1、Web应用
一 Web应用的组成
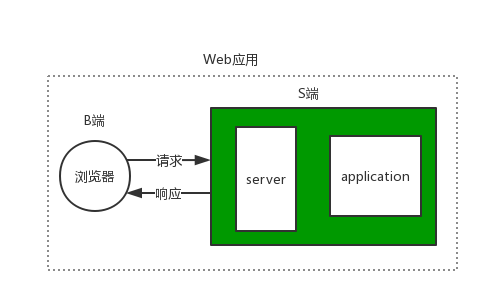
接下来我们学习的目的是为了开发一个Web应用程序,而Web应用程序是基于B/S架构的,其中B指的是浏览器,负责向S端发送请求信息,而S端会根据接收到的请求信息返回相应的数据给浏览器,需要强调的一点是:S端由server和application两大部分构成,如图所示:
二 开发一个Web应用
我们无需开发浏览器(本质即套接字客户端),只需要开发S端即可,S端的本质就是用套接字实现的,如下
# S端
import socket
def make_server(ip, port, app): # 代表server
sock = socket.socket()
sock.bind((ip, port))
sock.listen(5)
print('Starting development server at http://%s:%s/' %(ip,port))
while True:
conn, addr = sock.accept()
# 1、接收浏览器发来的请求信息
recv_data = conn.recv(1024)
# print(recv_data.decode('utf-8'))
# 2、将请求信息直接转交给application
res = app(recv_data)
# 3、向浏览器返回消息(此处并没有按照http协议返回)
conn.send(res)
conn.close()
def app(environ): # 代表application
# 处理业务逻辑
return b'hello world'
if __name__ == '__main__':
make_server('127.0.0.1', 8008, app) # 在客户端浏览器输入:http://127.0.0.1:8008 会报错(注意:请使用谷歌浏览器)
目前S端已经可以正常接收浏览器发来的请求消息了,但是浏览器在接收到S端回复的响应消息b'hello world'时却无法正常解析 ,因为浏览器与S端之间收发消息默认使用的应用层协议是HTTP,浏览器默认会按照HTTP协议规定的格式发消息,而S端也必须按照HTTP协议的格式回消息才行。
S端修订版本:处理HTTP协议的请求消息,并按照HTTP协议的格式回复消息
# S端
import socket
def make_server(ip, port, app): # 代表server
sock = socket.socket()
sock.bind((ip, port))
sock.listen(5)
print('Starting development server at http://%s:%s/' %(ip,port))
while True:
conn, addr = sock.accept()
# 1、接收并处理浏览器发来的请求信息
# 1.1 接收浏览器发来的http协议的消息
recv_data = conn.recv(1024)
# 1.2 对http协议的消息加以处理,简单示范如下
ll=recv_data.decode('utf-8').split('\r\n')
head_ll=ll[0].split(' ')
environ={}
environ['PATH_INFO']=head_ll[1]
environ['method']=head_ll[0]
# 2:将请求信息处理后的结果environ交给application,这样application便无需再关注请求信息的处理,可以更加专注于业务逻辑的处理
res = app(environ)
# 3:按照http协议向浏览器返回消息
# 3.1 返回响应首行
conn.send(b'HTTP/1.1 200 OK\r\n')
# 3.2 返回响应头(可以省略)
conn.send(b'Content-Type: text/html\r\n\r\n')
# 3.3 返回响应体
conn.send(res)
conn.close()
def app(environ): # 代表application
# 处理业务逻辑
return b'hello world'
if __name__ == '__main__':
make_server('127.0.0.1', 8008, app)
此时,重启S端后,再在客户端浏览器输入:http://127.0.0.1:8008 便可以看到正常结果hello world了。
我们不仅可以回复hello world这样的普通字符,还可以夹杂html标签,浏览器在接收到消息后会对解析出的html标签加以渲染
# S端
import socket
def make_server(ip, port, app):
sock = socket.socket()
sock.bind((ip, port))
sock.listen(5)
print('Starting development server at http://%s:%s/' %(ip,port))
while True:
conn, addr = sock.accept()
