SparkStreaming 笔记
简介
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的准实时数据流处理。
实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。
- 例如:map,reduce,join,window
最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
SparkStreaming 与 Storm, Flink(Native Streaming) 的比较
- | | Storm | Spark Streaming | Flink |
| ------------------------------ | ------------- | ------------------------ | -------------- |
| Streaming Method(实现流的方式) | Native | Micro-Batching | Native |
| Sematic Guarantees(语义保证) | At-Least-Once | Exactly-Once | Exactly-Once |
| Back Pressure(反压机制) | No | Yes | Yes |
| Latency(延迟) | Very Low | Medium | Low |
| ThroughPut(吞吐量) | Low | High | High |
| Fault Tolerance(容错机制) | Record ACKs | RDD Based Check Pointing | Check Pointing |
| Stateful(是否有状态) | No | Yes(DStream) | Yes(Operators) |
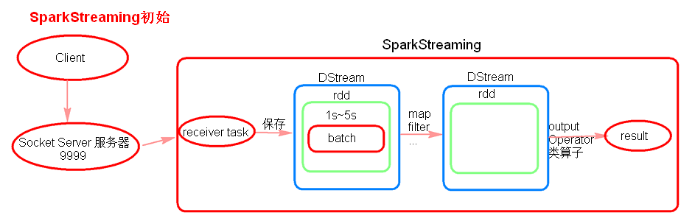
SparkStreaming 初始
- 初始理解
- 注意点:
- receiver task 是 7*24 小时一直在执行, 一直接受数据, 将一段时间内接收到的数据保存到 batch中。假设 batchInterval 为 5s, 那么会将接收来的数据每隔 5 秒封装到一个 batch 中。
- batch 没有分布式计算特性, 这一个batch的数据又被封装到一个 RDD 中最终封装到一个 DStream中。
- 假设 batchInterval 为 5 秒, 每隔 5 秒通过 SparkStreaming 将得到一个 DStream, 在第6秒的时候计算这 5 秒的数据, 假设执行任务的时间是 3 秒, 那么第 6~9 秒, 那么第 6 ~ 9 秒一边在接收数据, 一边在计算任务, 而 9 ~ 10 秒只是在接收数据。第11秒重复以上操作。
- 如果 job 执行的时间 batchInterval 会有什么样的问题?
- 如果接受过来的数据设置的级别是Memory-Only, 接受来的数据会越堆积越多, 最后可能会导致 OOM (如果设置的 StorageLevel 包含 disk, 则内存存放不下的数据会溢写至disk, 增大延迟)。
- 注意点:
SparkStreaming 代码
启动 socket server 服务器: nc -lk 9999
receiver 模式下接受数据, local 的模拟线程必须 >= 2, 一个线程用 receiver 来接受数据, 另一个线程用来执行 job。
Durations 时间设置就是我们能够接受的延迟度。这个需要根据集群的资源情况以及人物的执行情况来调节。
创建 JavaStreamingContext 有两种方式 (SparkConf, SparkContext)
所有的代码逻辑完成后要有一个output operation 类算子。
JavaStreamingContext.start() Streaming 框架启动后不能再次添加业务逻辑。
JavaStreamingContext.stop() 无参的 stop 方法 将 SparkContext 一同关闭, stop(false), 不会关闭 SparkContext。
package com.ronnie.java.streaming; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.Arrays;
import java.util.Iterator; public class WordCountTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("wc").setMaster("local[2]"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaStreamingContext streamingContext = new JavaStreamingContext(jsc, Durations.seconds(5)); JavaReceiverInputDStream<String> dStream = streamingContext.socketTextStream("node01", 9999); JavaDStream<String> wordDStream = dStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
String[] split = line.split(" ");
return Arrays.asList(split).iterator();
}
}); JavaPairDStream<String, Integer> pairDStream = wordDStream.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
}); JavaPairDStream<String, Integer> resultDStream = pairDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
resultDStream.print(); streamingContext.start(); streamingContext.awaitTermination(); streamingContext.stop();
}
}
- 初始理解
SparkStreaming 算子操作
(1). foreachRDD
output operation 算子, 必须对抽取出来的 RDD 执行 action 类算子, 代码才能执行。
package com.ronnie.java.output_operator; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.Arrays;
import java.util.Iterator; /**
* foreachRDD 算子注意:
* 1.foreachRDD是DStream中output operator类算子
* 2.foreachRDD可以遍历得到DStream中的RDD,可以在这个算子内对RDD使用RDD的Transformation类算子进行转化,但是一定要使用rdd的Action类算子触发执行。
* 3.foreachRDD可以得到DStream中的RDD,在这个算子内,RDD算子外执行的代码是在Driver端执行的,RDD算子内的代码是在Executor中执行。
*
*/ public class Operator_foreachRDD {
public static void main(String[] args) {
final SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline"); JavaSparkContext sc = new JavaSparkContext(conf); /**
* 在创建streamingContext的时候 设置batch Interval
*/ JavaStreamingContext jsc = new JavaStreamingContext(sc, Durations.seconds(5)); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node01", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
}); JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
//outputoperator类的算子 counts.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> pairRDD) throws Exception {
/**
* 这里的代码在 driver 端运行
*/
System.out.println("=======================driver==============="); pairRDD.filter(new Function<Tuple2<String, Integer>, Boolean>() {
@Override
public Boolean call(Tuple2<String, Integer> v1) throws Exception {
System.out.println(v1 + " ====== ");
return v1._2 >= 2;
}
// 必须要接action 算子
}).foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple2) throws Exception {
System.out.println(tuple2);
}
}); }
});
// counts.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
// @Override
// public void call(JavaPairRDD<String, Integer> pairRDD) throws Exception {
// //rdd之外的这些代码,是在driver运行的。每启动一个job都会执行这里的代码...
