日志数据的持久化保存,避免web服务器日志量过大的时候造成的数据收集与保存不一致而导致日志丢失,其中Kafka可以做集群,然后再由Logstash服务器从Kafka持续的取出数据。
(6)logstash2从Filebeat取出的日志信息,并放入Kafka中进行保存。
(7)Filebeat在客户端进行日志的收集。
注1:【Kafka的加入原因与作用】
整个架构加入Kafka,是为了让整个系统更好的分层,Kafka作为一个消息流处理与持久化存储软件,能够帮助我们在主节点上屏蔽掉多个从节点之间不同日志文件的差异,负责管理日志端(从节点)的人可以专注于向 Kafka里生产数据,而负责数据分析聚合端的人则可以专注于从 Kafka内消费数据。所以部署时要把Kafka加进去。
而且使用Kafka进行日志传输的原因还在于其有数据缓存的能力,并且它的数据可重复消费,Kafka本身具有高可用性,能够很好的防止数据丢失,它的吞吐量相对来说比较好并且使用广泛。可以有效防止日志丢失和防止logsthash挂掉。综合来说:它均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,
注2:【双层的Logstash作用】
这里为什么要在Kafka前面增加二台logstash呢?是因为在大量的日志数据写入时,容易导致数据的丢失和混乱,为了解决这一问题,增加二台logstash可以通过类型进行汇总分类,降低数据传输的臃肿。
如果只有一层的Logstash,它将处理来自不同客户端Filebeat收集的日志信息汇总,并且进行处理分析,在一定程度上会造成在大规模日志数据下信息的处理混乱,并严重加深负载,所以有二层的结构进行负载均衡处理,并且职责分工,一层汇聚简单分流,一层分析过滤处理信息,并且内层都有二台Logstash来保障服务的高可用性,以此提升整个架构的稳定性。
接下来分别说明原理与各个组件之间的交互(配置文件)。
1】Filebeat与Logstash-collect连接配置
这里为了方便记忆,把此处的Logstash称为Logstash-collect,首先看Filebeat的配置文件:
其中,filebeat配置输出到logstash:5044端口,在logstash上启动5044端口作为logstash与filebeat的通信agent,而logstash本身服务起在9600端口
[root@192-168-108-191 logstash]# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 :::5044 :::*
LISTEN 0 50 ::ffff:192.168.108.191:9600 :::*
vim /etc/filebeat/filebeat.yml # 对几个重要配置进行设置如下
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
- /var/log/tiops/**/*.log # 即tiops平台的所有日志位置, 指定数据的输入路径为/tiops/**/*.log结尾的所有文件,注意/tiops/子目录下的日志不会被读取,孙子目录下的日志可以
#- c:\programdata\elasticsearch\logs\*
fields:
service: filebeat
multiline: # 多行日志合并为一行,适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。
pattern: ‘^\[‘
negate: true
match: after
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# 删除以DBG开头的行:
exclude_lines: ['^DBG']
# filebeat的日志可发送到logstash、elasticsearch、kibana,选择一个即可,本次默认选择logstash,其他二个可以注释
output.logstash:
# The Logstash hosts
hosts: ["192.168.108.191:5044", "192.168.108.87:5044"] # 发往二台Logstash-collect
loadbalance: true
worker: 2
#output.elasticsearch:
#hosts: ["http://192.168.108.35:9200"]
#username: "elk"
#password: ""
#setup.kibana:
#host: "192.168.108.182:5601"
注1:【Filebeat与Logstash-collect的日志消息流转】
注意事项:Logstash-collect怎么接收到Filebeat发送的消息,并再次发向下一级呢?
