R----tidyr包介绍学习
tidyr包:reshape2的替代者,功能更纯粹
tidyr包的应用
tidyr主要提供了一个类似Excel中数据透视表(pivot table)的功能;
gather和spread函数将数据在长格式和宽格式之间相互转化,应用在比如稀疏矩阵和稠密矩阵之间的转化;
separate和union方法提供了数据分组拆分、合并的功能,应用在nominal数据的转化上
R将整洁数据定义为:每个变量的数据存储在自身的列中,每个观测值的数据存储在其自身的行中。整洁数据是进行数据再加工的基础。
tidyr包主要涉及:
1)缺失值的简单补齐
2)长形表变宽形表与宽形表变长形表
gather-把宽度较大的数据转换成一个更长的形式,它类比于从reshape2包中融合函数的功能
spread-把长的数据转换成一个更宽的形式,它类比于从reshape2包中铸造函数的功能。
gather()相反的是spread(),前者将不同的列堆叠起来,后者将同一列分开
3)列分割与列合并
separate-将一列按分隔符分割为多列
unite-将多列按指定分隔符合并为一列
tidyr包:(gather(宽数据转为长数据)、spread(长数据转为宽数据)、unit(多列合并为一列)、separate(将一列分离为多列))
栗子:
1.载入包
# 使用datasets包中的mtcars数据集做演示
library(tidyr)
library(dplyr)
head(mtcars)
