Machine Learning笔记整理 ------ (二)训练集与测试集的划分
在实际应用中,一般会选择将数据集划分为训练集(training set)、验证集(validation set)和测试集(testing set)。其中,训练集用于训练模型,验证集用于调参、算法选择等,而测试集则在最后用于模型的整体性能评估。
1. 留出法 (Hold-out)
将数据集D划分为2个互斥子集,其中一个作为训练集S,另一个作为测试集T,即有:
D = S ∪ T, S ∩ T = ∅
用训练集S训练模型,再用测试集T评估误差,作为泛化误差估计。
特点:单次使用留出法得到的估计结果往往不够稳定可靠,故如果要使用留出法,一般采用若干次随机划分,重复进行实验评估后,取平均值作为最终评估结果。
比例:S = 2/3 ~ 4/5 D,T = 1/3 ~ 1/5 D
2. 交叉验证法 (Cross validation)
将数据集D划分为k个大小相似的互斥子集,即:
D = D1 ∪ D2 ∪ D3 ∪ ...... ∪ Dk
有:Di ∩ Dj=∅,每个子集Dr都尽可能保持数据分布的一致性,即:从D中通过分层采样得到,每次使用k-1个子集的并集作为训练集S,余下的一个作为测试集T,最终返回的是k个测试结果的均值。因其稳定性与保真性取决于k值,故又称为k折交叉验证 (K-fold cross validation),其中k最常用取值为10,又称10折交叉验证。
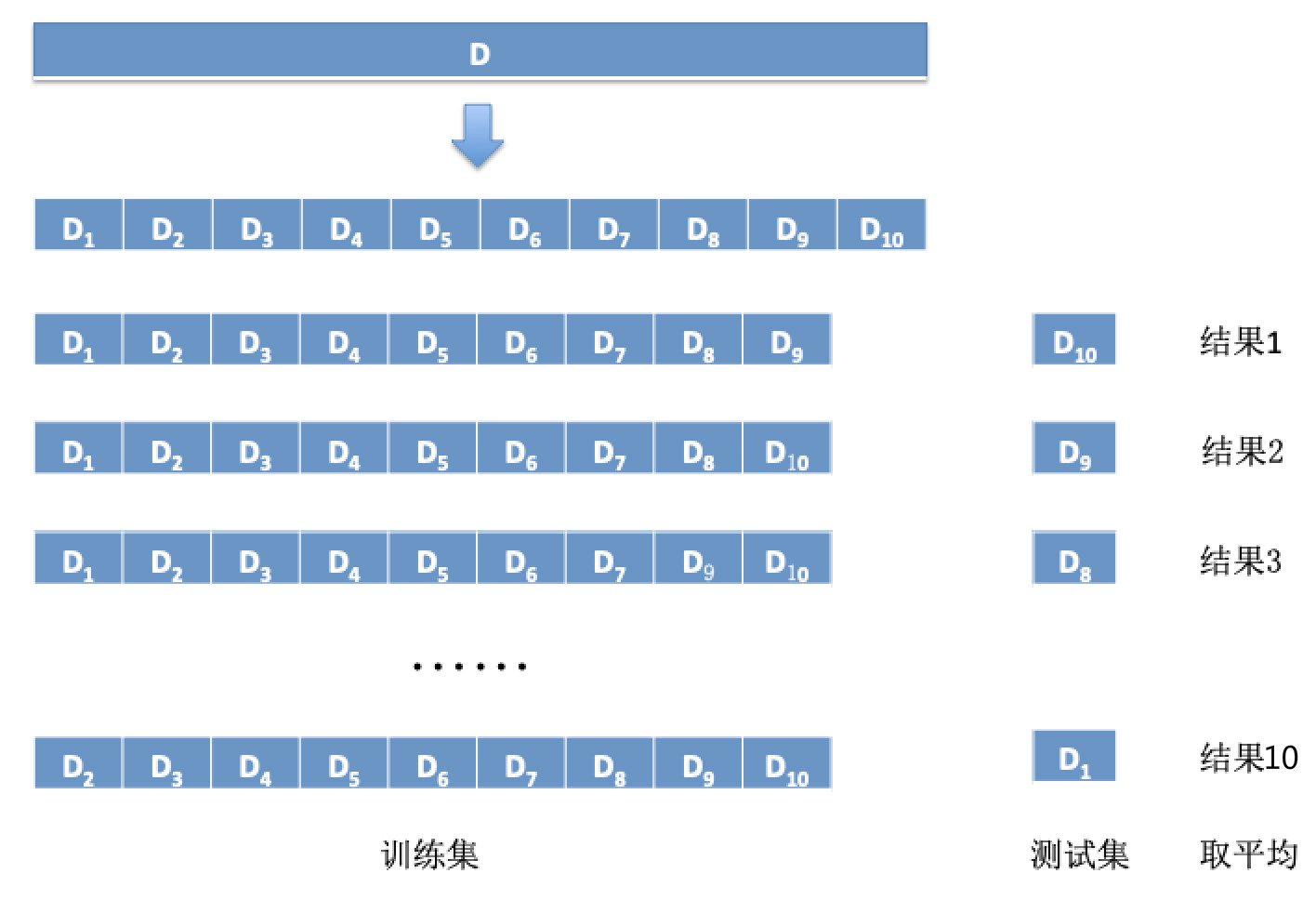
当k等于样本数量时,得到k折交叉验证的特例:留一法 (Leave-One-Out, LOO)。
特点:当数据集D中数据量较大时,训练m个模型的开销过大。
#!/usr/bin/env python3 # 使用10折交叉验证来划分Iris数据集的训练集、测试集
from sklearn.cross_validation import KFold # 参数n_splits决定了k值,即折数
kf = KFold(len(iris.y), n_splits = 10, shuffle = True) for train_index, test_index in kf:
x_train, x_test = iris.x[train_index], iris.x[test_index]
y_train, y_test = iris.y[train_index], iris.y[test_index] x_train.shape, x_test.shape, y_train.shape, y_test.shape
输出结果: ((135, 4), (15, 4), (135, ), (15, ))
或者,其实自己用的更多的是下面一种:
#! /usr/bin/env python3 from sklearn.cross_validation import train_test_split
import numpy as np filename = '文件路径' # 参数delimiter是数据集中属性间的分隔符
data_set = np.loadtxt(filename, delimiter = ';') # 假定该数据集中的属性数目为11,标记label位于数据集的最后一列
x = data_set[:, 0:11]
y = data_set[: 11] # 划分比例为8:2
x_train, y_train, x_test, y_test = train_test_split(x, y, test_size = 0.2) x_train.shape, y_train.shape, x_test.shape, y_test.shape
输出结果: ((16497, 11), (16497,), (4125, 11), (4125,))
3. 自助法 (Bootstrapping)
以自助采样为基础 (Boostrap sampling),给定包含m个样本的数据集D,对D进行采样,产生数据集D':每次随机从D中挑选一个样本,拷贝后放入D',再讲该样本放回D中,使得该样本在下次采样时仍然有可能被采集到。重复该过程m次,即可得到包含m个样本的数据集D',这就是自助采样的结果。显然,部分样本会多次出现,而另一部分则不会,在m次采样中,始终不被采集到的概率为 (1-1/m)m,即:
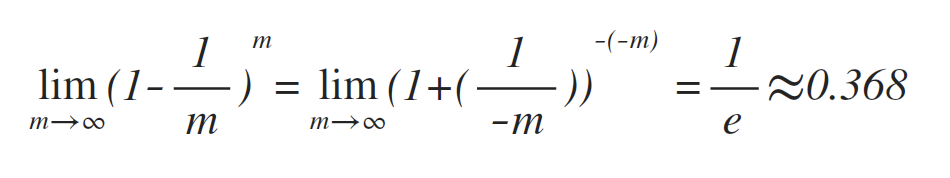
故D中有约36.8%的样本不会出现在D'中,所以将D'用作训练集S,D\D'用作测试集T,这样仍有约36.8%的数据样本不在训练集内,可以用作测试集进行测试。
特点:适用于数据集D中数据量较小时,难以划分训练集、测试集时使用。
Machine Learning笔记整理 ------ (二)训练集与测试集的划分的更多相关文章
- Machine Learning笔记整理 ------ (一)基本概念
机器学习的定义:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E,使其在T中任务获得了性能改善,我们则说关于任务类T和P,该程序对经验E进行了学习(Mitchell, 1997) ...
- Machine Learning笔记整理 ------ (五)决策树、随机森林
1. 决策树 一般的,一棵决策树包含一个根结点.若干内部结点和若干叶子结点,叶子节点对应决策结果,其他每个结点对应一个属性测试,每个结点包含的样本集合根据属性测试结果被划分到子结点中,而根结点包含样本 ...
