spark streaming 接收kafka消息之五 -- spark streaming 和 kafka 的对接总结
Spark streaming 和kafka 处理确保消息不丢失的总结
接入kafka
我们前面的1到4 都在说 spark streaming 接入 kafka 消息的事情。讲了两种接入方式,以及spark streaming 如何和kafka协作接收数据,处理数据生成rdd的
主要有如下两种方式
基于分布式receiver
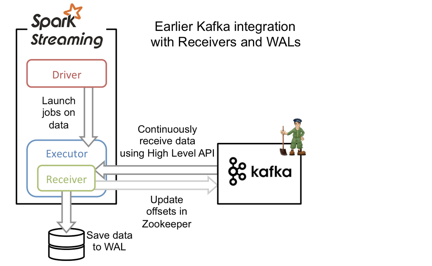
基于receiver的方法采用Kafka的高级消费者API,每个executor进程都不断拉取消息,并同时保存在executor内存与HDFS上的预写日志(write-ahead log/WAL)。当消息写入WAL后,自动更新ZooKeeper中的offset。
它可以保证at least once语义,但无法保证exactly once语义。原因是虽然引入了WAL来确保消息不会丢失,但有可能会出现消息已写入WAL,但更新comsuer 的offset到zk时失败的情况,此时consumer就会按上一次的offset重新发送消息到kafka重新获取一次已保存到WAL的数据。这种方式还会造成数据冗余(WAL中一份,blockmanager中一份,其中blockmanager可能会做StorageLevel.MEMORY_AND_DISK_SER_2,即内存中一份,磁盘上两份),大大降低了吞吐量和内存磁盘的利用率。现在基本都使用下面基于direct stream的方法了。
基于direct stream的方法
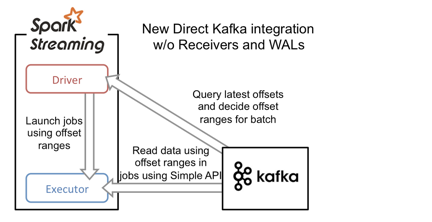
基于direct stream的方法采用Kafka的简单消费者API,大大简化了获取message 的流程。executor不再从Kafka中连续读取消息,也消除了receiver和WAL。还有一个改进就是Kafka分区与RDD分区是一一对应的,允许用户控制topic-partition 的offset,程序变得更加可控。
driver进程只需要每次从Kafka获得批次消息的offset range,然后executor进程根据offset range去读取该批次对应的消息即可。由于offset在Kafka中能唯一确定一条消息,且在外部只能被Streaming程序本身感知到,因此消除了不一致性,保证了exactly once语义。不过,由于它采用了简单消费者API,我们就需要自己来管理offset。否则一旦程序崩溃,整个流只能从earliest或者latest点恢复,这肯定是不稳妥的。
如何保证处理结果不丢失呢?
主要有两种方案:
2.1. 主要是 通过设计幂等性操作,在 at least once 的语义之上,确保数据不丢失
2.2. 在一些shuffle或者是集合计算的结果集中, 在 exactly-once 的基础上,同时更新 处理结果和 offset,这种情况下,一般都是使用事务来做。
现有的支持事务的,也就是传统的数据库了,对于一些缓存系统为了更简单更高效的访问,即使有事务机制,也设计的非常简单,或是只实现了部分功能,例如 redis 的事务是不能支持回滚的。需要我们在代码中做相应的设计,来确保事务的正确执行。
分布式 RDD 计算过程如何确保准确性和一致性?
即分布式RDD计算是如何和确保计算恰好计算一次的呢?后续会出一系列源码分析,分析 spark 是如何做分布式计算的。
spark streaming 接收kafka消息之五 -- spark streaming 和 kafka 的对接总结的更多相关文章
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- 第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3.kafka的架构模型 1.producer:消息的生产者,主要是用于生产消息的.主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通 ...