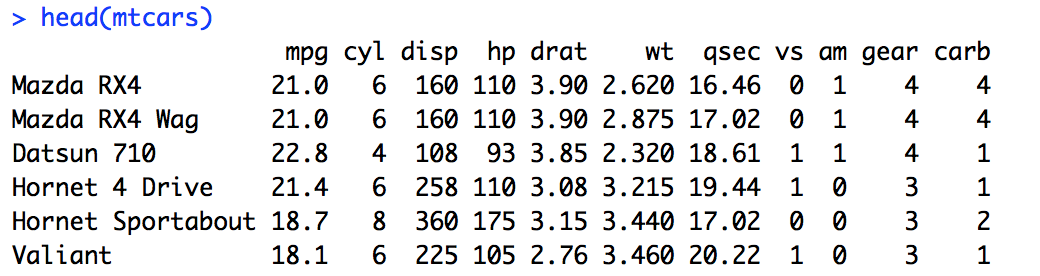
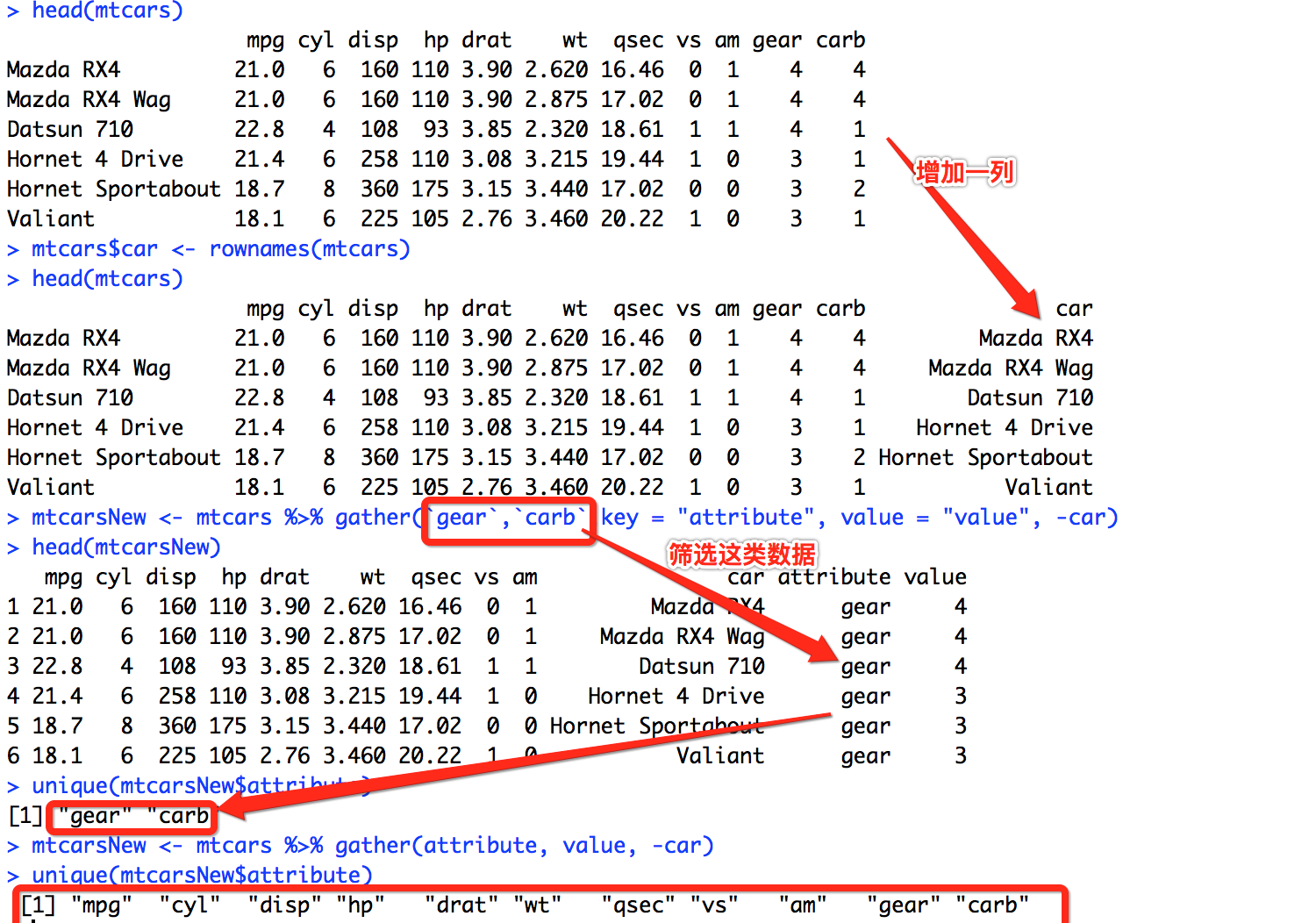
# 为方便处理,在数据集中增加一列car
mtcars$car <- rownames(mtcars)
mtcars <- mtcars[, c(12, 1:11)] #将添加的一列从最后一列移到最前列
head(mtcars)

2.gather--宽数据转为长数据
使用gather()函数实现宽表转长表,语法如下:
gather(data, key, value, …, na.rm = FALSE, convert = FALSE)
data:需要被转换的宽形表
key:将原数据框中的所有列赋给一个新变量key
value:将原数据框中的所有值赋给一个新变量value
…:可以指定哪些列聚到同一列中
na.rm:是否删除缺失值
开始使用:
# 除了car列外,其余列聚合成两列,分别命名为attribute和value
mtcarsNew <- mtcars %>% gather(attribute, value, -car)
head(mtcarsNew)
tail(mtcarsNew)
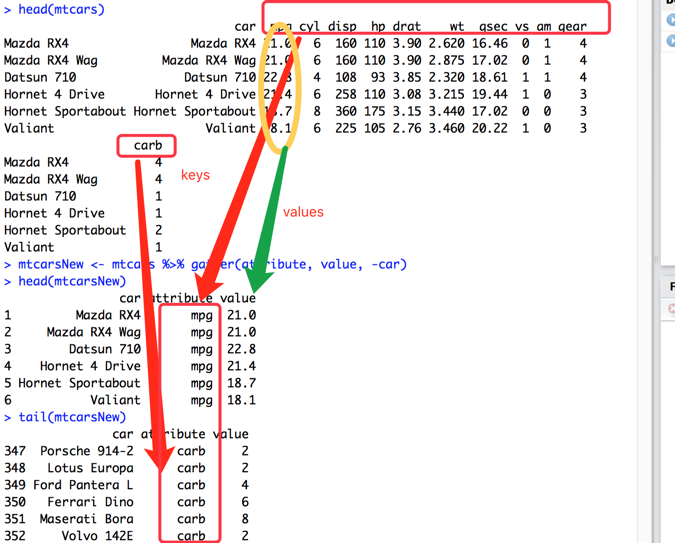
如你所见,除了car列外,其余列聚合成两列(一列对应列名,一列对应值),分别命名为attribute和value。
dplyr()利用%>%(链式操作)来改进:
链式操作是啥意思呢?