不仅仅配置发往二台Logstash-collect的ip地址加端口,还要注意fields字段,可以理解为是一个Key,当Logstash-collect收到多个Key时,它可以选择其中一个或者多个Key来进行下一级发送,达到日志消息的转发。
在使用了6.2.3版本的ELK以后,如果使用if [type]配置,则匹配不到在filebeat里面使用document_type定义的字符串。因为6.0版本以上已经取消了document_type的定义。如果要实现以上的配置只能使用如下配置:
fields:
service: filebeat
service : filebeat都是自己定义的,定义完成后使用Logstash的if 判断,条件为if [fields][service] == "filebeat".就可以了,具体可以看下面的转发策略。
注2:【Filebeat负载平衡主机的输出】
这里还有一点需要说明一下,就是关于Filebeat与Logstash-collect连接的负载均衡设置。
logstash是一个无状态的流处理软件。logstash怎么集群配置只能横向扩展,然后自己用配置管理工具分发,因为他们内部并没有交流的。
Filebeat提供配置选项,可以使用它来调整负载平衡时发送消息到多个主机。要启用负载均衡,您指定loadbalance的值为true。
output.logstash:
# The Logstash hosts
hosts: ["192.168.108.191:5044", "192.168.108.87:5044"] # 发往二台Logstash-collect
loadbalance: true
worker: 2
loadbalance: false # 消息只是往一个logstash里发,如果这个logstash挂了,就会自动将数据发到另一个logstash中。(主备模式)
loadbalance: true # 如果为true,则将数据均分到各个logstash中,挂了就不发了,往存活的logstash里面发送。
即logstash地址如果为一个列表,如果loadbalance开启,则负载到里表中的服务器,当一个logstash服务器不可达,事件将被分发到可到达的logstash服务器(双活模式)
loadbalance选项可供 Redis,Logstash, Elasticsearch输出。Kafka的输出可以在其自身内部处理负载平衡。
同时每个主机负载平衡器还支持多个workers。默认是1。如果你增加workers的数量, 将使用额外的网络连接。workers参与负载平衡的总数=主机数量*workers。
在这个小节,配置总体结构,与日志数据流向如下图:

2】Logstash-collect与Kafka连接配置
首先看/etc/logstash/logstash.yml文件,作为Logstash-collect的公共配置文件,我们需要做一下的更改:
vim /etc/logstash/logstash.yml
- path.data: /var/lib/logstash #数据存放路径
- path.config: /etc/logstash/conf.d #配置文件的读取路径
- path.logs: /var/log/logstash #日志文件的保存路径
- pipeline.workers: 2 # 默认为CPU的核数
- http.host: "192.168.108.186"
- http.port: 9600-9700 # logstash will pick up the first available ports
注意上面配置文件的读取路径 /etc/logstash/conf.d,在这个文件夹里面,我们可以设置Logstash的输入输出。logstash支持把配置写入文件/etc/logstash/conf.d/xxx.conf,然后通过读取配置文件来采集数据。
logstash收集日志基本流程: input–>codec–>filter–>codec–>output ,所以配置文件可以设置输入输出与过滤的基本格式如下:(这里暂时忽略filter,因为这一层的Logstash主要汇聚数据,暂不分析匹配)
关于codec => json # json处理
logstash最终会把数据封装成json类型,默认会添加@timestamp时间字段、host主机字段、type字段。原消息数据会整个封装进message字段。如果数据处理过程中,用户解析添加了多个字段,则最终结果又会多出多个字段。也可以在数据处理过程中移除多个字段,总之,logstash最终输出的数据格式是json格式。所以数据经过Logstash会增加额外的字段,可以选择过滤。
Logstash主要由 input,filter,output三个组件去完成采集数据。
input {
指定输入
}
filter {
}
output {
指定输出
}
解释说明如下:
input
input组件负责读取数据,可以采用file插件读取本地文本文件,stdin插件读取标准输入数据,tcp插件读取网络数据,log4j插件读取log4j发送过来的数据等等。本次用 beats插件读取Filebeat发送过来的日志消息。
filter
filter插件负责过滤解析input读取的数据,可以用grok插件正则解析数据,date插件解析日期,json插件解析json等等。
output
