Redis主从,集群部署及迁移
工作中有时会遇到需要把原Redis集群下线,迁移到另一个新的Redis集群的需求(如机房迁移,Redis上云等原因)。此时原Redis中的数据需要如何操作才可顺利迁移到一个新的Redis集群呢? 本节简单介绍相关方法及一些工具;
redis有主从架构及redis-cluster架构,架构不同,两者的迁移方法也是不相同的;
Redis主从迁移
若原来的redis集群为主从结构,则迁移工作是相当简单方便的。可使用slaveof迁移或aof/rdb迁移数据。
- slaveof : 利用slaveof制作新的从库,从而达到数据迁移的目的。
- aof迁移: 暂停写服务,把aof文件导出到新的redis机群中完成数据迁移。
slaveof同步数据
如下示例:将把原来redis_master 192.124.64.212:6379迁移到新redis_master 192.124.64.214:6380。
#旧 redis_master 192.124.64.212:6379 --> 新redis_master 192.124.64.214:6380
1.数据同步
$redis-cli -h redis_master_new 6380 slaveof redis_master_old 6379
$redis-cli -h 192.124.64.214 6380 slaveof 192.124.64.212 6379
2.修改新read-only配置为no.
修改新redis的read-only配置为no,新的redis可以写数据。否则会出错.
$redis-cli -h 192.124.64.214 -p 6380 -a pwd123 set foo bar
(error) READONLY You can't write against a read only slave
查看当前slave-read-only配置
$redis-cli -h 192.124.64.214 -p 6380 -a pwd123 config get slave-read-only
1) "slave-read-only"
2) "yes"
$redis-cli -h 192.124.64.214 6380 config set slave-read-only no
$redis-cli -h 192.124.64.214 6380 config get slave-read-only
3. 业务停止对原redis停写.
4. 业务变更redis配置,重启web服务
业务修改redis配置为新的redis地址,并重启web服务。
5. 检查新/旧redis链接情况
旧redis:
redis-cli -h 192.124.64.212 -p 6379 -a pwd123 info clients
connected_clients:1
redis-cli -h 192.124.64.212 -p 6379 -a pwd123 client list
redis-cli -h 192.124.64.212 -p 6379 -a pwd123 client list |awk -F'addr=' '{print $2}' | awk '{print $1}'|awk -F':' '{print $1}'|sort |uniq -c|sort -nr
1 192.124.64.214
新redis:
redis-cli -h 192.124.64.214 -p 6380 -a pwd123 info clients
redis-cli -h 192.124.64.214 -p 6380 -a pwd123 dbsize
6.断开同步
redis-cli -h 192.124.64.214 -p 6380 info |grep role
redis-cli -h 192.124.64.214 -p 6380 slaveof NO ONE
OK
redis-cli -h 192.124.64.214 -p 6380 info |grep role
role:master
7. 测试业务情况(略)
aof同步数据
若是原来的redis可以暂停写操作,则咱们用aof来同步数据也很方便;
#旧redis导出aof文件
$redis-cli -h old_instance_ip -p old_instance_port config set appendonly yes
$redis-cli -h old_instance_ip -p old_instance_port configconfig get appendonly
1) "appendonly"
2) "yes"
#aof文件导入到新的redis
$redis-cli -h new_redis_instance_ip -p 6379 -a password --pipe < appendonly.aof
#导入完成后,关闭原redis AOF
$redis-cli -h old_instance_ip -p old_instance_port config set appendonly no
