基于代理的数据库分库分表框架 Mycat实践
| 192.168.199.75 | MySQL 、 MyCAT | master |
| 192.168.199.74 | MySQL | slave |
| 192.168.199.76 | MySQL | standby master |
如果说上面这张表不足以说明实验模型,那接下来再给一张图好了,如下所示:

我想这样看来的话,各个节点布了哪些组件,节点间的角色关系应该一目了然了吧
实验环境规划好了以后,接下来进行具体的部署与实验过程,首先当然是 MyCAT代理的部署
MyCAT 部署
关于该部分,网上教程实在太多了,但最好还是参考官方文档来吧,下面也简述一下部署过程
- 下载 MyCAT并解压安装
这里安装的是 MyCAT 1.5
wget https://raw.githubusercontent.com/MyCATApache/Mycat-download/master/1.5-RELEASE/Mycat-server-1.5.1-RELEASE-20161130213509-linux.tar.gz
tar -zxvf Mycat-server-1.5.1-RELEASE-20161130213509-linux.tar.gz
mv mycat /usr/local/
- 启动 MyCAT
./mycat start

- MyCAT连接测试
mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB

MyCAT 配置
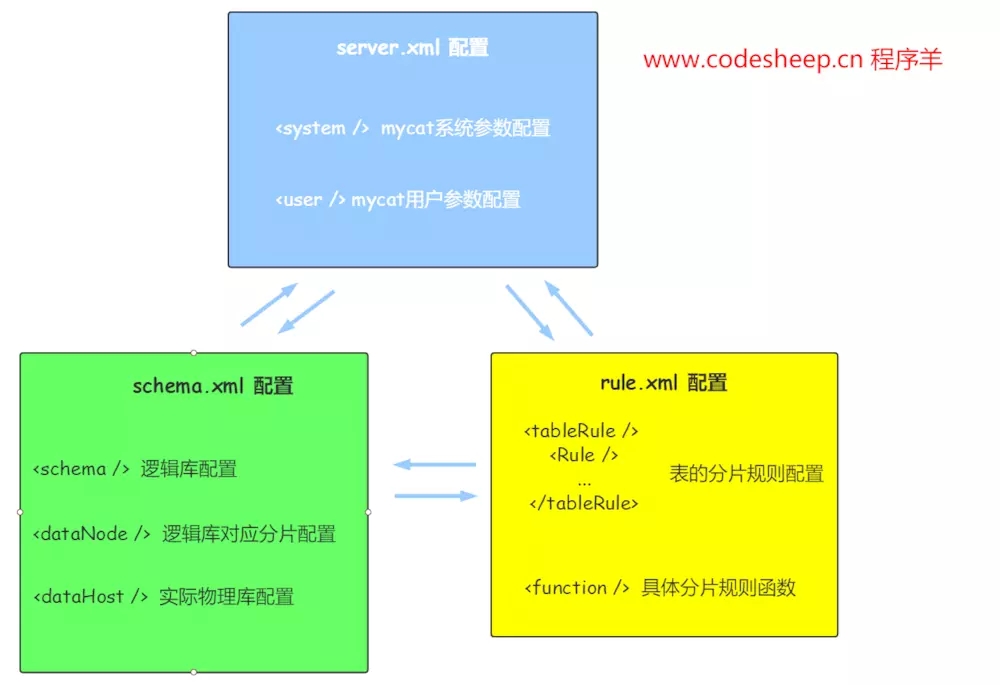
官网上对于这一部分的描述是非常详细的,MyCAT 配置主要涉及三个 XML配置文件:
server.xml:MyCAT框架的系统参数/用户参数配置文件schema.xml: MyCAT框架的逻辑库表与分片的配置文件rule.xml:MyCAT框架的逻辑库表分片规则的配置文件
用如下图形可以形象地表示出这三个 XML配置文件的配置内容和相互关系:
下面来进入具体的实验环节 ,这也是围绕 MyCAT提供的几大主要功能展开的,主要涉及三个方面
- 分库分表
- 读写分离
- 主备切换
实验之前,我们先给出公共的 server.xml文件的配置,这部分后续实验过程中并不修改,其也就是定义了系统参数和用户参数:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
<!-- <property /> 这块诸多的property配置在此就不配置了,参照官网按需配置 -->
</system>
<user name="test">
