阿里HBase高可用8年“抗战”回忆录
2017年开始阿里HBase走向公有云,我们有计划的在逐步将阿里内部的高可用技术提供给外部客户,目前已经上线了同城主备,将作为我们后续高可用能力发展的一个基础平台。本文分四个部分回顾阿里HBase在高可用方面的发展:大集群、MTTF&MTTR、容灾、极致体验,希望能给大家带来一些共鸣和思考。
大集群
一个业务一个集群在初期很简便,但随着业务增多会加重运维负担,更重要的是无法有效利用资源。首先每一个集群都要有Zookeeper、Master、NameNode这三种角色,固定的消耗3台机器。其次有些业务重计算轻存储,有些业务重存储轻计算,分离模式无法削峰填谷。因此从2013年开始阿里HBase就走向了大集群模式,单集群节点规模达到700+。
隔离性是大集群的关键难题。保障A业务异常流量不会冲击到B业务,是非常重要的能力,否则用户可能拒绝大集群模式。阿里HBase引入了分组概念“group”,其核心思想为:共享存储、隔离计算
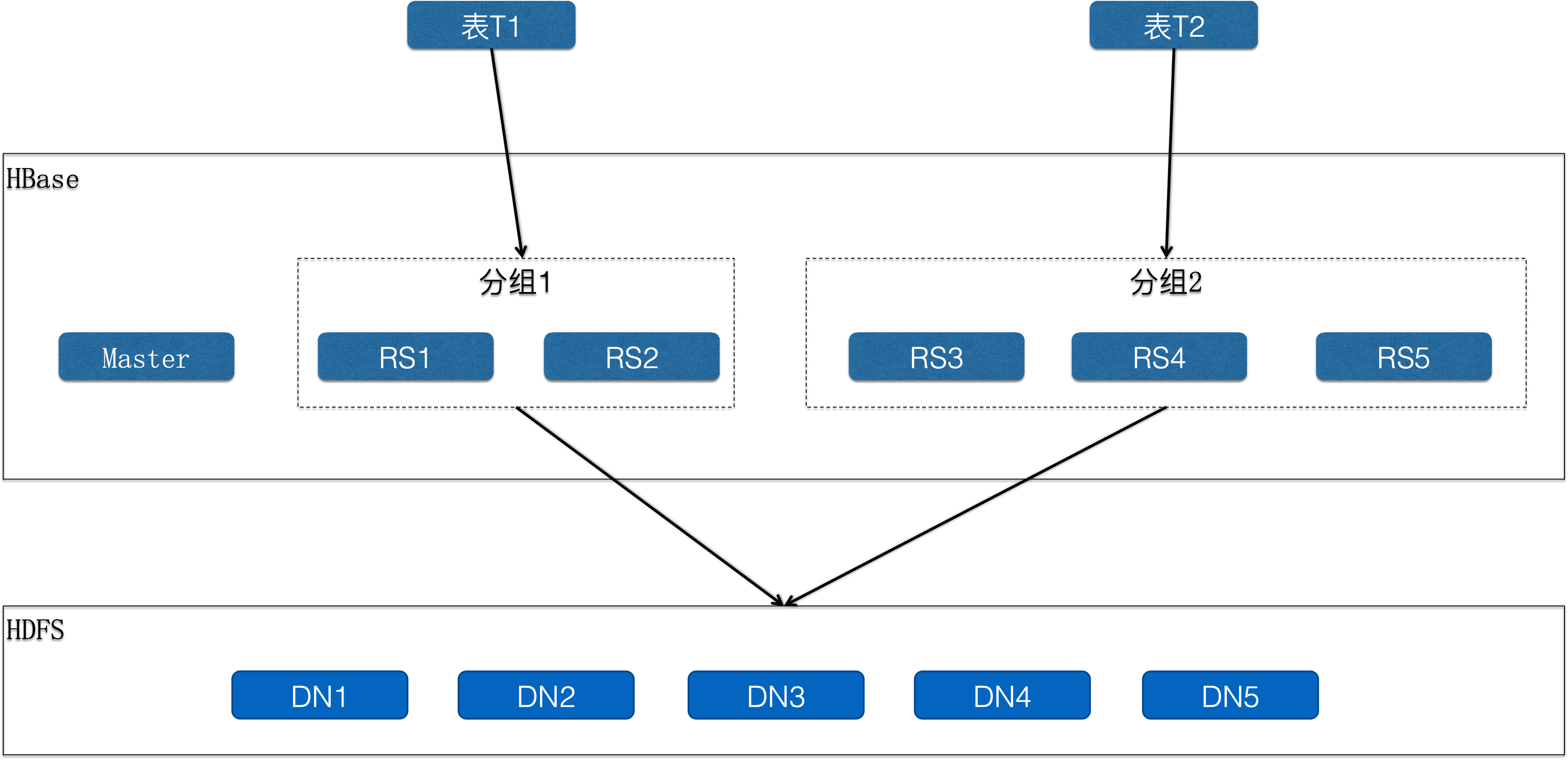
如上图所示,一个集群内部被划分成多个分组,一个分组至少包含一台服务器,一个服务器同一时间只能属于一个分组,但是允许服务器在分组之间进行转移,也就是分组本身是可以扩容和缩容的。一张表只能部署在一个分组上,可以转移表到其它的分组。可以看到,表T1读写经过的RegionServer和表T2读写经过的RegionServer是完全隔离的,因此在CPU、内存上都物理隔离,但是下层使用的HDFS文件系统是共享的,因此多个业务可以共享一个大的存储池子,充分提升存储利用率。开源社区在HBase2.0版本上引入了RegionServerGroup。
坏盘对共享存储的冲击:由于HDFS机制上的特点,每一个Block的写入会随机选择3个节点作为Pipeline,如果某一台机器出现了坏盘,那么这个坏盘可能出现在多个Pipeline中,造成单点故障全局抖动。现实场景中就是一块盘坏,同一时间影响到几十个客户给你发信息打电话!特别如果慢盘、坏盘不及时处理,最终可能导致写入阻塞。阿里HBase目前规模在1万+台机器,每周大概有22次磁盘损坏问题。我们在解决这个问题上做了两件事,第一是缩短影响时间,对慢盘、坏盘进行监控报警,提供自动化处理平台。第二是在软件上规避单点坏盘对系统的影响,在写HDFS的时候并发的写三个副本,只要两个副本成功就算成功,如果第三个副本超时则将其放弃。另外如果系统发现写WAL异常(副本数少于3)会自动滚动产生一个新的日志文件(重新选择pipeline,大概率规避坏点)。最后HDFS自身在高版本也具备识别坏盘和自动剔除的能力。
客户端连接对Zookeeper的冲击:客户端访问hbase会和Zookeeper建立长连接,HBase自身的RegionServer也会和Zookeeper建立长连接。大集群意味着大量业务,大量客户端的链接,在异常情况下客户端的链接过多会影响RegionServer与Zookeeper的心跳,导致宕机。我们在这里的应对首先是对单个IP的链接数进行了限制,其次提供了一种分离客户端与服务端链接的方案 HBASE-20159
