【论文阅读】Binary Multi-View Clustering
文章地址:https://ieeexplore.ieee.org/document/8387526
出自:IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018.
本文是对《Binary Multi-View Clustering》一文的个人理解总结,详细内容敬请阅读原文。
一、主要解决的问题
1、多视角的大尺度的数据集聚类性能表现欠佳;
2、实值聚类消耗较大的内存资源和计算资源;
2、编码和聚类是独立的,不能相互作用。
二、创新点
1、BMVC是第一个使用二进制编码技术解决大规模多视图聚类问题的方法,BMVC同时从多个视图和联合优化二进制编码和聚类。
2、提出了一种交替优化算法用于解决离散的优化问题,。针对二值聚类中心学习的关键子问题,还提出了一种自适应离散近似线性方法(ADPLM)。
3、BMVC具有较好的聚类性能,还明显更少的计算时间和内存开销,内存和时间上快的不止一点,这一点真的很好。
三、文章概要:
文章是编码的多视角聚类问题。首先说明什么是多视角和如何编码,然后从哈希编码联合聚类模型、优化以及实验分析三个方面简述文章主要思想和实验设计。
所谓多视角,引用原文:1. Different to single-view clustering using singular data descriptor, in this paper, we first describe each data point (e.g., an image) by various features (e.g., different image descriptors, such as HOG, Color Histogram and GIST) and then feed these features from multiple descriptors into our clustering. It is noteworthy that the “Multiview” in our paper indicates multiple image descriptors of features rather than multiple modalities. 简单来说:本文多视角就是多种特征。
1、哈希编码
为什么要进行编码呢?
第一,针对实值聚类需要较大的内存资源,尤其是谱聚类方法,对较大尺度的图像数据集需要占用很大的内存,编码能够对数据特征进行降维处理,尽可能的保留了样本的自身特征。第二、计算机能够更容易处理编码数据,降低计算复杂度。
如何编码:对于任意一个视角(一种特征),n为数据集中图像的数目,m是选取的锚点数。具体或称如下图。

怎么样让编码更好的体现特征,设计了如下代价函数:
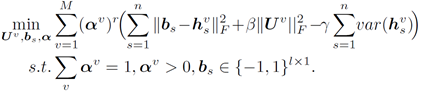
- 希望多视角学习得到的 M 个哈希矢量与 二值编码B 能够相似,最小化编码和哈希矢量的L2范式;
- 希望得到的投影转换矩阵约简单越好,最小化U的L2范式;
- 希望数据点的二值码分布均衡,最大化其方差;
- 不同视角扮演的分量不同,不同视角优化不同权重。
2、哈希编码联合聚类模型
聚类模型使用的是矩阵分解的方法,希望每个编码b可以用一个聚类中心C和指示向量g(权重)的乘积来表示,希望分解的误差最小。方法化较为常见,话不多说代价函数详见下式:
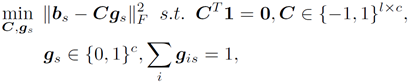
文章的一个主要创新点体现再此,作者将编码和聚类同时进行优化,将两者目标方程结合在一起,在学习过程中,相对于pipeline的方法更能将编码和聚类相互作用体现出来。于是总的代价函数:
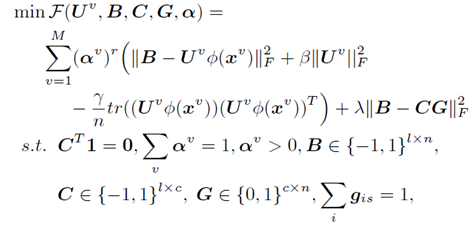
3、 优化
面对如此复杂的代价函数( 涉及到离散约束条件的np hard问题),如何进行优化训练?
