AI - 概念(Concepts)
01 - 05
01 - AI、ML与DL的关系
从涵盖范围上来讲,人工智能(AI)大于机器学习(ML)大于深度学习(DL)
- 人工智能(AI):能够感知、推理、行动和适应的程序;
- 机器学习(ML):能够随着数据量的增加不断改进性能的算法;
- 深度学习(DL):是机器学习的一个子集,利用多层神经网络从大量数据中进行学习;

02 - 简要对比机器学习与深度学习
通俗来说,机器学习是一门讨论各式各样的适用于不同问题的函数形式,以及如何使用数据来有效地获取函数参数具体值的学科。
深度学习是指机器学习中的一类函数,它们的形式通常为多层神经网络。
“深度学习是一种特殊的机器学习,通过学习将世界使用嵌套的概念层次来表示并实现巨大的功能和灵活性,其中每个概念都定义为与简单概念相关联,而更为抽象的表示则以较不抽象的方式来计算。
03 - ML与DL的主要区别
机器学习(Machine Learning, ML)
- 一个电脑程序要完成任务(Tasks),如果电脑获取的关于T的经验(Experience)越多就表现(Performmance)得越好,那么就可以说这个程序‘学习’了关于T的经验
- 首先人工设置或定义一些重要“指标”和“特征”,就这些“特征”进行编码,然后机器通过分析数据中这些特征,来找到相应的模式(怎样的特征组合会导致怎样的结果)
- 概率论、统计学、逼近论、凸分析、算法复杂度理论等,算法基本固定
深度学习(Deep Learning, DL)
- 深度学习是一种特殊的机器学习,高性能而且灵活
- 概念组成的网状层级结构:底层的特征(Low-level features)组合为中间层特征(Mid-level features),然后进一步组合为高层特征(High-level features)
- 相比机器学习,深度学习试图自己从数据中学习特征,自动找出所需要的重要特征