// System.out.println("**********************************************");
//
// //RDD的处理,必须最后有触发算子,才能启动整个任务的计算....
// JavaPairRDD<String, Integer> filter = pairRDD.filter(new Function<Tuple2<String, Integer>, Boolean>() {
// @Override
// public Boolean call(Tuple2<String, Integer> v1) throws Exception {
// System.out.println("==============================");
// return true;
// }
// });
//
// filter.foreach(new VoidFunction<Tuple2<String, Integer>>() {
// @Override
// public void call(Tuple2<String, Integer> tuple2) throws Exception {
// System.out.println(tuple2);
// }
// });
// }
// }); jsc.start(); // 等待 spark程序被终止
jsc.awaitTermination(); jsc.stop(); System.out.println("stop==================");
}
}
(2). transform
transformation 类算子
可以通过 transform 算子, 对 Dstream 做 RDD 到 RDD 的任意操作。
package com.ronnie.java.transformer; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.ArrayList;
import java.util.List; public class Operator_Transform {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local[2]").setAppName("transform");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); //模拟黑名单
List<String> blackList = new ArrayList<String>();
blackList.add("zeus");
blackList.add("lina"); //广播黑名单
final Broadcast<List<String>> broadcastList = jsc.sparkContext().broadcast(blackList); //接受socket数据源
JavaReceiverInputDStream<String> nameList = jsc.socketTextStream("node01", 9999); //原始数据 "1 zs" "2 la" ,返回元组:(ls,"2 la")
JavaPairDStream<String, String> pairNameList = nameList.mapToPair(new PairFunction<String, String, String>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, String> call(String line) throws Exception {
//原始数据 "1 zs" 、"2 la" ,返回元组:(la,"2 la") return new Tuple2<String, String>(line.split(" ")[1], line);
}
}); JavaDStream<String> transFormResult = pairNameList.transform(new Function<JavaPairRDD<String,String>, JavaRDD<String>>() { private static final long serialVersionUID = 1L; @Override
public JavaRDD<String> call(JavaPairRDD<String, String> nameRDD)throws Exception { System.out.println("============================================");
//(la,"2 la")
JavaPairRDD<String, String> filter =
nameRDD.filter(new Function<Tuple2<String,String>, Boolean>() { private static final long serialVersionUID = 1L; @Override
public Boolean call(Tuple2<String, String> v1)
throws Exception {
// v1 : (zs,"1 zs")
//得到广播变量
List<String> blackList = broadcastList.value();
//如果广播变量 黑名单里包含了本条数据的名称,则本条数据被过滤掉
return blackList.contains(v1._1);
}
});
//返回一个 javaRDD
return filter.map(new Function<Tuple2<String,String>, String>() { private static final long serialVersionUID = 1L; @Override
public String call(Tuple2<String, String> v1)
throws Exception {
// v1 (zs,"1 zs")
return v1._2;
}
});
}
}); transFormResult.print(); jsc.start(); jsc.awaitTermination(); jsc.stop();
}
}
(3). updateStateByKey
- transformation 类算子
- updateStateByKey 作用:
- 使用到 updateStateByKey 要开启 checkpoint 机制 和 功能。
- 多久会将内存中的数据写入到磁盘一份?
- 如果 batchInterval 设置的 时间 小于 10 秒, 那么 10 秒写入磁盘一份。
- 如果 batchInterval 设置的时间大于 10 秒, 那么就会 根据 batchInterval 时间间隔写入磁盘一份
package com.ronnie.java.transformer; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional; import org.apache.spark.api.java.function.Function2; import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.Arrays;
import java.util.List; /**
* UpdateStateByKey的主要功能:
* 1、为Spark Streaming中每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。
* 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新
* <p>
* hello,3
* bjsxt,2
* <p>
* 如果要不断的更新每个key的state,就一定涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能
* <p>
* 全面的广告点击分析
*
* @author root
* <p>
* 有何用? 统计广告点击流量,统计这一天的车流量,统计点击量
*/ public class Operator_UpdateStateByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("UpdateStateByKeyDemo"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); /**
* 设置checkpoint目录
*
* 多久会将内存中的数据(每一个key所对应的状态)写入到磁盘上一份呢?