%>%的功能是用于实现将一个函数的输出传递给下一个函数的第一个参数。注意这里的,传递给下一个函数的第一个参数,然后就不用写第一个参数了。
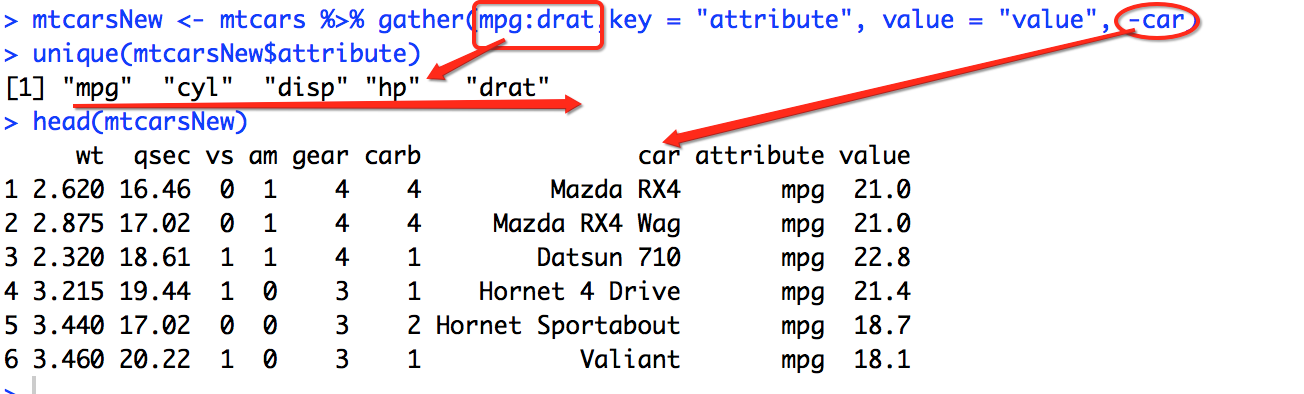
tidyr很好的一点是可以只gather若干列而其他列保持不变。如果你想gather在map和gear之间的所有列而保持carb和car列不变,可以像下面这样做:
# gather在map和gear之间的所有列,而保持carb和car列不变
mtcarsNew <- mtcars %>% gather(attribute, value, mpg:gear)
head(mtcarsNew)

连续筛选
不连续筛选
mtcarsNew <- mtcars %>% gather(`gear`,`carb`,key = "attribute", value = "value", -car)
head(mtcarsNew)
unique(mtcarsNew$attribute)
3.spread--长数据转为宽数据
有时,为了满足建模或绘图的要求,往往需要将长形表转换为宽形表,或将宽形表变为长形表。如何实现这两种数据表类型的转换。使用spread()函数实现长表转宽表,语法如下:
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
data:为需要转换的长形表
key:需要将变量值拓展为字段的变量
value:需要分散的值
fill:对于缺失值,可将fill的值赋值给被转型后的缺失值
使用:
mtcarsSpread <- mtcarsNew %>% spread(attribute, value)
head(mtcarsSpread)

注:各列的相互位置稍有调整.
4.unite--多列合并为一列
unite的调用格式如下:
unite(data, col, …, sep = “_”, remove = TRUE)
data:为数据框
col:被组合的新列名称
…:指定哪些列需要被组合
sep:组合列之间的连接符,默认为下划线
remove:是否删除被组合的列
其作用是将多列合并为一列,举例如下:
# 先虚构一数据框
set.seed(1)
date <- as.Date('2016-11-01') + 0:14
hour <- sample(1:24, 15)
min <- sample(1:60, 15)
second <- sample(1:60, 15)
event <- sample(letters, 15)
data <- data.table(date, hour, min, second, event)