- 算法更新快,概括为两个方向,图像处理和语音处理,两者分别主要对应卷积神经网络和递归神经网络的应用
机器学习对比深度学习
机器学习
- 数据依赖:当数据规模较小时,传统的机器学习算法使用制定的规则,性能会比较好
- 硬件依赖:一台普通的笔记本即可
- 特征工程:几乎所有的特征都需要通过行业专家确定然后编码为一种数据类型,大多数机器学习算法的性能依赖于所提取的特征的准确度
- 解决问题的方式:通常会将问题分解为多个子问题并逐个子问题解决最后结合所有子问题的结果获得最终结果
- 训练时间:训练消耗的时间相对较少,依据据场景,几秒钟到几小时不等
- 可理解性:算法的特征和规则清晰明确,可以解释决策背后的推理 深度学习
- 数据依赖:随着数据规模的增加其性能也不断增长,更适合数据量大的场景
- 硬件依赖:需要进行大量的矩阵运算,需要有GPU的参与,更依赖安装GPU的高端机器
- 特征工程:尝试从数据中直接获取高等级的特征,削减了对每一个问题设计特征提取器的工作
- 解决问题的方式:一次性地、端到端地解决问题
- 训练时间:参数很多,因此训练算法需要消耗更长的时间,模型一旦训练好,运行预测任务会很快
- 可理解性:深度学习模型复杂,内部的特征和规则难以理解,可能无法解释结果是如何产生的
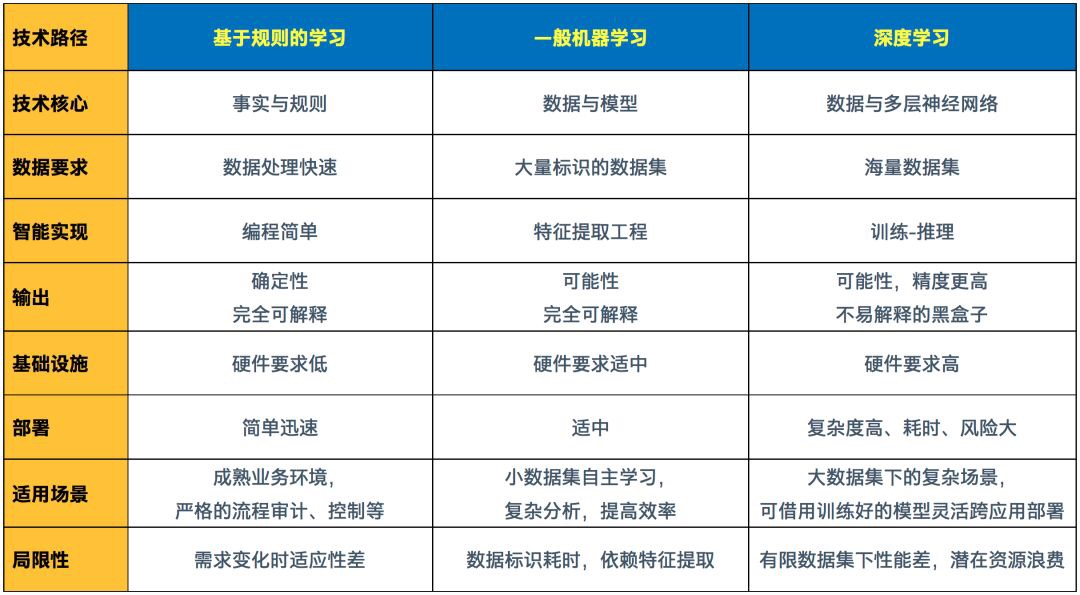
04 - 特征处理
通常原始数据格式基本不能为建模所用,必须从中构建可用于学习的特征。
事实上,这是机器学习项目中的最花精力的部分。但这也是“最有趣”的部分之一,在这里直觉、创造力和“小技巧”与专业技术是同样重要的东西。
- 特征处理是将领域知识放入特征提取器里面来减少数据的复杂度并生成使学习算法工作的更好的模式的过程。
- 特征处理过程很耗时而且需要专业知识。
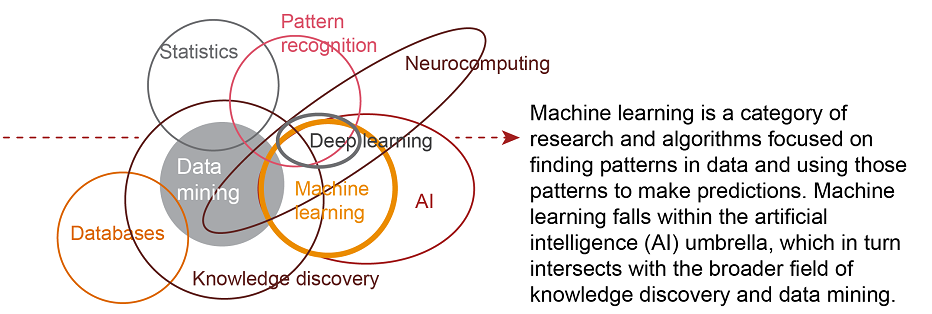
05 - 机器学习与其他学科的关系
