PyODPS DataFrame 的代码在哪里跑
在使用 PyODPS DataFrame 编写数据应用时,尽管编写的是同一个脚本文件,但其中的代码会在不同位置执行,这可能导致一些无法预期的问题,本文介绍当出现相关问题时,如何确定代码在何处执行,以及提供部分场景下解决问题的方法。
概述
假定我们要执行下面的代码:
from odps import ODPS, options
import numpy as np
o = ODPS(access_id, access_key, project, endpoint)
df = o.get_table('pyodps_iris').to_df()
coeffs = [0.1, 0.2, 0.4]
def handle(v):
import numpy as np
return float(np.cosh(v)) * sum(coeffs)
options.df.supersede_libraries = True
val = df.sepal_length.map(handle).sum().execute(libraries=['numpy.zip', 'other.zip'])
print(np.sinh(val))
在开始分析之前,首先需要指出的是,PyODPS 是一个 Python 包而非 Python Implementation,PyODPS 的运行环境均为未经修改的 Python,因而并不会出现与正常 Python 解释器不一致的行为。亦即,你所写的每一条语句不会有与标准 Python 语句不同的行为,例如自动变成分布式代码,等等。
下面解释该代码的执行过程。
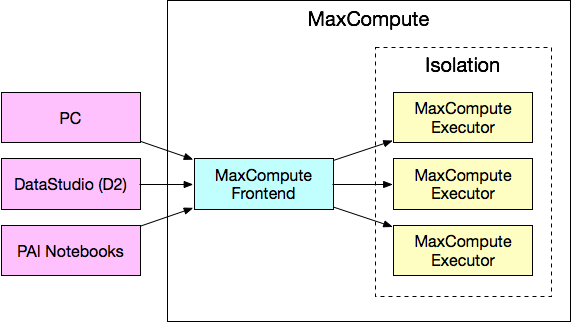
上图是执行上述代码时可能涉及的系统。代码本身执行的位置在图中用紫色表示,这些系统都位于 MaxCompute 外部,为了方便表述,下文称为“本地”。在本地执行的代码包括 handle 函数之外的部分(注意 handle 传入 map 时仅传入了函数本身而并未执行)。因而,这些代码在执行时,行为与普通 Python code 的执行行为类似,import 第三方包时,引用的是本地的包。因而,上面的代码中,libraries=['numpy.zip', 'other.zip']引用的other.zip因为并没有在本地安装,因而如果代码中有诸如 import other 这样的语句,会导致执行报错。即便 other.zip 已被上传到 MaxCompute 资源也是如此,因为本地根本没有这个包。理论上,本地代码如果不涉及 PyODPS 包,则与 PyODPS 无关,用户需要自行排查。
对于 handle 函数,情况发生了变化。handle 函数传入 map 方法时,如果使用的后端是 MaxCompute 后端,会先被 cloudpickle 模块提取闭包和字节码,此后 PyODPS DataFrame 会使用闭包和字节码生成一个 Python UDF,提交到 MaxCompute。最后,作业以 SQL 的形式在 MaxCompute 执行时,会调用这个 Python UDF,其中的字节码和闭包内容会被 unpickle,此后在 MaxCompute Executor 执行。由此可见,在上述代码中,
- 在 handle 函数体中的代码都不会在本地执行,而会在 MaxCompute Executor 中执行;
- handle 函数体中无法引用本地安装的包,只有在 MaxCompute Executor 中存在的包才有效;
- 上传的第三方包必须能够在 MaxCompute Executor 中的 Python 版本(目前为 Python 2.7,UCS2)中调用;
- handle 函数体中修改引用的外部变量(上述代码中的 coeffs)不会导致本地的 coeffs 值被修改;
- 如果在 handle 中引用在 handle 外 import 的包,在 handle 中调用可能会报错,因为在不同环境中,包的结构可能不同,而 cloudpickle 会将本地包的引用带到 MaxCompute Executor,导致报错,因而建议 import 在 handle 中进行;
- 由于使用 cloudpickle,如果在 handle 中调用了其他文件中的代码,该文件所在的包必须存在于 MaxCompute Executor 中。如果你不想使用第三方包的形式解决该问题,请将所有引用的个人代码放在同一个文件中。
上述对 handle 函数的解释对于自定义聚合、apply 和 map_reduce 中调用的自定义方法 / Agg 类均适用。如果使用的后端是 Pandas 后端,则所有代码都会在本地运行,因而本地也需要安装相关的包。但鉴于 Pandas 后端调试完毕后通常会转移到 MaxCompute 运行,建议在本地装包的同时,参照 MaxCompute 后端的惯例进行开发。
使用第三方包
- 个人电脑 / 自有服务器在本地使用第三方包 / 其他文件中的代码
在相应的 Python 版本上安装即可。
- DataWorks 中本地使用其他文件中的代码
该部分功能由 DataWorks 提供,请参考 DataWorks 文档。
- map / apply / map_reduce / 自定义聚合中使用第三方包 / 其他文件中的代码
参考 https://yq.aliyun.com/articles/591508 。需要补充的是,在 DataWorks 上上传资源后,需要点击“提交”确保资源被正确上传到 MaxCompute。如果需要使用自己的 Numpy 版本,在上传正确版本的 wheel 包的同时,需要配置 odps.df.supersede_libraries = True,同时确保你上传的 numpy 包名位于 libraries 的最前面,如果指定了 options.df.libraries,则 numpy 包名需要位于 options.df.libraries 的最前面。
引用其他 MaxCompute 表中的数据
- 个人电脑 / 自有服务器在本地访问 MaxCompute 表
如果 Endpoint 可以连接,使用 PyODPS / DataFrame 访问。
- map / apply / map_reduce / 自定义聚合中访问其他 MaxCompute 表
MaxCompute Executor 中通常不支持访问 Endpoint / Tunnel Endpoint,其上也没有 PyODPS 包可用,因而不能直接使用 ODPS 入口对象或者 PyODPS DataFrame,也不能从自定义函数外部传入这些对象。如果表的数据量不大,建议将 DataFrame 作为资源传入(见 https://pyodps.readthedocs.io/zh_CN/latest/df-element.html#function-resource )。如果数据量较大,建议改写成 join。
访问其他服务
- 个人电脑 / 自有服务器在本地访问其他服务
保证自己的环境中可以正常访问相关服务,生产服务器可以联系 PE。
- DataWorks 上的本地代码中访问其他服务
请咨询 DataWorks。
- map / apply / map_reduce / 自定义聚合中访问其他服务
参考 https://yq.aliyun.com/articles/591508 启用 Isolation,如果仍然遇到网络报错,请联系 MaxCompute 用户群,找 PE 帮忙解决。
本文作者:继盛
本文为云栖社区原创内容,未经允许不得转载。
PyODPS DataFrame 的代码在哪里跑的更多相关文章
- PyODPS DataFrame 处理笛卡尔积的几种方式
PyODPS 提供了 DataFrame API 来用类似 pandas 的接口进行大规模数据分析以及预处理,本文主要介绍如何使用 PyODPS 执行笛卡尔积的操作. 笛卡尔积最常出现的场景是两两之间 ...