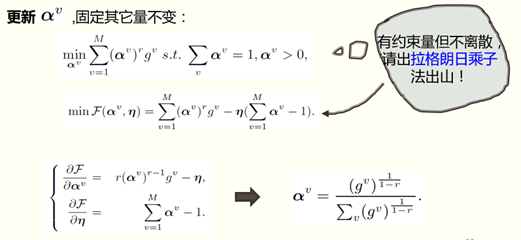
作者,使用了一个交替优化策略,即更新某个变量时,固定其它变量不变的循环更新方法。
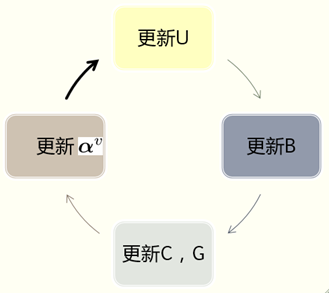
更新U ,固定其它量不变,总代价函数变为:
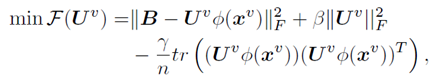
可见该项不含约束项,直接求导,令其倒数为0,得到此时最优U;
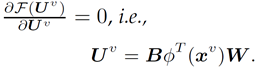
其中,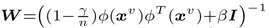
更新B , 总代价函数变为:
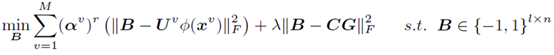
包含有离散约束量,怎么办呢,先化简看看啦:
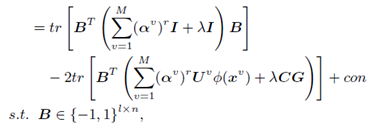
化简到此,是不是有种“柳暗花明又一村“的感觉,第一项是常数,因为B转置和B之间的项是一常数乘以单位阵,又因B转置乘以B为常数,故第一项为常数。于是就变为求第二项的最小值,前面有(-)符号,使得B转置乘以一项的值最大,这一项就为B。因为B为编码,所以取符号操作,B为:
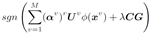

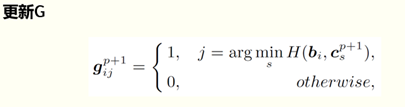
找出每个b到任何聚类中心的hamming距离,最近的给权值g为1,其它置为0。
4、实验分析
作者在Caltech101, NUS-WIDE-Obj, Cifar-10, Sun-397 YouTube Faces 实验验证。
以Caltech101为例,精度上对比如图,在多view上作者算法是最高的,并且提升幅度较大。

效率上的对比,作者算法相对于K-means时间上提升了60倍的速度,是不是相当惊人!

内存资源占用对比,内存降低近1500倍,是不是更加惊人!
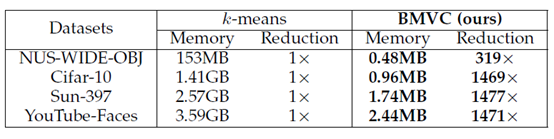
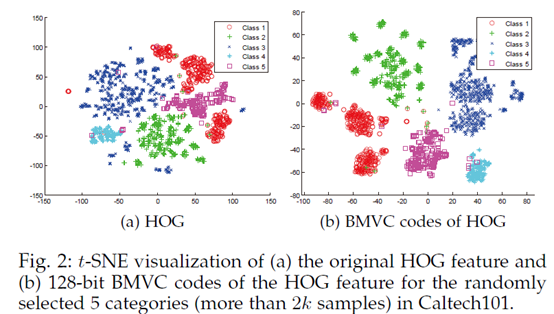
有人可能会有疑问,为什么编码后聚类性能能够提升??来看编码后的特征分布,如下两图,相同簇用同种颜色表示,编码后的特征簇间分布更加分散,簇内分布更加紧密,这就更容易对其进行聚类。以至于效果能够提升。
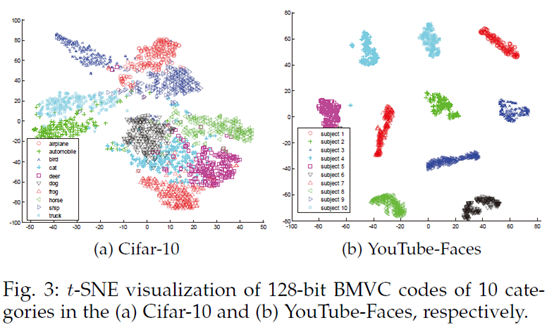
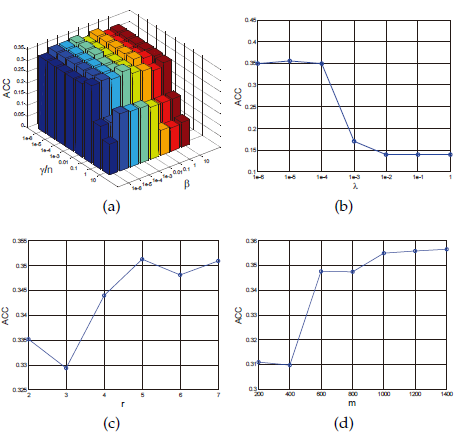
参数灵敏度分析:
手动调整参数较多,作者实验分析了这些参数对性能的影响,好在模型对这些参数不敏感。参数在一定大范围内能够保持稳定的聚类性能!