MTTF&MTTR
稳定性是生命线,随着阿里业务的发展,HBase逐步扩大在线场景的支持,对稳定性的要求是一年更比一年高。衡量系统可靠性的常用指标是MTTF(平均失效时间)和MTTR(平均恢复时间)
MTTF(mean time to failure)
造成系统失效的来源有:
硬件失效,比如坏盘、网卡损坏、机器宕机等
自身缺陷,一般指程序自身的bug或者性能瓶颈
运维故障,由于不合理的操作导致的故障
服务过载,突发热点、超大的对象、过滤大量数据的请求
依赖失效,依赖的HDFS、Zookeeper组件出现不可用导致HBase进程退出
下面我介绍一下阿里云HBase在稳定性上遇到的几个代表性问题:(注:慢盘、坏盘的问题已经在大集群一节中涉及,这里不再重复)
- 周期性的FGC导致进程退出
在支持菜鸟物流详情业务的时候,我们发现机器大概每隔两个月就会abort一次,因为内存碎片化问题导致Promotion Fail,进而引发FGC。由于我们使用的内存规格比较大,所以一次FGC的停顿时间超过了与Zookeeper的心跳,导致ZK session expired,HBase进程自杀。我们定位问题是由于BlockCache引起的,由于编码压缩的存在,内存中的block大小是不一致的,缓存的换入换出行为会逐步的切割内存为非常小的碎片。我们开发了BucketCache,很好的解决了内存碎片化的问题,然后进一步发展了SharedBucketCache,使得从BlockCache里面反序列化出来的对象可以被共享复用,减少运行时对象的创建,从而彻底的解决了FGC的问题。
- 写入HDFS失败导致进程退出
HBase依赖俩大外部组件,Zookeeper和HDFS。Zookeeper从架构设计上就是高可用的,HDFS也支持HA的部署模式。当我们假设一个组件是可靠的,然后基于这个假设去写代码,就会产生隐患。因为这个“可靠的”组件会失效,HBase在处理这种异常时非常暴力,立即执行自杀(因为发生了不可能的事情),寄希望于通过Failover来转移恢复。有时HDFS可能只是暂时的不可用,比如部分Block没有上报而进入保护模式,短暂的网络抖动等,如果HBase因此大面积重启,会把本来10分钟的影响扩大到小时级别。我们在这个问题上的方案是优化异常处理,对于可以规避的问题直接处理掉,对于无法规避的异常进行重试&等待。
- 并发大查询导致机器停摆