# 把date,hour,min和second列合并为新列datetime
# R中的日期时间格式为"Year-Month-Day-Hour:Min:Second"
dataNew <- data %>%unite(datehour, date, hour, sep = ' ') %>%unite(datetime, datehour, min, second, sep = ':')
dataNew
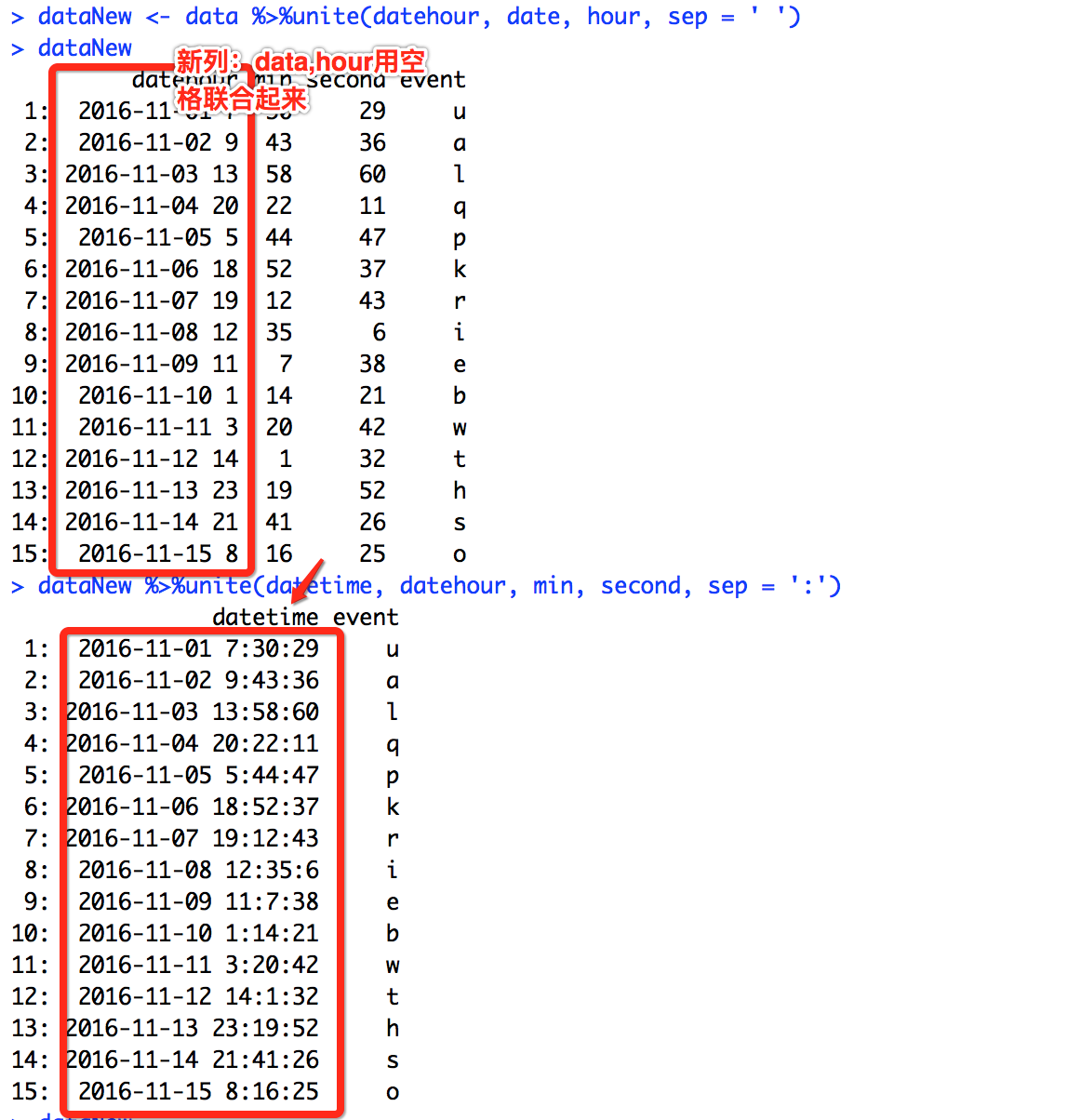
若不习惯使用链式方式,这样写也可:
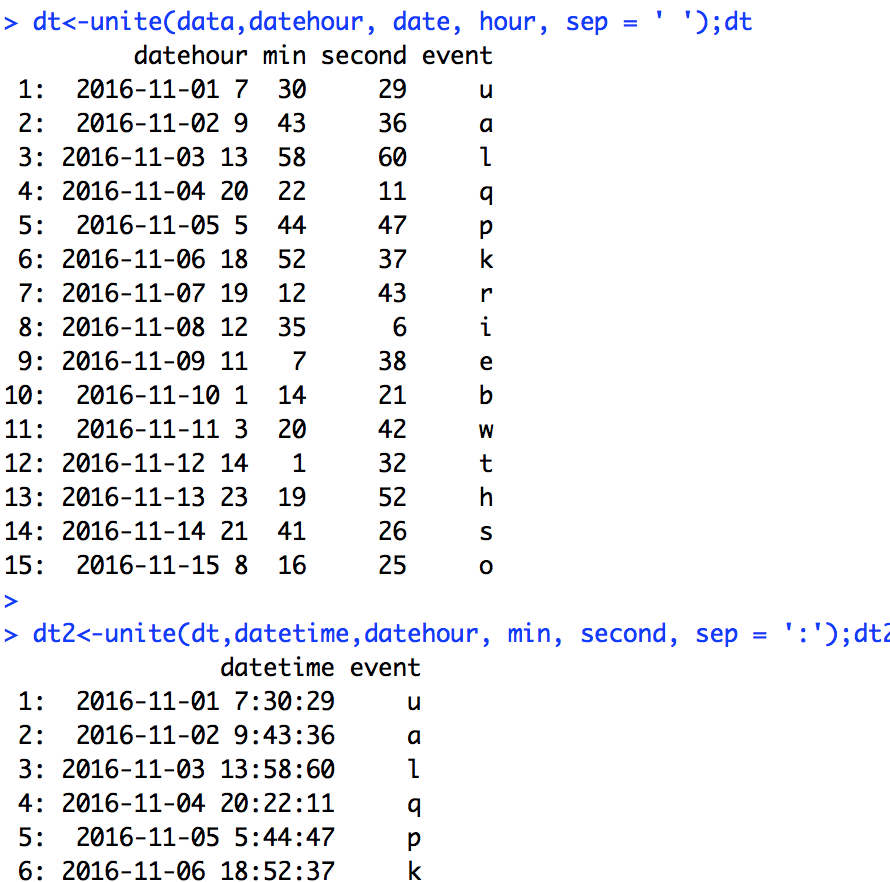
dt<-unite(data,datehour, date, hour, sep = ' ');dt
dt2<-unite(dt,datetime,datehour, min, second, sep = ':');dt2
5.separate--将一列分离为多列
separate()函数可将一列拆分为多列,一般可用于日志数据或日期时间型数据的拆分,语法如下:
separate(data, col, into, sep = “[^[:alnum:]]+”, remove = TRUE,
convert = FALSE, extra = “warn”, fill = “warn”, …)
data:为数据框
col:需要被拆分的列
into:新建的列名,为字符串向量
sep:被拆分列的分隔符
remove:是否删除被分割的列
举例如下:
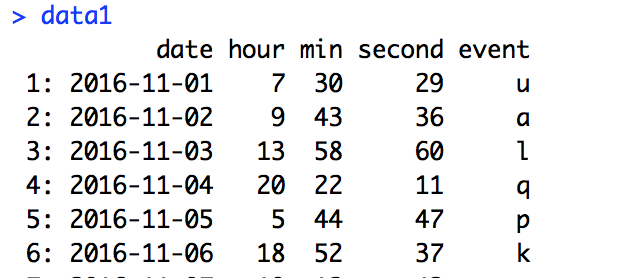
# 可以用separate函数将数据恢复到刚创建的时候
# 首先,将datetime分为date列和time列 然后,将time列分为hour,min,second列
data1 <- dataNew %>%separate(datetime, c('date', 'time'), sep = ' ') %>%separate(time, c('hour', 'min', 'second'), sep = ':')
data1
一、缺失值的简单补齐
library(tidyr)
创建含有缺失值的数据框示例
x <- c(1,2,7,8,NA,10,22,NA,15)
y <-c('a',NA,'b',NA,'b','a','a','b','a')
df <- data.table(x = x, y = y)
df
> x <- c(1,2,7,8,NA,10,22,NA,15)
> y <-c('a',NA,'b',NA,'b','a','a','b','a')
> df <- data.table(x = x, y = y)
> df
x y
1: 1 a
2: 2 NA
3: 7 b
4: 8 NA
5: NA b
6: 10 a
7: 22 a