<property name="password">test</property>
<property name="schemas">TESTDB</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
分库分表实验
预期实验效果:通过 MyCAT代理往一张逻辑表中插入的多条数据,在后端自动地分配在不同的物理数据库表上
我们按照本文 第二节【环境规划】中给出的实验模型图来给出如下的 MyCAT逻辑库配置文件 schema.xml 和 分库分表规则配置文件 rule.xml
- 准备配置文件
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/" >
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2" rule="sharding-by-month" />
</schema>
<dataNode name="dn1" dataHost="testhost" database="db1" />
<dataNode name="dn2" dataHost="testhost" database="db2" />
<dataHost name="testhost" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="xxxxxx">
<readHost host="hostS1" url="192.168.199.74:3306" user="root" password="xxxxxx" />
</writeHost>
<writeHost host="hostM2" url="192.168.199.76:3306" user="root" password="xxxxxx">
</writeHost>
</dataHost>
</mycat:schema>
其中定义了实验用到的 hostM1、hostS1 和 hostM2
rule.xml
<tableRule name="sharding-by-month">
<rule>
<columns>create_date</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="org.opencloudb.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2018-11-01</property>
</function>
这里配置了
sharding-by-month的分库分表规则,即按照表中的create_date字段进行分割,从2018-11-01日期开始,月份不同的数据落到不同的物理数据库表中