HBase的大查询,通常指那些带有Filter的Scan,在RegionServer端读取和过滤大量的数据块。如果读取的数据经常不在缓存,则很容易造成IO过载;如果读取的数据大多在缓存中,则很容易因为解压、序列化等操作造成CPU过载;总之当有几十个这样的大请求并发的在服务器端执行时,服务器load会迅速飙升,系统响应变慢甚至表现的像卡住了。这里我们研发了大请求的监控和限制,当一个请求消耗资源超过一定阈值就会被标记为大请求,日志会记录。一个服务器允许的并发大请求存在上限,如果超过这个上限,后来的大请求就会被限速。如果一个请求在服务器上运行了很久都没有结束,但客户端已经判断超时,那么系统会主动中断掉这个大请求。该功能的上线解决了支付宝账单系统因为热点查询而导致的性能抖动问题。
- 大分区Split缓慢
在线上我们偶尔会遇到某个分区的数量在几十GB到几个TB,一般都是由于分区不合理,然后又在短时间内灌入了大量的数据。这种分区不但数据量大,还经常文件数量超级多,当有读落在这个分区时,一定会是一个大请求,如果不及时分裂成更小的分区就会造成严重影响。这个分裂的过程非常慢,HBase只能从1个分区分裂为2个分区,并且要等待执行一轮Compaction才能进行下一轮分裂。假设分区大小1TB,那么分裂成小于10GB的128个分区需要分裂7轮,每一轮要执行一次Compaction(读取1TB数据,写出1TB数据),而且一个分区的Compaction只能由一台机器执行,所以第一轮最多只有2台机器参与,第二轮4台,第三轮8台。。。,并且实际中需要人为干预balance。整个过程做下来超过10小时,这还是假设没有新数据写入,系统负载正常。面对这个问题我们设计了“级联分裂”,可以不执行Compaction就进入下一次分裂,先快速的把分区拆分完成,然后一把执行Compaction。
前面讲的都是点,关于如何解决某个顽疾。导致系统失效的情况是多种多样的,特别一次故障中可能交叉着多个问题,排查起来异常困难。现代医学指出医院应当更多投入预防而不是治疗,加强体检,鼓励早就医。早一步也许就是个感冒,晚一步也许就变成了癌症。这也适用于分布式系统,因为系统的复杂性和自愈能力,一些小的问题不会立即造成不可用,比如内存泄漏、Compaction积压、队列积压等,但终将在某一刻引发雪崩。应对这种问题,我们提出了“健康诊断”系统,用来预警那些暂时还没有使系统失效,但明显超过正常阈值的指标。“健康诊断”系统帮助我们拦截了大量的异常case,也在不停的演进其诊断智能。
MTTR(mean time to repair)
百密终有一疏,系统总是会失效,特别的像宕机这种Case是低概率但一定会发生的事件。我们要做的是去容忍,降低影响面,加速恢复时间。HBase是一个可自愈的系统,单个节点宕机触发Failover,由存活的其它节点来接管分区服务,在分区对外服务之前,必须首先通过回放日志来保证数据读写一致性。整个过程主要包括Split Log、Assign Region、Replay Log三个步骤。hbase的计算节点是0冗余,所以一个节点宕机,其内存中的状态必须全部回放,这个内存一般可以认为在10GB~20GB左右。