output插件负责将filter处理过的数据输出。可以用elasticsearch插件输出到es,redis插件输出到redis,stdout插件标准输出,kafka插件输出到kafka等等
在实际的Tiops平台日志处理流程中,配置如下:
二个Logstash-collect均采用此相同的配置
在/etc/logstash/conf.d目录下,创建filebeat-kafka.conf文件,内容如下:
input {
beats {
port => 5044 # logstash上启动5044端口作为logstash与filebeat的通信agent
codec => json # json处理
}
}
#此处附加Redis作为缓存消息的配置,本次采用Kafka,所以此部分暂时注释
#output {
# if [fields][service] == "filebeat"{
# redis {
# data_type => "list"
# host => "192.168.108.200"
# db => "0"
# port => "6379"
# key => "tiops-tcmp"
# }
# }
#}
output {
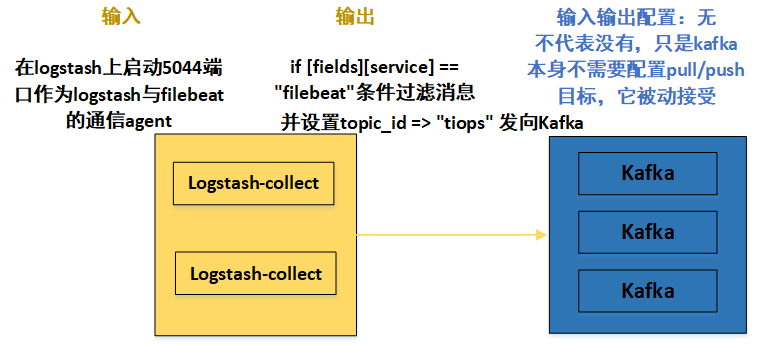
if [fields][service] == "filebeat"{ # 参照第一部分,Logstash-collect怎么接收到Filebeat发送的消息,并再次发向下一级呢?这里就是取filebeat的Fields字段的Key值,进行向下发送
kafka {
bootstrap_servers => "192.168.108.200:9092,192.168.108.165:9092,192.168.108.103:9092" # kafka集群配置,全部IP:端口都要加上
topic_id => "tiops" # 设置Kafka的topic,这样发送到kafka中时,kafka就会自动创建该topic
}
}
}
在这个小节,配置总体结构与日志数据流向如下图:
3】Kafka与Logstash-grok连接配置
在上面第二部分,我们已经成功把数据从Logstash-collect发送到Kafka,而Kafka本身的输入输出并没有配置。而是Logstash-collect指定了一个topic,这并不代表kafka不需要配置参数,只是kafka本身不需要配置pull/push目标参数,它被动接受
别的生产者发送过来的数据,因为Logstash-collect指定了Kafka集群的IP地址和端口。那么数据将会被发送到Kafka中,那么Kafka如何处理这些日志数据,那么这时候就需要Kafka配置消息处理参数了。
这个我们现在暂时先给出参数,至于具体原因涉及到MQ的高可用、消息过期策略、如何保证消息不重复消费、如何保证消息不丢失、如何保证消息按顺序执行以及消息积压在消息队列里怎么办等问题,我们之后详细分析并解决。
以下是Kafka集群中,某一台的配置文件,在Kafka源码目录的/kafka/config/server.properties文件设置如下:(加粗的为重要配置文件)
- broker.id=0
- listeners=PLAINTEXT://192.168.108.200:9092
- advertised.listeners=PLAINTEXT://192.168.108.200:9092
- num.network.threads=3
- num.io.threads=8
- socket.send.buffer.bytes=102400
- socket.receive.buffer.bytes=102400
- socket.request.max.bytes=104857600
- log.dirs=/var/log/kafka-logs
- num.partitions=1
- num.recovery.threads.per.data.dir=1
- offsets.topic.replication.factor=1
- transaction.state.log.replication.factor=1
- transaction.state.log.min.isr=1
- log.retention.hours=168
- log.segment.bytes=1073741824
- log.retention.check.interval.ms=300000
- zookeeper.connect=192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 # zookeeper 集群
- delete.topic.enable=true
同时kafka是依赖于zookeeper注册中心的一款分布式消息队列,所以需要有zookeeper单机或者集群环境。本次采用Kafka自带的Zookeeper环境。
在Kafka源码目录的/kafka/config/zookeeper.properties文件设置如下
- dataDir=/opt/zookeeper # 这时需要在/opt/zookeeper文件夹下,新建myid文件,把broker.id填写进去,本次本节点为0。
- # the port at which the clients will connect
- clientPort=2181