* 如果你的batch interval小于10s 那么每格10s会将内存中的数据写入到磁盘上
* 如果batch interval 大于10s,那么就以batch interval为准
*
* 这样做是为了防止频繁的写入写出 HDFS
*/ // jsc.checkpoint("hdfs://ronnie/spark/checkpoint");
jsc.checkpoint("./checkpoint/updateState"); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node01", 9999); JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator()); JavaPairDStream<String, Integer> ones = words.mapToPair(x->new Tuple2<>(x,1)); JavaPairDStream<String, Integer> resultDstream = ones.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() {
@Override
public Optional<Integer> call(List<Integer> v1, Optional<Integer> v) throws Exception {
/**
* v1:经过分组最后 这个key所对应的value [1,1,1,1,1]
* v:这个key在本次之前之前的状态
*/
int value = 0; for(Integer tmp : v1){
value += tmp;
} if(v.isPresent()){
value += v.get();
} return Optional.of(value);
}
}); resultDstream.print(); // JavaPairDStream<String, Integer> counts =
// ones.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() {
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception {
// /**
// * values:经过分组最后 这个key所对应的value [1,1,1,1,1]
// * state:这个key在本次之前之前的状态
// */
//
// Integer updateValue = 0;
// if (state.isPresent()) {
// updateValue = state.get();
// }
//
// System.out.println(updateValue + " ======== ");
//
// for (Integer value : values) {
// updateValue += value;
// }
// return Optional.of(updateValue);
// }
// }); //output operator
// counts.print(); jsc.start(); jsc.awaitTermination(); jsc.close();
} }(4). Window Operation (窗口操作)
package com.ronnie.java.transformer; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.Arrays;
import java.util.Iterator; public class Operator_Window { public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 设置日志级别为WARN
*
*/
jssc.sparkContext().setLogLevel("WARN");
/**
* 注意:
* 没有优化的窗口函数可以不设置checkpoint目录
* 优化的窗口函数必须设置checkpoint目录
*/
// jssc.checkpoint("hdfs://node1:9000/spark/checkpoint");
jssc.checkpoint("./checkpoint"); JavaReceiverInputDStream<String> searchLogsDStream = jssc.socketTextStream("node01", 9999); JavaDStream<String> searchWordDStream = searchLogsDStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterator<String> call(String t) throws Exception {
System.out.println(t + "*************");
return Arrays.asList(t.split(" ")).iterator();
}
});
// 将搜索词映射为(searchWord, 1)的tuple格式
JavaPairDStream<String, Integer> searchWordPairDStream = searchWordDStream.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String searchWord) throws Exception {