我们假设整个集群的数据回放能力是 R GB/s,单个节点宕机需要恢复 M GB的数据,那么宕机N个节点就需要 M * N / R 秒,这里表达的一个信息是:如果R不足够大,那么宕机越多,恢复时间越不可控,那么影响R的因素就至关重要,在Split Log、Assign Region、Replay Log三个过程中,通常Split Log、Assign Region的扩展性存在问题,核心在于其依赖单点。Split Log是把WAL文件按分区拆分成小的文件,这个过程中需要创建大量的新文件,这个工作只能由一台NameNode来完成,并且其效率也并不高。Assign Region是由HBase Master来管理,同样是一个单点。阿里HBase在Failover方面的核心优化是采用了全新的MTTR2架构,取消了Split Log这一步骤,在Assign Region上也做了优先Meta分区、Bulk Assign、超时优化等多项优化措施,相比社区的Failover效率提升200%以上
从客户角度看故障,是2分钟的流量跌零可怕还是10分钟的流量下降5%可怕?我想可能是前者。由于客户端的线程池资源有限,HBase的单机宕机恢复过程可能造成业务侧的流量大跌,因为线程都阻塞在访问异常机器上了,2%的机器不可用造成业务流量下跌90%是很难接受的。我们在客户端开发了一种Fast Fail的机制,可以主动发现异常服务器,并快速拒绝发往这个服务器的请求,从而释放线程资源,不影响其它分区服务器的访问。项目名称叫做DeadServerDetective
容灾
容灾是重大事故下的求生机制,比如地震、海啸等自然灾害造成毁灭性打击,比如软件变更等造成完全不可控的恢复时间,比如断网造成服务瘫痪、恢复时间未知。从现实经验来看,自然灾害在一个人的一生中都难遇到,断网一般是一个年级别的事件,而软件变更引发的问题可能是月级别的。软件变更是对运维能力、内核能力、测试能力等全方位的考验,变更过程的操作可能出错,变更的新版本可能存在未知Bug。另一个方面为了不断满足业务的需求又需要加速内核迭代,产生更多的变更。
容灾的本质是基于隔离的冗余,要求在资源层面物理隔离、软件层面版本隔离、运维层面操作隔离等,冗余的服务之间保持最小的关联性,在灾难发生时至少有一个副本存活。阿里HBase在几年前开始推进同城主备、异地多活,目前99%的集群至少有一个备集群,主备集群是HBase可以支持在线业务的一个强保障。主备模式下的两个核心问题是数据复制和流量切换
数据复制
选择什么样的复制方式,是同步复制还是异步复制,是否要保序?主要取决于业务对系统的需求,有些要求强一致,有些要求session一致,有些可以接受最终一致。占在HBase的角度上,我们服务的大量业务在灾难场景下是可以接受最终一致性的(我们也研发了同步复制机制,但只有极少的场景),因此本文主要专注在异步复制的讨论上。很长一段时间我们采用社区的异步复制机制(HBase Replication),这是HBase内置的同步机制。
同步延迟的根因定位是第一个难题,因为同步链路涉及发送方、通道、接受方3个部分,排查起来有难度。我们增强了同步相关的监控和报警。