机器学习是一种重在寻找数据中的模式并使用这些模式来做出预测的研究和算法的门类。
机器学习是人工智能领域的一部分,并且和知识发现与数据挖掘有所交集。
06 - 10
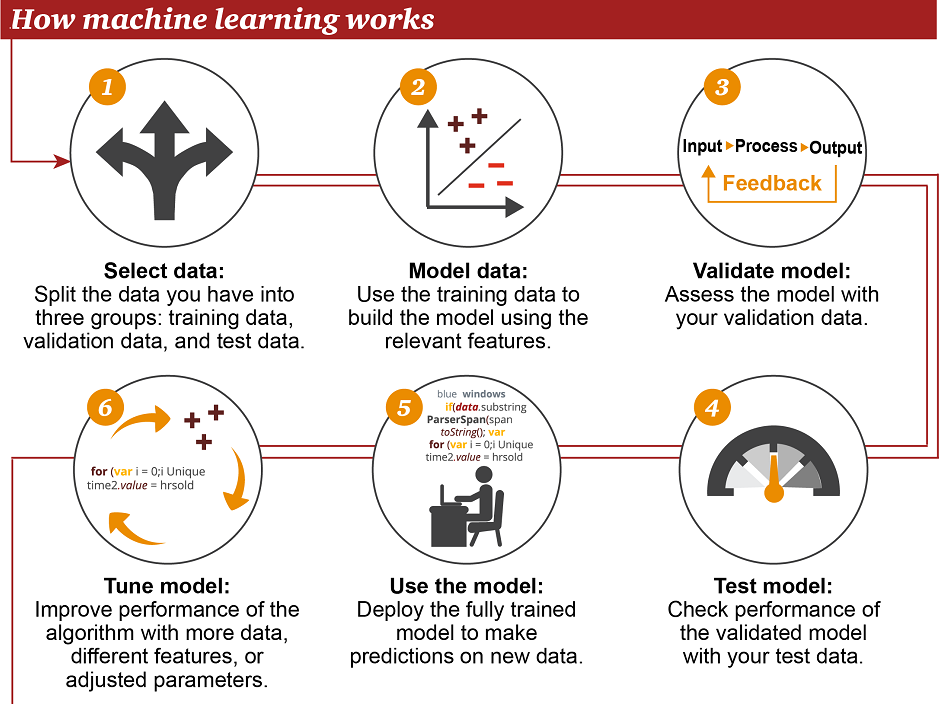
06 - 机器学习的工作方式
- 选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
- 模型数据:使用训练数据来构建使用相关特征的模型
- 验证模型:使用你的验证数据接入你的模型
- 测试模型:使用你的测试数据检查被验证的模型的表现
- 使用模型:使用完全训练好的模型在新数据上做预测
- 调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表
07 - 机器学习所处的位置
传统编程:
软件工程师编写程序来解决问题。
首先存在一些数据→为了解决一个问题,软件工程师编写一个流程来告诉机器应该怎样做→计算机遵照这一流程执行,然后得出结果
统计学:
分析师比较变量之间的关系
机器学习:
数据科学家使用训练数据集来教计算机应该怎么做,然后系统执行该任务。
首先存在大数据→机器会学习使用训练数据集来进行分类,调节特定的算法来实现目标分类→该计算机可学习识别数据中的关系、趋势和模式
智能应用:
智能应用使用人工智能所得到的结果,如图是一个精准农业的应用案例示意,该应用基于无人机所收集到的数据

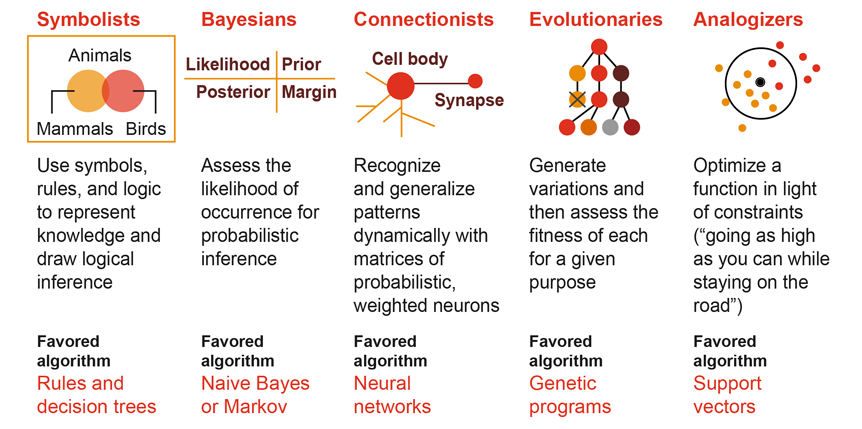
08 - 机器学习的流派
流派合作和算法融合是实现真正通用人工智能(AGI)的唯一方式。
- 符号主义:使用符号、规则和逻辑来表征知识和进行逻辑推理,最喜欢的算法是:规则和决策树
- 贝叶斯派:获取发生的可能性来进行概率推理,最喜欢的算法是:朴素贝叶斯或马尔可夫