return new Tuple2<String, Integer>(searchWord, 1);
}
});
/**
* 每隔10秒,计算最近60秒内的数据,那么这个窗口大小就是60秒,里面有12个rdd,在没有计算之前,这些rdd是不会进行计算的。
* 那么在计算的时候会将这12个rdd聚合起来,然后一起执行reduceByKeyAndWindow操作 ,
* reduceByKeyAndWindow是针对窗口操作的而不是针对DStream操作的。
*/
// JavaPairDStream<String, Integer> resultDStream = searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
// @Override
// public Integer call(Integer v1, Integer v2) throws Exception {
// System.out.println( "v1 : " + v1 + " v2: " + v2);
// return v1 + v2;
// }
// }, Durations.seconds(15), Durations.seconds(5));
//
// resultDStream.print(); // JavaPairDStream<String, Integer> searchWordCountsDStream =
// searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
// @Override
// public Integer call(Integer v1, Integer v2) throws Exception {
//
// System.out.println(v1 + " : " + v2);
// return v1 + v2;
// }
// },Durations.seconds(15),Durations.seconds(5)); /**
* window窗口操作优化:
*/
JavaPairDStream<String, Integer> searchWordCountDStream = searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("v1:" + v1 + " v2:" + v2 + " ++++++++++");
return v1 + v2;
}
}, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("v1:" + v1 + " v2:" + v2 + "------------");
return v1 - v2;
}
}, Durations.seconds(15), Durations.seconds(5)); searchWordCountDStream.print(); jssc.start(); jssc.awaitTermination(); jssc.close();
}
}
Driver HA(Standalone 或 Mesos)
因为 SparkStreaming 当 7*24 小时运行, Driver 只是一个简单的进程, 有可能挂掉, 所以实现 Driver 的 HA 就有必要(如果使用的 Client 模式无法 实现 Driver HA, 这里针对的是cluster模式)。
Yarn 平台 cluster 模式提交任务, AM(ApplicationMaster) 相当于 Driver, 如果挂掉会自动启动 AM。
这里所说的 DriverHA 仅针对 Spark Standalone 和 Mesos 资源调度的情况下。
实现 Driver 的高可用有两个步骤:
- 提交任务层面
- 在提交任务的时候加上选项 --supervise, 当 Driver 挂掉的时候会重启 Driver。
- 代码层面
- 使用 JavaStreamingContext.getOrCreate (checkpoint 路径, JavaStreamingContextF、actory)
- 提交任务层面
Driver 中元数据包括:
创建应用程序的配置信息。
DStream 的操作逻辑。
job 中没有完成的批次数据, 也就是 job 的执行进度。
SparkStreaming 2.2(包含以前) + kafka
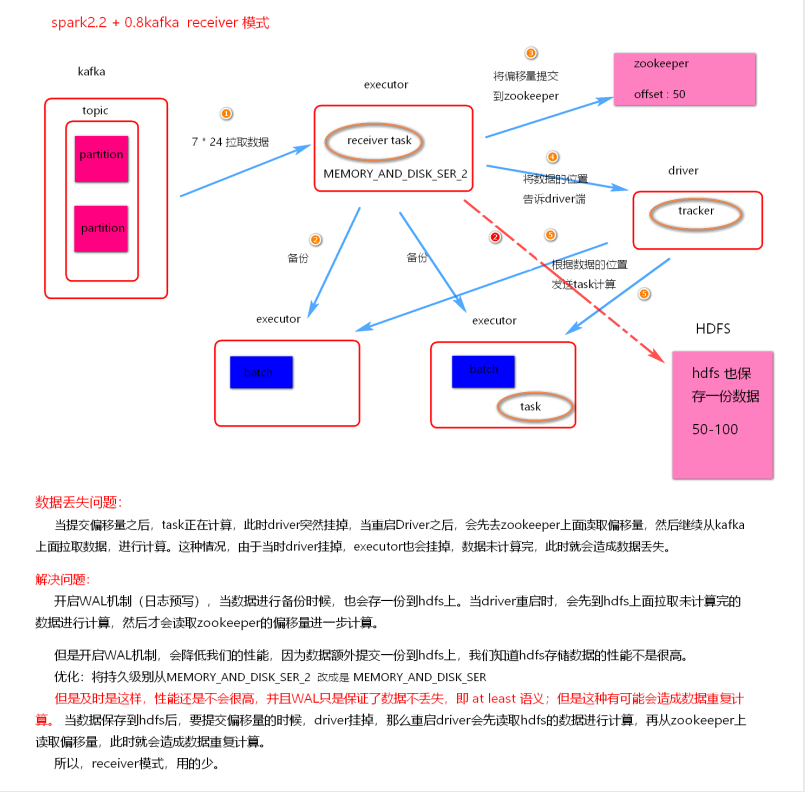
(1). receiver 模式
- 理解图
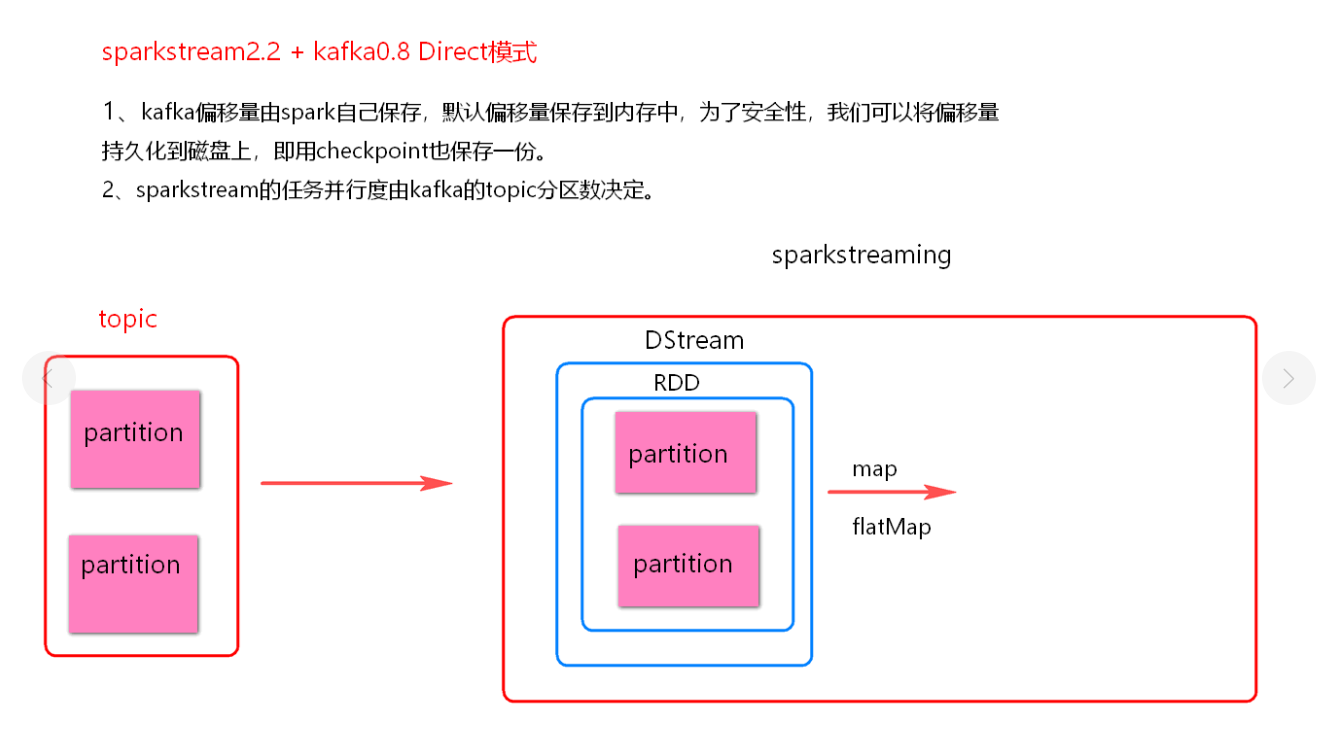
(2). Direct 模式
- 理解图
代码:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.*;
import scala.Tuple2; import java.util.*; /**
*
自己维护偏移量
*/ public class SparkStreamingOnKafkaDirected2 { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingOnKafkaDirected"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
kafkaParams.put("auto.offset.reset", "earliest");
kafkaParams.put("group.id", "sk-2");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
//偏移量保存到外部存储系统,此时就无需存到kafka.