热点容易引发同步延迟是第二个难题。HBase Replication采用推的方式进行复制,读取WAL日志然后进行转发,发送线程和HBase写入引擎是在同一台RegionServer的同一个进程里。当某台RegionServer写入热点时,就需要更多的发送能力,但写入热点本身就挤占了更多的系统资源,写入和同步资源争抢。阿里HBase做了两个方面的优化,第一提高同步性能,减少单位MB同步的资源消耗;第二研发了远程消耗器,使其它空闲的机器可以协助热点机器同步日志。
资源需求、迭代方式的不匹配是第三个难题。数据复制本身是不需要磁盘IO的,只消耗带宽和CPU,而HBase对磁盘IO有重要依赖;数据复制的worker本质上是无状态的,重启不是问题,可以断点续传,而HBase是有状态的,必须先转移分区再重启,否则会触发Failover。一个轻量级的同步组件和重量级的存储引擎强耦合在一起,同步组件的每一次迭代升级必须同时重启HBase。一个重启就可以解决的同步问题,因为同时要重启hbase而影响线上读写。一个扩容CPU或者总带宽的问题被放大到要扩容hbase整体。
综上所述,阿里HBase最终将同步组件剥离了出来作为一个独立的服务来建设,解决了热点和耦合的问题,在云上这一服务叫做BDS Replication。随着异地多活的发展,集群之间的数据同步关系开始变得复杂,为此我们开发了一个关于拓扑关系和链路同步延迟的监控,并且在类环形的拓扑关系中优化了数据的重复发送问题。
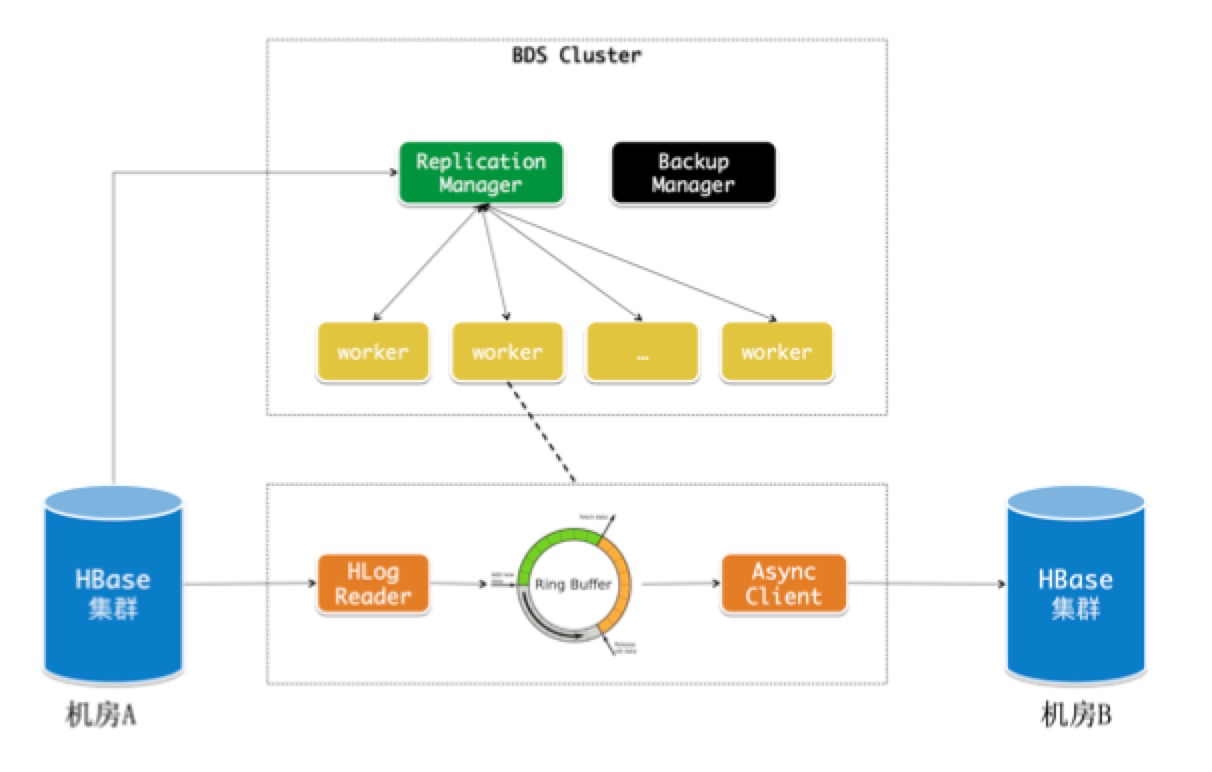
BDS Replication
流量切换
在具备主备集群的前提下,灾难期间需要快速的把业务流量切换到备份集群。阿里HBase改造了HBase客户端,流量的切换发生在客户端内部,通过高可用的通道将切换命令发送给客户端,客户端会关闭旧的链接,打开与备集群的链接,然后重试请求。
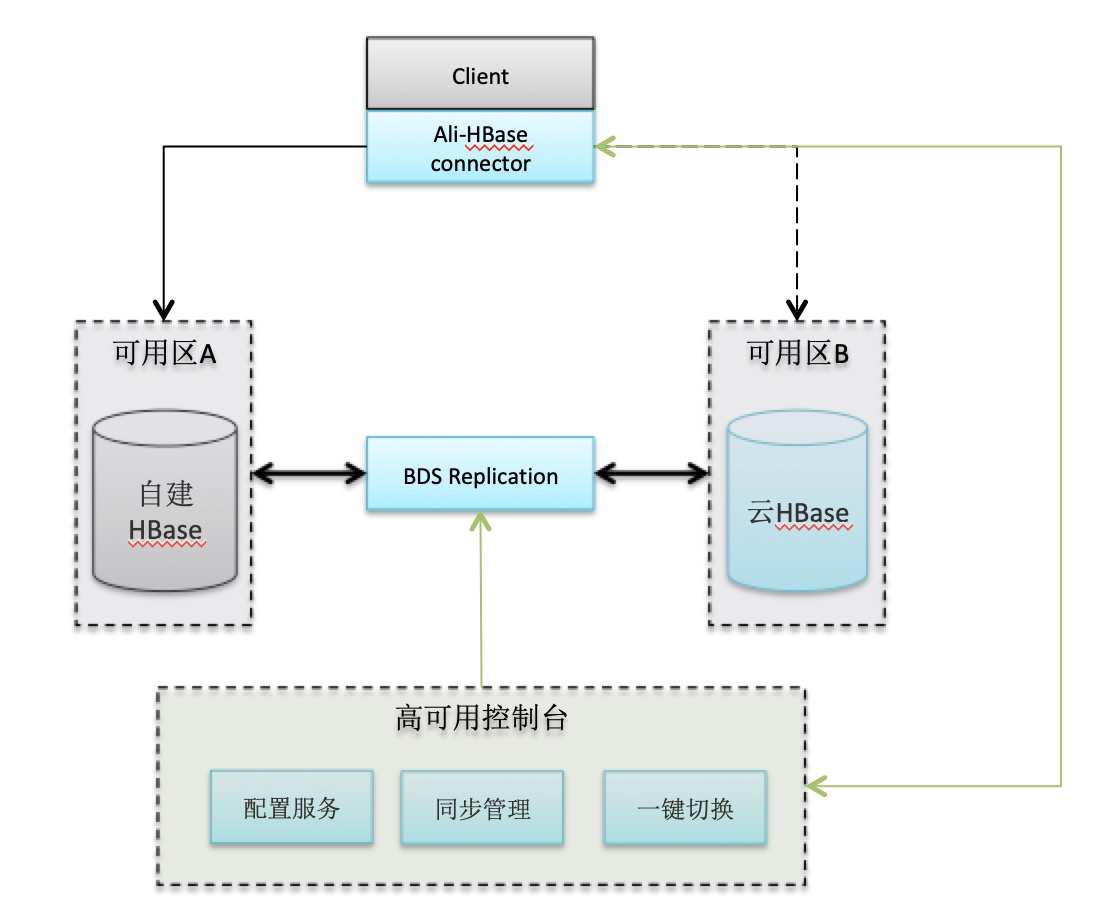
阿里云同城主备
切换瞬间对Meta服务的冲击:hbase客户端首次访问一个分区前需要请求Meta服务来获取分区的地址,切换瞬间所有客户端并发的访问Meta服务,现实中并发可能在几十万甚至更多造成服务过载,请求超时后客户端又再次重试,造成服务器一直做无用功,切换一直无法成功。针对这个问题我们改造了Meta表的缓存机制,极大地提高了Meta表的吞吐能力,可以应对百万级别的请求。同时在运维上隔离了Meta分区与数据分区,防止相互影响。
从一键切换走向自动切换。一键切换还是要依赖报警系统和人工操作,现实中至少也要分钟级别才能响应,如果是晚上可能要10分钟以上。阿里HBase在演进自动切换过程中有两个思路,最早是通过增加一个第三方仲裁,实时的给每一个系统打健康分数,当系统健康分低于一个阈值,并且其备库是健康的情况下,自动执行切换命令。这个仲裁系统还是比价复杂的,首先其部署上要保持网络独立,其次其自身必须是高可靠的,最后健康分的正确性需要保证。仲裁系统的健康判断是从服务器视角出发的,但从客户端角度来讲,有些时候服务器虽然活着但是已经不正常工作了,可能持续的FGC,也可能出现了持续网络抖动。所以第二个思路是在客户端进行自动切换,客户端通过失败率或其它规则来判定可用性,超过一定阈值则执行切换。