- 联结主义:使用概率矩阵和加权神经元来动态地识别和归纳模式,最喜欢的算法是:神经网络
- 进化主义:生成变化,然后为特定目标获取其中最优的,最喜欢的算法是:遗传算法
- Analogizer:根据约束条件来优化函数(尽可能走到更高,但同时不要离开道路),最喜欢的算法是:支持向量
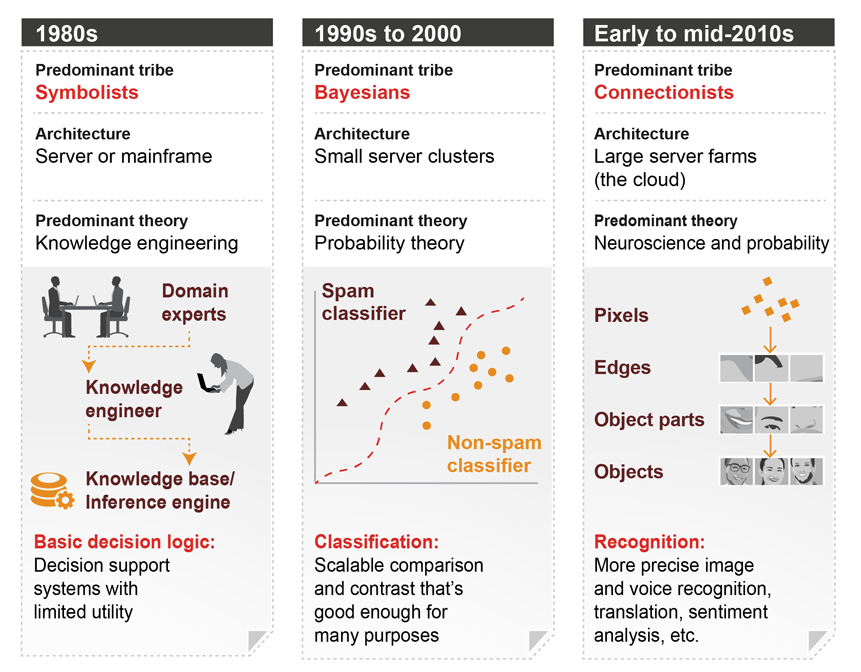
09 - 机器学习的演进阶段
1980 年代
- 主导流派:符号主义
- 架构:服务器或大型机
- 主导理论:知识工程
- 基本决策逻辑:决策支持系统,实用性有限
1990 年代到 2000 年
- 主导流派:贝叶斯
- 架构:小型服务器集群
- 主导理论:概率论
- 分类:可扩展的比较或对比,对许多任务都足够好了
2010 年代早期到中期
- 主导流派:联结主义
- 架构:大型服务器农场
- 主导理论:神经科学和概率
- 识别:更加精准的图像和声音识别、翻译、情绪分析等
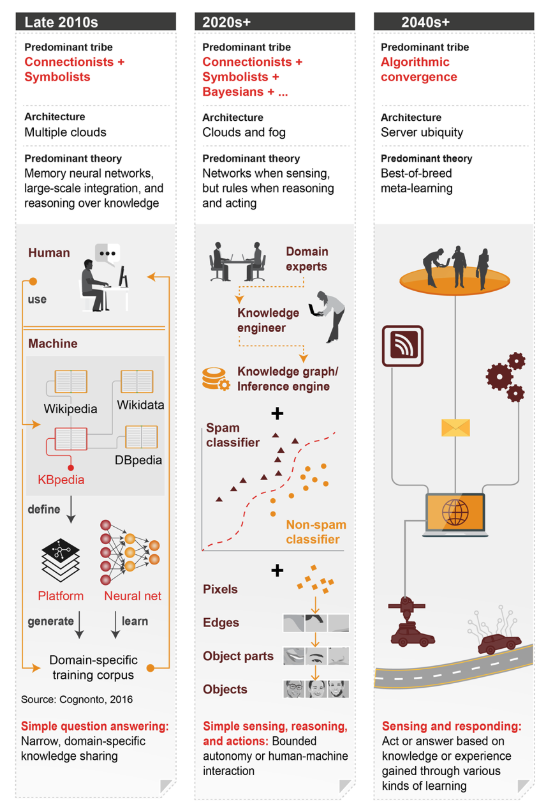
2010 年代末期
- 流派之间开始有望合作,并将各自的方法融合到一起
- 主导流派:联结主义+符号主义
- 架构:许多云
- 主导理论:记忆神经网络、大规模集成、基于知识的推理
- 简单的问答:范围狭窄的、领域特定的知识共享
2020 年代+
- 主导流派:联结主义+符号主义+贝叶斯+……
- 架构:云计算和雾计算
- 主导理论:感知的时候有网络,推理和工作的时候有规则
- 简单感知、推理和行动:有限制的自动化或人机交互
2040 年代+
- 主导流派:算法融合
- 架构:无处不在的服务器
- 主导理论:最佳组合的元学习
- 感知和响应:基于通过多种学习方式获得的知识或经验采取行动或做出回答
10 - 符号主义
符号式编程:“先确定符号以及符号之间的计算关系,然后才放数据进去计算”。
符号之间的运算关系,称为运算图。
符号式计算的优点:
- 当确立了输入和输出的计算关系后,在进行运算前可以对这种运算关系进行自动化简,从而减少计算量,提高计算速度。
- 运算图一旦确定,整个计算过程就都明确了,可用内存复用的方式减少程序占用的内存。
事实上,Keras,Tensorflow和Theano都是符号主义的计算框架。
在Keras,Tensorflow和Theano中,参与符号运算的那些变量统一称作张量(Tensor)。
- 0阶张量:纯量或标量 (scalar), 也就是一个数值,例如,\'Howdy\' 或 5
- 1阶张量:向量 (vector)或矢量,也就是一维数组(一组有序排列的数),例如,[2, 3, 5, 7, 11] 或 [5]
- 2阶张量:矩阵 (matrix),也就是二维数组(有序排列的向量),例如,[[3.1, 8.2, 5.9][4.3, -2.7, 6.5]]
- 3阶张量:三维的矩阵,也就是把矩阵有序地叠加起来,成为一个“立方体”
- 以此类推,等等
简而言之,符号主义计算框架的计算过程,就是建立一个从张量到张量的映射函数,然后再放入真实数据进行计算。
对深度学习而言,这个“映射函数”就是一个神经网络,而神经网络中的每个层自然也都是从张量到张量的映射。
11 - 15
11 - Optimization(优化问题)
解决“优化问题”,可以使用牛顿法 (Newton’s method), 最小二乘法(Least Squares method), 梯度下降法 (Gradient Descent) 等等,神经网络属于梯度下降法。
12 - 误差方程 (Cost Function)
用来计算预测值和实际值的差异,在预测数值的问题中, 常用平方差 (Mean Squared Error) 来代替。
13 - 全局最优解(Global minima)与局部最优解(Local minima)
在误差曲线中, 只要找到梯度线躺平的地方, 就能迅速找到误差最小时的 W.