Slaveof及aof迁移对比
slaveof 会把目标redis库上当前的key全部清除,这点要注意。
当redis数据量较大时使用slaveof xxx,会给master带来较大的压力。最好业务低峰时间处理。
aof迁移数据可以保留新redis上已存在的数据,这点不同于slaveof。
aof不能实时同步,所以迁移期间的redis增量数据不能同步,故常需要把原来的redis停写操作。
Redis集群迁移
Redis-cluster介绍
Redis-cluster是 redis 的一个分布式实现,cluster将数据存储到多个不同Redis实例中,解决了单机Redis容量有限的问题。并且Redis-cluster某个节点故障时,若此节点有可用的从库,则redis-cluster将可以继续处理请求,从而实现了redis的高可用。
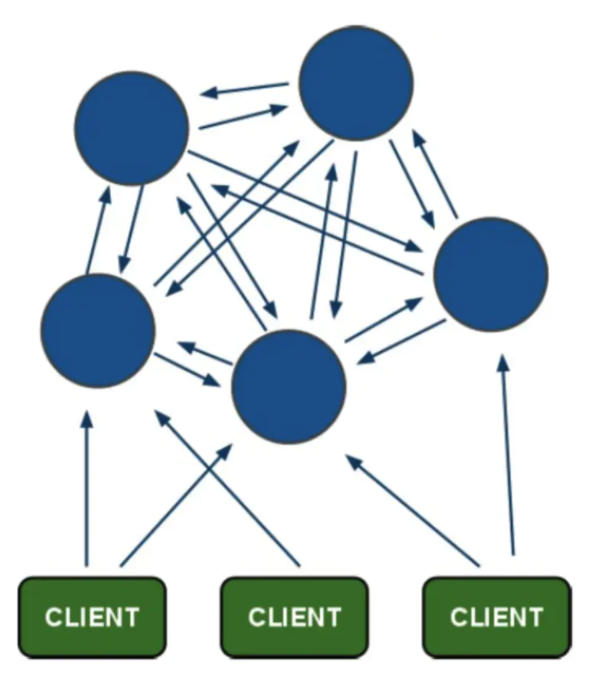
Redis-Cluster迁移
方法一: 集群节点增删实现
方法1: 集群节点增删实现 把Redis新节点逐台加入当前集群,变成一个大的Redis集群。 然后进行手动failover,最后下线原主库节点。
说明: 要注意的是在需要故障转移的slave节点上执行,否则报错:(error) ERR You should send CLUSTER FAILOVER to a slave;
#redis-cli -h 192.124.64.212 -p 6301 -a pwd123 -c cluster nodes |grep master |sort -k 9n
#redis-cli -h 192.124.64.212 -p 6301 -a pwd123 -c cluster nodes |grep slave |sort -k 9n
#/usr/local/redis-5.0.6/bin/redis-cli --cluster info 192.124.64.212:6301 -a pwd123
#/usr/local/redis-5.0.6/bin/redis-cli --cluster check 192.124.64.212:6301 -a pwd123
redis-cli -h 新加的从库节点 -p 6301 -a pwd123 cluster failover
方法二: 迁移工具实现
若场景是希望原Redis集群暂时保留,即如下图,同时有两个独立的集群,则就无法使用迁移方法1。(如双机房Redis高可用场景)
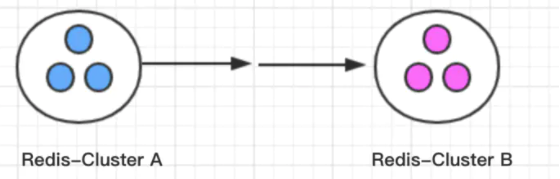
Redis-Cluster是由多个redis实例组成的集群,无法直接使用slave of 命令把redis-cluster-B变成redis-cluster-A的从库。
redis-cluster迁移:
- 若是业务可以中断,可停止Cluster-A 写操作,把Redis rdb/aof文件传输到新的Cluster-B机群再重启服务。
- 使用某些redis数据迁移工具来迁移redis-cluster数据。(推荐此方法)
迁移工具
常见迁移工具
[
](https://github.com/alibaba/RedisShake)
- redis-dump: redis-dump 是一个将redis数据导入/导出为json格式数据的小工具。
- redis-port : 最初是 codis 项目相关工具,支持实时同步 redis 数据到 codis/redis等中。
- redis-migrate-tool: 是唯品会开源的redis数据迁移工具,可用于异构redis集群间的数据在线迁移。
- redis-shake : 是阿里云的redis数据同步的工具。支持redis主从->redis-cluster,cluster-cluster等多种redis架构的数据同步。
redis-dump
redis-dump可以方便的把一个redis实例的数据导出来(不是redis-cluster的数据)。redis-dump命令需要用到keys命令,若是rename此命令,则redis-dump将会出错。
#把192.124.64.212:6379 数据导到192.124.64.214:6380。
$redis-dump -u :pwd123@192.124.64.212:6379 | redis-load -u :pwd123@192.124.64.214:6380
#
$redis-dump -u :pwd123@192.124.64.212:6379
{"db":0,"key":"foo","ttl":-1,"type":"string","value":"bar","size":3}
#keys不可用将出错
$redis-dump -u :pwd123@192.124.64.212:6379>redis_6379.json
ERR unknown command 'keys'