- 在三个物理节点数据库上分别创建两个库 db1和 db2
create database db1;
create database db2;
- 连接 MyCAT
mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB
- 通过 MyCAT来创建数据库
travelrecord
create table travelrecord (id bigint not null primary key,city varchar(100),create_date DATE);
- 通过 MyCAT来往
travelrecord表中插入两条数据
insert into travelrecord(id,city,create_date) values(1,'NanJing','2018-11-3');
insert into travelrecord(id,city,create_date) values(2,'BeiJing','2018-12-3');
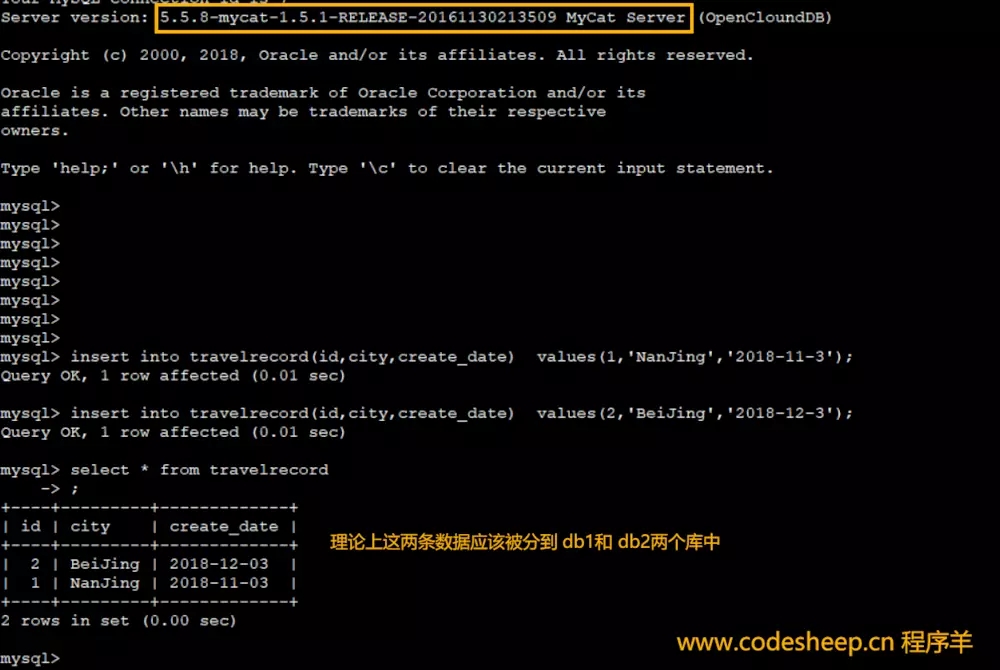
由于插入的这两条记录的 create_date分别是 2018-11-3和 2018-12-3,而我们配的分库分表的规则即是根据 2018-11-01这个日期为起始来进行递增的,按照前面我们配的分片规则,理论上这两条记录按照 create_date日期字段的不同,应该分别插入到 hostM1的 db1和 db2两个不同的数据库中。
- 验证一下数据分片的效果
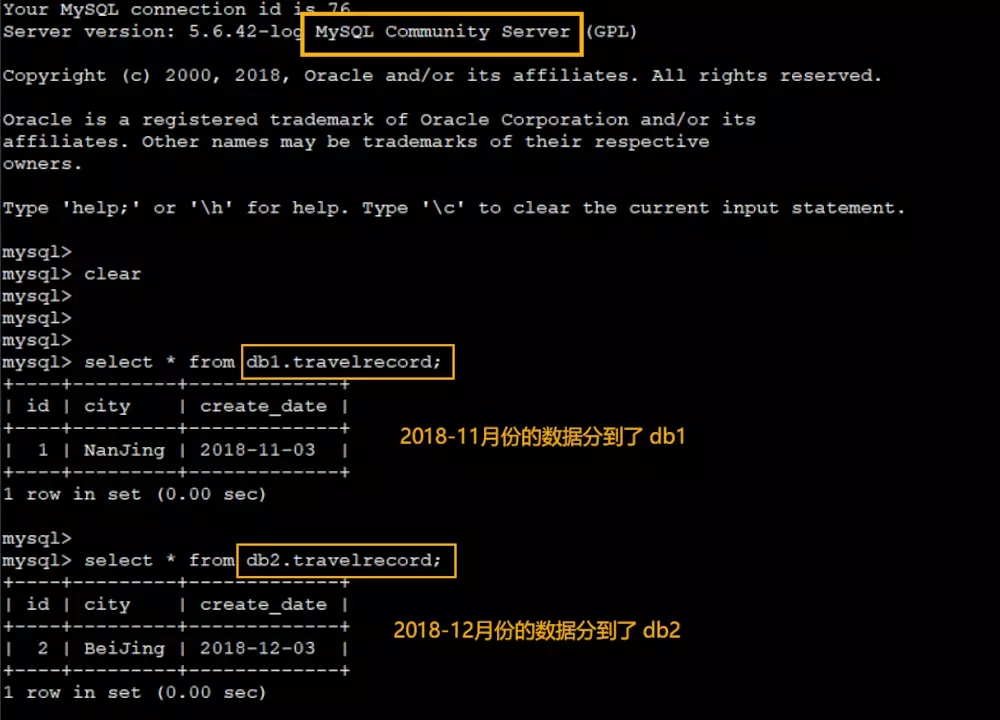
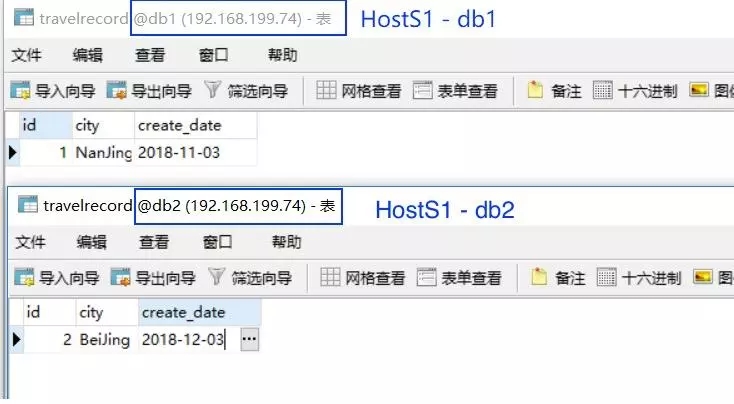
由于 hostM1和 hostS1组成了 主-从库 关系,因此刚插入的两条数据也应该相应自动同步到 hostS1的 db1和 db2两个数据库中,不妨也来验证一下:
读写分离实验
预期实验效果:开启了 MyCAT的读写分离机制后,读写数据操作各行其道,互不干扰
此节实验用到的配置文件 schema.xml 和 rule.xml基本和上面的【分库分表】实验没什么不同,只是我们需要关注一下 schema.xml配置文件中 <dataHost />标签里的 balance字段,它是与读写分离息息相关的配置:
因此我们就需要弄清楚 <dataHost /> 标签中 balance参数的含义:
balance="0":不开启读写分离机制,即读请求仅分发到 writeHost上balance="1":读请求随机分发到当前 writeHost对应的 readHost和 standby writeHost上balance="2":读请求随机分发到当前 dataHost内所有的 writeHost / readHost上balance="3":读请求随机分发到当前 writeHost对应的 readHost上
我们验证一下 balance="1"的情况,即开启读写分离机制,且读请求随机分发到当前 writeHost对应的 readHost和 standby writeHost上,而对于本文来讲,也即:hostS1 和 hostM2 上
我们来做两次数据表的 SELECT读操作:
mysql> select * from travelrecord limit 6;
+----+----------+-------------+
| id | city | create_date |
+----+----------+-------------+
| 3 | TianJing | 2018-11-04 |
| 5 | ShenYang | 2018-11-05 |
| 4 | Wuhan | 2018-12-04 |
| 6 | Harbin | 2018-12-05 |
+----+----------+-------------+
4 rows in set (0.08 sec)
mysql> select * from travelrecord limit 6;
+----+---------+-------------+
| id | city | create_date |
+----+---------+-------------+
| 2 | BeiJing | 2018-12-03 |
| 8 | WuXi | 2018-12-06 |
| 1 | NanJing | 2018-11-03 |
| 7 | SuZhou | 2018-11-06 |
+----+---------+-------------+
4 rows in set (0.01 sec)
然后我们取出 mycat.log日志查看一下具体详情,我们发现第一次 select读操作分发到了 hostM2上:
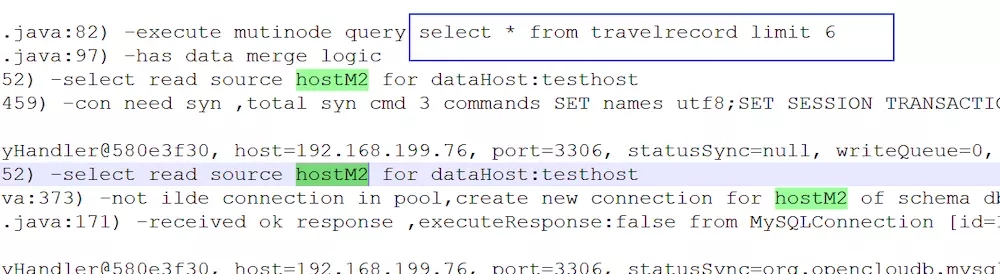
而第二次 select读操作分发到了 hostS1上:
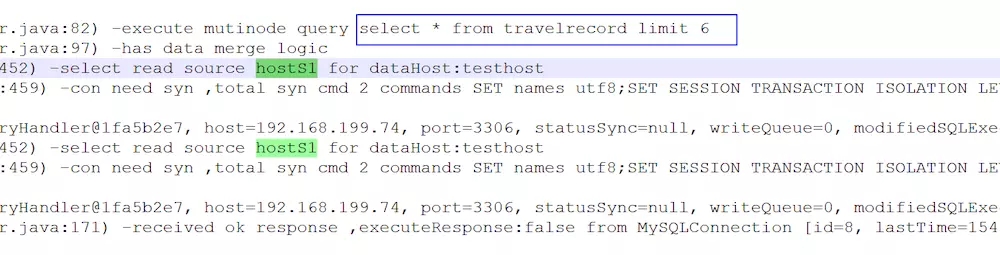
主备切换实验
预期实验效果:开启 MyCAT的主备机制后,当主库宕机时,自动切换到备用机进行操作
关于主备切换,则需要弄清楚 <dataHost /> 标签中 switchType参数的含义:
switchType="-1":不自动切换主备数据库switchType="1":自动切换主备数据库switchType="2":基于MySQL主从复制的状态来决定是否切换,需修改heartbeat语句:show slave statusswitchType="3":基于Galera(集群多节点复制)的切换机制,需修改heartbeat语句:show status like 'wsrep%'
此处验证一下 Mycat的主备自动切换效果。为此首先我们将 switchType="-1" 设置为 switchType="1",并重启 MyCat服务:
<dataHost name="testhost" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
在本实验环境中,在 hostM1 和 hostM2均正常时,默认写数据时是写到 hostM1的
- 接下来手动停止 hostM1 上的 MySQL数据库来模拟 hostM1 宕机:
systemctl stop mysqld.service
接下来再通过 MyCat插入如下两条数据:
insert into travelrecord(id,city,create_date) values(3,'TianJing','2018-11-4');
insert into travelrecord(id,city,create_date) values(4,'Wuhan','2018-12-4');
效果如下:
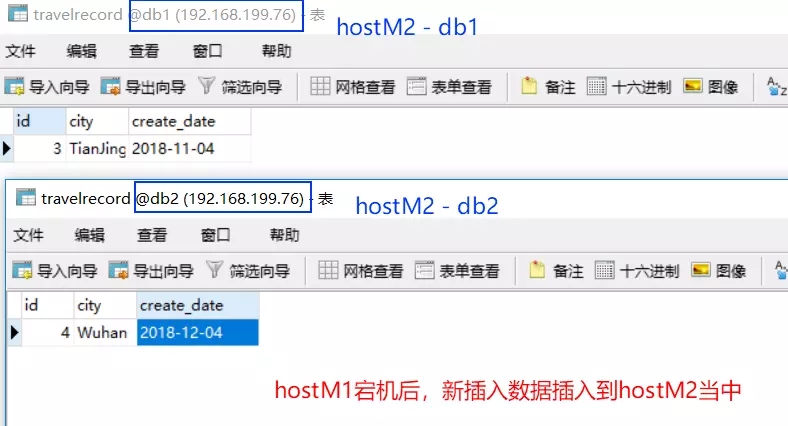
- 此时,我们恢复 hostM1,但接下来的数据写入依然进入 hostM2
insert into travelrecord(id,city,create_date) values(5,'ShenYang','2018-11-5');
insert into travelrecord(id,city,create_date) values(6,'Harbin','2018-12-5');
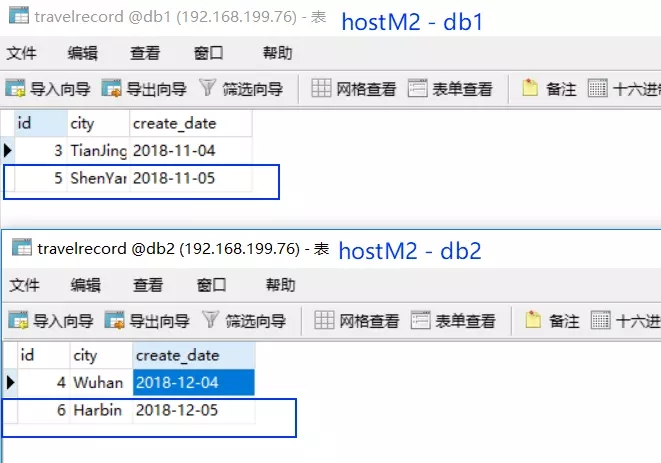
- 接下来手动让 hostM2宕机,看 hostM1 是否能升级为主写节点
再插入两条数据:
insert into travelrecord(id,city,create_date) values(7,'SuZhou','2018-11-6');
insert into travelrecord(id,city,create_date) values(8,'WuXi','2018-12-6');
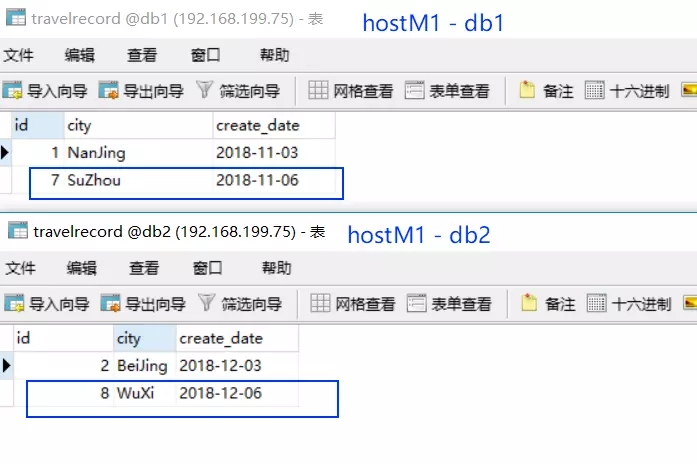
很明显,答案是肯定的
后 记
由于能力有限,若有错误或者不当之处,还请大家批评指正,一起学习交流!
