python 手机app数据爬取
今天向大家介绍app爬取。
@
一:爬取主要流程简述
1.APP的爬取比Web爬取更加容易,反爬虫没有那么强,且大部分数据是以JSON形式传输的,解析简单。
2.在APP中想要查看请求与响应(类似浏览器的开发者工具监听到的各个网络请求和响应),就需要借助抓包软件。
3.在抓取之前,需要设置代理将手机处于抓包软件的监听下,就可以用同一网络进行监听,获得所有的网络和请求。
4.如果是有规则的,就只需要分析即可;如果没有规律,就可以用另一个工具mitmdump对接Python脚本直接处理Response。
5.抓取肯定不能由人手动完成,还需要做到自动化,还要对App进行自动化控制,可以用库Appium。
二:抓包工具Charles
1.Charles的使用
Charles是一个网络抓包工具,比Fiddler功能更强大,可以进行分析移动App的数据包,获取所有的网络请求和网络内容
2.安装
(1)安装链接
官网:https://www.charlesproxy.com
(2)须知
charles是收费软件,但可以免费试用30天。试用期过了,还可以试用,不过每次试用不能超过30分钟,启动有10秒的延迟,但大部分还可以使用。
(3)安装后
3.证书配置
(1)证书配置说明
现在很多网页都在向HTTPS(超文本传输协议的加密版,即HTTP加入SSL层),经过SSL加密更加安全,真实,大部分都由CA机构颁发安全签章(12306不是CA机构颁发,但不被信任)。现在应用HTTPS协议的App通信数据都会是加密的,常规的截包方法是无法识别请求内部的数据的。
要抓取APP端的数据,要在PC和手机端都安装证书。
(2)windows系统安装证书配置
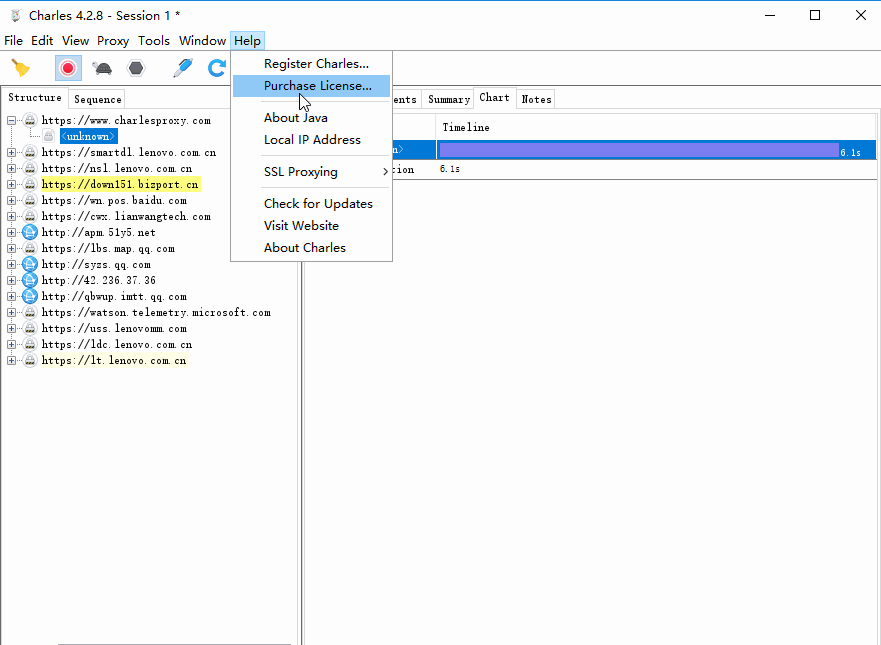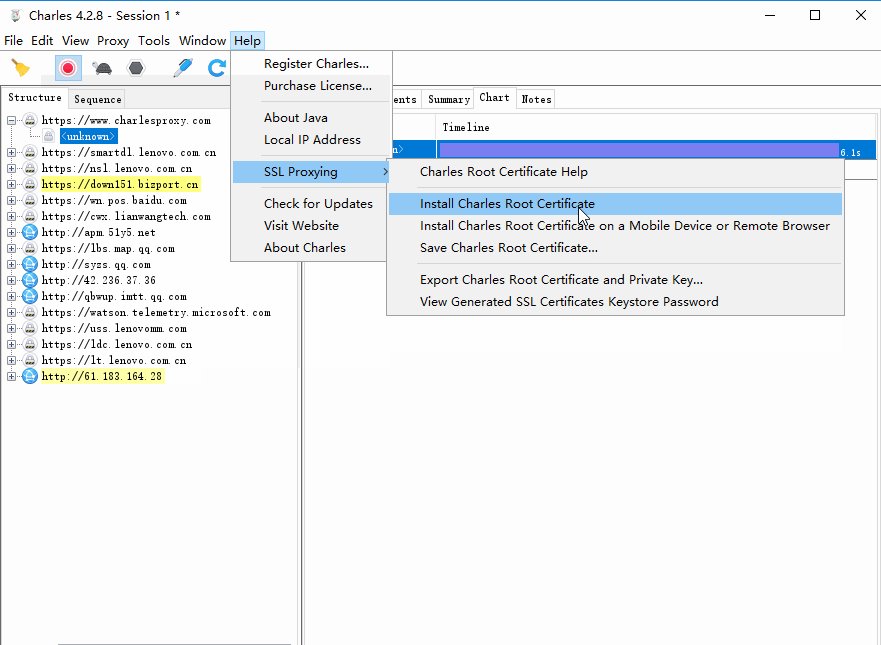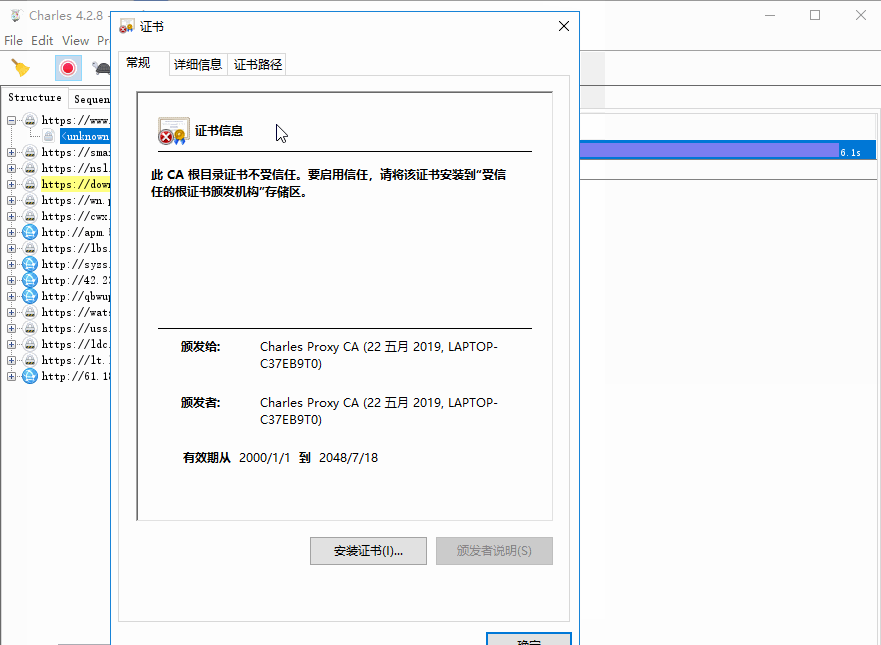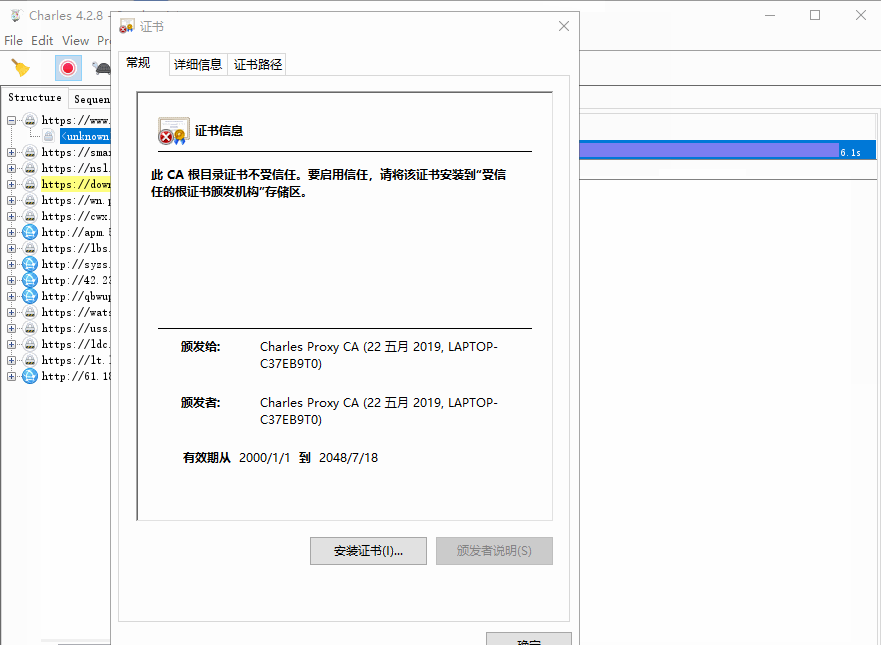