kafkaParams.put("enable.auto.commit", false); //topic中每个分区对应的起始偏移量,放入map
Map<TopicPartition, Long> fromOffsets = new HashMap<>(); TopicPartition topicAndPartition = new TopicPartition("sm3",0);
// 这里我直接代码写死分区起始偏移量,正常情况下,要去外部存储系统去读取
fromOffsets.put(topicAndPartition,17285L); JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream(
jsc,
LocationStrategies.PreferConsistent(),
//指明读取每个分区的其实偏移量
ConsumerStrategies.<String, String>Assign(fromOffsets.keySet(), kafkaParams, fromOffsets)
); stream.map(new Function<ConsumerRecord<String,String>, String>() {
@Override
public String call(ConsumerRecord<String, String> consumerRecord) throws Exception {
return consumerRecord.value();
}
}).foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> rdd) throws Exception {
rdd.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}
}); /**
* 必须在源头拿到偏移量,因为在其他的Dstream中rdd的偏移量已经被丢弃掉了
*/
stream.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() { public void call(JavaRDD<ConsumerRecord<String, String>> rdd) throws Exception {
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges(); //可以将offset保存到redis,hbase,mysql等外部存储系统
for (OffsetRange o : offsetRanges) {
System.out.println(
"将偏移量插入到hbase.redis...." + o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset()
); }
//将偏移量插入到hbase.redis....
}
}); jsc.start(); try {
jsc.awaitTermination();
} catch (InterruptedException e) { e.printStackTrace();
} jsc.close();
} }
import io.netty.handler.codec.string.StringDecoder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.consumer.OffsetCommitCallback;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.*; import org.apache.spark.streaming.kafka010.*;
import scala.Tuple2; import java.util.*; /** kafka0.11 :用kafka来存储偏移量位置,关掉自动提交偏移量,改成异步手动提交。
缺点:
第一: 这种方式,若消费者组在一定时间内没到kafka中读数据,kafka会对清除掉对应组的偏移量
* 第二: 无法保证有且只有一次语义,因为偏移量的提交是异步的,所有若结果的输出依然要自己实现幂等性。 kafka在这里就是充当偏移量存储系统而已,跟kafka0.8.2.1版本的high level API 由zookeeper来保存偏移量差不多。
*/ public class SparkStreamingOnKafkaDirected { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingOnKafkaDirected"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
kafkaParams.put("auto.offset.reset", "earliest");
kafkaParams.put("group.id", "sk-2");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
//将自动提交,改成手动提交,否则数据会造成重复消费或数据丢失问题。
kafkaParams.put("enable.auto.commit", false); Collection<String> topics = Arrays.asList("sm3"); JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jsc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
); JavaDStream<String> words = stream.flatMap(new FlatMapFunction<ConsumerRecord<String, String>, String>() {
@Override
public Iterator<String> call(ConsumerRecord<String, String> consumerRecord) throws Exception { return Arrays.asList(consumerRecord.value().split("\t")).iterator();
}
}); words.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> rdd) throws Exception {
rdd.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception { System.out.println(s);
}
});
}
}); /**
* 必须在Dstream源头拿到偏移量,因为在其他的Dstream中rdd的偏移量位置已经被丢弃掉了
*/
stream.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() {
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> rdd) throws Exception {
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges(); /**
* 将偏移量异步提交到kafka中,有kafka来保存偏移量。
* 缺点:
* 第一: 这种方式,若消费者组在一定时间内没到kafka中读数据,kafka会对清除掉对应组的偏移量
* 第二: 无法保证有且只有一次语义,因为偏移量的提交是异步的,所有若结果的输出依然要自己实现幂等性。
*
*/
((CanCommitOffsets) stream.inputDStream()).commitAsync(offsetRanges); for (OffsetRange o : offsetRanges) {
System.out.println(
o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset()
); } }
}); jsc.start(); try {
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
} jsc.close();
} }
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function0;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies; import java.util.*; /**
* 开启checkpoint机制,来保存偏移量
* 第一:当代码逻辑改变时,无法从checkpoint中来恢复offset.