作者:CodeSheep
链接:https://www.jianshu.com/p/d8b9da291a89
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
基于代理的数据库分库分表框架 Mycat实践的更多相关文章
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- 当当开源sharding-jdbc,轻量级数据库分库分表中间件
近期,当当开源了数据库分库分表中间件sharding-jdbc. Sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,实现透明化数据 ...
- 数据库分库分表(sharding)系列【转】
原文地址:http://www.uml.org.cn/sjjm/201211212.asp数据库分库分表(sharding)系列 目录; (一) 拆分实施策略和示例演示 (二) 全局主键生成策略 (三 ...
- 数据库分库分表(sharding)系列
数据库分库分表(sharding)系列 目录; (一) 拆分实施策略和示例演示 (二) 全局主键生成策略 (三) 关于使用框架还是自主开发以及sharding实现层面的考量 (四) 多数据源的 ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
- sharding-jdbc,轻量级数据库分库分表中间件
Sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,实现透明化数据库分库分表访问.Sharding-JDBC是继dubbox和ela ...
- php面试专题---mysql数据库分库分表
php面试专题---mysql数据库分库分表 一.总结 一句话总结: 通过数据切分技术将一个大的MySQLServer切分成多个小的MySQLServer,既攻克了写入性能瓶颈问题,同一时候也再一次提 ...
- 分布式事务-Sharding 数据库分库分表
Sharding (转)大型互联网站解决海量数据的常见策略 - - ITeye技术网站 阿里巴巴Cobar架构设计与实践 - 机械机电 - 道客巴巴 阿里分布式数据库服务原理与实践:沈询_文档下载 ...
- 转数据库分库分表(sharding)系列(二) 全局主键生成策略
本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请参考该系列的前一篇文章:数据库分库分表( ...
随机推荐
- form表单添加富文本编辑器
<div class="control-group"> <label class="control-label">内容:</lab ...
- 3、sql 表的连接
摘自: https://blog.csdn.net/holly2008/article/details/25704471 表连接分为:CROSS JOIN.INNERT JOIN.OUTER JOIN ...
- sed 删除用法
sed ‘1,4d’ dataf1 #把第一行到第四行删除,并且显示剩下的内容 sed ‘/La/d’ dataf2 #把含有 La 的行删除 sed ‘/La/!d`’#把不含 La 的行删除,!是 ...
- 一、移动端商城 Vue 组件库
一.组件库 移动端商城 Vue 组件库
- C语言——枚举类型用法
1.枚举的定义 enum 枚举名{ 枚举元 素1,枚举元素2,枚举元素3...}: 2.使用枚举类型的好处 增加程序的可读性,我们都知道在计算机中所有信息都是用二进制来表示的,如果你用二进制来表示某件 ...
- 005-监控项item详解,手动创建item实例
模板里的监控项都可以用 zabbix-get 命令执行 来获取相应的值,方法如下: [root@linux-node2 ~]# zabbix_get -s 192.168.1.230 -k agent ...
- 利用logrotate切割nginx的access.log日志
一.新建一个nginx的logrotate配置文件 /var/log/nginx/access.log { daily rotate compress delaycompress missingok ...
- 22_2mybatis——CURD
1.CURD操作 第一步:创建maven工程并导入坐标 <?xml version="1.0" encoding="UTF-8"?> <pro ...
- 详解PHP文件下载的原理和实现
通常文件下载过程是十分简单的,建立一个链接指向到目标文件就可以了.例如下面的链接: XML/HTML代码 <a href=http://www.xxx.com/xxx.rar>点击下载文件 ...
- thinkphp类型转换
类型转换 说白了就是在model类中声明的字段输出类型:其语法如下: 注意strtotime()函数可以将诸如‘2018-12-21’这样的日期字符串转为整数存入数据库 自动完成---等于提前对某一表 ...