极致体验
在风控和推荐场景下,请求的RT越低,业务在单位时间内可以应用的规则就越多,分析就越准确。要求存储引擎高并发、低延迟、低毛刺,要高速且平稳的运行。阿里HBase团队在内核上研发CCSMAP优化写入缓存,SharedBucketCache优化读取缓存,IndexEncoding优化块内搜索,加上无锁队列、协程、ThreadLocal Counter等等技术,再结合阿里JDK团队的ZGC垃圾回收算法,在线上做到了单集群P999延迟小于15ms。另一个角度上,风控和推荐等场景并不要求强一致,其中有一些数据是离线导入的只读数据,所以只要延迟不大,可以接受读取多个副本。如果主备两个副本之间请求毛刺是独立事件,那么理论上同时访问主备可以把毛刺率下降一个数量级。我们基于这一点,利用现有的主备架构,研发了DualService,支持客户端并行的访问主备集群。在一般情况下,客户端优先读取主库,如果主库一定时间没有响应则并发请求到备库,然后等待最先返回的请求。DualService的应用获得的非常大的成功,业务接近零抖动。
主备模式下还存在一些问题。切换的粒度是集群级别的,切换过程影响大,不能做分区级别切换是因为主备分区不一致;只能提供最终一致性模型,对于一些业务来讲不好写代码逻辑;加上其它因素(索引能力,访问模型)的推动,阿里HBase团队基于HBase演进了自研的Lindorm引擎,提供一种内置的双Zone部署模式,其数据复制采用推拉组合的模式,同步效率大大提升;双Zone之间的分区由GlobalMaster协调,绝大部分时间都是一致的,因此可以实现分区级别切换;Lindorm提供强一致、Session一致、最终一致等多级一致性协议,方便用户实现业务逻辑。目前大部分阿里内部业务已经切换到Lindorm引擎。
零抖动是我们追求的最高境界,但必须认识到导致毛刺的来源可以说无处不在,解决问题的前提是定位问题,对每一个毛刺给出解释既是用户的诉求也是能力的体现。阿里HBase开发了全链路Trace,从客户端、网络、服务器全链路监控请求,丰富详尽的Profiling将请求的路径、资源访问、耗时等轨迹进行展示,帮助研发人员快速定位问题。
总结
本文介绍了阿里HBase在高可用上的一些实践经验,结尾之处与大家分享一些看可用性建设上的思考,抛砖引玉希望欢迎大家讨论。
从设计原则上
- 1 面向用户的可用性设计,在影响面、影响时间、一致性上进行权衡
MTTF和MTTR是一类衡量指标,但这些指标好不一定满足用户期望,这些指标是面向系统本身而不是用户的。 - 2 面向失败设计,你所依赖的组件总是会失败