- # disable the per-ip limit on the number of connections since this is a non-production config
- maxClientCnxns=100
- tickTime=2000
- initLimit=10
- syncLimit=5
- server.0=192.168.108.200:2888:3888
- server.1=192.168.108.165:2888:3888
- server.2=192.168.108.103:2888:3888
其他注意事项,请看之前的Kafka集群安装步骤,这里主要给出集群某一节点的配置文件参数。
到目前为止,我们配置了kafka的参数,对消息进行了处理(持久化...),接下来就需要对Kafka中的消息进行下一步的传输,即传送到Logstash-grok。
这里需要注意的是:并不是Kafka主动把消息发送出去的,当然Kafka也支持这种操作,但是在这里,采用的是Logstash-grok作为消费者,主动拉取Kafka中的消息,来进行消费。
所以就需要像第二步Logstash-collect那样进行输入输出设置,这里Logstash-grok不仅仅配置输入输出,最重要的是它的过滤filter作用。
在/etc/logstash/conf.d目录下,创建logstash-es.conf文件,这里给出Logstash-grok中一个的内容如下(二个Logstash-grok配置一样):
#input {
# redis {
# data_type => "list"
# host => "192.168.108.200"
# db => "0"
# port => "6379"
# key => "tiops-tcmp"
# # password => "123456"
# }
#}
input{
kafka{
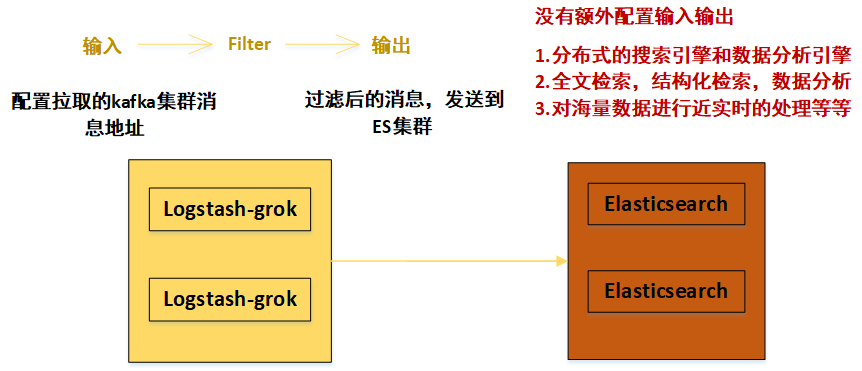
bootstrap_servers => ["192.168.108.200:9092,192.168.108.165:9092,192.168.108.103:9092"] # 配置拉取的kafka集群消息地址
group_id => "tyun" # 设置 group_id,对于这个消费组而言会有一个消费 offset,消费掉是 auto_commit 部分控制的,这个参数会定期将你消费的 offset 提交到 kafka,下次启动的时候已经消费过的就不会重复消费了;
# 如果想重新消费,可以换一个 group_id 即可
auto_offset_reset => "earliest"
consumer_threads => "3" # 多个实例的consumer_threads数之和应该等于topic分区数近似达到logstash多实例的效果。
decorate_events => "false"
topics => ["tiops"] # kafka topic 名称,获取指定topic内的消息
type => "log"
codec => json
}
}
filter { # 此处Logstash最主要的过滤作用,可以自定义正则表达式,选择性输出消息
grok {
match => {
#截取
"message" => "(?<LOG>(?<=architecture=x86_64}|containerized=true})(.*)/?)"
}
}
}
output { # 过滤后的消息,发送到ES集群
elasticsearch {
hosts => ["192.168.108.35:9200","192.168.108.194:9200"]
codec => json
index => "tiops-%{+YYYY.MM.dd}" # 自定义索引名称
}
在这个小节,配置总体结构与日志数据流向如下图:

4】Logstash-grok与Elasticsearch(ES)集群连接配置
ElasticSearch集群
在第三步中,我们已经将Logstash-grok过滤后的消息,发送到了ES集群,这里的ES集群被动接受发送过来的消息,即ES集群本身不需要配置输入源,已经由其他组件发送决定了。
ES的配置将集中体现在集群自身的配置上。
Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据
Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。
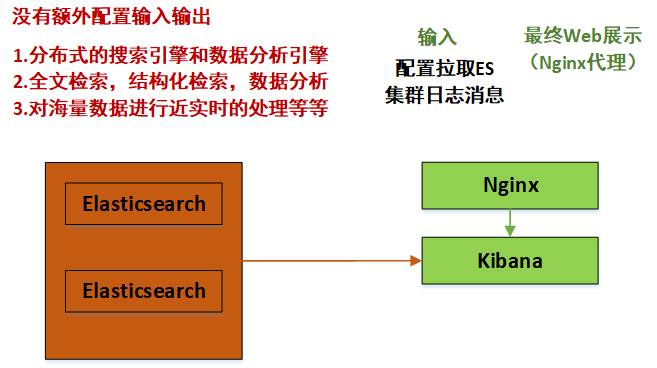
ES功能:(1)分布式的搜索引擎和数据分析引擎
(2)全文检索,结构化检索,数据分析
(3)对海量数据进行近实时的处理
安装后的ES集群,配置在/etc/elasticsearch/elasticsearch.yml文件,集群中,各个节点配置大体相同,不同之处下面有红字标出,主要就是节点名称与网络监听地址,需要每个节点自行按实际填写。
- cluster.name: elk-cluster #集群名称
- node.name: elk-node1 #节点名称,一个集群之内节点的名称不能重复
- path.data: /data/elkdata #数据路径
- path.logs: /data/elklogs #日志路径
- # bootstrap.memory_lock: true #锁住es内存,保证内存不分配至交换分区。