第二:当从checkpoint中恢复数据时,有可能造成重复的消费,需要我们写代码来保证数据的输出幂等 * @author root
*/ public class SparkStreamingOnKafkaDirectedCheckPoint { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingOnKafkaDirected"); String checkpointDirectory = ".checkpoint";
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, new Function0<JavaStreamingContext>() {
@Override
public JavaStreamingContext call() throws Exception {
return createContext(checkpointDirectory,conf);
}
}); jsc.start(); try {
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
} jsc.close(); } private static JavaStreamingContext createContext(String checkpointDirectory, SparkConf conf) { System.out.println("create...new context");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(10));
jsc.checkpoint(checkpointDirectory); Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
kafkaParams.put("auto.offset.reset", "earliest");
kafkaParams.put("group.id", "sk-1");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
//将自动提交,改成手动提交,否则数据会造成重复消费或数据丢失问题。
kafkaParams.put("enable.auto.commit", true); Collection<String> topics = Arrays.asList("sm3"); JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jsc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
); JavaDStream<String> words = stream.flatMap(new FlatMapFunction<ConsumerRecord<String, String>, String>() {
@Override
public Iterator<String> call(ConsumerRecord<String, String> consumerRecord) throws Exception { return Arrays.asList(consumerRecord.value().split("\t")).iterator();
}
}); words.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> rdd) throws Exception {
rdd.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
Thread.sleep(1000);
System.out.println(s );
}
});
}
}); return jsc;
} }
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.Random; /**
* 向kafka中生产数据
*
* @author root
*/
public class SparkStreamingProducerForKafka extends Thread { static String[] channelNames = new String[]{
"Spark", "Scala", "Kafka", "Flink", "Hadoop", "Storm",
"Hive", "Impala", "HBase", "ML"
}; static String[] actionNames = new String[]{"View", "Register"}; private String topic; //发送给Kafka的数据,topic
private KafkaProducer<Integer, String> producerForKafka; private static String dateToday;
private static Random random; public SparkStreamingProducerForKafka(String topic) {
dateToday = new SimpleDateFormat("yyyy-MM-dd").format(new Date());
this.topic = topic;
random = new Random();
Properties conf = new Properties();
conf.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
conf.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
conf.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerForKafka = new KafkaProducer<>(conf);
} @Override
public void run() {
int counter = 0;
while (true) {
counter++;
// String userLog = userlogs();
String message = "shsxt" + counter; producerForKafka.send(new ProducerRecord<>(topic, message)); System.out.println(message );
// 每2条数据暂停1秒
if (0 == counter % 5) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
} public static void main(String[] args) { new SparkStreamingProducerForKafka("sm3").start();
// new SparkStreamingProducerForKafka("sk2").start(); } //生成随机数据
private static String userlogs() { StringBuffer userLogBuffer = new StringBuffer("");
int[] unregisteredUsers = new int[]{1, 2, 3, 4, 5, 6, 7, 8};
long timestamp = new Date().getTime();
Long userID = 0L;
long pageID = 0L; //随机生成的用户ID
if (unregisteredUsers[random.nextInt(8)] == 1) {
userID = null;
} else {
userID = (long) random.nextInt(2000);
} //随机生成的页面ID
pageID = random.nextInt(2000); //随机生成Channel
String channel = channelNames[random.nextInt(10)]; //随机生成action行为
String action = actionNames[random.nextInt(2)]; userLogBuffer.append(dateToday)
.append("\t")
.append(timestamp)
.append("\t")
.append(userID)
.append("\t")
.append(pageID)
.append("\t")
.append(channel)
.append("\t")