8: NA b
9: 15 a
下面用x的均值或中位数替换缺失值,用y的众数替换缺失值。
计算x的均值和中位数
x_mean <- mean(df$x, na.rm = TRUE)
x_median <- median(df$x, na.rm = TRUE)
> x_mean <- mean(df$x, na.rm = TRUE);x_mean
[1] 9.285714
> x_median <- median(df$x, na.rm = TRUE);x_median
[1] 8
计算y的众数
y_mode <- as.character(df$y[which.max(table(df$y))])
> y_mode <- as.character(df$y[which.max(table(df$y))]);y_mode
[1] "a"
替换数据框df中x和y的缺失值
df2 <- replace_na(data = df, replace = list(x = x_mean, y = y_mode))
df2
> df2 <- replace_na(data = df, replace = list(x = x_mean, y = y_mode));df2
x y
1: 1.000000 a
2: 2.000000 a
3: 7.000000 b
4: 8.000000 a
5: 9.285714 b
6: 10.000000 a
7: 22.000000 a
8: 9.285714 b
9: 15.000000 a
df3 <- replace_na(data = df, replace = list(x = x_median, y = y_mode))
df3
> df3 <- replace_na(data = df, replace = list(x = x_median, y = y_mode));df3
x y
1: 1 a
2: 2 a
3: 7 b
4: 8 a
5: 8 b
6: 10 a
7: 22 a
8: 8 b
9: 15 a
上面的缺失值补齐方法只是简单的使用指定值(可以是均值、中位数、众数等),如果还想了解多重插补方法实现缺失值的处理,
********************************************************
可以参考:<缺失值处理方法>
首先了解一下处理缺失值的一般步骤:
1)识别缺失值;
2)检测导致缺失数据的原因;
3)删除包含缺失值的观测或用合理的值代替缺失值。
第一步对缺失值的识别是非常简单的,可以使用is.na()、is.nan()、和is.infinite()函数来鉴别数据集中是否存在缺失;
第二步需要根据实际的场景业务去理解缺失的原因,如敏感数据导致用户不填或网络、机器故障导致数据断层等;