- network.host: 192.168.108.35 #网络监听地址,可以访问elasticsearch的ip, 默认只有本机
- http.port: 9200 #用户访问查看的端口,9300是ES组件访问使用
- discovery.seed_hosts: ["192.168.108.35","192.168.108.194"] 单播(配置一台即可,生产可以使用组播方式)
- cluster.initial_master_nodes: ["192.168.108.35"] # Master
- http.cors.enabled: true # 这二个是ES插件的web显示设置,head插件防止跨域
- http.cors.allow-origin: "*"
可见集群配置中最重要的两项是node.name与network.host,每个节点都必须不同。其中node.name是节点名称主要是在Elasticsearch自己的日志加以区分每一个节点信息。
discovery.seed_hosts是集群中的节点信息,可以使用IP地址、可以使用主机名(必须可以解析)。
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播),如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。(节点发现)
这里没有配置分片的数目,在ES的7版本中,默认为1,这个包括replicas可后来自定义设置。
在这个小节,配置总体结构与日志数据流向如下图:
5】Elasticsearch(ES)集群与Kibana连接配置
Kibana是一个开源的分析和可视化平台,和Elasticsearch一起工作时,就可以用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
同时Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
在第四步中,我们已经将ES集群中的数据进行了处理,建立了索引(相当于MySQL的database概念),并且分片、副本等都存在,而且处理后的数据更加方便于检索。
Kibana的配置在/etc/kibana/kibana.yml文件中,如下:
- server.port: 5601 #监听端口
- server.host: "192.168.108.182" #监听IP地址,建议内网ip
- #kibana.index: ".newkibana"
- elasticsearch.hosts: ["http://192.168.108.35:9200","http://192.168.108.194:9200"] # ES机器的IP,这里的所有host必须来自于同一个ES集群
- #xpack.security.enabled: false #添加这条,这条是配置kibana的安全机制,暂时关闭。
可以看出,这里的Kibana会主动去ES集群中去拉取数据,最后在浏览器Web端进行实时展示。
这时,我们打开浏览器界面如下,看看最终的结果:

注:Nginx代理配置,可以通过自定义域名访问并设置密码,提升安全性。(可选)
upstream kibana_server {
server 192.168.108.182:5601 weight=1 max_fails=3 fail_timeout=60;
}
server {
listen 80;
server_name www.kibana.com;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/conf.d/htpasswd.users;
location / {
proxy_pass http://kibana_server;
proxy_http_version 1.1;
}
}
在这个小节,配置总体结构与日志数据流向如下图:
6】总结

再将日志流向的配置文件输入输出标注一下:
万字长文:ELK(V7)部署与架构分析的更多相关文章
- ELK(V7)部署与架构分析
1.ELK的背景介绍与应用场景 在项目应用运行的过程中,往往会产生大量的日志,我们往往需要根据日志来定位分析我们的服务器项目运行情况与BUG产生位置.一般情况下直接在日志文件中tailf. grep. ...
- ELK 实现 Java 分布式系统日志分析架构
日志是分析线上问题的重要手段,通常我们会把日志输出到控制台或者本地文件中,排查问题时通过根据关键字搜索本地日志,但越来越多的公司,项目开发中采用分布式的架构,日志会记录到多个服务器或者文件中,分析问题 ...
- 精讲 使用ELK堆栈部署Kafka
使用ELK堆栈部署Kafka 通过优锐课的java架构学习分享,在本文中,我将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件. 在发生生产事件后,恰恰在你最需要它们时,日 ...
- 性能追击:万字长文30+图揭秘8大主流服务器程序线程模型 | Node.js,Apache,Nginx,Netty,Redis,Tomcat,MySQL,Zuul
本文为<高性能网络编程游记>的第六篇"性能追击:万字长文30+图揭秘8大主流服务器程序线程模型". 最近拍的照片比较少,不知道配什么图好,于是自己画了一个,凑合着用,让 ...