千万不要假设你依赖的组件不会失败,比如你确信HDFS不会丢数据,然后写了一个状态机。但实际上如果多个DN同时宕机数据就是会丢失,此时可能你的状态机永远陷入混乱无法推进。再小概率的事件总是会发生,对中标的用户来讲这就是100%。
从实现过程上
- 完善的监控体系
监控是基础保障,是最先需要投入力量的地方。100%涵盖故障报警,先于用户发现问题是监控的第一任务。其次监控需要尽可能详细,数据展示友好,可以极大的提高问题定位能力。 - 基于隔离的冗余
冗余是可用性上治本的方法,遇到未知问题,单集群非常难保障SLA。所以只要不差钱,一定至少来一套主备。 - 精细的资源控制
系统的异常往往是因为资源使用的失控,对CPU、内存、IO的精细控制是内核高速稳定运行的关键。需要投入大量的研发资源去迭代。 - 系统自我保护能力
在请求过载的情况下,系统应该具备类如Quota这样的自我保护能力,防止雪崩发生。系统应该能识别一些异常的请求,进行限制或者拒绝。 - Trace能力
实时跟踪请求轨迹是排查问题的利器,需要把Profiling做到尽量详细
本文作者: Roin123
本文为云栖社区原创内容,未经允许不得转载。
阿里HBase高可用8年“抗战”回忆录的更多相关文章
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- HBase高可用原理与实践
前言 前段时间有套线上HBase出了点小问题,导致该套HBase集群服务停止了2个小时,从而造成使用该套HBase作为数据存储的应用也出现了服务异常.在排查问题之余,我们不禁也在思考,以后再出现类似的 ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- 大数据高可用集群环境安装与配置(07)——安装HBase高可用集群
1. 下载安装包 登录官网获取HBase安装包下载地址 https://hbase.apache.org/downloads.html 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 阿里云HBase推出普惠性高可用服务,独家支持用户的自建、混合云环境集群
HBase可以支持百TB数据规模.数百万QPS压力下的毫秒响应,适用于大数据背景下的风控和推荐等在线场景.阿里云HBase服务了多家金融.广告.媒体类业务中的风控和推荐,持续的在高可用.低延迟.低成本 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- HBase Master HA高可用
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行. 所以这里要配置HBase高可用的话,只需要 ...
- HBase Master高可用(HA)
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行. 所以这里要配置HBase高可用的话,只需要 ...
