Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架。这篇是介绍Spark Structured Streaming的基本开发方法。以Spark 自带的example进行测试和介绍,其为"StructuredNetworkWordcount.scala"文件。
1. Quick Example
由于我们是在单机上进行测试,所以需要修单机运行模型,修改后的程序如下:
|
package org.apache.spark.examples.sql.streaming import org.apache.spark.sql.SparkSession /** * Counts words in UTF8 encoded, '\n' delimited text received from the network. * * Usage: StructuredNetworkWordCount <hostname> <port> * <hostname> and <port> describe the TCP server that Structured Streaming * would connect to receive data. * * To run this on your local machine, you need to first run a Netcat server * `$ nc -lk 9999` * and then run the example * `$ bin/run-example sql.streaming.StructuredNetworkWordCount * localhost 9999` */ object StructuredNetworkWordCount { def main(args: Array[String]) { if (args.length < 2) { System.err.println("Usage: StructuredNetworkWordCount <hostname> <port>") System.exit(1) } val host = args(0) val port = args(1).toInt val spark = SparkSession .builder .appName("StructuredNetworkWordCount") .master("local[*]") .getOrCreate() import spark.implicits._ // Create DataFrame representing the stream of input lines from connection to host:port val lines = spark.readStream .format("socket") .option("host", host) .option("port", port) .load() // Split the lines into words val words = lines.as[String].flatMap(_.split(" ")) // Generate running word count val wordCounts = words.groupBy("value").count() // Start running the query that prints the running counts to the console val query = wordCounts.writeStream .outputMode("complete") .format("console") .start() query.awaitTermination() } } |
2. 剖析
对于上述所示的程序,进行如下的解读和分析:
2.1 数据输入
在创建SparkSessiion对象之后,需要设置数据源的类型,及数据源的配置。然后就会数据源中源源不断的接收数据,接收到的数据以DataFrame对象存在,该类型与Spark SQL中定义类型一样,内部由Dataset数组组成。
如下程序所示,设置输入源的类型为socket,并配置socket源的IP地址和端口号。接收到的数据流存储到lines对象中,其类型为DataFarme。
|
// Create DataFrame representing the stream of input lines from connection to host:port val lines = spark.readStream .format("socket") .option("host", host) .option("port", port) .load() |
2.2 单词统计
如下程序所示,首先将接受到的数据流lines转换为String类型的序列;接着每一批数据都以空格分隔为独立的单词;最后再对每个单词进行分组并统计次数。
|
// Split the lines into words val words = lines.as[String].flatMap(_.split(" ")) // Generate running word count val wordCounts = words.groupBy("value").count() |
2.3 数据输出
通过DataFrame对象的writeStream方法获取DataStreamWrite对象,DataStreamWrite类定义了一些数据输出的方式。Quick example程序将数据输出到控制终端。注意只有在调用start()方法后,才开始执行Streaming进程,start()方法会返回一个StreamingQuery对象,用户可以使用该对象来管理Streaming进程。如上述程序调用awaitTermination()方法阻塞接收所有数据。
3. 异常
3.1 拒绝连接
当直接提交编译后的架包时,即没有启动"nc –lk 9999"时,会出现图 11所示的错误。解决该异常,只需在提交(spark-submit)程序之前,先启动"nc"命令即可解决,且不能使用"nc –lk localhost 9999".

图 11
3.2 NoSuchMethodError
当通过mvn打包程序后,在命令行通过spark-submit提交架包,能够正常执行,而通过IDEA执行时会出现图 12所示的错误。

图 12
出现这个异常,是由于项目中依赖的Scala版本与Spark编译的版本不一致,从而导致出现这种错误。图 13和图 14所示,Spark 2.10是由Scala 2.10版本编译而成的,而项目依赖的Scala版本是2.11.8,从而导致出现了错误。
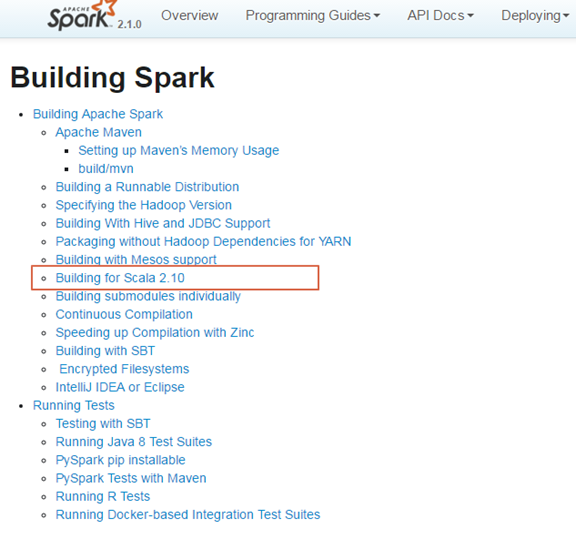
图 13

