大数据学习(02)——HDFS入门
Hadoop模块
提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块。

Common是基础模块,这个是必须用的。剩下常用的就是HDFS和YARN。
MapReduce现在用的比较少了,多数场景下会被Spark取代。
Ozone是一个新组件,对象存储,可以看做是HDFS的升级版。
HDFS组成
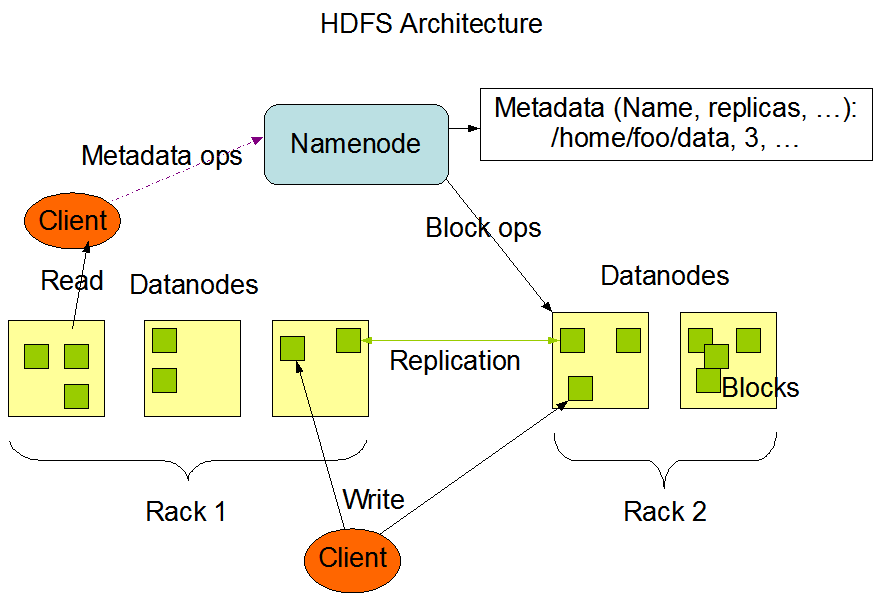
作为Hadoop的分布式文件系统,它的思想远比这个产品本身更重要。它主要包含这么几个组成部分:
- NameNode,主节点,用来保存元数据信息,包括文件属性、文件切成多少个Block、每个Block在哪个DataNode上等等
- DataNode,存储文件的Block
- SecondaryNameNode,为NameNode做记录合并工作,减少NameNode重启加载时间
这个文件系统的命令跟Linux的文件系统命令很相似,只不过前面要加上hdfs dfs前缀。
DataNode
当一个文件上传到HDFS时,根据配置文件里的块大小,它会被切成多个大小相同的Block(最后一块大小是实际值),分散存放在多个DataNode上。
每一个Block根据配置文件里的副本数设置,多个副本也会放在不同的DataNode上。这里有一个概念叫做Block放置策略,它是由NameNode来确定的。
Block多个副本在DataNode之间复制传输的时候,又被切成更小的单元,其中包含数据和校验和。切成小单元的目的,是为了提高Block复制的并发度,让它成为一个流水线作业,减少总体网络传输时间。
如果某一个副本在复制的时候出现问题,这个操作不会由客户端来重试,而是NameNode在检查副本数不足时,自动复制缺少的副本。
NameNode
存放元数据信息:一部分来源于客户端的目录增删、文件上传等操作,另一部分来源于DataNode存放文件Block之后的反馈信息。
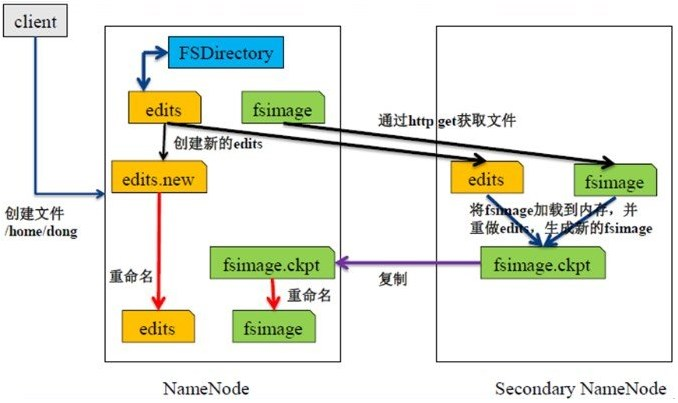
它使用FsImage保存某个时点全量的元数据信息,使用EditLog来记录实时变化的元数据信息,两个文件加起来构成了当前的全量信息。
Block放置策略:如果上传文件的节点是DataNode并且副本数为3,那么Block第一个副本放在该DataNode上,第二个副本放在其他机柜的DataNode上(与第一个节点不在同一个交换机),第三个副本放在与第二个副本相同机柜的DataNode上(同一个交换机网络开销小)
NameNode重启时,它会加载最新的FsImage,并把之后的EditLog重新执行一次,再把内存里恢复的元数据写一个新的FsImage。
SecondaryNameNode
它不是NameNode的备份。
它的工作是从NameNode上拉取FsImage和EditLog,并把两者合并后的新的FsImage推给NameNode。
在两种情况下会触发这个工作:
- 到达固定的时间间隔(比如一个小时)
- EditLog文件大小达到一个值(比如64M)
为什么有HDFS
在HDFS出现之前,已经有那么多分布式文件系统了,为什么还要再造一个轮子呢?