recv_data = conn.recv(1024)
ll=recv_data.decode('utf-8').split('\r\n')
head_ll=ll[0].split(' ')
environ={}
environ['PATH_INFO']=head_ll[1]
environ['method']=head_ll[0]
res = app(environ)
conn.send(b'HTTP/1.1 200 OK\r\n')
conn.send(b'Content-Type: text/html\r\n\r\n')
conn.send(res)
conn.close()
def app(environ):
# 返回html标签
return b'<h1>hello web</h1><img src="https://www.baidu.com/img/bd_logo1.png"></img>'
if __name__ == '__main__':
make_server('127.0.0.1', 8008, app)
更进一步我们还可以返回一个文件,例如timer.html,内容如下
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h2>{{ time }}</h2>
</body>
</html>
S端程序如下
# S端
import socket
def make_server(ip, port, app): # 代表server
sock = socket.socket()
sock.bind((ip, port))
sock.listen(5)
print('Starting development server at http://%s:%s/' %(ip,port))
while True:
conn, addr = sock.accept()
recv_data = conn.recv(1024)
ll=recv_data.decode('utf-8').split('\r\n')
head_ll=ll[0].split(' ')
environ={}
environ['PATH_INFO']=head_ll[1]
environ['method']=head_ll[0]
res = app(environ)
conn.send(b'HTTP/1.1 200 OK\r\n')
conn.send(b'Content-Type: text/html\r\n\r\n')
conn.send(res)
conn.close()
def app(environ):
# 处理业务逻辑:打开文件,读取文件内容并返回
with open('timer.html', 'r', encoding='utf-8') as f:
data = f.read()
return data.encode('utf-8')
if __name__ == '__main__':
make_server('127.0.0.1', 8008, app)
上述S端为浏览器返回的都是静态页面(内容都固定的),我们还可以返回动态页面(内容是变化的)
# S端
import socket
def make_server(ip, port, app): # 代表server
sock = socket.socket()
sock.bind((ip, port))
sock.listen(5)
print('Starting development server at http://%s:%s/' %(ip,port))
while True:
conn, addr = sock.accept()
recv_data = conn.recv(1024)
ll=recv_data.decode('utf-8').split('\r\n')
head_ll=ll[0].split(' ')
environ={}
environ['PATH_INFO']=head_ll[1]
environ['method']=head_ll[0]
res = app(environ)
conn.send(b'HTTP/1.1 200 OK\r\n')
conn.send(b'Content-Type: text/html\r\n\r\n')
conn.send(res)
conn.close()
def app(environ):
# 处理业务逻辑
with open('timer.html', 'r', encoding='utf-8') as f:
data = f.read()
import time
now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
data = data.replace('{{ time }}', now) # 字符串替换
return data.encode('utf-8')
if __name__ == '__main__':
make_server('127.0.0.1', 8008, app) # 在浏览器输入http://127.0.0.1:8008,每次刷新都会看到不同的时间
三 Web框架的由来