.append(action); System.out.println(userLogBuffer.toString()); return userLogBuffer.toString();
} }
(3). 相关配置
预写日志:
spark.streaming.receiver.writeAheadLog.enable # 默认false没有开启
blockInterval: receiver 模式
spark.streaming.blockInterval # 默认200ms
反压机制:
spark.streaming.blockInterval # 默认false
接受数据速率
Receiver 模式:
spark.streaming.receiver.maxRate # 默认没有设置
Direct 模式:
spark.streaming.kafka.maxRatePerPartition
优雅的停止 sparkstream:
spark.streaming.stopGracefullyOnShutdown 设置为true
kill -15/sigterm driverpid
(4). 总结 SparkStreaming 2.2(包含以前) + kafka 0.8.2
Receiver 模式
- receiver 模式采用了 Receiver 接收器模式, 需要一个线程一直接收数据, 将数据接收到 Executor中, 默认存储级别是 MEMORY_AND_DISK_SER_2
- receiver 模式自动使用 Zookeeper 管理消费者 offset
- receiver 模式底层读取 kafka 采用 High Level Consumer API 实现, 这种模式不关心 offset, 只要数据。
- receiver 模式当 Driver 挂掉时, 有丢失数据问题, 可以开启 WAL 机制, 避免丢失数据, 但是开启之后加大了数据处理延迟, 并且存在数据重复消费风险。
- receiver 模式并行度 由 spark.streaming.blockInterval = 200ms, 可以减少这个参数增大并行度, 最小不能低于 50ms
- Receiver 模式不被使用
- 被动将数据接收到 Executor, 当有任务堆积时, 数据存储问题
- 这种模式 不能手动维护消费者offset
Direct 模式
direct 模式没有使用 receiver 接收器模式, 每批次处理数据直接获取当前批次数据处理
direct 模式没有使用 Zookeeper 管理消费者 offset, 使用的是 Spark 自己管理, 默认存在内存中, 可以设置 checkpoint, 也会保存到 checkpoint 中一份。
direct 模式底层读取 kafka 使用 Simple Consumer API, 可以手动维护消费者 offsset
direct 模式并行度 与 读取的 topic 的 partition 一一对应
可以使用设置 checkpoint 的方式管理消费者 offset, 使用StreamingContext.getOrCreate(ckDir, CreateStreamingContext) 恢复。
- 该方式的两种缺点:
- 当代码逻辑改变时, 无法从 checkpoint 来恢复 offset。
- 当从 checkpoint 中恢复数据时, 有可能造成重复的消费, 需要我们写代码来保证数据的输出幂等。
- 该方式的两种缺点:
如果代码逻辑改变, 就不能使用 checkpoint 模式管理 offset, 可以手动维护消费者 offset, 可以将 offset 存储到外部系统。
kafka 0.11 版本改变
kafka 0.8.2 版本消费者 offset 存储在zookeeper中, 对于 zookeeper 而言 每次操作代价 是 很昂贵的, 而且 zookeeper 集群是不能扩展写能力的。
kafka 0.11 版本默认使用心得消费者 api, 消费者 offset 会更新到一个 kafka 自带的 topic[_consumer_offsets] 中。
以消费者组 groupid 为单位, 可以查询每个组的消费 topic 情况:
#查看所有消费者组
./kafka-consumer-groups.sh --bootstrap-server node1:9092, node2:9092, node3:9092 --list #查看消费者消费的offset位置信息
./kafka-consumer-groups.sh --bootstrap-server node1:9092, node2:9092, node3:9092 --describe --group MyGroupId #重置消费者组的消费offset信息 ,--reset-offsets –all-topics 所有offset。--to-earliest 最小位置。
# --execute 执行
./kafka-consumer-groups.sh --bootstrap-server c7node1:9092,c7node2:9092,c7node3:9092 --group MyGroupId --reset-offsets --all-topics --to-earliest --execute
SparkStreaming 2.3 + kafka 0.11
(1). 丢弃了SparkStreaming + kafka 的 receiver 模式。
(2). 采用了新的消费者 api 实现, 类似于 2.2 中 SparkStreaming 读取 kafka Direct 模式。(并行度一样)
(3).因为采用了新的消费者 api 实现, 所有相对于 1.6 的 Direct 模式[simple api 实现], api 使用上有很大差别。未来这种 api 有可能继续变化。
(4). 大多数情况下, SparkStreaming 读取数据使用 LocationStrategies.PreferConsistent 策略, 该策略会将分区均匀的分布在集群的 Executor 之间。
- 如果 Executor 在 kafka 集群中的某些节点上, 可以使用 LocationStrategies.PreferBrokers 这种策略, 那么当前这个 Executor 中的数据会来自当前 broker 节点。
- 如果节点之间的分区有明显的分布不均, 可以使用 LocationStrategies.PreferFixed 这种策略, 可以通过一个 map 指定将 topic 分区分布在哪些节点。
(5). 新的消费者 api 可以将 kafka 中的消息预读取到缓存区中, 默认大小为64k。默认缓存区在 Executor中。
- 加快处理数据速度方式:
- 增大消费端最大缓存容量, 参数: spark.streaming.kafka.consumer.cache.maxCapacity
- 关闭缓存机制, 参数: spark.streaming.kafka.consumer.cache.enabled = false
(6). 消费者 offset 相关
如果设置了 checkpoint, 那么 offset 将会存储在 checkpoint 中。
- 缺点:
- 当代码逻辑改变时, 无法从 checkpoint 中来恢复 offset
- 当从 checkpoint 中恢复数据时, 有可能造成重复的消费, 需要我们写代码来保证数据的输出幂等
- 缺点:
依靠 kafka 来存储消费者 offset, kafka中有一个特殊的 topic 来存储消费者 offset。
新的消费者 api 中, 会定期自动提交 offset, 自动提交 offset 的频率由参数 auto.commit.interval.ms 决定, 默认 5s 。
为了保证消费数据的精确性, 我们可以自动提交, 改成异步的手动提交消费者 offset。
缺点:
- offset 存储在 kafka 中由参数 offsets.retention.minutes=1440 控制是否过期删除, 默认是保存一天, 如果停机时消费没有达到时长, 存储在 kafka 中的消费者组会被清空, offset 也就被清除了。
- 无法保证有且只有一次语义, 因为偏移量的提交是异步的, 所有结果的输出依然要自己实现幂等性。
自己存储 offset, 这样在处理逻辑时, 保证数据处理的事务
- 如果处理数据失败, 就不保存 offset
- 处理数据成功则保存 offset, 这样可以做到精准的处理一次数据
SparkStreaming 笔记的更多相关文章
- 【大数据】SparkStreaming学习笔记
第1章 Spark Streaming概述 1.1 Spark Streaming是什么 Spark Streaming用于流式数据的处理.Spark Streaming支持的数据输入源很多,例如:K ...
