Shuffle 机制
1. 概述
- Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。
2. Partition 分区
- 需求:要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地,不同省份输出到不同文件中(分区)。
// 默认 Partitioner 分区
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
2.1 自定义 Partitioner 步骤
// 1. 自定义类继承 Partitioner, 重写 getPartition() 方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制区代码逻辑
......
}
}
// 2. 在 Job 驱动中,设置自定义 Partitioner
job.setPartitionerClass(CustomPartitioner.class);
// 3. 自定义 Partition 后,要根据自定义 Partitioner 的逻辑设置相应数量的 ReduceTask
job.setNumReduceTasks(自定义的数量);
2.2 分区总结
- 如果 ReduceTask 的数量大于getPartition的结果数,则会多产生几个空的输出文件 part-r-000xx;
- 如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会产生IOException;
- 如果ReduceTask的数量为1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000;
- 分区号必须从零开始,逐一累加。
3. WritableComparable 排序
- MapTask 和 ReduceTask 均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
3.1 排序概述
- MapTask:它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它回对磁盘上所有文件进行归并排序。
- ReduceTask:它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大的文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask 统一对内存和磁盘上的所有数据进行一次归并排序。
3.1 排序分类
- 部分排序
- MapReduce 根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
- 全排序
- 最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
- 辅助排序(GroupingComparator 分组)
- 在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
- 二次排序
- 在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
3.2 Combiner 合并
- Combiner是MR程序中Mapper和Reducer之外的一种组件;
- Combiner组件的父类就是Reducer;
- Combiner和Reducer的区别在于运行的位置:
- Combiner是在每一个MapTask所在的节点运行;
- Reducer是接收全局所有Mapper的输出结果;
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来;
3.3 GroupingComparator 分组(辅助排序)
- 对Reduce阶段的数据根据某一个或几个字段进行分组。
// 分组排序步骤:
// 1. 自定义类继承 WritableComparator
// 2. 重写 compare()方法
// 3. 创建一个构造将比较对象的类传给父类
4. Shuffle 机制
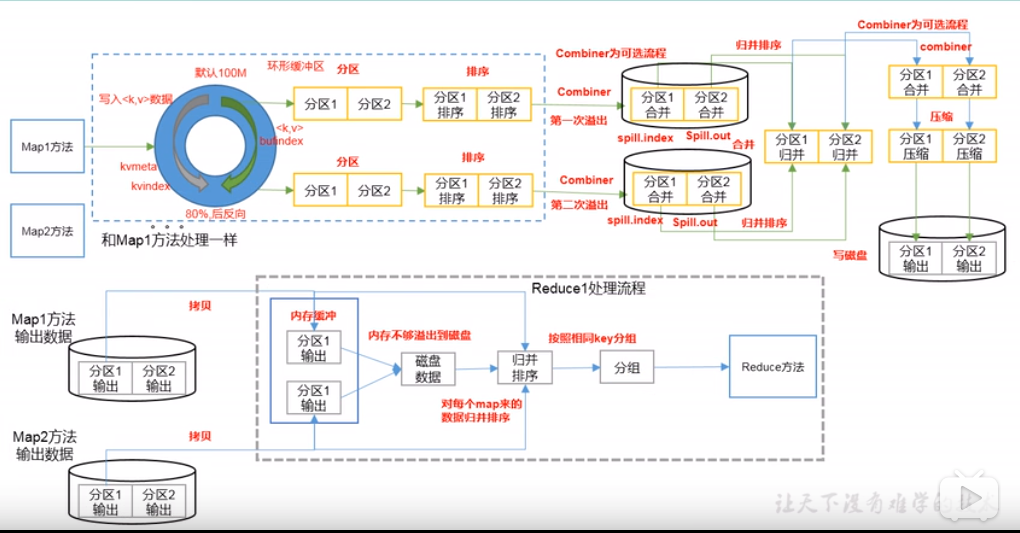
Shuffle 机制的更多相关文章
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- 3 weekend110的shuffle机制 + mr程序的组件全貌
前面,讲到了hadoop的序列化机制,mr程序开发,自定义排序,自定义分组. 有多少个reduce的并发任务数可以控制,但有多少个map的并发任务数还没 缓存,分组,排序,转发,这些都是mr的shuf ...
随机推荐
- [HNOI2002]营业额统计 II
https://www.luogu.org/problemnew/show/2234 将权值离散化,以权值为下标建立权值线段树 #include <bits/stdc++.h> using ...
- C++标准库分析总结(五)——<Deque、Queue、Stack设计原则>
本节主要总结标准库Deque的设计方法和特性以及相关迭代器内部特征 1.Deque基本结构 Deque(双向队列)也号称连续空间(其实是给使用者一个善意的谎言,只是为了好用),其实它使用分段拼接起来的 ...
- Java基础系列 - JAVA集合ArrayList,Vector,HashMap,HashTable等使用
package com.test4; import java.util.*; /** * JAVA集合ArrayList,Vector,HashMap,HashTable等使用 */ public c ...
- tab切换里面做轮播图
这里的轮播图有三页,并且每页的数据有8个,只能将23个数据分割开来,这里要实现5个tab用一个轮播图 <div class="report_detail_class"> ...
- usb 设备 复位
How to Reset USB Device in Linux by ROMAN10 on MAY 4, 2011 · 9 COMMENTS USB devices are anywhere n ...
- yarn集群8088端口被攻击挖矿
yarn集群8088端口被攻击挖矿 https://www.jianshu.com/p/a2d6b0d827ab https://blog.csdn.net/lm709409753/article/d ...
- Redis 单线程却能支撑高并发 - 简书 https://www.jianshu.com/p/2d293482f272
小结: 1.在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况:2.Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一 ...
- 如何交叉编译openssl库?
1. 获取源码 wget https://www.openssl.org/source/openssl-1.0.2s.tar.gz 2. 解压源码 tar xvf openssl-1.0.2s.tar ...
- 动画之Evaluator
Evaluator就是通过监听器拿到当前动画对对应的具体数值,作用在于从插值器返回的数值进行转换成对应的数值.简单来说就是转换器 Evaluator返回值的类型更加动画中值决定的,所以在使用的时候注意 ...
- ThinkPhp5 mongodb 使用自定义objectID出错解决
在Tp5中使用mongodb 使用自定义ObjectId时报错:Cannot use object of type MongoDB\\BSON\\ObjectID as array 查询源码发现在to ...