综上案例我们可以发现一个规律,在开发S端时,server的功能是复杂且固定的(处理socket消息的收发和http协议的处理),而app中的业务逻辑却各不相同(不同的软件就应该有不同的业务逻辑),重复开发复杂且固定的server是毫无意义的,有一个wsgiref模块帮我们写好了server的功能,这样我们便只需要专注于app功能的编写即可
wsgiref模块
1.请求来的时候解析http格式的数据 封装成大字典
2.响应走的时候给数据打包成符合http格式 再返回给浏览器
# wsgiref实现了server,即make_server
from wsgiref.simple_server import make_server
def app(environ, start_response): # 代表application
# 1、返回http协议的响应首行和响应头信息
start_response('200 OK', [('Content-Type', 'text/html')])
# 2、处理业务逻辑:根据请求url的不同返回不同的页面内容
if environ.get('PATH_INFO') == '/index':
with open('index.html','r', encoding='utf-8') as f:
data=f.read()
elif environ.get('PATH_INFO') == '/timer':
with open('timer.html', 'r', encoding='utf-8') as f:
data = f.read()
import time
now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
data = data.replace('{{ time }}', now) # 字符串替换
else:
data='<h1>Hello, web!</h1>'
# 3、返回http响应体信息,必须是bytes类型,必须放在列表中
return [data.encode('utf-8')]
if __name__ == '__main__':
# 当接收到请求时,wsgiref模块会对该请求加以处理,然后后调用app函数,自动传入两个参数:
# 1 environ是一个字典,存放了http的请求信息
# 2 start_response是一个功能,用于返回http协议的响应首行和响应头信息
s = make_server('', 8011, app) # 代表server
print('监听8011')
s.serve_forever() # 在浏览器输入http://127.0.0.1:8011/index和http://127.0.0.1:8011/timer会看到不同的页面内容
timer.html已经存在了,新增的index.html页面内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>主页</h1>
</body>
</html>
上述案例中app在处理业务逻辑时需要根据不同的url地址返回不同的页面内容,当url地址越来越多,需要写一堆if判断,代码不够清晰,耦合程度高,所以我们做出以下优化
# 处理业务逻辑的函数
def index(environ):
with open('index.html', 'r', encoding='utf-8') as f:
data = f.read()
return data.encode('utf-8')
def timer(environ):
import datetime
now = datetime.datetime.now().strftime('%y-%m-%d %X')
with open('timer.html', 'r', encoding='utf-8') as f:
data = f.read()
data = data.replace('{{ time }}', now)
return data.encode('utf-8')
# 路径跟函数的映射关系
url_patterns = [
('/index', index),
('/timer', timer),
]
from wsgiref.simple_server import make_server
def app(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
# 拿到请求的url并根据映射关系url_patters执行相应的函数
reuqest_url = environ.get('PATH_INFO')
for url in url_patterns:
if url[0] == reuqest_url:
data = url[1](environ)
break
else:
data = b'404'
return [data]
if __name__ == '__main__':
s = make_server('', 8011, app)
print('监听8011')
s.serve_forever()