redis-port/redis-migrate-tool/ redis-shake : 这几个工具功能相近,可支持redis的实时数据同步。本文以redis-shake来重点介绍。
redis-shake
redis-shake是阿里云自研的开源工具,支持对Redis数据进行解析(decode)、恢复(restore)、备份(dump)、同步(sync/rump)。在sync模式下,redis-shake使用SYNC或PSYNC命令将数据从源端Redis同步到目的端Redis,支持全量数据同步和增量数据同步,增量同步在全量同步完成后自动开始。
功能介绍
- 备份dump:将源redis的全量数据通过RDB文件备份起来。
- 解析decode:对RDB文件进行读取,并以json格式解析存储。
- 恢复restore:将RDB文件恢复到目的redis数据库。
- 同步sync: 支持源redis和目的redis的数据同步,支持全量和增量数据的迁移。支持单节点、主从版、集群版之间的互相同步。需要注意的是,如果源端是集群版,可以启动一个RedisShake,从不同的db结点进行拉取,同时源端不能开启move slot功能;对于目的端,如果是集群版,写入可以是1个或者多个db结点。
- 同步rump:支持源redis和目的redis的数据同步,仅支持全量的迁移。采用scan和restore命令进行迁移,支持不同云厂商不同redis版本的迁移。
redis-shake迁移原理
redis-shake的基本原理就是模拟一个从节点加入源redis集群,首先进行全量拉取并回放,然后进行增量的拉取(通过psync命令)。如下图所示:

如果源端是集群模式,只需要启动一个redis-shake进行拉取,同时不能开启源端的move slot操作。如果目的端是集群模式,可以写入到一个结点,然后再进行slot的迁移,当然也可以多对多写入。
环境准备
本文进行Redis集群迁移测试,为了节约机器,目标集群复用了源Redis机器,只是修改了端口。 本文计划测试cluster_A---> cluster_B,及Cluster_A---> Redis_C主从的两种迁移场景;
机器规划
redis-shake机器
| 角色 | 版本 | IP |
|---|---|---|
| redis-shake | redis-shake-1.6.24 | 192.124.64.212 |
源Redis集群A:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6301,7301 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6301,7301 |
| node-3 | redis-5.0.6 | 192.124.64.214 | 6301,7301 |
目标Redis集群B:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6302,7302 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6302,7302 |
| node-3 | redis-5.0.6 | 192.124.64.214 | 6302,7302 |
源Redis主从C:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-3.2.9 | 192.168.0.108 | 6303 |
| node-2 | redis-3.2.9 | 192.168.0.111 | 6303 |
目标Redis主从C:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-3.2.9 | 192.168.0.100 | 6303 |
| node-2 | redis-3.2.9 | 192.168.0.107 | 6303 |
Redis主从迁移实施
Redis部署(3.2.9)
源Redis主从:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-3.2.9 | 192.168.0.108 | 6303 |
| node-2 | redis-3.2.9 | 192.168.0.111 | 6303 |
目标Redis主从C:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-3.2.9 | 192.168.0.100 | 6303 |
| node-2 | redis-3.2.9 | 192.168.0.107 | 6303 |
部署redis(两个主从都做)
yum -y install gcc gcc-c++
wget http://download.redis.io/releases/redis-3.2.9.tar.gz
tar zxf redis-3.2.9.tar.gz
cd redis-3.2.9/deps/
make geohash-int hiredis jemalloc linenoise lua
cd ..