打开Charles,点击Help->SSL Proxying->Install Charles Root Certificate,进入证书的安装页面:
点击安装证书,就会打开证书安装向导,然后点击下一步,此时需要选择证书的存储区域,选择第二个选项”将所有证书放入下列存储”:
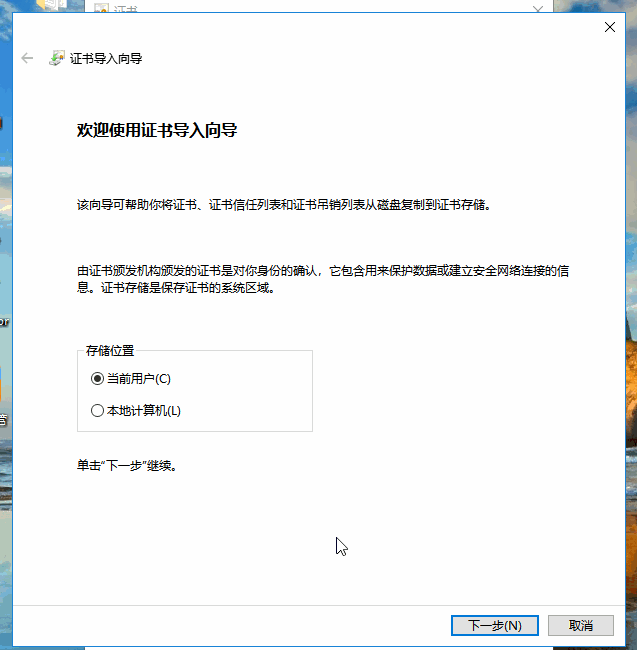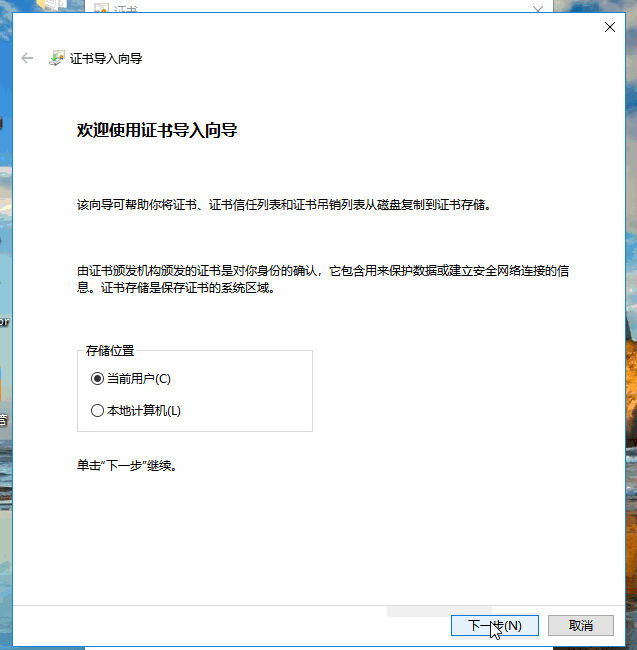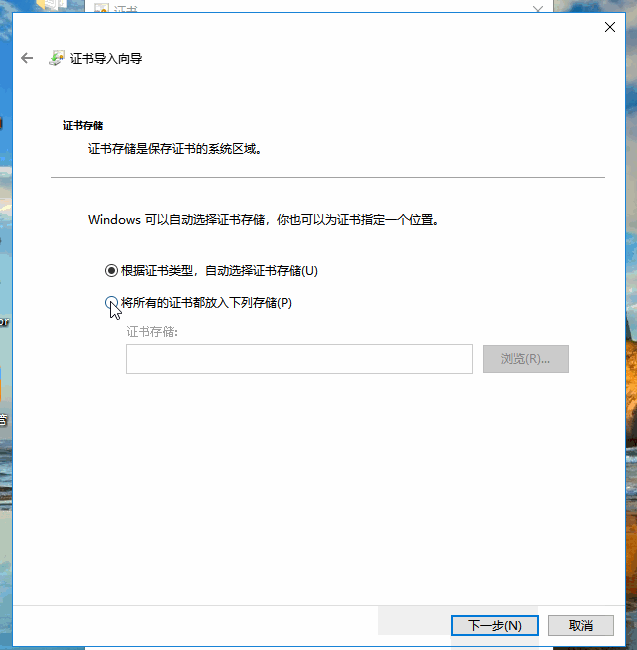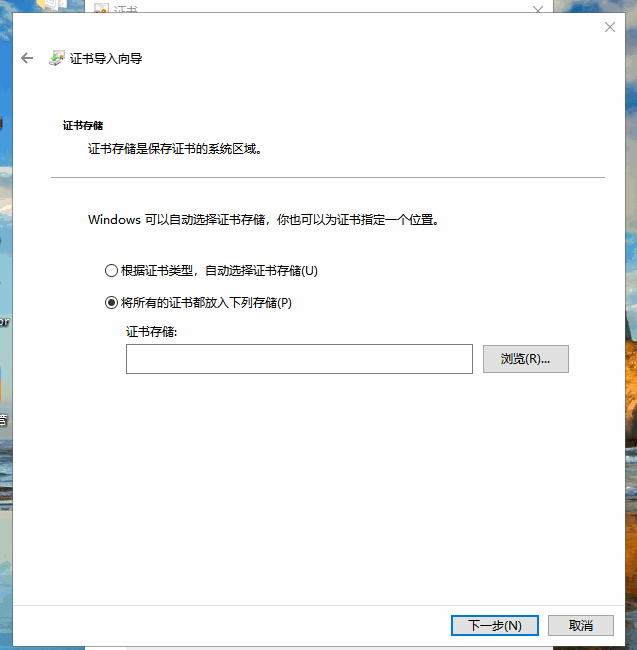
然后点击浏览,选择证书存储位置为”受信任的根证书颁发机构”,点击确认并进入下一步:
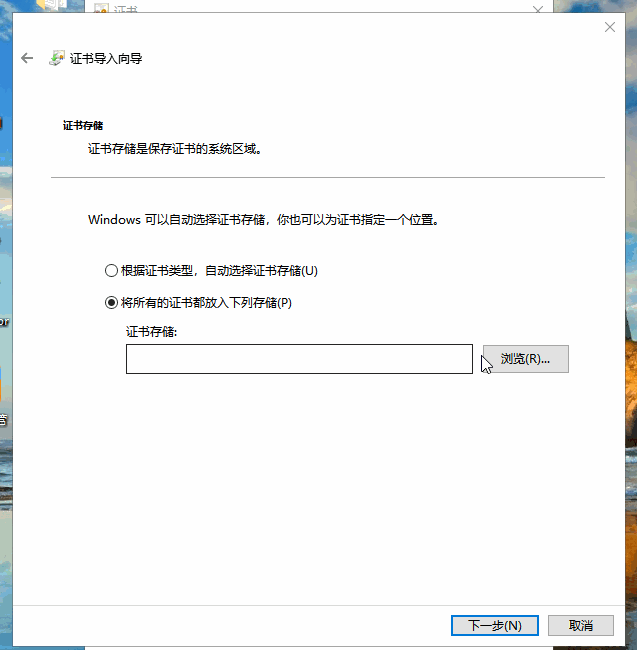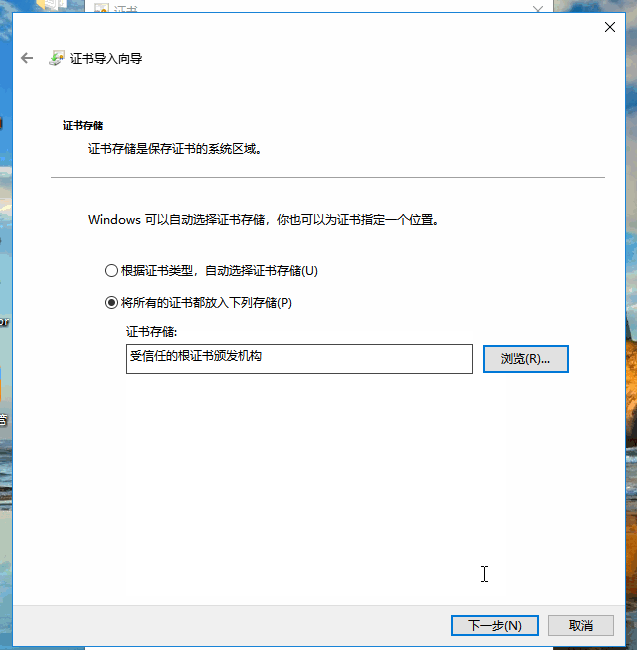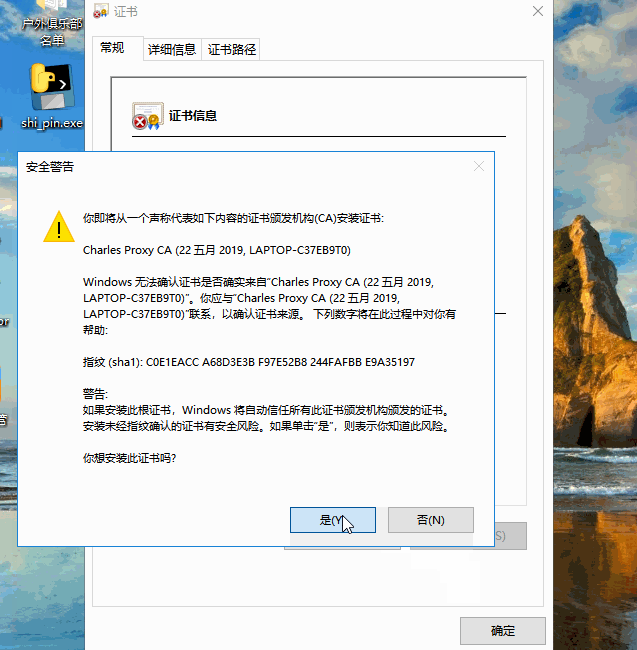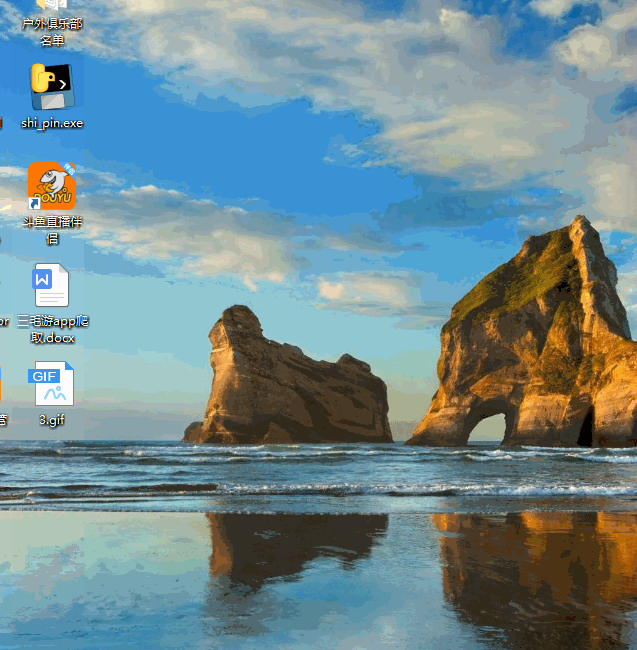
(3)Android手机安装证书配置
手机与电脑连接同一个WiFi。
设置如下:
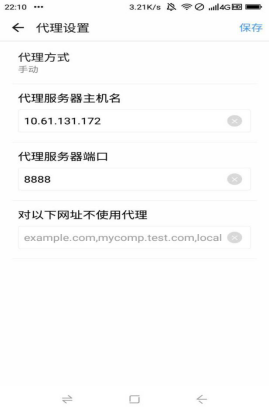
可以用操作系统命令ipconfig查看PC端ip:

为10.61.131.172,默认代理端口号为8888。之后代理服务器为电脑的IP地址。端口为8888。设置如下:
会发现360手机的标志
接下来对手机下载证书:
访问手机访问 chls.pro/ssl ,下载证书:
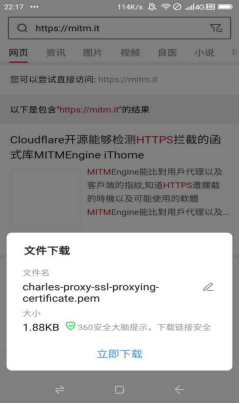