全局最优固然是最好, 但是很多时候, 获得的只是一个局部最优。
虽然不是全局最优, 但神经网络也能让局部最优足够优秀,即使拿着一个局部最优也能出色完成任务。
14 - 迁移学习(Transfer Learning)
简单来说,对于一个有分类能力的神经网络,保留它的代表特征转换能力(理解能力),用另外一个神经网络替换掉这个神经网络的输出层,用这种移植的方式再进行训练, 可以让它处理不同的问题。
15 - 梯度爆炸与梯度消失
梯度消失
通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是$f'(x) = f(x)(1-f(x))$。
因此两个0到1之间的数相乘,得到的结果就会变得很小了。
神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
梯度爆炸
如果初始化权值过大,前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。
解决梯度消失或者梯度爆炸的方法
梯度消失一般出现在深层网络和采用了不合适的损失函数,比如sigmoid。
梯度爆炸一般出现在深层网络和权值初始化值太大的情况。
解决梯度消失或者梯度爆炸,可以采用ReLU激活函数来替代sigmoid函数。
16 - 20
16 - 神经网络的训练过程
通常分为两个阶段:前向传播和反向传播。
通过前向传播和反向传播不断调整神经网络的权重,最终到达预设的迭代次数或者对样本的学习已经到了比较好的程度后,就停止迭代,此时一个神经网络就基本训练完成。
前向传播
上一层的神经元与本层的神经元有连接,本层的神经元对上一层神经元对应的权值进行加权和运算,然后通过一个非线性函数(激活函数)得到本层神经元的结果,也就是输出。
逐层逐个神经元都通过该操作向前传播,最终得到输出层的结果。
反向传播
由最后一层开始,逐层向前传播进行权值的调整。
前向传播得到的结果与实际的结果得到一个偏差,利用梯度下降法,通过偏导数与残差的乘积从最后一层逐层向前去改变每一层的权重。
17 - 优化器(Optimizer)
选取合适的优化器,可以加速神经网络训练 (Speed Up Training)。
Tensorflow可用的Optimizer有很多不同的种类:https://www.tensorflow.org/api_docs/python/tf/train
Stochastic Gradient Descent (SGD)是最基本最常用的。
将数据拆分成小批量的, 然后再分批不断放入神经网络中计算。
每次使用批数据,虽然不能反映整体数据的情况,不过却很大程度上加速了NN的训练过程,而且也不会丢失太多准确率。
但事实证明SGD并不是最快速的训练方法,而是耗时最长的一种。
除了SGD,还有Momentum、AdaGrad、RMSProp、Adam等来加速训练。
18 - 混淆矩阵与准确率,精准率,召回率
混淆矩阵
二分类的模型,将预测情况与实际情况的所有结果两两混合,就组成了混淆矩阵。
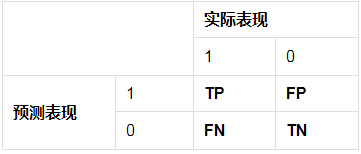
- P(Positive):代表1
- N(Negative):代表0
- T(True):代表预测正确
- F(False):代表错误
准确率(Accuracy)
定义:预测正确的结果占总样本的百分比
公式:准确率=(TP+TN)/(TP+TN+FP+FN)
注意:准确率则代表整体的预测准确程度,但是在样本不平衡的情况下,得到的高准确率结果含有很大的水分,并不能作为很好的指标来衡量结果。
精准率(Precision)、查准率
定义:在所有被预测为正的结果中实际为正的概率,针对的是预测结果
公式:精准率=TP/(TP+FP)
注意:精准率代表对正样本结果中的预测准确程度。
召回率(Recall)、查全率
定义:在实际为正的样本中被预测为正样本的概率,针对的是原样本
公式:召回率=TP/(TP+FN)
注意:召回率越高,代表实际被预测出来的概率越高。
参考信息
机器学习算法常用指标总结:https://www.cnblogs.com/maybe2030/p/5375175.html
练习
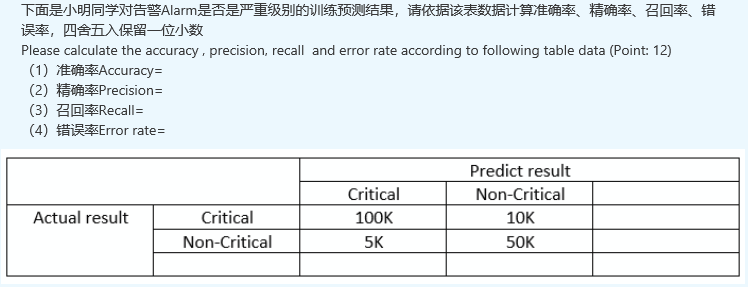

19 - xxx
xxx
AI - 概念(Concepts)的更多相关文章
- boost.asio源码剖析(四) ---- asio中的泛型概念(concepts)
* Protocol(通信协议) Protocol,是asio在网络编程方面最重要的一个concept.在第一章中的levelX类图中可以看到,所有提供网络相关功能的服务和I/O对象都需要Protoc ...