随机推荐
- navicat12过期问题,Windows平台。
首先关闭Navicat 然后 win+R,输入regedit 回车,打开注册表编辑器: 删除HKEY_CURRENT_USER\Software\PremiumSoft\Data 展开HKEY_CUR ...
- JS中数据结构之链表
1.链表的基本介绍 数组不总是组织数据的最佳数据结构,在很多编程语言中,数组的长度是固定的,所以当数组已被数据填满时,再要加入新的元素就会非常困难.在数组中,添加和删除元素也很麻烦,因为需要将数组中的 ...
- vue中的文件上传和下载
文件上传 vue中的文件上传主要分为两步:前台获取到文件和提交到后台 获取文件 前台获取文件,主要是采用input框来实现 <el-dialog :title="addName&quo ...
- 15 个最佳 jQuery 翻书效果插件
本文为你带来15个非常实用的.实现类似翻书效果的jQuery插件,你可以很容易地整合到你的web应用中,提升用户体验. 1. BookBlock BookBlock可以将任何内容(如图像.文本)创建 ...
- java配置和tomcat安装
原文: https://www.cnblogs.com/lwjboke/p/7089126.html 下载: jdk历史版本 下载地址: http://www.oracle.com/technetwo ...
- [CSP-S模拟测试]:小奇挖矿2(DP+赛瓦维斯特定理)
题目背景 小奇飞船的钻头开启了无限耐久+精准采集模式!这次它要将原矿运到泛光之源的矿石交易市场,以便为飞船升级无限非概率引擎. 题目描述 现在有$m+1$个星球,从左到右标号为$0$到$n$,小奇最初 ...
- 20175120彭宇辰 《Java程序设计》第十周学习总结
教材内容总结 十二章 Java多线程机制 一.进程与线程.操作系统与进程 -线程不是进程,是比进程更小的执行单位.但与进程不同的是,线程的中断和恢复可以更加节省系统的开销. -线程可以共享进程中的某些 ...
- Oracle -操作数据库
删除数据: delete:用delete删除记录,Oracle系统会产生回滚记录,所以这种操作可以使用ROLLBACK来撤销 truncate:删除数据时,不会产生回滚记录.所以执行速度相对较快些 可 ...
- Oracle 11g 概述
始于:1970.6月份的一篇论文,IBM研究员埃德加‘考特<大型共享数据库的关系模型>(也是转折点)1977.6月Larry Ellison Bob Miner Ed Oates创办了“软 ...
- Linux环境下对大小写敏感,linux环境升级node
linux对大小写敏感 在window下可以正常运行的代码,在linux环境下报错,找不到文件,因为window下对大小写不敏感,linux对大小写敏感 linux环境下node升级 1.安装nvm ...