make && make install
cd utils/
./install_server.sh
chkconfig --add redis_6379
chkconfig redis_6379 on
/*
./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379] 6379
Please select the redis config file name [/etc/redis/6379.conf]
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379]
Selected default - /var/lib/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server]
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!
*/
[root@redis utils]# /etc/init.d/redis_6379 status
Redis is running (7887)
修改Redis-Master的redis.conf配置文件
#[root@redis-master redis]# mkdir /usr/local/redis/backup -p
[root@redis-master redis]# vim /etc/redis/6379.conf
daemonize yes
pidfile /var/run/redis-16379.pid
logfile /var/log/redis-16379.log
port 6379
bind 0.0.0.0
timeout 300
databases 16
dbfilename dump-6379.db
dir /usr/local/redis/backup
masterauth 123456
requirepass 123456
# 重启服务使服务生效
[root@redis-master redis]# /etc/init.d/redis_6379 restart
修改Redis-Slave的redis.conf配置文件
[root@redis-slave redis]# mkdir /usr/local/redis/backup -p
[root@redis-slave redis]# vim /etc/redis/6379.conf
daemonize yes
pidfile /var/run/redis-26379.pid
logfile /var/log/redis-26379.log
port 26379
bind 0.0.0.0
timeout 300
databases 16
dbfilename dump-6379.db
dir /usr/local/redis/backup
masterauth 123456
requirepass 123456
slaveof 192.168.0.108 6379
# 重启服务使服务生效
[root@redis-master redis]# redis-server ./redis.conf
验证主从复制是否生效
# 主节点
[root@redis-master redis]# redis-cli -h 127.0.0.1 -p 6379 -a 123456
127.0.0.1:16379> set zhou youmen
OK
# 从节点
[root@redis-slave redis]# redis-cli -h 127.0.0.1 -p 6379 -a 123456
127.0.0.1:6379> get zhou
"youmen"
127.0.0.1:6379> INFO replication
# Replication
role:slave
master_host:192.168.0.108
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:129
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
至此主从复制OK了
Redis迁移
模拟数据
cat input_key.sh
#!/bin/bash
for i in $(seq 1 1000)
do
redis-cli -h 127.0.0.1 -p 6379 -a 123456 set k_${i} v_${i} && echo "set k_${i} is ok"
done
sh input_key.sh
aof同步数据迁移
若是原来的redis可以暂停写操作,则咱们用aof来同步数据也很方便;
#旧redis导出aof文件
[root@redis-master ~]# redis-cli -h 192.168.0.108 -p 6379 -a 123456 config set appendonly yes
OK
[root@redis-master ~]# redis-cli -h 192.168.0.108 -p 6379 -a 123456 config get appendonly
1) "appendonly"
2) "yes"
scp /usr/local/redis/backup/appendonly.aof 192.168.0.107:
#aof文件导入到新的redis
[root@nginx ~]# redis-cli -h 192.168.0.107 -p 6379 -a 123456 --pipe < appendonly.aof
#导入完成后,关闭原redis AOF
[root@redis-master ~]# redis-cli -h 192.168.0.107 -p 6379 -a 123456 config set appendonly no
Redis集群迁移实施
Redis集群部署
https://www.cnblogs.com/you-men/p/12861215.html
5.1 redis-shark安装
软件下载地址: github.com/alibaba/Red… 。软件解压缩后就可使用。
安装:
#安装redis-shake
$wget 'https://github.com/alibaba/RedisShake/releases/download/release-v1.6.24-20191220/redis-shake-1.6.24.tar.gz' .