- ELK、ELFK企业级日志分析系统
ELK.ELFK企业级日志分析系统 目录 ELK.ELFK企业级日志分析系统 一.ELK日志分析系统 1. ELK简介 1.2 ElasticSearch 1.3 Logstash 1.4 Kiban ...
- 【万字长文】使用 LSM-Tree 思想基于.Net 6.0 C# 实现 KV 数据库(案例版)
文章有点长,耐心看完应该可以懂实际原理到底是啥子. 这是一个KV数据库的C#实现,目前用.NET 6.0实现的,目前算是属于雏形,骨架都已经完备,毕竟刚完工不到一星期. 当然,这个其实也算是NoSQL ...
- ELK+redis搭建nginx日志分析平台
ELK+redis搭建nginx日志分析平台发表于 2015-08-19 | 分类于 Linux/Unix | ELK简介ELKStack即Elasticsearch + Logstas ...
- tomcat架构分析 (Session管理)
Session管理是JavaEE容器比较重要的一部分,在app中也经常会用到.在开发app时,我们只是获取一个session,然后向session中存取数据,然后再销毁session.那么如何产生se ...
- 使用elk+redis搭建nginx日志分析平台
elk+redis 搭建nginx日志分析平台 logstash,elasticsearch,kibana 怎么进行nginx的日志分析呢?首先,架构方面,nginx是有日志文件的,它的每个请求的状态 ...
随机推荐
- 广义线性模型(Generalized Linear Model)
广义线性模型(Generalized Linear Model) http://www.cnblogs.com/sumai 1.指数分布族 我们在建模的时候,关心的目标变量Y可能服从很多种分布.像线性 ...
- =WM_VSCROLL(消息反射) 和 WM_VSCROLL(消息响应)的区别(控件拥有者自己不处这个理消息,而是反射给控件对象本身来处理这个消息)
=WM_VSCROLL(消息反射) 和 WM_VSCROLL(消息响应)的区别 所谓消息反射就是控件拥有者自己不处这个理消息,而是反射给控件对象本身来处理这个消息 1.“=WM_VSCROLL”是消息 ...
- 读取注册表获取Windows系统XP/7/8/10类型(使用wcscmp比较wchar[]内容)
很多方案是采用GetVersion.GetVersionEx这两个API来查询操作系统的版本号来判断当前的操作系统是Windows系列中的哪个,在Win10没有出现前,这种方法是行的通的,但是Win1 ...
- ring3下利用WMI监视进程创建(vc版)
#include "stdafx.h" #define _WIN32_DCOM #include <iostream> using namespace std; #in ...
- Qt - 设置程序界面风格(现成的QMacStyle等等)
类的继承关系: QMotifStyle:OSF(开放基金协会)开发的一个工业标准的GUI(图形用户接口): QCDEStyle:公共桌面环境(Common Desktop Environment)的缩 ...
- 原生Js汉语拼音首字母匹配城市名/自动提示列表
根据城市的汉语名称首字母把城市排序,基本思路: 1.处理数据,按照需要的格式分别添加{HOT:{hot:[],ABCDEFG:{a:[1,2,3],b:[1,2,3]},HIGHLMN:{},OPQR ...
- spring boot热部署devtools
1 pom.xml文件 注:热部署功能spring-boot-1.3开始有的 <!--添加依赖--> <dependency> <groupId>org.sprin ...
- python正则表达式模块
正则表达式是对字符串的最简约的规则的表述.python也有专门的正则表达式模块re. 正则表达式函数 释义 re.match() 从头开始匹配,匹配失败返回None,匹配成功可通过group(0)返回 ...
- [转]深入了解iPad上的MouseEvent
iPad上没有鼠标,所以手指在触发触摸事件(TouchEvent)的时候,系统也会产生出模拟的鼠标事件(MouseEvent). 这对于普通网页的浏览需求而言,基本可以做到与PC端浏览器无明 ...
- java web 开发教程(1) - 开发环境搭建
勤拂拭软件系列教程 之 Java Web开发之旅(1) Java Web开发环境搭建 1 前言 工作过程中,遇到不少朋友想要学习jsp开发,然而第一步都迈不出,连一个基本的环境都没有,试问,如何能够继 ...