此时下载的是个.pem 格式的。需要手动更改为.crt 格式,最后随便放进某个文件夹即可:
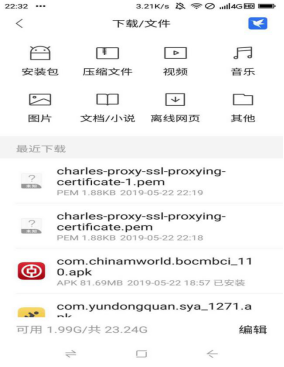
用手机(我用的360手机)设置里的安全,找到从存储设备安装找到该crt文件进行配置:
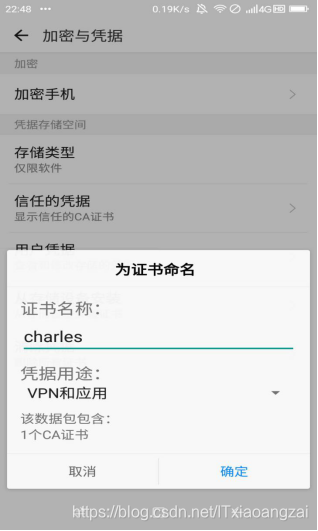
此时需要设置锁屏:
就可以完成证书的安装。
4.开启SSL监听
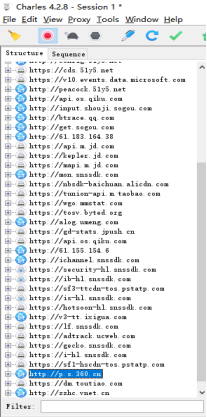
点击Proxy->SSLProxying Settings,在弹出的窗口中点击Add按钮,添加需要监听的地址和端口号。需要监听所有的HTTPS请求,可以直接将地址和端口设置为,即添加:*设置,就可以抓取所有的HTTPS请求包;如果不配置,抓取的HTTPS请求包状态可能是unknown。
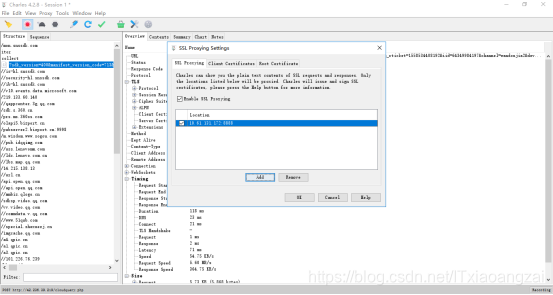
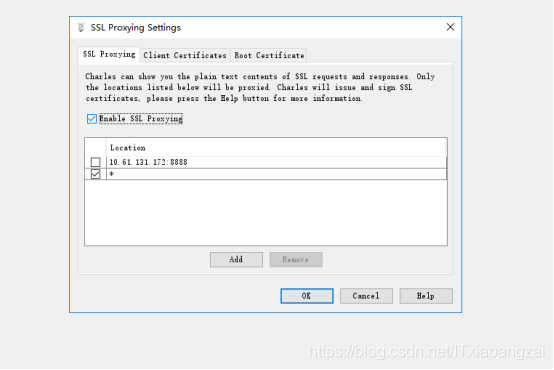
这样就指定只监听我们需要的ip和端口的请求和响应。
5.原理
Charles运行时会在PC端的8888开启一个代理服务,实际上是一个HTTP/HTTPS的代理。
可以是用手机通过相同的无线网络连接(这里用的是校园网),设置手机代理为Charles的代理地址,这样手机访问互联网的数据就会经过Charles抓包工具,Charles转发这些数据到真实的服务器,再转发到手机中。这样抓包工具(Charles)就起到了中间人的作用,还有权对请求和响应进行修改。
6.抓包
我们可以看到我们已经请求了很多数据了,点击左上角的扫帚按钮即可清空捕获到的所有请求,然后点击第二个监听按钮,表明Charles正在监听App的网络数据流。如下:
抓包后可以看到音乐:
可以通过分析不同的URL请求,获得数据,也可以通过修改数据,得到那些参数是需要的。