图 14
解决该问题,只需在项目的pom.xml文件中指定与spark编译的版本一致,即可解决该问题。如图 15所示的执行结果。

图 15
4. 参考文献
Spark Structured streaming框架(1)之基本使用的更多相关文章
- Spark Structured Streaming框架(3)之数据输出源详解
Spark Structured streaming API支持的输出源有:Console.Memory.File和Foreach.其中Console在前两篇博文中已有详述,而Memory使用非常简单 ...
- Spark Structured Streaming框架(1)之基本用法
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark Structured Streaming框架(5)之进程管理
Structured Streaming提供一些API来管理Streaming对象.用户可以通过这些API来手动管理已经启动的Streaming,保证在系统中的Streaming有序执行. 1. St ...
- Spark Structured Streaming框架(4)之窗口管理详解
1. 结构 1.1 概述 Structured Streaming组件滑动窗口功能由三个参数决定其功能:窗口时间.滑动步长和触发时间. 窗口时间:是指确定数据操作的长度: 滑动步长:是指窗口每次向前移 ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
随机推荐
- [补] winpcap编程——EAPSOCKET实现校园网锐捷登录(mentohust)
EAP SOCKET Implement Mentohust 时间20161115 对于EAP协议不了解,可参考上一篇随笔. 通过抓包分析校园网的锐捷登录流程,我在上一篇随笔中实现了EAPSOCKET ...
- (转)Java线程:线程的同步与锁
Java线程:线程的同步与锁 一.同步问题提出 线程的同步是为了防止多个线程访问一个数据对象时,对数据造成的破坏. 例如:两个线程ThreadA.ThreadB都操作同一个对象Fo ...
- 【ES】ElasticSearch初体验之使用Java进行最基本的增删改查~
好久没写博文了, 最近项目中使用到了ElaticSearch相关的一些内容, 刚好自己也来做个总结. 现在自己也只能算得上入门, 总结下自己在工作中使用Java操作ES的一些小经验吧. 本文总共分为三 ...
- node.js fs.open 和 fs.write 读取文件和改写文件
Node.js的文件系统的Api //公共引用 var fs = require('fs'), path = require('path'); 1.读取文件readFile函数 //readFile( ...
- Java生成MD5加密字符串代码实例
这篇文章主要介绍了Java生成MD5加密字符串代码实例,本文对MD5的作用作了一些介绍,然后给出了Java下生成MD5加密字符串的代码示例,需要的朋友可以参考下 (1)一般使用的数据库中都会保存用 ...
- Redux源码分析之combineReducers
Redux源码分析之基本概念 Redux源码分析之createStore Redux源码分析之bindActionCreators Redux源码分析之combineReducers Redux源码分 ...
- NYOJ--1236--挑战密室(第八届河南省程序设计大赛)
挑战密室 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 R组织的特工Dr. Kong 为了寻找丢失的超体元素,不幸陷入WTO密室.Dr. Kong必须尽快找到解锁密 ...
- 白帽子之路首章:Footprinting, TARGET ACQUISITION
*Disclaimer: All materials provided on this blog are for educational purposes only. The author and o ...
- 版本管理工具Git(1)带你认识git
简介 本篇将带领大家认识,git.github,让大家对git有基本的认识:下面将持续更新几篇文章来介绍git,见git导航: 下一篇中将讲解git的安装及使用: Git系列导航 版本管理工具Git( ...
- JavaScript闭包只学这篇就够了
闭包不是魔法 这篇文章使用一些简单的代码例子来解释JavaScript闭包的概念,即使新手也可以轻松参透闭包的含义. 其实只要理解了核心概念,闭包并不是那么的难于理解.但是,网上充斥了太多学术性的文章 ...