- 你的C#代码是怎么跑起来的(二)
接上篇:你的C#代码是怎么跑起来的(一) 通过上篇文章知道了EXE文件的结构,现在来看看双击后是怎样运行的: 双击文件后OS Loader加载PE文件并解析,在PE Optional Header里找 ...
- CLR via C#(01)-.NET平台下代码是怎么跑起来的
1. 源代码编译为托管模块 程序在.NET框架下运行,首先要将源代码编译为托管模块.CLR是一个可以被多种语言所使用的运行时,它的很多特性可以用于所有面向它的开发语言.微软开发了多种语言的编译器,编译 ...
- 你的C#代码是怎么跑起来的(一)
写了那么多C#代码,大家有没有想过自己写的代码编译后的可执行文件内部是什么样子,是怎样在系统上运行的? 编译成exe,然后双击exe文件运行,这中间到底发生了些什么呢,这篇先来剖析下exe内部的样子: ...
- 你编写的Java代码是咋跑起来的?
如果你是一名 Java 开发人员,你肯定指定 Java 代码有很多种不同的运行方式.比如说可以在开发工具(IDEA.Eclipse等)中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至 ...
- VSCode代码修改后跑起来没反应,打开本地文件,代码没变化
两种解决办法: 首先:修改VSCode默认配置文件,点击左下角设置标志图 -> 设置,出来了设置相关的东西,搜索 files.autoSave 第一种:把"files.autoSave ...
- 4.DataFrame(快速开始)
快速开始 基本概念 ''' 在使用 DataFrame 时,需要了解三个对象上的操作:Collection(DataFrame) ,Sequence,Scalar Collection(DataFra ...
- 只有20行Javascript代码!手把手教你写一个页面模板引擎
http://www.toobug.net/article/how_to_design_front_end_template_engine.html http://barretlee.com/webs ...
- vim下使用YouCompleteMe实现代码提示、补全以及跳转设置
配置YouCompleteMe 1. 安装vundle vundle是一个管理vim插件的工具,使用vundle安装YouCompleteMe比较方便. 按照作者在https://github.com ...
随机推荐
- 深入浅析python中的多进程、多线程、协程
深入浅析python中的多进程.多线程.协程 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源 ...
- ObservableCollection类
https://blog.csdn.net/GongchuangSu/article/details/48832721 https://blog.csdn.net/hyman_c/article/de ...
- golang之vscode环境配置
go语言开发,选择vscode作为IDE工具也是一个不错的选择,毕竟goland收费,老是破解也挺麻烦,除了这点,不过说实话挺好用的.vscode的话相对来说就毕竟原始,适合初学者. 1.vscode ...
- Fitnesse批量读取变量信息,并保存到用例执行上下文中
Fitnesse变量可以分成两种,一种是自定义变量,另一种是用例执行过程中的临时变量. 在Finesse使用过程中,如果需要定义一些公共的变量,可以统一在一个文件中使用自定义变量的方法,将公共变量全部 ...
- ubuntu上安装nodejs和npm
在使用npm时,特别注意nodejs的版本问题. 一般选择源码安装
- HR招聘_(十)_招聘方法论(供应商管理)
招聘和供应商长期合作,所以供应商管理也至关重要.供应商一般分为猎头,渠道,外包三类. 猎头 高端职位,高难度职位,急需职位和量大职位会和猎头公司合作共同完成招聘任务,猎头公司一般会有两种服务,猎头和R ...
- 关于rss的内容(转载)
转载自: https://blog.csdn.net/zhao1949/article/details/52806123 (本文对读者有帮助的话请移步支持原作者) 内容记录: 在C++技术网开通了RS ...
- phpstorm服务器配置
转载自百度经验https://jingyan.baidu.com/article/84b4f565ea229960f6da320c.html 这个教程里面后面修改的两步目前没有用到,之后可能会用到,暂 ...
- Codeforces 451D
题目链接 D. Count Good Substrings time limit per test 2 seconds memory limit per test 256 megabytes inpu ...
- 性能监控工具Munin
实际场景 公司产品需要观察Ubuntu主机性能,以衡量客户现场的产品是否能满足高频使用需求 选型 在比较了诸多工具之后,考虑时间成本因素,用了比较简单的Munin 安装步骤 1. apt-get in ...