【原创】大数据基础之ORC(1)简介

Optimized Row Columnar (ORC) file
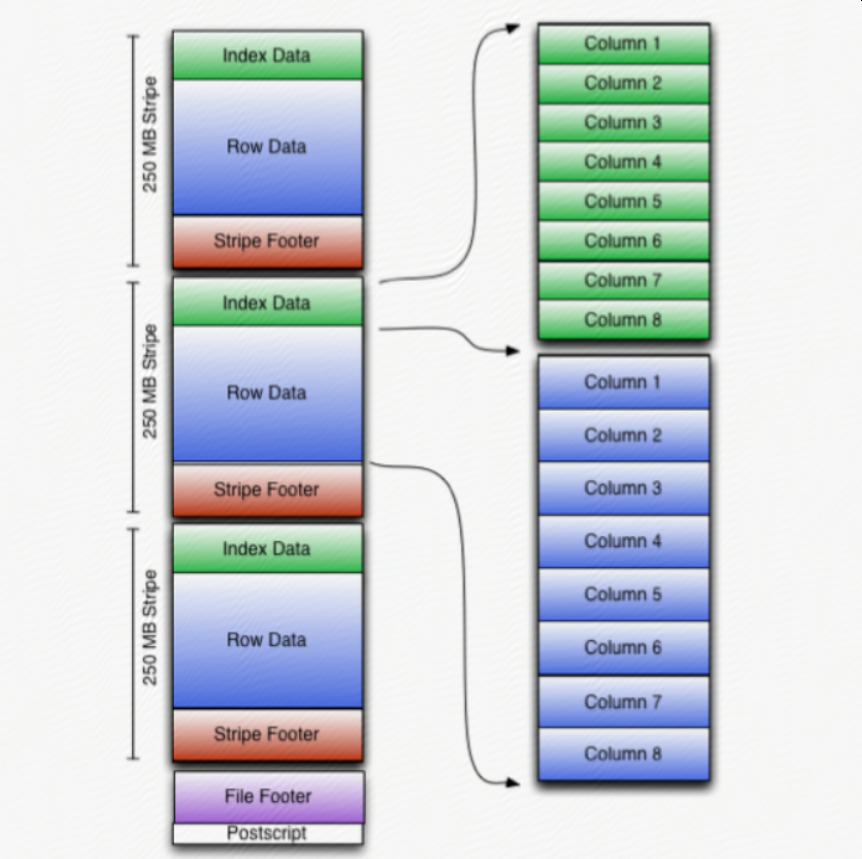
行列混合存储
层次结构:
file -> stripes -> row groups(10000 rows)
Background
Back in January 2013, we created ORC files as part of the initiative to massively speed up Apache Hive and improve the storage efficiency of data stored in Apache Hadoop. The focus was on enabling high speed processing and reducing file sizes.
ORC是为了加速hive查询以及节省hadoop磁盘空间而生的;
ORC is a self-describing type-aware columnar file format designed for Hadoop workloads. It is optimized for large streaming reads, but with integrated support for finding required rows quickly. Storing data in a columnar format lets the reader read, decompress, and process only the values that are required for the current query. Because ORC files are type-aware, the writer chooses the most appropriate encoding for the type and builds an internal index as the file is written.
ORC是一种自描述的列式存储文件类型,它为了大规模流式读取而特别优化,同时也支持快速定位需要的行;列式存储使得reader可以只读取、解压和处理他们需要的值;
Predicate pushdown uses those indexes to determine which stripes in a file need to be read for a particular query and the row indexes can narrow the search to a particular set of 10,000 rows. ORC supports the complete set of types in Hive, including the complex types: structs, lists, maps, and unions.
( In ORC, the minimum and maximum values of each column are recorded per file, per stripe (~1M rows), and every 10,000 rows. Using this information, the reader should skip any segment that could not possibly match the query predicate.
Predicate pushdown is amazing when it works, but for a lot of data sets, it doesn't work at all. If the data has a large number of distinct values and is well-shuffled, the minimum and maximum stats will cover almost the entire range of values, rendering predicate pushdown ineffective. )
Predicate Pushdown谓词下推,是一个来自RDBMS的概念,即在不影响结果的前提下,尽量将过滤条件提前执行,这样可以显著减少过程中的数据量;
ORC的Predicate Pushdown使用index来判断在一个file中哪些stripes需要被读取,并且可以将查询范围缩小到10000行的集合;实现原理在ORC中,每个file/每个stripe/每10000行,都有索引会记录该数据范围内每列最大最小值等统计信息,所以可以很容易的根据查询条件判断是否需要读取相应的file/stripe/10000行;
ORC支持hive中所有的数据类型;
ORC files are divided in to stripes that are roughly 64MB by default. The stripes in a file are independent of each other and form the natural unit of distributed work. Within each stripe, the columns are separated from each other so the reader can read just the columns that are required.