- kafka+spark-streaming实时推荐系统性能优化笔记
1) --conf spark.dynamicAllocation.enabled=false 如果正在使用的是CDH的Spark,修改这个配置为false:开源的Spark版本则默认是false. ...
- spark复习笔记(7):sparkstreaming
一.介绍 1.sparkStreaming是核心模块Spark API的扩展,具有可伸缩,高吞吐量以及容错的实时数据流处理等.数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字 ...
- sparkStreaming复习笔记(1)
一.SparkStreaming 1.sparkcore模块的扩展,具有可扩展,高吞吐量,容错机制,针对实时数据流处理,数据可以来自于kafka,flume以及tcp套接字,可以使用更加复杂的函数来进 ...
- 大数据笔记(三十二)——SparkStreaming集成Kafka与Flume
三.集成:数据源 1.Apache Kafka:一种高吞吐量的分布式发布订阅消息系统 (1) (*)消息的类型 Topic:主题(相当于:广播) Queue:队列(相当于:点对点) (*)常见的消息系 ...
- 大数据笔记(三十一)——SparkStreaming详细介绍,开发spark程序
Spark Streaming: Spark用于处理流式数据的模块,类似Storm 核心:DStream(离散流),就是一个RDD=================================== ...
- 通过案例对SparkStreaming透彻理解三板斧之三
本课将从二方面阐述: 一.解密SparkStreaming Job架构和运行机制 二.解密SparkStreaming容错架构和运行机制 一切不能进行实时流处理的数据都将是无效的数据.在流处理时代,S ...
- 通过案例对SparkStreaming透彻理解三板斧之二
本节课主要从以下二个方面来解密SparkStreaming: 一.解密SparkStreaming运行机制 二.解密SparkStreaming架构 SparkStreaming运行时更像SparkC ...
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
随机推荐
- routes 学习
对于routes的学习,感觉还是看官方文档理解的比较快,主要说明connect和resource Setting up routes¶ It is assumed that you are using ...
- 初学微信小程序——配置问题(2)
六.生命周期函数: 在微信公众平台指南中搜索生命周期,找到页面生命周期 比如,我打开cate.js并编写,代码如下: ** * 生命周期函数--监听页面加载 */ onLoad: function ...
- SpringCloud学习之Zuul路由转发、拦截和熔断处理(七)
Spring Cloud Zuul 服务网关是微服务架构中一个不可或缺的部分.通过服务网关统一向外系统提供REST API的过程中,除了具备服务路由.均衡负载功能之外,它还具备了权限控制等功能. Sp ...
- 《C++ Primer(中文版)(第5版)》斯坦利·李普曼 (Stanley B. Lippman) (作者), 约瑟·拉乔伊 (Josee Lajoie) (作者), 芭芭拉·默 (Barbara E. Moo) (作者) azw3
内容简介: 这本久负盛名的C++经典教程,时隔八年之久,终迎来的重大升级.除令全球无数程序员从中受益,甚至为之迷醉的——C++ 大师 Stanley B. Lippman 的丰富实践经验,C++标准委 ...
- Redis字符串类型
字符串是Redis中最基本的数据类型,他能存储任何形式的字符串,包括二进制数据. 命令 赋值 SET key value > SET key hello OK 取值 GET key > G ...
- pyhon 内置函数
chr() asci码 dir() 目录,显示目录. divmod(10,3) 返回商和余数 例如 (3, 1) 返回的为一个元组 可以用于分页 enumerate() ...
- 图片转换到指定大小PDF
1.首先转换为eps jpeg2ps compile to exec file ./jpeg2ps -p a4 a.jpg -o x.eps2.从eps转换到pdf ps2pdf -dDownsa ...
- django+centos+mariadb读写分离完美实现(上)-mysql主从备份实现
首先画图一张,用来展示今天要做的事情,读写分离,个人理解就是使用mysql主从备份的原理,让两个数据库同时为自己提供服务.其中主库负责数据保存,从库负责数据展示,可以一主一从,也可以一主多从.从而降低 ...
- Codeforces 590 A:Median Smoothing
A. Median Smoothing time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- 2-10 就业课(2.0)-oozie:2、介绍和安装1
oozie的安装及使用 1. oozie的介绍 Oozie是运行在hadoop平台上的一种工作流调度引擎,它可以用来调度与管理hadoop任务,如,MapReduce.Pig等.那么,对于Oozie ...