第三步是处理缺失的重要步骤,一般可以通过推理法、行删除法和多重插补法进行处理。
一、识别缺失值
上面提到可以使用is.na()、is.nan()、和is.infinite()来鉴别数据集中是否存在缺失,但该方法返回的是所有向量或数据框中每一个元素是否为缺失值,显然数据量非常大的话该方法返回的结果就不太容易接受。个人觉得可以使用mice包中的md.pattern()函数来发现数据集中缺失值的模式。但该方法只能识别R中的NA和NaN为缺失值,而不能将-Inf和Inf视为缺失值,处理的办法可以用NA替代这些值。
例子
#创建数据集
set.seed(1234)
x1 <- runif(n = 1000, min = 1, max = 15)
x2 <- 100*rnorm(n = 1000) + 10
x3 <- rt(n = 1000, df = 3)
x4 <- rf(n = 1000, df1 = 2, df2 = 3)
y <- 2*x1 - 0.3*x2 + 0.6*x3 - 1.2*x4 + rnorm(1000)
nonemiss.df <- data.table(y = y, x1 = x1, x2 = x2, x3 = x3, x4 = x4)
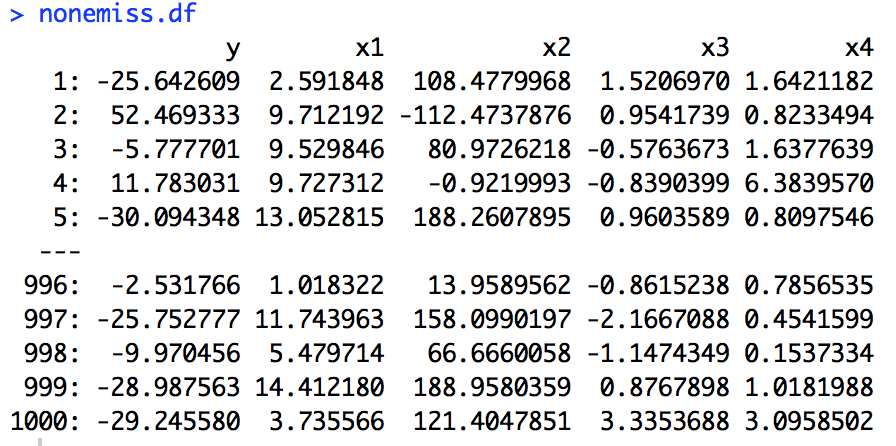
#随机将y,x3和x4列的某些观测设为缺失值
set.seed(1234)
miss.df <- data.frame(y = y, x1 = x1, x2 = x2, x3 = x3, x4 = x4)
miss.df[sample(1:nrow(miss.df), 40),1] <- NA
miss.df[sample(1:nrow(miss.df), 50),2] <- NA
miss.df[sample(1:nrow(miss.df), 60),5] <- NA

#用mice包中的md.pattern()函数探索缺失值的模式
library(mice)
md.pattern(miss.df)

图中返回了数据集中缺失值的情况,0表示列中存在缺失值,1表示列中不存在缺失值。
第一行描述数据集中没有缺失值的模式;
从第二行至倒数第二行反映了某些列中会存在缺失值;
第一列表示缺失值的观测数量(排除第一个值,即858);
最后一列表示缺失值的变量个数;
最后一行给出每个变量缺失值的个数。
通过这张缺失值模式表能够清楚的发现哪些变量存在缺失值,而这些变量又包含了多少数量的缺失。还可以通过可视化的方法来探索数据集中存在缺失值的情况,本人比较喜欢使用VIM包中的aggr()函数。
例子
library(VIM)
aggr(miss.df, prop = FALSE, numbers = TRUE)