这是有规则的,无规则的如果没有规律的url,就可以用另一个工具mitmdump对接Python脚本直接处理Response。
三:抓包工具mitmproxy(免费的)
1.简介
mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler和Charles的功能,但它是一个控制台的形式操作。
2.关联组件
mirmproxy还有两个关联组件。一个是mitmdump,是命令行接口,可以对接Python脚本,用Python处理数据;另一个是mitmweb,是一个web程序,可以清楚地查看mitmproxy捕获的请求。
3.安装和证书配置
(1)用pip安装
这个是安装python后就有的安装方法,也是最简单的安装方法,在控制台输入
Pip install mitmproxy即可,会自动安装mitmdump和mitmweb组件:
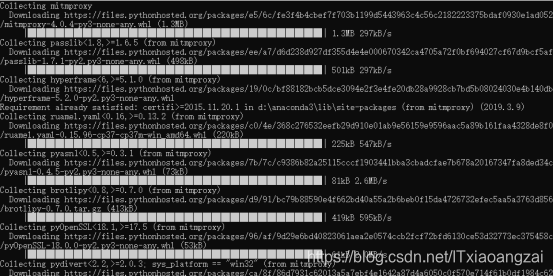
但是到最后安装会失败:
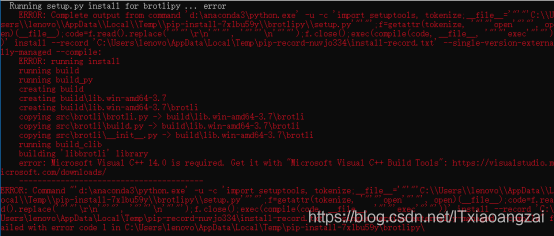
是因为安装这个包的 window 系统需要首先安装 Microsoft Visual C++ V14.0以上 才行。
可以在https://visualstudio.microsoft.com/downloads/
直接下载即可,安装之后需要c++的库之类的东西都安装了,然后再在命令行进行安装 mitmproxy即可:
然后进入安装目录,我们选择第三个:
在“安装 Visual Studio”屏幕中找到所需的工作负载,选择"使用的桌面开发C++"工作负荷:
注:这里的文件太大,我直接安装到E盘。
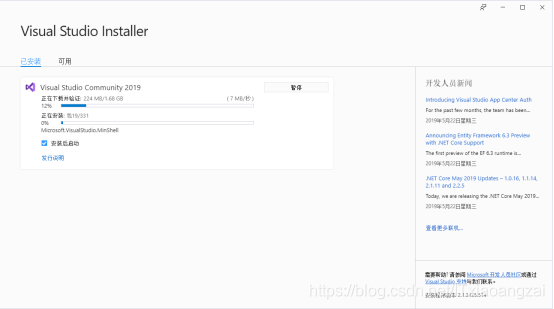
之后再安装就可以安装成功了:

(2)在GitHub或官网上安装