确切地说,HDFS不是一个完整的文件系统,它的出现是为了更好地执行分布式计算,这是以前的文件系统不具备的特性。
为了达到这个目的,HDFS不支持文件的修改。因为一旦某个Block被修改了,它的大小就会发生变化。为了保持每个Block大小一致,必然会引起其后所有Block的重新切分和移动,IO成本太高。
当然,它也可以只修改元素据里Block的偏移量,但这样会导致修改多次之后,Block的大小差异太大,不利于计算任务的平均分配。
大数据学习(02)——HDFS入门的更多相关文章
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- Binding(二):控件关联和代码提升
上节我们讲到,使用Binding,我们可以关联后台代码中的属性,在某些情况下,我们可能需要将两个控件关联起来,借助Binding,我们也可以轻松的实现. 关联控件 设想这样一个场景,界面中有个Chec ...
- DBA入门相关知识介绍
DBA(database administrator):数据库管理员 DBMS(database management system):数据库管理系 ...
- cisco交换机端口从errdisable状态恢复
故障描述 经用户反馈,一台cisco2960x接入交换机的一个端口插网线不通,ip电话也没有poe供电. 排查过程 查看交换机端口状态,发现变成了errdisable: ZH_HQN_SW2960X_ ...
- Kubernetes自动伸缩pod-HPA
在运维中,虽然能预先知道负载何时会飙升,或者如果负载的变化是较长时间内逐渐发生的,手动扩容也是可以接受的,但指望靠人工干预来处理突发而不可预测的流量增长,仍然不够理想. 幸运的是,Kubernetes ...
- Docker搭建zabbix+grafana监控系统
一.准备工作 1.mysql数据库:192.168.1.5 2.nginx服务:192.168.1.10 3.docker服务器:192.168.1.20 4.zabbix客户端若干 二.docker ...
- CentOS-Docker搭建Nacos-v1.1.4(单点)
通用属性配置(v1.1.4) name description option MODE cluster模式/standalone模式 cluster/standalone default cluste ...
- 在使用XStream时没有processAnnotations方法
https://stackoverflow.com/questions/28770909/xstream-processannotations 我遇到这个问题的原因是xstream.jar的版本问题 ...
- 11 shell中内置关键字[[]]:检查条件是否成立
0.[[]] [] (())的对比 1.[[]]支持正则表达式 0.[[]] [] (())的对比 [[ ]] 对数字的比较不友好,所以使用 if 判断条件时,建议用(())来处理整型数字,用[[]] ...
- MySQL索引类型总结和使用技巧以及注意事项 (转)
在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable表: 代码如下: CREATE TABLE mytable( ID INT NOT NULL, us ...
- Java实验项目三——面向对象定义职工类和日期类
Program:按照如下要求设计类: (1)设计一个日期类,用于记录年.月.日,并提供对日期处理的常用方法. (2)设计一个职工类,该职工类至少具有下面的属性:职工号,姓名,性别,生日,工作部门,参加 ...