$tar -zxvf redis-shake-1.6.24.tar.gz
$mv redis-shake-1.6.24 /usr/local/redis-shake
#环境变量
$echo 'export PATH=$PATH:/usr/local/redis-shake'>>/etc/profile
$source /etc/profile
#查看版本
$redis-shake.linux --version
#目录中文件信息
$tree /usr/local/redis-shake
.
├── ChangeLog
├── redis-shake.conf
├── redis-shake.darwin
├── redis-shake.linux
├── redis-shake.windows
├── start.sh
└── stop.sh
启动:
#启动程序, xxx为sync, restore, dump, decode, rump之一
$redis-shake.linux -conf=redis-shake.conf -type=xxx
redis-shake --conf={配置文件地址} --type={模式:sync/dump等} 模式需要与配置文件中的source target对应。
模式为sync, restore, dump, decode, rump其中之一,全量+增量同步请选择sync。
mac下请使用redis-shake.darwin,windows请用redis-shake.windows
redis-shake模式介绍:
- dump模式 : 将云数据库Redis版实例中的数据备份到RDB文件中。
- decode模式: decode实现对RDB文件进行读取,并以json格式解析存储。
- restore模式: restore模式可将RDB文件恢复到目的redis数据库。
- sync模式: sync模式将某Redis数据迁移至其它Redis集群。
- rump模式: rump模式采用scan和restore命令进行迁移,支持不同云厂商不同redis版本的迁移。
5.2 redis-shake配置
- 如何进行配置 https://github.com/alibaba/RedisShake/wiki/
- redis-shake迁移 https://help.aliyun.com/document_detail/111066.html
5.2.1 sync模式参数
在sync模式下,redis-shake使用SYNC或PSYNC命令将数据从源端Redis同步到目的端Redis,支持全量数据同步和增量数据同步,增量同步在全量同步完成后自动开始。
sync模式参数说明:
| 参数 | 说明 | 示例 |
|---|---|---|
| source.type | 支持standalone,sentinel,cluster和proxy | cluster |
| source.address | 源Redis的连接地址与服务端口。 | xxx.xxx.1.10:6379 |
| source.password_raw | 源Redis的连接密码。 | SourcePass233 |
| target.address | 目的Redis的连接地址与服务端口。 | xx.redis.rds.aliyuncs.com:6379 |
| target.password_raw | 目的Redis的连接密码。 | TargetPass233 |
| rewrite | 如果目的Redis有相同的key,是否覆盖,可选值:true(覆盖);false(不覆盖)。 | 默认为true,为false且存在数据冲突则会出现异常提示。 |
| target.db | 待迁移的数据在目的Redis中的逻辑数据库名。当该值设置为-1时,源Redis和目的Redis中的名称相同 | -1 |
| parallel | RDB文件同步中使用的并发线程数,用于提高同步性能。 | 最小值为1,推荐值为64。 |
5.3 执行迁移
分别演示下cluster_A---> cluster_B,及Cluster_A---> Redis_C主从的两种场景。
5.3.1 Redis-Cluster迁移到Redis-Cluster
源Redis集群A:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6301,7301 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6301,7301 |
| node-3 | redis-5.0.6 | 192.124.64.214 | 6301,7301 |
目标Redis集群B:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6302,7302 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6302,7302 |
| node-3 | redis-5.0.6 | 192.124.64.214 | 6302,7302 |
1)检查源/目标Redis信息
获取源端集群信息:echo 'cluster nodes' | redis-cli -c -h 192.124.64.212 -p 6301 -a pwd123 | egrep master 源端集群master: 192.124.64.212:6301;192.124.64.213:6301;192.124.64.214:6301获取目标端集群信息:echo 'cluster nodes' | redis-cli -c -h 192.124.64.212 -p 6302 -a pwd123 | egrep master 目标集群master: 192.124.64.212:6302;192.124.64.213:6302; 192.124.64.214:6302