GitHub:https://github.com/mitmproxy/mitmproxy
官网:https://mitmproxy.org
下载地址:https://github.com/mitmproxy/mitmproxy/releases
3.证书配置
(1) 产生CA证书
对于mitmproxy来说,如果想要截获HTTPS请求,也需要设置证书。它在安装后会提供一套CA证书,只要客户端信任了mitmproxy的证书,就可以通过mitmproxy获取HTTPS请求的具体内容,否则无法解析HTTPS请求。
在cmd中输入命令行接口命令mitmdump,产生CA证书,在用户目录找到CA证书:
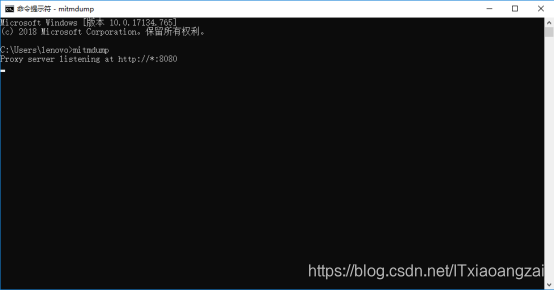
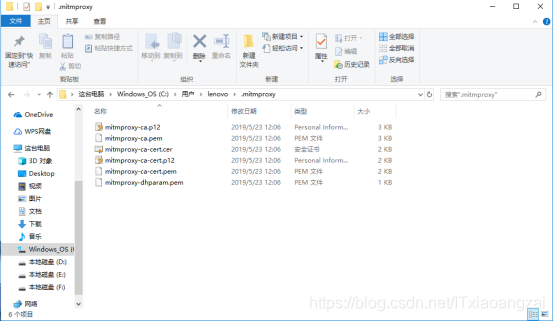
这里的目录可以自行指定,但必须是在第一次运行mimdump时。
(2)PC端安装
电脑是Window系统,因此用mitmproxy-ca.p12,双击后出现导入证书的引导页:
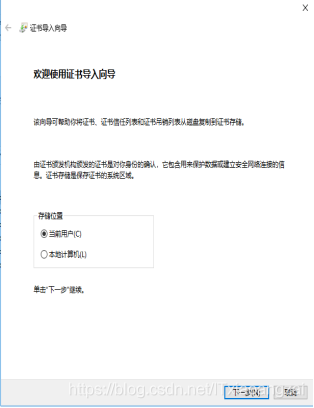
点击下一步,不需要设置密码:
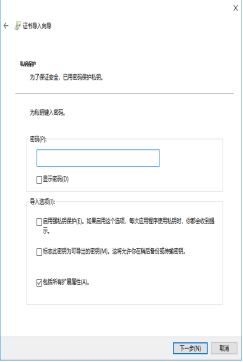
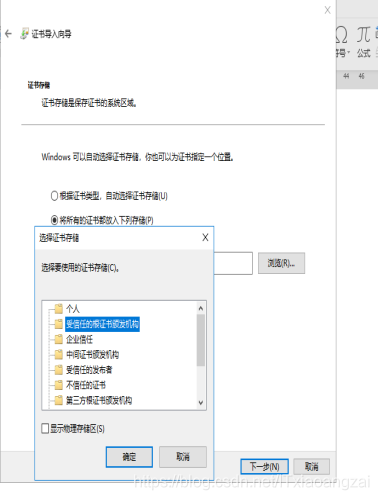
接下来点击下一步,需要选择证书的存储区域,和配置Charles一样:
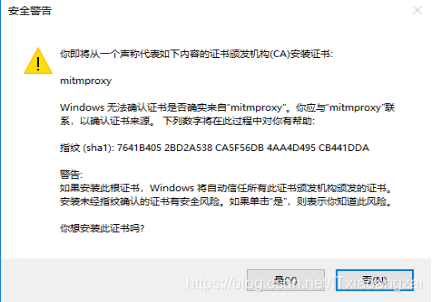
最后会有警告,选择是即可,证书就安装到我们的电脑上了:
(3)手机端安装
我的手机是Android系统,直接把mitmproxy-ca.pem文件发送到手机上即可。
配置方法和Charles类似。HTTPS请求。
手动更改为.crt 格式,最后随便放进某个文件夹即可,用手机(我用的360手机)设置里的安全,找到从存储设备安装找到该crt文件进行配置:
4.抓包原理
在mitmproxy中,会在PC端的8080端口运行,然后开启一个代理服务,就是一个HTTP/HTTPS代理,类似ip代理。
手机和PC在同一局域网内,设置代理为mitmproxy的代理地址,抓包工具mitmproxy就相当于中间人的作用,数据就会流经抓包工具。这个过程还可以对接mitmdump,抓取到的请求和响应都可以直接用Python来处理,然后分析,存到本地,或存到数据库。
5.设置代理
在抓包前需要先设手机局域网置代理为抓包工具mitmproxy代理。
(1)启动代理服务
在cmd中输入mitmproxy,会在8080端口运行一个代理服务,由于该命令不支持Windows系统,因此在Windows系统中用mitmdump命令:

用mitmdump启动代理服务,监听8080端口:

(2)设置当前代理
将手机和电脑连到同一局域网下,先用操作系统命令ipconfig查看PC端当前局域网的ip:
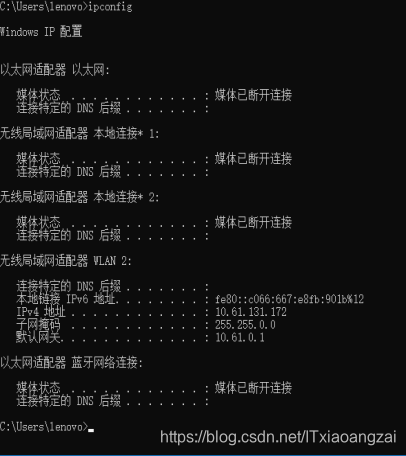
为10.61.131.172,在手机端设置代理如下:

这样就配置好了mitmproxy的代理。
6.抓包
运行mitmweb(由于mitmproxy不能用),就可以看到手机上的所有请求:
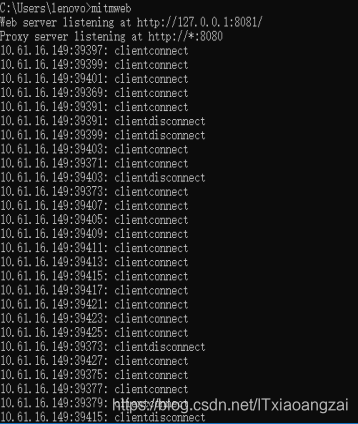
网页呈现如下:
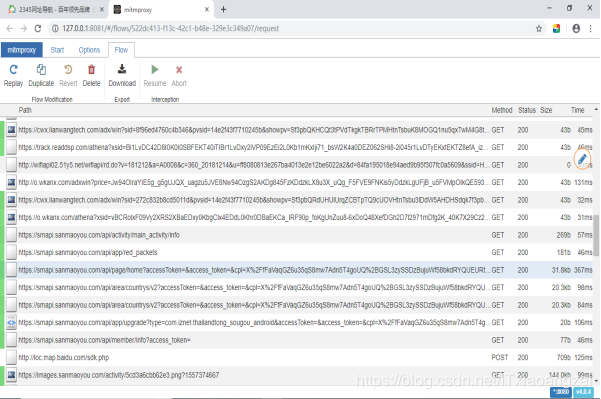
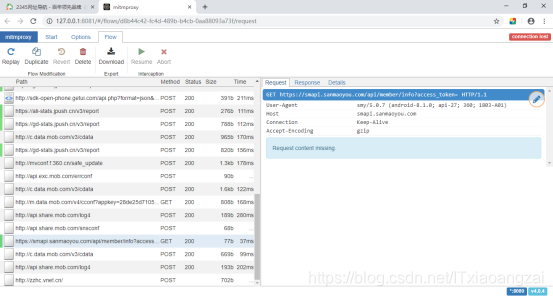
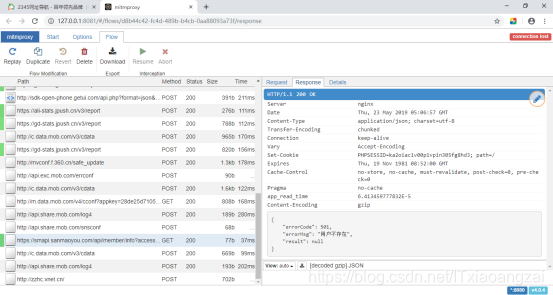
随便打开一条网络请求,发现和在网页的开发者工具下,监听到的一样:
7.mitmproxy的高级功能mitmdump
上面的功能与方法在Fiddler和Charles中也有,那么mitmproxy的优势何在?