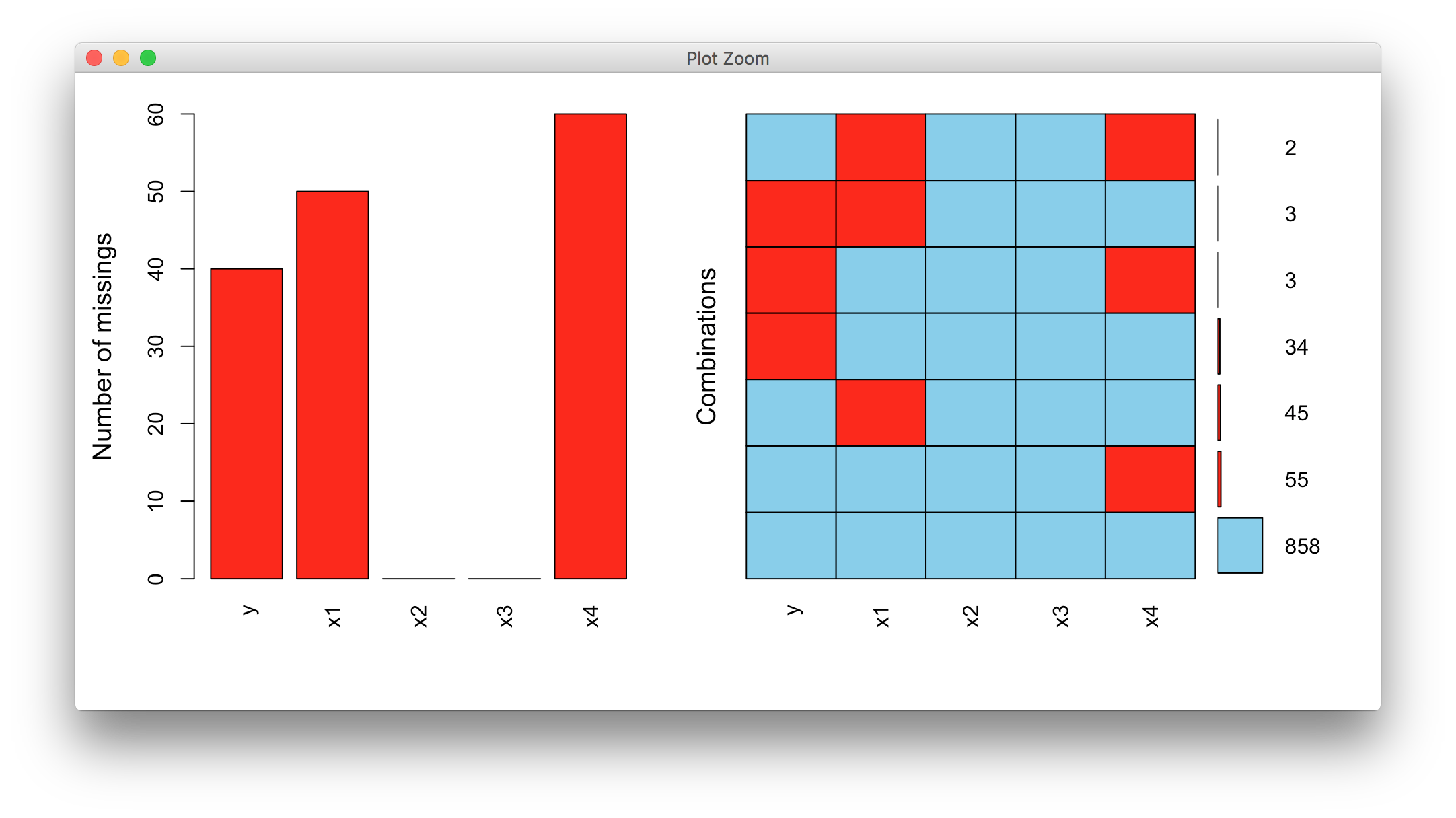
图中能非常直观的反映哪些变量存在缺失值及缺失情况如何。
二、缺失数据处理方法
推理法
该方法根据变量间的数学或逻辑关系进行填补或恢复缺失值,如根据某几个变量间的关系来推断缺失值可能的值;根据姓名来推断缺失的性别或根据购买的产品特征推断用户可能所属的年龄段等。
行删除法
数据集中含有一个或多个缺失值的任意一行都会被删除,一般假定缺失数据是完全随机产生的,且缺失的量仅仅是数据集中的一小部分,可以考虑使用该方法进行缺失值的处理。
多重插补法
该方法是一种基于重复模拟的处理缺失值的方法,它将从一个含缺失值的数据集中生成一组完整的数据集,这些缺失值都是通过蒙特卡洛方法进行替补。替补方法有很多,如贝叶斯线性回归法、自助线性回归法、Logist回归法和线性判别分析法等。
关于多重插补法可以使用mice包中的mice()函数(有关该函数的详细说明可以查看R的帮助文档),该包实现多重插补法并将完整数据集应用到统计模型中的思路如下:
1)mice()函数从一个含缺失值的数据框开始,返回一个包含多个完整数据集对象(默认可以模拟参数5个完整的数据集);
2)with()函数可依次对每个完整数据集应用统计建模;
3)pool()函数将with()生成的单独结果整合到一起。
例子
library(mice)
im <- mice(data = miss.df, m = 10, method = 'pmm')
fit <- with(data = im, expr = lm(y ~ x1 + x2 + x3 + x4))
pooled <- pool(object = fit)
summary(pooled)
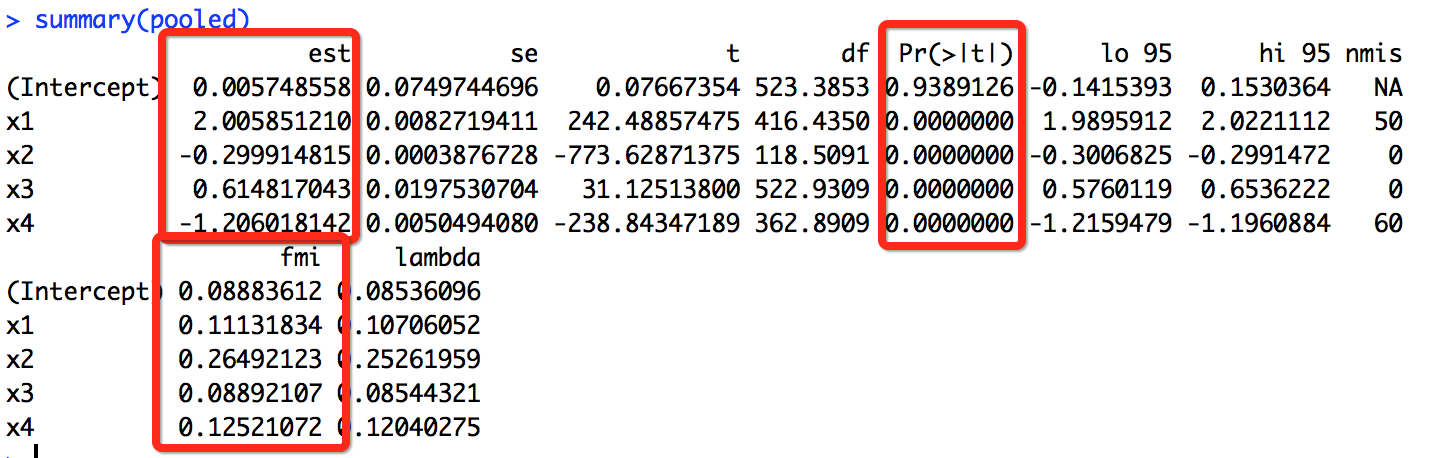
图中给出了线性模型在填补缺失值后的数据集的返回结果。
为了比较,同样将缺失数据集应用到线性模型中:
lm.fit <- lm(y ~ x1 + x2 + x3 + x4, data = miss.df)
summary(lm.fit)

发现缺失数据集和多重插补数据集应用到线性回归后的参数估计基本一致,这主要是因为缺失值是完全随机产生的。如果缺失值不是随机产生的,且缺失比重比较大的话,就不适合使用行删除法,而强烈建议使用多重插补法。
还有一种比较传统的方法是用均值或中位数来替换缺失值,如果缺失数据量比较大的话,该方法可能会低估标准差和曲解变量间的相关性,导致错误的统计检验和P值。
R----tidyr包介绍学习的更多相关文章
- R----dplyr包介绍学习
dplyr包:plyr包的替代者,专门面对数据框,将ddplyr转变为更易用的接口 %>%来自dplyr包的管道函数,其作用是将前一步的结果直接传参给下一步的函数,从而省略了中间的赋值步骤,可以 ...
