将数据从数据仓库Hive导入到MySQL
1.启动Hadoop,hive,mysql
2.在mysql中建表(需要导入数据的)
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(),`item_id` varchar(),`cat_id` varchar(),`merchant_id` varchar(),`brand_id` varchar(), `month` varchar(),`day` varchar(),`action` varchar(),`age_range` varchar(),`gender` varchar(),`province` varchar()) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.选择数据仓库live中的数据:
建临时表:
create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
选中要被导出的数据:
INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;
3.使用Sqoop将数据从Hive导入MySQL
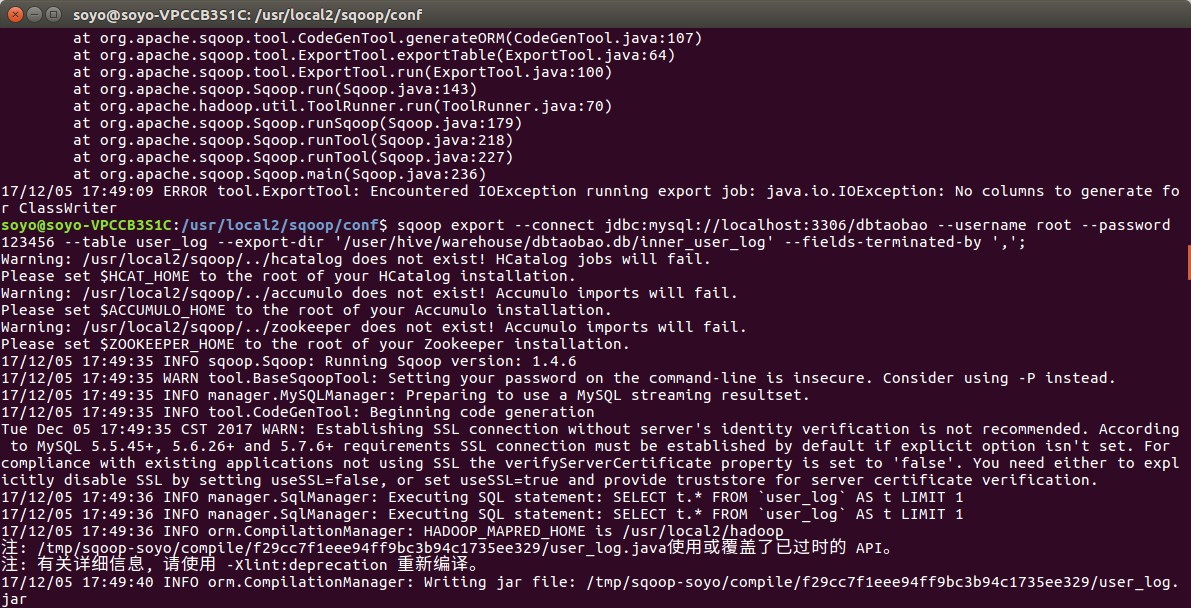
字段值解释:
localhost:3306/dbtaobao -->(数据库名)MySQL
table:user_log -->(将要被你导入数据的mysql数据库表名)
export-dir:’********‘ -->HDFS上文件的路径(数据仓库hive中需要被导出的数据库表)
fields-terminated-by ',' -->Hive 中被导出的文件字段的分隔符
将数据从数据仓库Hive导入到MySQL的更多相关文章
- sqlserver 中数据导入到mysql中的方法以及注意事项
数据导入从sql server 到mysql (将数据以文本格式从sqlserver中导出,注意编码格式,再将文本文件导入mysql中): 1.若从slqserver中导出的表中不包含中文采用: bc ...
- sqoop从hive导入数据到mysql时出现主键冲突
今天在将一个hive数仓表导出到mysql数据库时出现进度条一直维持在95%一段时间后提示失败的情况,搞了好久才解决.使用的环境是HUE中的Oozie的workflow任何调用sqoop命令,该死的o ...
- 使用Sqoop从mysql向hdfs或者hive导入数据时出现的一些错误
1.原表没有设置主键,出现错误提示: ERROR tool.ImportTool: Error during import: No primary key could be found for tab ...
- Mysql & Hive 导入导出数据
---王燕行转列sql select split(concat_ws(',',collect_set(cast(smzq as string))),',')[1] ,split(concat_ws(' ...
- 22.把hive表中数据导入到mysql中
先通过可视化工具链接mysql,在链接的时候用sqoop 用户登录 在数据库userdb下新建表 保存,输入表名upflow 现在我们需要把hive里面的数据通过sqoop导入到mysql里面 sqo ...
- 【转】Hive导入10G数据的测试
原博文出自于: http://blog.fens.me/hadoop-hive-10g/ 感谢! Hive导入10G数据的测试 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让H ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 将Hive统计分析结果导入到MySQL数据库表中(一)——Sqoop导入方式
https://blog.csdn.net/niityzu/article/details/45190787 交通流的数据分析,需求是对于海量的城市交通数据,需要使用MapReduce清洗后导入到HB ...
- Hive导入10G数据的测试
Hive导入10G数据的测试 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越便宜,一台非 ...
随机推荐
- 标准sqlserver连接语句
sqlserver左右全内连接 原始链接http://www.cnblogs.com/youzhangjin/archive/2009/05/22/1486982.html 连接条件可在FR ...
- Python 循环语句(break和continue)
Python 循环语句(break和continue) while 语句时还有另外两个重要的命令 continue,break 来跳过循环,continue 用于跳过该次循环,break 则是用于退出 ...
- python标准库笔记
1.python互联网数据处理模块 base64数据编码 二进制数据 encode ASCII字符 ASCll字符 decode 二进制数据 json数据交换格式 轻量的数据交换格式,json暴露的A ...
- [BZOJ1264][AHOI2006]基因匹配Match(DP + 树状数组)
传送门 有点类似LCS,可以把 a[i] 在 b 串中的位置用一个链式前向星串起来,由于链式前向星是从后往前遍历,所以可以直接搞. 状态转移方程 f[i] = max(f[j]) + 1 ( 1 &l ...
- http post提交数组
方式一:@RequestParam方式 服务提供方用@RequestParam注解接收参数,参数类型为long数组: @ApiOperation(value = "***", ta ...
- CentOS虚拟机与本机同步时间
接着之前的任务,还是为了在VMWare上搭建分布式hadoop集群.搭着搭着注意到虚拟机上的时间和本机是不同步的,而且可以说是乱七八糟,3台虚拟机时间都与本机差了8个小时以上.首先确认不是时区的问题, ...
- Ubuntu 16.04升级Linux内核为4.7.0最快的方法
升级内容有很多好处,比如支持最新硬件驱动,使系统更安装等.但是升级内容也会带来一些问题,比如一些软件的兼容性问题,从而出现一些莫名其妙的问题等,所以升级时要慎重考虑. 升级方法: 下载脚本: http ...
- reader dc
https://get.adobe.com/cn/reader/otherversions/
- WCF - 自定义绑定
自定义绑定 当系统提供的某个绑定不符合服务的要求时,可使用 CustomBinding 类.所有绑定都是从绑定元素的有序集构造而来的.自定义绑定可以从一组系统提供的绑定元素生成,也可以包含用户定义的自 ...
- js下载
下载用ajax不好使,得用表单提交的方式 download:function(url,paramObj){ var doc = document; //使用一个隐藏的form表单执行提交,没有则创建 ...