在mitmproxy中它的强大体现到mitmdump工具,可以对接Python对数据请求进行处理。
它是mitmproxy的命令行接口,可以对接python程序对请求进行处理,不需要手动截取和分析HTTP请求和响应,进行数据存储和解析都可以通过Python来完成。
(1)简单获取数据(随便一个app)
我们先创建一个文件夹:
然后打开转到该文件夹下:

输入mitmdump -w outfile(outfile名称和扩展名可以自定义,文件放到当前cmd打开目录下,也可以用绝对相对路径,但比较麻烦):
截取广播页面:
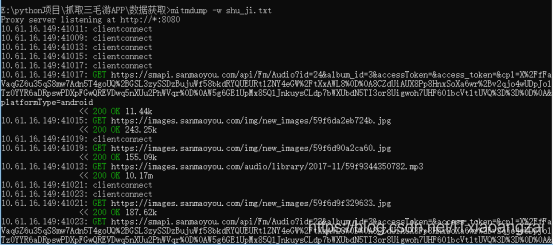
之后把截获的数据保存到文件夹下:

打开文件,发现好多乱码:

下面会对其进行处理。
(2)可以指定一个脚本来处理截获的数据:
Mitmdump -s script.py(脚本名字可以自定义),需要放在cmd当前目录下,也可以用绝对相对路径,但比较麻烦。
写入如下代码:
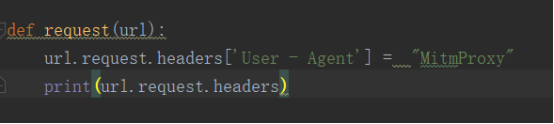
就是定义了一个request()方法,参数为url,其实是一个HTTPFlow对象,通过request属性即可获取到当前请求对象。然后打印出请求头,将User-Agent(用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言浏览器插件等)修改为MitmProxy。
运行之后手机端访问http://httpbin.org/get,可以看到请求头:

PC端如下:
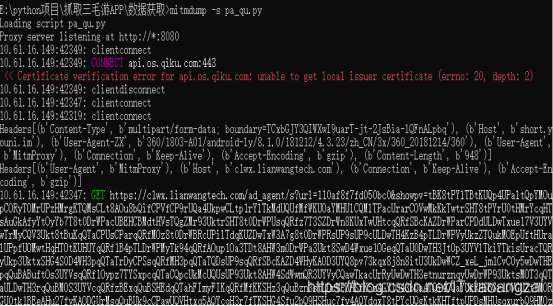
手机端请求的Headers实际上就是请求的Headers,User-Agent被修改成了mitmproxy(防反爬),PC端显示修改后的Headers内容,其User-Agent正是MitProxy。
这样就可以让服务器识别不出我们的是爬虫程序了。
(3)日志输出
mitmdump提供了专门的日志输出功能,就是设定输出到控制台的颜色,可以分别为不同级别配置不同的颜色,更加直观:
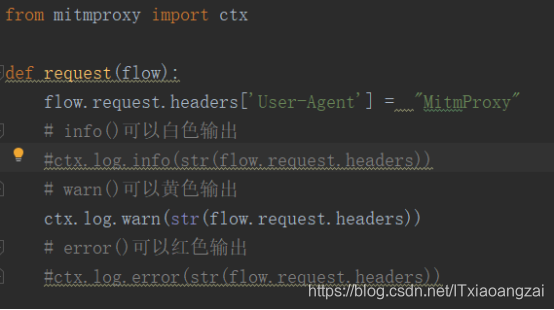
效果如下:
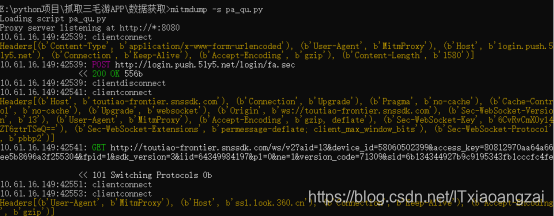
(4)输出请求数据
可以输出一些请求信息,比如请求连接(url),请求头(headers),请求Cookies(cookies),请求Host(host),请求方法(method),请求端口(port),请求协议(scheme)等。
还可以把这些请求的信息进行修改后,再发送到服务器中,这样,服务器返回的可能不是app想请求的网页,这就是为什么一些app打开后却访问到了其他网址的原因。
也可以通过该用法,通过修改Cookies,添加代理等方式来尽可能避免反爬。
这里就先进行略过。
(5)获得响应
响应就是请求后服务器返回的信息,也就是我们需要的,大部分是json格式文件。
对于json格式文件,mitmdump也提供了对应的处理接口,就是response()方法。
我们可以打印各个http/https请求的响应内容,不过text才是我们想要的json格式文件,也可以用content,不过返回的是二进制文件。
代码如下:
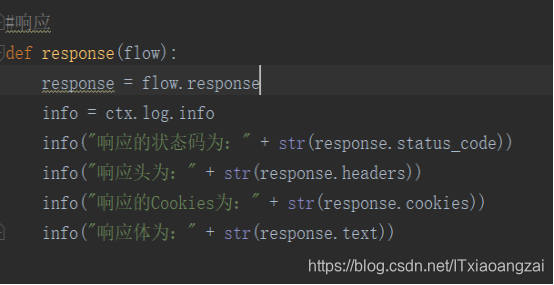
我们先试一下:
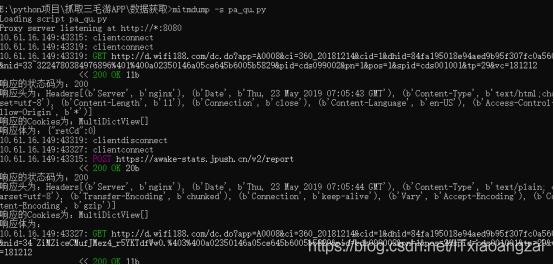
内容有些乱,接下来我们就进行分析得到我们需要的数据。
四:利用mitmproxy进行app数据获取
1.获取请求url
获取http/https请求url,也可以认为是接口:
修改python文件,获得请求的url:
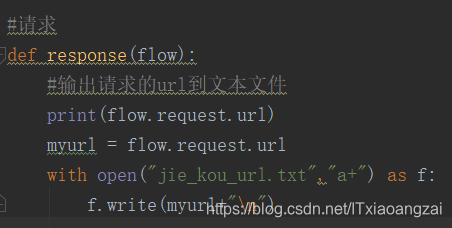
然后停留在该页面:
会发现出现了好多url:
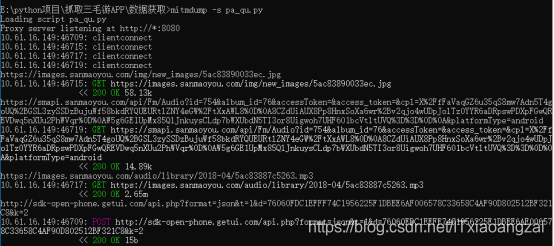
我们一一分析一下,发现接口信息分别是:
这个接口
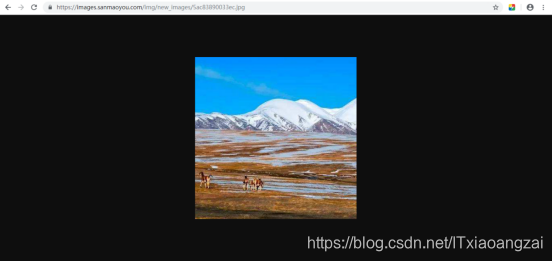
https://images.sanmaoyou.com/img/new_images/5ac83890033ec.jpg
是GET请求获取文件:
这个接口的为json文件,为GET获取方式:

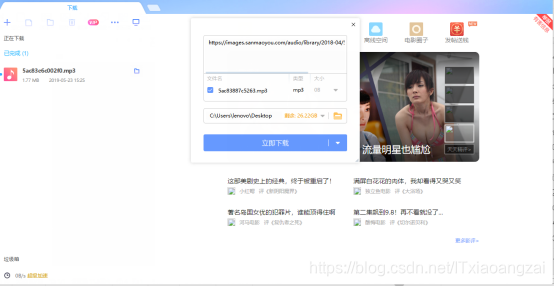
这个接口
https://images.sanmaoyou.com/audio/library/2018-04/5ac83887c5263.mp3
是下载音乐,为GET获取方式:
这个接口
http://sdk-open-phone.getui.com/api.php?format=json&t=1&d=76060FDC1EFFF74C1956225F1DBEE6AF006578C33658C4AF90D802512BF321C8&k=2是POST方式,是传文件。
我们在向右点击下一个广播,进行验证:
发现基本上,新打开一个广播后,会加载mp3文件,图片文件,比较长的接口就返回json文件:
2.接口url文件
把接口保存到txt文件中:
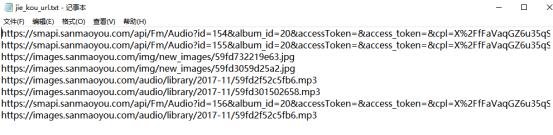
发现只有很长的接口才返回json文件。因此下面就需要对这些接口进行筛选。
3.爬取json
代码在pa_qu_json.py文件中,需要先创建一个json爬取数据文件夹,爬取后的结果如下:
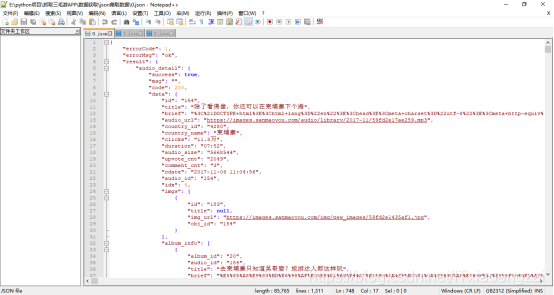
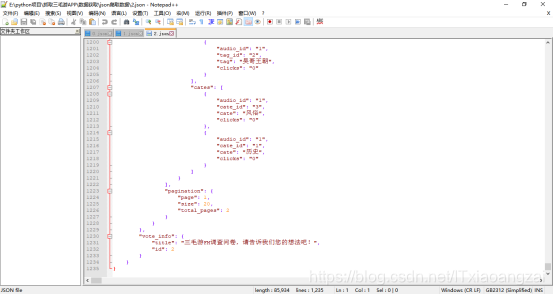
接下来用Python处理即可,这里只是简单爬取。在实际应用中,不是人工的,是用代码自动化进行分析各个请求和响应进行爬取。这里有个跨平台的移动端自动化测试工具,可以很方便地进行自动化爬取,在下一个爬虫博客中会详细讲到,希望大家把宝贵意见提出来一起学习进步。
python 手机app数据爬取的更多相关文章
- python 手机App数据抓取实战二抖音用户的抓取
前言 什么?你问我国庆七天假期干了什么?说出来你可能不信,我爬取了cxk坤坤的抖音粉丝数据,我也不知道我为什么这么无聊. 本文主要记录如何使用appium自动化工具实现抖音App模拟滑动,然后分析数据 ...
- python 手机App数据抓取实战一
前言 当前手机使用成为互联网主流,每天手机App产生大量数据,学习爬虫的人也不能只会爬取网页数据,我们需要学习如何从手机 APP 中获取数据,本文就以豆果美食为例,讲诉爬取手机App的流程 环境准备 ...
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- Python进行拉勾网数据爬取框架与思路
爬取内容 用交互式的方式输入想查询的职位并循环输出职位简要信息,为了方便阅读,本文使用到的变量并不是以目标变量的英文来命名,而是为了方便而取的变量名,各位大牛请谅解.(因贵网站爬取一定量数据后需要登陆 ...
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python3,x:如何进行手机APP的数据爬取
Python3,x:如何进行手机APP的数据爬取 一.简介 平时我们的爬虫多是针对网页的,但是随着手机端APP应用数量的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来 ...
- 人人贷网的数据爬取(利用python包selenium)
记得之前应同学之情,帮忙爬取人人贷网的借贷人信息,综合网上各种相关资料,改善一下别人代码,并能实现数据代码爬取,具体请看我之前的博客:http://www.cnblogs.com/Yiutto/p/5 ...
随机推荐
- Django---SETTINGS配置(***)
Django---SETTINGS核心配置项 django核心配置项 Django的默认配置文件中,包含上百条配置项目,其中很多是我们'一辈子'都不碰到或者不需要单独配置的,这些项目在需要的时候再去查 ...
- 74HC238引脚定义 使用方法
三八译码器 用作IO扩展与复用 用3个IO,可以控制8个输出 引脚定义 A0~A2:3个输入 E1.E2:拉低使能,可以接地 E3:拉高使能,可以接VCC Y0~Y7:8个输出 真值表 如果想输出8个 ...
- Linux 查找目录下大于*M的文件
1. 查找指定文件夹下等于1M的文件 find ./ -size 1M | wc -l 2. 查找指定文件夹下大于1M的文件 find ./target_path -size +1M | wc -l
- zsh: command not found: 解决方法
问题原有:mac中安装了my zsh [https://www.cnblogs.com/dadonggg/p/11027454.html] ,但是造成了在使用vscode的时候,提示”zsh: com ...
- Mysql—配置文件my.ini或my.cnf的详解
[mysqld] log_bin = mysql-bin binlog_format = mixed expire_logs_days = # 超过7天的binlog删除 slow_query_log ...
- 4-8 pie与布局
In [1]: %matplotlib inline import matplotlib.pyplot as plt 1.pie简单参数:plt.pie(x, explode=None, labe ...
- 01-路由跳转 安装less this.$router.replace(path) 解决vue/cli3.0语法报错问题
2==解决vue2.0里面控制台包的一些语法错误. https://www.jianshu.com/p/5e0a1541418b 在build==>webpack.base.conf.j下注释掉 ...
- 201871010111-刘佳华《面向对象程序设计(java)》第6-7周学习总结
201871010111-刘佳华<面向对象程序设计(java)>第6-7周学习总结 实验六 继承定义与使用 实验时间 2019-9-29 第一部分:理论部分. 1.继承:已有类来构建新类的 ...
- win10安装配置mongodb
1. 下载MongoDB并安装官网下载地址:https://blog.csdn.net/qq_41127332/article/details/80755595 ,选择合适的版本进行下载.我选择是3. ...
- Ubuntu16.04下安装Cmake-3.8.2并为其配置环境变量
下载安装包 首先我们到官网下载最新的cmake二进制安装包https://cmake.org/files/ 这里,我下载的是比较新的cmake-3.8.2-Linux-x86_64.tar.gz解压安 ...