2)配置RedisShake
修改配置文件,重点是修改source.type,source.address,source.password_raw; target.type,target.address,target.password_raw。
which redis-shake/usr/local/redis-shake/redis-shake $cd /usr/local/redis-shake/$vim /usr/local/redis-shake/redis-shake-cluster.conf#配置如下# id唯一标识一次同步进程id=redis-shake-clusterlog.file = /var/log/redis-shake.loglog.level = info# 端口配置,默认system_profile = 9310http_profile = 9320 # source相关配置[cluster|standalone]source.type = cluster#source.addres,需要配置源端的所有集群中db节点列表以及目的端集群所有db节点列表source.address = 192.124.64.212:6301;192.124.64.213:6301;192.124.64.214:6301source.password_raw = pwd123source.auth_type = auth # Des相关配置target.type= clustertarget.address = 192.124.64.212:6302;192.124.64.213:6302;192.124.64.214:6302target.password_raw = pwd123target.auth_type = auth# all the data will be written into this db. < 0 means disable.target.db = -1# 过滤执行类型的key# filter.key = QH;cn# 在rdb全量同步阶段,如果目标redis已经存在对应的key时是否覆盖,如果为false就抛异常rewrite = true# 是否做metric统计,建议设置为true,如果设置为false,/metric中的部分参数的值就一直是0metric = true
3)执行迁移 执行迁移,开启数据同步迁移。 若是数据量特别大,需要在压力低峰时,要后台执行迁移。
$redis-shake.linux -type sync -conf ./redis-shake-cluster.conf 复制代码
4)监控进度
- restful监控指标 github.com/alibaba/Red…
查看日志:
查看同步日志确认同步状态,当出现sync rdb done时,全量同步已经完成,同步进入增量阶段。若+forward=0,则此时源端没有新的数据写入,同步链路中没有增量数据正在传输,您可以以此为依据选择适当的时机将业务切换到Cluster_B集群。
$tail -f /var/log/redis-shake.log 2020/04/15 20:28:40 [INFO] dbSyncer[2] FlushEvent:IncrSyncStart Id:redis-shake-cluster 2020/04/15 20:28:40 [INFO] dbSyncer[1] total = 178B - 178B [100%] entry=0 2020/04/15 20:28:40 [INFO] dbSyncer[1] sync rdb done 2020/04/15 20:28:40 [INFO] dbSyncer[1] FlushEvent:IncrSyncStart Id:redis-shake-cluster 2020/04/15 20:28:41 [INFO] dbSyncer[2] sync: +forwardCommands=0 +filterCommands=0 +writeBytes=0 2020/04/15 20:28:41 [INFO] dbSyncer[0] sync: +forwardCommands=0 +filterCommands=0 +writeBytes=0
监控状态:
$curl 127.0.0.1:9320/metric | python -m json.tool
5)检查验证 可以用scan命令来简单抽查数据同步的结果。也可以用redis-full-check进行数据校验,确保两端数据一致,详细步骤请参见校验迁移后的数据。
测试写入数据:
#源Redis,写入测试数据$redis-cli -c -h 192.124.64.212 -p 6301 -a pwd123 192.124.64.212:6301> set foo bar192.124.64.214:6301> set foo1 bar1192.124.64.214:6301> scan 0 match '*' count 1000 1) "0"2) 1) "foo" 2) "foo1"#目标Redis,用scan检查$redis-cli -c -h 192.124.64.212 -p 6302 -a pwd123 scan 0 match '*' count 1000 1) "0"2) 1) "foo" 2) "foo1"
说明: scan命令只能对某一个redis节点scan,不支持对cluster scan。
检查keys数:
#源Redis/usr/local/redis-5.0.6/bin/redis-cli --cluster info 192.124.64.212:6301 -a pwd123 192.124.64.212:6301 (5e19efdd...) -> 2 keys | 6720 slots | 1 slaves.192.124.64.213:6301 (8021b063...) -> 0 keys | 5462 slots | 1 slaves.192.124.64.214:6301 (7f411012...) -> 2 keys | 4202 slots | 1 slaves.[OK] 4 keys in 3 masters.#目标Redis/redis-cli -h 192.124.64.212 -p 6303 -a pwd123 scan 0 match '*' count 1000 1) "0"2) 1) "foo" 2) "foo1"
可以看到源及目标redis集群,keys的数目是一致的。
Redis-Cluster迁移到Redis主从
源Redis集群A:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6301,7301 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6301,7301 |
| node-3 | redis-5.0.6 | 192.124.64.214 | 6301,7301 |
目标Redis主从C:
| 角色 | 版本 | IP | port |
|---|---|---|---|
| node-1 | redis-5.0.6 | 192.124.64.212 | 6303 |
| node-2 | redis-5.0.6 | 192.124.64.213 | 6303 |
1)配置RedisShake
修改配置文件,重点是修改source.type,source.address,source.password_raw; target.type,target.address,target.password_raw。
$vim ./redis-shake-standalone.conf source.type = cluster#source.addres,需要配置源端的所有集群中db节点列表以及目的端集群所有db节点列表source.address = 192.124.64.212:6301;192.124.64.213:6301;192.124.64.214:6301source.password_raw = pwd123source.auth_type = auth# Des相关配置target.type= standalonetarget.address = 192.124.64.212:6303;192.124.64.213:6303target.password_raw = pwd123
2)执行迁移
执行迁移,开启数据同步迁移。 若是数据量特别大,需要在压力低峰时,要后台执行迁移。
$redis-shake.linux -type sync -conf ./redis-shake-standalone.conf
3)检查验证
检查日志:
$tail -f /var/log/redis-shake.log 2020/04/15 21:10:23 [INFO] dbSyncer[2] sync rdb done 2020/04/15 21:10:23 [INFO] dbSyncer[2] FlushEvent:IncrSyncStart Id:redis-shake-cluster 2020/04/15 21:10:23 [WARN] dbSyncer[2] GetFakeSlaveOffset not enable when psync == false 2020/04/15 21:10:24 [INFO] dbSyncer[1] sync: +forwardCommands=0 +filterCommands=0 +writeBytes=0
检查数据:
#源Redis,写入数据$redis-cli -c -h 192.124.64.212 -p 6301 -a pwd123 set hello hi$redis-cli -c -h 192.124.64.212 -p 6301 -a pwd123 set foo barbar$redis-cli -c -h 192.124.64.212 -p 6301 -a pwd123 set foo1 bar1bar1#$redis-cli --cluster info 192.124.64.212:6301 -a pwd123 192.124.64.212:6301 (5e19efdd...) -> 1 keys | 6720 slots | 1 slaves.192.124.64.213:6301 (8021b063...) -> 0 keys | 5462 slots | 1 slaves.192.124.64.214:6301 (7f411012...) -> 2 keys | 4202 slots | 1 slaves.[OK] 3 keys in 3 masters.#目标Redis,查看数据$redis-cli -h 192.124.64.212 -p 6303 -a pwd123 scan 0 match '*' count 10001) "0"2) 1) "hello" 2) "foo" 3) "foo1"
可以看到源及目标redis集群,keys的数目是一致的。
Redis主从,集群部署及迁移的更多相关文章
- 02.Redis主从集群的Sentinel配置
1.集群环境 1.Linux服务器列表 使用4台CentOS Linux服务器搭建环境,其IP地址如下: 192.168.110.100 192.168.110.101 192.168.110.102 ...
- centos6下redis cluster集群部署过程
一般来说,redis主从和mysql主从目的差不多,但redis主从配置很简单,主要在从节点配置文件指定主节点ip和端口,比如:slaveof 192.168.10.10 6379,然后启动主从,主从 ...