- R----stringr包介绍学习
1. stringr介绍 stringr包被定义为一致的.简单易用的字符串工具集.所有的函数和参数定义都具有一致性,比如,用相同的方法进行NA处理和0长度的向量处理. 字符串处理虽然不是R语言中最主要 ...
- R----Shiny包介绍学习
为什么用Shiny Shiny让数据分析师写完分析与可视化代码后,稍微再花几十分钟,就可以把分析代码工程化,将分析成果快速转化为交互式网页分享给别人.所以,如果你是一名使用R的数据分析师,选择Shin ...
- R----ggplot2包介绍学习
分析数据要做的第一件事情,就是观察它.对于每个变量,哪些值是最常见的?值域是大是小?是否有异常观测? ggplot2图形之基本语法: ggplot2的核心理念是将绘图与数据分离,数据相关的绘图与数据无 ...
- R----ggplot2包介绍学习--转载
https://www.cnblogs.com/nxld/p/6059603.html 分析数据要做的第一件事情,就是观察它.对于每个变量,哪些值是最常见的?值域是大是小?是否有异常观测? ggplo ...
- R-RMySQL包介绍学习
参考内容: RMySQL数据库编程指南R语言使用RMySQL连接及读写Mysql数据库 RMySql包安装和加载优点问题,试着根据提示简单安装和加载可以使用,后续再查询资料解决. 3.2.1 连接数据 ...
- R----data.table包介绍学习
相比dplyr包,data.table包能够更大程度地提高数据的处理速度,这里就简单介绍一下data.tale包的使用方法. data.table:用于快速处理大数据集的哦 数据的读取 data.ta ...
- R----plotly包介绍学习
plotly包:让ggplot2的静态图片变得可交互 Plotly 是个交互式可视化的第三方库,官网提供了Python,R,Matlab,JavaScript,Excel的接口,因此我们可以很方便地在 ...
- R----lubridata包介绍学习
lubridate包,非常强大,能够识别各种类型的日期.字符型和时间型数据,都是格式比较特别的你数据,在处理时,比较麻烦,但是有了lubridate这个包之后,时间处理变得非常简单,这个包函数命名简单 ...
随机推荐
- JS开发windows phone8.1系列之3
http://msdn.microsoft.com/zh-cn/library/windows/apps/dn629638.aspx 这部分主要是使用页面导航 管理方式,在程序的default.htm ...
- document获取节点byId&byName
<script type="text/javascript"> /* *需要:获取页面中的DIV节点: *思路: *通过docment对象完成.因为div节点有ID属性 ...
- Final-阶段站立会议2
组名:天天向上 组长:王森 组员:张政.张金生.林莉.胡丽娜 代码地址:HTTPS:https://git.coding.net/jx8zjs/llk.git SSH:git@git.coding.n ...
- 一步一步来做WebQQ机器人-(四)(获取好友列表和群列表)
× 本篇主要是: 获取好友列表,群列表 我会尽量详细一点,尽我所知的分享一些可能大家已经掌握的或者还不清楚的经验 利于大家阅读,文章样式不再复杂化,根据内容取固定色 目前总进度大概65% 全系列预计会 ...
- (转)python爬取拉勾网信息
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候 ...
- 关于webapi post 使用多个参数的间接用法
问题描述: Web Api 当使用Post提交的时候 由于只能接受一个参数 ,所以我们基本都会选择把所需要的参数,进行封装实体. 有的时候所需要的信息在其他两个实体中,还需要重新封装也不爽. 今天发现 ...
- java中PriorityQueue优先级队列使用方法
优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素. PriorityQueue是从JDK1.5开始提供的新的数据结构接口. 如果不提供Comparator的话,优先 ...
- openfire及xmpp简单介绍
一.oprenfire 1.openfire是采用Java开发,开源的实时协作(RTC)服务器基于XMPP(Jabber)协议.可以使用它轻易的构建高效率的即时通信服务器. 2.Openfire安装和 ...
- 小试牛刀3之JavaScript基础题
JavaScript基础题 1.让用户输入两个数字,然后输出相加的结果. *prompt() 方法用于显示可提示用户进行输入的对话框. 语法: prompt(text,defaultText) 说明: ...
- SQL2008 SQL2012 远程连接配置方法
第一步: SQL2008(或2012): 打开SQL Server Management Studio-->在左边[对象资源管理器]中选择第一项(主数据库引擎)-->右键-->方面- ...