四、总结
Contributions:
1. 提出了一种能够降低计算复杂度和内存开销的多视角聚类算法;
2. 提供了一种编码和聚类同时优化的思想;
Limitations:
1. 文章中所提,手动调整参数太多(源于太多的约束项)。
如有不足,肯请指出。
张亚超
2018年10月22日
【论文阅读】Binary Multi-View Clustering的更多相关文章
- 【论文阅读】Deep Adversarial Subspace Clustering
导读: 本文为CVPR2018论文<Deep Adversarial Subspace Clustering>的阅读总结.目的是做聚类,方法是DASC=DSC(Deep Subspace ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
- SLAM论文阅读笔记
[1]陈卫东, 张飞. 移动机器人的同步自定位与地图创建研究进展[J]. 控制理论与应用, 2005, 22(3):455-460. [2]Cadena C, Carlone L, Carrillo ...
- [论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximati
[论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximation 本文结构 解决问题 主要贡献 主要 ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
随机推荐
- 解决 IDEA 创建 Gradle 项目没有src目录
第一次写博客,前几天遇到一个问题,就是使用ider创建gradle项目后,src目录没有自动生成出来,今天就给大家分享一下怎么解决. 目录: 1.创建Gradle项目 2.解决没有生成src目录问题 ...
- MyBatis(3)-- Mapper映射器
一.select元素 1.select元素的应用 id为Mapper的全限定名,联合称为一个唯一的标识 paremeterType标识这条SQL接收的参数类型 resultType标识这条SQL返回的 ...
- incompatible implicit declaration of built-in function 'fabs'
形如: float a = -3.0; float b = fabs(a); 形参数据类型和实参数据类型完全一致,却还报警告: incompatible implicit declaration of ...
- .net调用阿里短信接口
一.创建一个空的api项目 二.应用阿里的短信包 aliyun-net-sdk-core 三.登录阿里添加签名和模板 四.创建创建AccessKey 注意 AccessKey创建后,无法再通过控制台查 ...
- Java自动化测试框架-09 - TestNG之依赖注入篇 (详细教程)
1.-依赖注入 TestNG支持两种不同类型的依赖项注入:本机(由TestNG本身执行)和外部(由诸如Guice的依赖项注入框架执行). 1.1-本机依赖项注入 TestNG允许您在方法中声明其他参数 ...
- 暑期集训20190729 字典序(dictionary)
[题目描述] 你需要构造一个1~n的排列,使得它满足m个条件,每个条件形如(ai,bi),表示ai必须在bi前面. 在此基础上,你需要让1尽可能靠前,然后你需要让2尽可能靠前,然后是3,4,5,…,n ...
- 【模板】prufer序列
如何构造一个prufer序列? 我们给一棵无根树的节点编上号,每次找到一个编号最小的度为1节点,删除它,并输出与它连接的点的编号,直到只剩下两个节点. 这样,我们就构造出来了一个prufer序列. 通 ...
- Appium+python自动化(三十九)-Appium自动化测试框架综合实践 - 代码实现(超详解)
简介 经过一段时间的准备,完善的差不多了,继续分享有关Appium自动化测试框架综合实践.想必小伙伴们有点等不及了吧! driver配置封装 kyb_caps.yaml 配置表 参考代码 platfo ...
- Requests库使用总结
概述 Requests是python中一个很Pythonic的HTTP库,用于构建HTTP请求与解析响应 Requests开发哲学 Beautiful is better than ugly.(美丽优 ...
- jquery layui的巨坑
jquery layui的巨坑 layui 模块不能写在ajax里 因为 layui只能执行一次 第二次会没效果 再执行需要刷新页面再执行