- 第1节 kafka消息队列:1、kafka基本介绍以及与传统消息队列的对比
1. Kafka介绍 l Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. l Kafka最初是由LinkedIn开发,并于20 ...
- 第1节 kafka消息队列:7、kafka的消费模型
- kafka消息会不会丢失
转载:https://baijiahao.baidu.com/s?id=1583469327946027281&wfr=spider&for=pc 消息发送方式 想清楚Kafka发送的 ...
- Kafka简介及使用PHP处理Kafka消息
Kafka简介及使用PHP处理Kafka消息 Kafka 是一种高吞吐的分布式消息系统,能够替代传统的消息队列用于解耦合数据处理,缓存未处理消息等,同时具有更高的吞吐率,支持分区.多副本.冗余,因此被 ...
- spark streaming 接收kafka消息之四 -- 运行在 worker 上的 receiver
使用分布式receiver来获取数据使用 WAL 来实现 exactly-once 操作: conf.set("spark.streaming.receiver.writeAheadLog. ...
- spark streaming 接收kafka消息之二 -- 运行在driver端的receiver
先从源码来深入理解一下 DirectKafkaInputDStream 的将 kafka 作为输入流时,如何确保 exactly-once 语义. val stream: InputDStream[( ...
- spark streaming 接收kafka消息之一 -- 两种接收方式
源码分析的spark版本是1.6. 首先,先看一下 org.apache.spark.streaming.dstream.InputDStream 的 类说明: This is the abstrac ...
随机推荐
- 浅谈Java中的命名规范
现代软件架构的复杂性需要协同开发完成,如何高效地协同呢? 答案是:制定一整套统一的规范. 无规矩不成方圆,无规范难以协同,比如,制订交通法规表面上是要限制行车权,实际上是保障公众的人身安全,试想如果没 ...
- ABP开发框架前后端开发系列---(8)ABP框架之Winform界面的开发过程
在前面随笔介绍的<ABP开发框架前后端开发系列---(7)系统审计日志和登录日志的管理>里面,介绍了如何改进和完善审计日志和登录日志的应用服务端和Winform客户端,由于篇幅限制,没有进 ...
- 《linux内核设计与实现》阅读笔记-进程与调度
一.进程 process: executing program code(text section) data section containing global variables open f ...
- 分享Sql Server 2008 r2 数据备份,同步服务器数据(二.本地发布,订阅)
上一篇文章中写到了数据库的本地备份,这一篇主要分享一下关于不同服务器的数据备份,主要是使用sql server中的本地发布,本地订阅功能,在数据库的读写分离中,也会经常性的用到这个功能. 复制-> ...
- never下ioc
生命周期 当前分单例,作用域(范围),短暂.单例是整个服务中只有一个实例,短暂则是每一次得到的都是新的实例,作用域就是在该一套行动中内得到的是同一个实例,该行动中指的是什么?我们看看demo下的sta ...
- JCS学习记录 --Java Caching System
Java Caching System--JCS 缓存工具 //jcs版本 jcs-1.3.jar //jcs--cache.ccf缓存配置文件 cache.ccf //所依赖的jar包concurr ...
- Appium+python自动化(十三)- 输入中文 - 一次填坑记(超详解)
简介 无论你在哪里,在做什么都会遇到很多坑,这些坑有些事别人挖的,有些是自己挖的.别人挖的叫坑人,自己挖的叫自杀,儿子挖的叫坑爹.因此在做app自动化道路上也不会是一帆风顺的,你会踩很多坑,这些坑和你 ...
- [apue] 多进程管道读写的一些疑问
对于一对一的pipe: 1) 写进程关闭写管道后,读进程继续读管道会导致read返回0: 2) 读进程关闭读管道后,写进程继续写管道会激发SIGPIPE信号,若捕获,则write返回-1: 而对于多对 ...
- Jsoup配合 htmlunit 爬取异步加载的网页
加入 jsoup 和 htmlunit 的依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId&g ...
- windows container 踩坑记
windows container 踩坑记 Intro 我们有一些服务是 dotnet framework 的,不能直接跑在 docker linux container 下面,最近一直在折腾把它部署 ...