随着业务逻辑复杂度的增加,处理业务逻辑的函数以及url_patterns中的映射关系都会不断地增多,此时仍然把所有代码都放到一个文件中,程序的可读性和可扩展性都会变得非常差,所以我们应该将现有的代码拆分到不同文件中
mysite # 文件夹
├── app01 # 文件夹
│ └── views.py
├── mysite # 文件夹
│ └── urls.py
└── templates # 文件夹
│ ├── index.htmlc
│ └── timer.html
├── main.py
views.py 内容如下:
# 处理业务逻辑的函数
def index(environ):
with open('templates/index.html', 'r',encoding='utf-8') as f: # 注意文件路径
data = f.read()
return data.encode('utf-8')
def timer(environ):
import datetime
now = datetime.datetime.now().strftime('%y-%m-%d %X')
with open('templates/timer.html', 'r',encoding='utf-8') as f: # 注意文件路径
data = f.read()
data=data.replace('{{ time }}',now)
return data.encode('utf-8')
urls.py内容如下:
# 路径跟函数的映射关系
from app01.views import * # 需要导入views中的函数
url_patterns = [
('/index', index),
('/timer', timer),
]
main.py 内容如下:
from wsgiref.simple_server import make_server
from mysite.urls import url_patterns # 需要导入urls中的url_patterns
def app(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
# 拿到请求的url并根据映射关系url_patters执行相应的函数
reuqest_url = environ.get('PATH_INFO')
for url in url_patterns:
if url[0] == reuqest_url:
data = url[1](environ)
break
else:
data = b'404'
return [data]
if __name__ == '__main__':
s = make_server('', 8011, app)
print('监听8011')
s.serve_forever()
至此,我们就针对application的开发自定义了一个框架,所以说框架的本质就是一系列功能的集合体、不同的功能放到不同的文件中。有了该框架,可以让我们专注于业务逻辑的编写,极大的提高了开发web应用的效率(开发web应用的框架可以简称为web框架),比如我们新增一个业务逻辑,要求为:浏览器输入http://127.0.0.1:8011/home 就能访问到home.html页面,在框架的基础上具体开发步骤如下:
步骤一:在templates文件夹下新增home.html
步骤二:在urls.py的url_patterns中新增一条映射关系
url_patterns = [
('/index', index),
('/timer', timer),
('/home', home), # 新增的映射关系
]
步骤三:在views.py中新增一个名为home的函数
def home(environ):
with open('templates/home.html', 'r',encoding='utf-8') as f:
data = f.read()
return data.encode('utf-8')
我们自定义的框架功能有限,在Python中我们可以使用别人开发的、功能更强大的Django框架
四 Django框架的安装与使用
在使用Django框架开发web应用程序时,开发阶段同样依赖wsgiref模块来实现Server的功能,我们使用Django框架是为了快速地开发application
4.1 安装
目前在企业开发中Django框架使用的主流版本为1.11.x版本,最新版本为2.x,我们主要讲解1.11版本,同时会涉及2.x的新特性
pip3 install django==1.11.18 # 在命令行执行该命令
# 如何让你的计算机能够正常的启动django项目
1.计算机的名称不能有中文
2.一个pycharm窗口只开一个项目
3.项目里面所有的文件也尽量不要出现中文
4.python解释器尽量使用 3.4~3.6 之间的版本
(如果你的项目报错 你点击最后一个报错信息去源码中把逗号删掉)
4.2 使用
4.2.1 快速创建并启动Django项目
如果使用的是我们自定义的框架来开发web应用,需要事先生成框架包含的一系列基础文件,然后在此基础上进行开发。