- 一、全新安装搭建redis主从集群
前言· 这里分为三篇文章来写我是如何重新搭建redis主从集群和哨兵集群的及原本服务器上有单redis如何通过升级脚本来实现redis集群.(redis结构:主-从(备)-从(备)) 至于为什么要搭建 ...
- docker搭建redis主从集群和sentinel哨兵集群,springboot客户端连接
花了两天搭建redis主从集群和sentinel哨兵集群,讲一下springboot客户端连接测试情况 redis主从集群 从网上查看说是有两种方式:一种是指定配置文件,一种是不指定配置文件 引用地址 ...
- 5000+字硬核干货!Redis 分布式集群部署实战
原理: Redis集群采用一致性哈希槽的方式将集群中每个主节点都分配一定的哈希槽,对写入的数据进行哈希后分配到某个主节点进行存储. 集群使用公式(CRC16 key)& 16384计算键key ...
- redis —主从&&集群(CLUSTER)
REDIS主从配置 为了节省资源,本实验在一台机器进行.即,在一台机器上启动两个端口,模拟两台机器. 机器准备: [root@adailinux ~]# cp /etc/redis.conf /etc ...
- Redis主从集群及哨兵模式
本次实验环境准备用一台服务器模拟3台redis服务器,1主2从 主从集群搭建 第一步:安装Redis 安装Redis,参考前面安装Redis文章,保证单机使用没有问题. 第二步:配置服务器文件 定位到 ...
- Redis cluster 集群部署和配置
目录 一.集群简介 cluster介绍 cluster原理 cluster特点 应用场景 二.集群部署 环境介绍 节点部署 启动集群 三.集群测试 一.集群简介 cluster介绍 redis clu ...
- redis cluster集群部署
上一篇http://www.cnblogs.com/qinyujie/p/9029153.html,主要讲解了 redis cluster 集群架构 的优势.redis cluster 和 redis ...
随机推荐
- 下载: www.bitmover.com/lmbench,最新版本3.0-a9
软件说明: lmbench是个用于评价系统综合性能的多平台开源benchmark,能够测试包括文档读写.内存操作.进程创建销毁开销.网络等性能,测试方法简单.Lmbench是个多平台软件,因此能够对同 ...
- BUUCTF(八)[极客大挑战 2019]LoveSQL
BUUCTF 1.打开题目 注入方法可参考NewsCenter 2.测试注入点 username: 1'or'1=1 password: 1'or'1=1 登录成功,说明存在注入漏洞. 下面测试位点个 ...
- Samba服务配置及配置文件说明
前言 1.配置Samba服务为什么要关闭防火墙(firewalld)和Selinux? 在linux操作系统中默认开启了防火墙,Selinux也处于启动状态,一般状态为enforing:所以,在我们搭 ...
- 2.9高级变量类型操作(列表 * 元组 * 字典 * 字符串)_内置函数_切片_运算符_for循环
高级变量类型 目标 列表 元组 字典 字符串 公共方法 变量高级 知识点回顾 Python 中数据类型可以分为 数字型 和 非数字型 数字型 整型 (int) 浮点型(float) 布尔型(bool) ...
- STM32的三种启动方式
- Oracle中Table函数简单应用实例
说明 表函数可接受查询语句或游标作为输入参数,并可输出多行数据. 该函数可以平行执行,并可持续输出数据流,被称作管道式输出. 应用表函数可将数据转换分阶段处理,并省去中间结果的存储和缓冲表. 优势 1 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- 狂神说redis笔记(四)
十二.Redis主从复制 概念 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器.前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), ...
- JDBC连接MySQL、Oracle和SQL server的配置
什么是JDBC 我们可以将JDBC看作是一组用于用JAVA操作数据库的API,通过这个API接口,可以连接到数据库,并且使用结构化查询语言(SQL)完成对数据库的查找,更新等操作. JDBC连接的流程 ...