- Machine Learning笔记整理 ------ (三)基本性能度量
1. 均方误差,错误率,精度 给定样例集 (Example set): D = {(x1, y1), (x2, y2), (x3, y3), ......, (xm, ym)} 其中xi是对应属性的值 ...
- Machine Learning笔记整理 ------ (四)线性模型
1. 线性模型 基本形式:给定由d个属性描述的样本 x = (x1; x2; ......; xd),其中,xi是x在第i个属性上的取值,则有: f(x) = w1x1 + w2x2 + ...... ...
- ML基础 : 训练集,验证集,测试集关系及划分 Relation and Devision among training set, validation set and testing set
首先三个概念存在于 有监督学习的范畴 Training set: A set of examples used for learning, which is to fit the parameters ...
- [DeeplearningAI笔记]ML strategy_2_2训练和开发/测试数据集不匹配问题
机器学习策略-不匹配的训练和开发/测试数据 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.4在不同分布上训练和测试数据 在深度学习时代,越来越多的团队使用和开发集/测试集不同分布的数据来 ...
- 训练集,验证集,测试集(以及为什么要使用验证集?)(Training Set, Validation Set, Test Set)
对于训练集,验证集,测试集的概念,很多人都搞不清楚.网上的文章也是鱼龙混杂,因此,现在来把这方面的知识梳理一遍.让我们先来看一下模型验证(评估)的几种方式. 在机器学习中,当我们把模型训练出来以后,该 ...
- Python sklearn拆分训练集、测试集及预测导出评分 决策树
机器学习入门 (注:无基础可快速入门,想提高准确率还得多下功夫,文中各名词不做过多解释) Python语言.pandas包.sklearn包 建议在Jupyter环境操作 操作步骤 1.panda ...
- 第五周(web,machine learning笔记)
2019/11/2 1. 表现层状态转换(REST, representational state transfer.)一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相 ...
随机推荐
- oracle cascade用法
原文地址:https://www.cnblogs.com/moyijian/p/9940323.html#4111551 级联删除,比如你删除某个表的时候后面加这个关键字,会在删除这个表的同时删除和该 ...
- hdu 1394 Minimum Inversion Number(逆序数对) : 树状数组 O(nlogn)
http://acm.hdu.edu.cn/showproblem.php?pid=1394 //hdu 题目 Problem Description The inversion number ...
- 安装mysql zip 安装包 Navicat连接
笔者在安装mysql时一直出现各种问题,今天难得成功一次,决定记录一下,留作纪念与参考 安装第一步,下载mysql https://dev.mysql.com/downloads/mysql/ 以在w ...
- 【转载】 旧版本Microsoft Office正在配置解决方法
原文:https://blog.csdn.net/sinat_37215184/article/details/81053931 在运行Microsoft Office 2010等旧版本的Office ...
- Cab 安装不成功问题
使用 iexpress.exe 成功打包了cab文件. 可下面问题来了,用静态的html调用,提示安装. 确认安装之后,却提示找不到相应的*.ocx,导致无法安装文件到系统 分析具体原因:*.ocx ...
- python学习笔记:第12天 列表推导式和生成器
目录 1. 迭代器 2. 推导式 1. 迭代器 什么是生成器呢,其实生成器的本质就是迭代器:在python中有3中方式来获取生成器(这里主要介绍前面2种) 通过生成器函数获取 通过各种推导式来实现生成 ...
- python3.5 安装twisted
https://blog.csdn.net/caimouse/article/details/77647952 下载地址:http://www.lfd.uci.edu/~gohlke/pythonli ...
- (数据科学学习手札46)Scala中的面向对象
一.简介 在Scala看来,一切皆是对象,对象是Scala的核心,Scala面向对象涉及到class.object.构造器等,本文就将对class中的重点内容进行介绍: 二.Scala中的类 2.1 ...
- POJ3259_Wormholes_KEY
题目传送门 题目大意:有F组数据,N表示有N点,M表示有M条边,走一遍边需要花费Ti个时间,还有W个虫洞,可以向前回溯Ti时间,求能否从1点出发,经过一些路或虫洞回到1点后时间为负. 建图后用SPFA ...
- Luogu P3120 [USACO15FEB]牛跳房子(金)Cow Hopscotch (Gold)
题目传送门 这是一道典型的记忆化搜索题. f[x][y]表示以x,y为右下角的方案数. code: #include <cstdio> #define mod 1000000007 usi ...