- 花十分钟,让你变成AI产品经理
花十分钟,让你变成AI产品经理 https://www.jianshu.com/p/eba6a1ca98a4 先说一下你阅读本文可以得到什么.你能得到AI的理论知识框架:你能学习到如何成为一个AI产品 ...
- 聊聊找AI算法岗工作
https://blog.csdn.net/weixin_42137700/article/details/81628028 首先,本文不是为了增加大家的焦虑感,而是站在一名学生的角度聊聊找AI算法岗 ...
- ROS学习手记 - 5 理解ROS中的基本概念_Services and Parameters
上一节完成了对nodes, Topic的理解,再深入一步: Services and Parameters 我不理解为何 ROS wiki 要把service与parameter放在一起介绍, 很想分 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- MMORPG大型游戏设计与开发(服务器 游戏场景 聊天管道和寻路器)
又快到双十一,又是不少同仁们出血的日子,首先希望大家玩的开心.我曾经想要仔细的剖析场景的的每个组件,就像这里的聊天管道与寻路器,但是仔细阅读别人代码的时候才发现元件虽小但是实现并不简单,因为有些东西还 ...
- DevOps is dirty work - Dream in One-Click
真是一晃就到年底,年初许的梦想实现了吗?这么残忍的问题还是不要知道答案了吧:) 这恍若隔世的大半年,不仅没有承接着上篇继续聊Continuous Delivery (CD),反而疑似荒废.然而,梦想还 ...
- MEAN Stack:创建RESTful web service
本文在个人博客上的地址为URL,欢迎品尝. 前段时间做了DTREE项目中的前后端数据存储功能,在原有的ngController上进行HTTP请求,后端接受到请求后再存储到mongoDB上.现将学习所得 ...
随机推荐
- [精华][推荐] CAS SSO单点登录环境搭建及实例
1.因为是本地模拟sso环境,而sso的环境测试需要域名,所以需要虚拟几个域名出来,步骤如下: 2.进入目录C:\Windows\System32\drivers\etc 3.修改hosts文件 12 ...
- 自己搭建git服务器
1.安装git 2.创建git用户,给权限(git目录下) 3.设置公钥 4.初始化git仓库 5.给权限(仓库) 连接到本地
- core里使用log4net
1. nuget 里安装 log4net 2. startup.cs里配置读取配置文件 public static ILoggerRepository repository { get; set; } ...
- mysql触发器trigger 实例详解
mysql触发器trigger 实例详解 (转自 https://www.cnblogs.com/phpper/p/7587031.html) MySQL好像从5.0.2版本就开始支持触发器的功能 ...
- django中views中方法的request参数
知其然亦要知其所以然 views每个方法的参数都是request,那么问题来了,request为何物? 首先,几乎每个方法都是取数据(无论是从数据库,还是从第三方接口),然后进行一定的处理,之后传给前 ...
- jquery学习总结12-24
一.jquery操作类的相关方法 1.addClass()方法可以为DOM元素添加类,若添加多个类中间可以用空格连接 2.removeClass()方法可以为DOM元素删除类,若删除多个类中间可以用空 ...
- Web Service CXF的工作流程
我们一起走进系统的内部,跟随每一个调用,去透视系统的每一个层面. 一.我们定义整个目录都在CXFServlet的监控之下 <servlet> <servlet-name>CXF ...
- 交叉编译ffmpeg(hi3520d)
./configure \--prefix=/usr/local/ffmpeg-3520D \--cross-prefix=/opt/hisi-linux-nptl/arm-hisiv100-linu ...
- 逻辑回归 vs 决策树 vs 支持向量机(I)
原文链接:http://www.edvancer.in/logistic-regression-vs-decision-trees-vs-svm-part1/ 分类问题是我们在各个行业的商业业务中遇到 ...
- Python环境安装及IDE介绍
因为最近时间比较松散,公司的业务也不多,所以想趁机赶紧投入到人工智能的学习大业当中.经过多次比较,看到目前市面上还是使用Python做为基础语言较多,进儿学习算法.人工智能组件.机器学习.数据挖掘等课 ...