ORC file会被分块成为多个stripes,每个stripes大概64M,大概100w行;一个文件中的不同stripes是相互独立的;在一个stripe中,不同的列也是分开存储的;
ORC uses type specific readers and writers that provide light weight compression techniques such as dictionary encoding, bit packing, delta encoding, and run length encoding – resulting in dramatically smaller files. Additionally, ORC can apply generic compression using zlib, or Snappy on top of the lightweight compression for even smaller files. However, storage savings are only part of the gain. ORC supports projection, which selects subsets of the columns for reading, so that queries reading only one column read only the required bytes. Furthermore, ORC files include light weight indexes that include the minimum and maximum values for each column in each set of 10,000 rows and the entire file. Using pushdown filters from Hive, the file reader can skip entire sets of rows that aren’t important for this query.
ORC使用类型相关的reader和writer来提供轻量级的压缩技术,结果是文件尺寸被极大的缩小了;除此之外,ORC还可以在内置轻量级压缩的基础上使用常用的压缩格式比如zlib、snappy等;
ORC stores the top level index at the end of the file. The overall structure of the file is given in the figure above. The file’s tail consists of 3 parts; the file metadata, file footer and postscript.
The metadata for ORC is stored using Protocol Buffers, which provides the ability to add new fields without breaking readers.
ORC在文件的末尾存储顶级index;文件末尾包含3个部分:metadata、footer、postscript;metadata是使用Protocol Buffer格式(可以增加新的列并且不影响读旧数据)存储的;
Stripes
The body of ORC files consists of a series of stripes. Stripes are large (typically ~200MB) and independent of each other and are often processed by different tasks. The defining characteristic for columnar storage formats is that the data for each column is stored separately and that reading data out of the file should be proportional to the number of columns read.
每一个ORC file都包含多个stripes,stripes之间相互独立,可以被不同的任务并行处理;
In ORC files, each column is stored in several streams that are stored next to each other in the file.
The stripe footer contains the encoding of each column and the directory of the streams including their location.
Stripes have three sections: a set of indexes for the rows within the stripe, the data itself, and a stripe footer. Both the indexes and the data sections are divided by columns so that only the data for the required columns needs to be read.
stripes有3个部分:index集合、data、footer;其中index和data中,列和列之间都是分开存放的;
The row group indexes consist of a ROW_INDEX stream for each primitive column that has an entry for each row group. Row groups are controlled by the writer and default to 10,000 rows. Each RowIndexEntry gives the position of each stream for the column and the statistics for that row group.
row group默认是10000行;
Bloom Filters are added to ORC indexes from Hive 1.2.0 onwards. Predicate pushdown can make use of bloom filters to better prune the row groups that do not satisfy the filter condition. A BLOOM_FILTER stream records a bloom filter entry for each row group (default to 10,000 rows) in a column. Only the row groups that satisfy min/max row index evaluation will be evaluated against the bloom filter index.
从hive1.2开始,Bloom Filter被引入,可以更好的支持Predicate Pushdown;
【原创】大数据基础之ORC(1)简介的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
随机推荐
- TypeError: argument to reversed() must be a sequence ERROR basehttp 124 "GET /admin/ HTTP/1.1" 500 114103 Performing system checks...
Error Msg TypeError: argument to reversed() must be a sequence ERROR basehttp 124 "GET /admin/ ...
- JS--编码规范
1. 请修复给定的 js 代码中,函数定义存在的问题 function functions(flag) { if (flag) { function getValue() { return 'a'; ...
- [Alpha阶段]第五次Scrum Meeting
Scrum Meeting博客目录 [Alpha阶段]第五次Scrum Meeting 基本信息 名称 时间 地点 时长 第五次Scrum Meeting 19/04/09 教1_2楼教室 65min ...
- 磁盘IO的性能指标 阻塞与非阻塞、同步与异步 I/O模型
磁盘IO的性能指标 - 蝈蝈俊 - 博客园https://www.cnblogs.com/ghj1976/p/5611648.html 阻塞与非阻塞.同步与异步 I/O模型 - 蝈蝈俊.net - C ...
- Shell命令-文件及内容处理之cut、rev
文件及内容处理 - cut.rev 1. cut:切割文件内容 cut命令的功能说明 cut 命令用于显示每行从开头算起num1 到 num2 的文字. cut命令的语法格式 cut [OPTION] ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):1. 自定义窗口部件 (widget)
1. 框架代码 用 PyCharm 新建一个名为 SimplePaintApp 的项目,然后新建一个名为 simple_paint_app.py 的 Python 源文件, 在代码编辑器中,输入以下框 ...
- Magento2自定义命令
命令命名准则 命名指南概述 Magento 2引入了一个新的命令行界面(CLI),使组件开发人员能够插入模块提供的命令. Command name Command name 在命令中,它紧跟在命令的名 ...
- 【转】Esp8266学习之旅① 搭建开发环境,开始一个“hellow world”串口打印。
@2019-02-28 [小记] Esp8266学习之旅① 搭建开发环境,开始一个“hellow world”串口打印.
- HashMap初认识
什么是HashSet? 它实现了Set接口,HashSet是Set集合的子类 有哈希表支持的,元素不可重复的哈希码值(实际上是一个HashMap的实例). 它不保证set的迭代顺序(遍历元素的顺序), ...
- LoadRunner【第四篇】参数化
参数化的定义及使用场景 定义:将脚本中的特定值用变量替代,该变量值是变化的(注意:这个值是我们自己创建的,不是服务器返回的). 使用参数化: 1.业务考虑,不允许相同信息 2.真实模拟不同用户 3.真 ...