如果使用的是Django框架来开发web应用,同样需要事先生成Django框架包含的一系列基础文件,然后在此基础上进行开发。
但Django框架更为方便的地方在于它已经为我们提供了一系列命令来帮我们快速地生成这一系列基础文件
# 在命令行执行以下指令,会在当前目录生成一个名为mysite的文件夹,该文件夹中包含Django框架的一系列基础文件
django-admin startproject mysite
创建功能模块
cd mysite # 切换到mysite目录下,执行以下命令
python manage.py startapp app01 # 创建功能模块app01,此处的startapp代表创建application下的一个功能模块。例如我们要开发application是京东商城,京东商城这个大项目下有一个订单管理模块,我们可以将其命名为app01
运行
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001 会看到Django的欢迎页面。
python manage.py runserver 127.0.0.1:8001 # 还可以这样写全
4.2.2 Django项目目录结构
截目录树的图(按照下述目录截图)
mysite # 文件夹
├── app01 # 文件夹
│ └── migrations # 文件夹
│ └── admin.py
│ └── apps.py
│ └── models.py
│ └── tests.py
│ └── views.py
├── mysite # 文件夹
│ └── settings.py
│ └── urls.py
│ └── wsgi.py
└── templates # 文件夹
├── manage.py
关键文件介绍
-manage.py---项目入口,执行一些命令
-项目名
-settings.py 全局配置信息
-urls.py 总路由,请求地址跟视图函数的映射关系
-app名字
-migrations 数据库迁移的记录
-models.py 数据库表模型
-views.py 处理业务逻辑的函数,简称视图函数
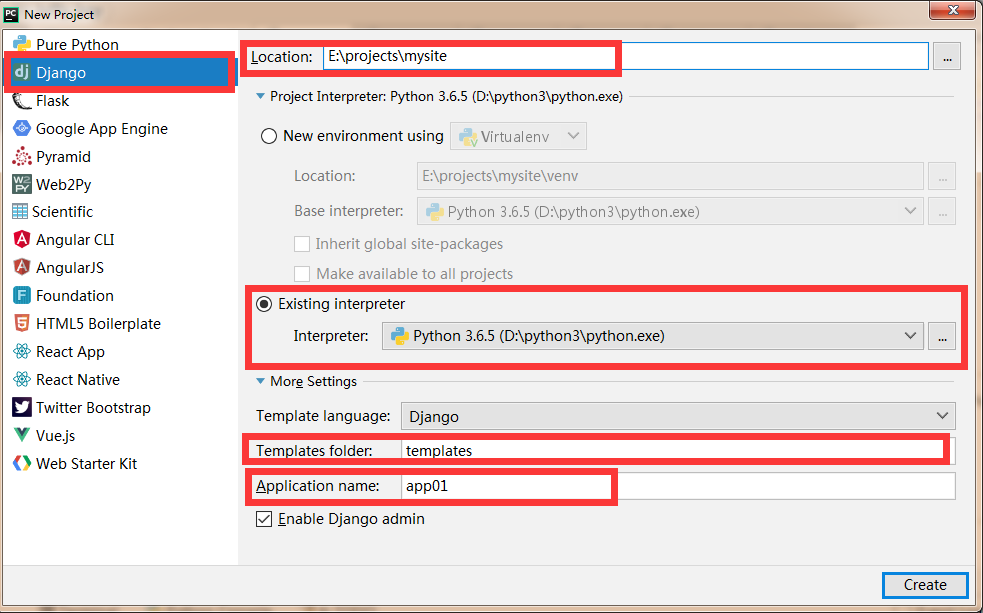
4.2.3 基于Pycharm创建Django项目
4.2.4 基于Django实现的一个简单示例
(1)url.py
from django.contrib import admin
from django.conf.urls import url
#导入views模块
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# r'^index/$' 会正则匹配url地址的路径部分
url(r'^index/$',views.index), # 新增地址http://127.0.0.1:8001/index/与index函数的映射关系
]
(2)视图
from django.shortcuts import render
# 必须定义一个request形参,request相当于我们自定义框架时的environ参数
def index(request):
import datetime
now=datetime.datetime.now()
ctime=now.strftime("%Y-%m-%d %X")
return render(request,"index.html",{"ctime":ctime}) # render会读取templates目录下的index.html文件的内容并且用字典中的ctime的值替换模版中的{{ ctime }}
(3)模版
在templates目录下新建文件index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h4>当前时间:{{ ctime }}</h4>
</body>
</html>
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/index/ 会看到当前时间。
4.2.5 Django框架的分层与请求生命周期
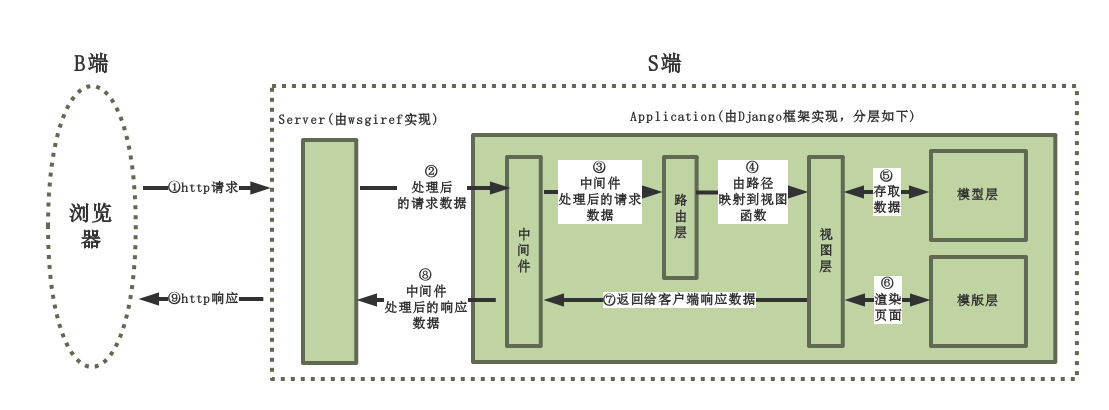
综上,我们使用Django框架就是为了开发application,而application的工作过程本质就是根据不同的请求返回不同的数据,Django框架将这个工作过程细分为如下四层去实现
1、路由层(根据不同的地址执行不同的视图函数,详见urls.py)
2、视图层(定义处理业务逻辑的视图函数,详见views.py)
3、模型层 (跟数据库打交道的,详解models.py)
4、模板层(待返回给浏览器的html文件,详见templates)
django请求生命周期
1、Web应用的更多相关文章
- C# Web应用调试开启外部访问
在用C#开发Web应用时有个痛点,就是本机用VS开启Web应用调试时外部机器无法访问此Web应用.这里将会介绍如何通过设置允许局域网和外网机器访问本机的Web应用. 目录 1. 设置内网访问 2. 设 ...
- 网页提交中文到WEB容器的经历了些什么过程....
先准备一个网页 <html><meta http-equiv="Content-Type" content="text/html; charset=gb ...
- 闲来无聊,研究一下Web服务器 的源程序
web服务器是如何工作的 1989年的夏天,蒂姆.博纳斯-李开发了世界上第一个web服务器和web客户机.这个浏览器程序是一个简单的电话号码查询软件.最初的web服务器程序就是一个利用浏览器和web服 ...
- java: web应用中不经意的内存泄露
前面有一篇讲解如何在spring mvc web应用中一启动就执行某些逻辑,今天无意发现如果使用不当,很容易引起内存泄露,测试代码如下: 1.定义一个类App package com.cnblogs. ...
- 对抗密码破解 —— Web 前端慢 Hash
(更新:https://www.cnblogs.com/index-html/p/frontend_kdf.html ) 0x00 前言 天下武功,唯快不破.但在密码学中则不同.算法越快,越容易破. ...
- 使用 Nodejs 搭建简单的Web服务器
使用Nodejs搭建Web服务器是学习Node.js比较全面的入门教程,因为要完成一个简单的Web服务器,你需要学习Nodejs中几个比较重要的模块,比如:http协议模块.文件系统.url解析模块. ...
- 一步步开发自己的博客 .NET版(11、Web.config文件的读取和修改)
Web.config的读取 对于Web.config的读取大家都很属性了.平时我们用得比较多的就是appSettings节点下配置.如: 我们对应的代码是: = ConfigurationManage ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- Web性能优化:图片优化
程序员都是懒孩子,想直接看自动优化的点:传送门 我自己的Blog:http://cabbit.me/web-image-optimization/ HTTP Archieve有个统计,图片内容已经占到 ...
- 使用ServiceStack构建Web服务
提到构建WebService服务,大家肯定第一个想到的是使用WCF,因为简单快捷嘛.首先要说明的是,本人对WCF不太了解,但是想快速建立一个WebService,于是看到了MSDN上的这一篇文章 Bu ...
随机推荐
- 35岁老半路程序员的Python从0开始之路
9年的ERP程式开发与维护,继而转向一年的售前,再到三年半的跨行业务,近4的兜兜转转又转回来做程式了,不过与之前不同的,是这次是新的程序语言Python, 同时此次是为了教学生而学习! 从今天开始,正 ...
- day01 Pyhton学习
一.python介绍 python是一种解释型.弱类型的高级编程语言. 编译型:是把源程序的每一条语言编译成机器语言,并保存成二进制文件,给计算机执行,运算速度快. 优点:程序执行效率高,可以脱离语言 ...
- C语法-函数不定长参数
目录 前言 语法 va_list va_start va_arg va_end 前言 基于头文件 stdarg.h 基于 STM32 基于 C 如果读者对指针和堆栈的知识点比较熟悉,本笔记就一眼飘过, ...
- rpm|yum安装的查看安装路径
[root@localhost src]# rpm -qa|grep grafanagrafana-7.1.0-1.x86_64[root@localhost src]# rpm -ql grafan ...
- BOOST 条件变量使用
代码: // boost库 条件变量 使用测试 #include <iostream> #include <boost/thread.hpp> using namespace ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- 在学习python的过程中,遇到的最大的困难是什么?
本人文科生,回顾自己近 2 年的Python 自学经历,有一些学习心得和避坑经验分享给大家,让大家在学习 Python 的过程中少走一些弯路!减少遇到不必要的学习困难! 首先,最开始最大的困难应该就是 ...
- 2020-2021-1 20209306 《linux内核原理与分析》第一周作业
学习过程中遇到了如下的问题,通过探索找到了可以解决的方法 1.如何退回主目录或者编辑某个文件夹. 使用cd/home可以退回主目录,这里注意的是绝对路径和相对路径的区别,在学习时我试图切换到home目 ...
- Hive sql函数
date: 2018-11-16 19:03:08 updated: 2018-11-16 19:03:08 Hive sql函数 一.关系运算 等值比较: = select 1 from dual ...
- react-native 常见问题
1.webpack使用babel-loader后编译报错 报错ERROR in ./entry.js Module build failed: SyntaxError: /Users/yixin/De ...