《现代体系结构上的UNIX系统:内核程序员的对称多处理和缓存技术(修订版)》——2.4 双路组相联高速缓存...
本节书摘来自异步社区《现代体系结构上的UNIX系统:内核程序员的对称多处理和缓存技术(修订版)》一书中的第2章,第2.4节,作者:【美】Curt Schimmel著,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.4 双路组相联高速缓存
双路组相联高速缓存(two-way set associative cache)类似于直接映射高速缓存,不同之处在于散列函数算出的索引指向高速缓存中可能保存数据的一组带有两行的高速缓存。在同一组内,每一行高速缓存都有它自己的标记,这意味着高速缓存可以同时保存经散列算法算出相同索引的两个不同地址的数据。Intel Pentium的片上数据高速缓存就是双路组相联高速缓存。它总共保存有8 KB的数据,每行32字节。这意味着高速缓存中总共有256行(8192字节÷32字节/行),组成128组(256行÷2行/组)。图2-16描绘出了这样的一个高速缓存。
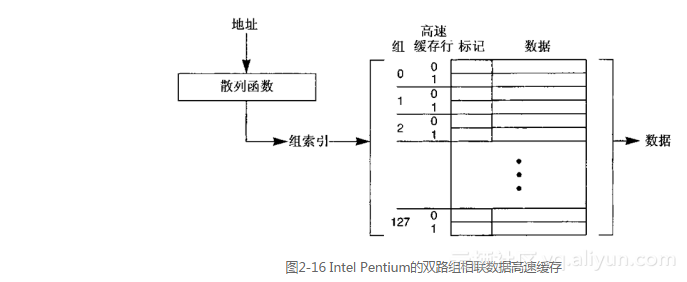
在查找操作期间,散列函数算出的索引指向一组两行可以保存数据的高速缓存。被索引的一组两行高速缓存中的标记和地址同时进行比较,以查看是否命中了两行中的某一行(组内所有行的标记并行比较,从而不会因采用串行比较而降低高速缓存的访问速度)。双路组相联高速缓存的目的是,减少直接映射高速缓存中两个不同地址经散列计算得出相同的索引值时发生的高速缓存颠簸。在双路组相联高速缓存中,这两个不同的地址都保存在高速缓存中。使用这种类型高速缓存的其他处理器还有Intel i860 XR以及80486的外部高速缓存。
现在就很清楚为什么直接映射高速缓存也称为单路组相联高速缓存了。“单路”和“双路”的说法是指每一组中高速缓存行的数量(在高速缓存内所有的组都有相同数量的行)。“相联”一词则是指实际上这一组高速缓存就是以内容编址(content-addressable)的或者说相联(associative)的一个存储器,因为它是通过对照组内高速缓存行的位置(或者地址)来检查标记的内容从而判断出一次命中的。直接映射高速缓存是n路组相联高速缓存的一种退化形式,因为每一个相联组中只有一行高速缓存。
配合双路组相联高速缓存的散列算法和配合直接映射高速缓存的散列算法相同,区别在于前者所需的位数更少,因为对于总量相同的高速缓存存储器来说,双路组相联高速缓存中的组数只有直接映射高速缓存的一半。所以用于图2-16中高速缓存的散列算法就只使用“位<11..5>”来选择组。和以前一样,“位<4..0>”选择高速缓存行内的字节(因为一行有32字节)。
替换策略稍微复杂一些。采用直接映射高速缓存时,在一次缺失操作期间,载入的高速缓存行必须放入将被索引的位置,从而可以在未来的查找操作期间找到。这一行就在散列算法所索引的高速缓存行组内。但是采用双路组相联高速缓存时,现在组内有两行都可以选择用来替换。两行中的任何一行都可以被替换,因为组内的两行在查找操作期间都可以搜索到。在理想情况下,最好替换在最长时间内不会被再次引用的行,因为这能提高高速缓存的整体命中率。遗憾的是,没有办法知道程序未来的引用模式。时间局部性表明,在组内宜采取LRU替换的做法,所以大多数实现(如Intel 80486 外部高速缓存)都利用了这种方法。这种做法不但易于实现,而且效果相当不错。给每个组加上一个额外的位(称为MRU,代表“最近使用”)就可以实现这种方法。每次在一组内出现一次命中时,MRU位就被更新,以反映该组内的哪一行产生了命中。当组内的一行必须被替换的时候,高速缓存首先检查其中是否有一行被标记为无效。如果有,那么就替换那一行。如果两行都是有效的,那么MRU位就指出上次使用的是那一行,于是就选择替换另一行。然后再更新MRU位来指出被替换的行。
双路组相联高速缓存的总结
双路组相联高速缓存通过索引带有两行的一组可能保存数据的高速缓存行,来尝试获得比直接映射高速缓存更好的高速缓存性能。双路组相联高速缓存实现起来要稍微复杂和昂贵一些,因为必须并行比较一组内两行的标记,而且需要一种更复杂的替换策略。
它相对于直接映射高速缓存的优势在于可以减少高速缓存颠簸的现象。如果在一个进程的局部引用中多个地址得出了同一个索引,那么这两个地址会同时被高速缓存,而直接映射高速缓存却一定要替换该行。注意,双路组相联高速缓存的性能绝对不会低于行数相同的直接映射高速缓存。在最差的情况下,如果程序产生地址的顺序是每个地址索引唯一一行,那么双路组相联高速缓存的性能就和直接映射高速缓存一样。另一方面,如果局部引用是由产生冗余索引的多个地址所构成的,那么双路组相联高速缓存的命中率会更高,因为它能同时缓存着产生相同索引的两个不同地址的数据。
《现代体系结构上的UNIX系统:内核程序员的对称多处理和缓存技术(修订版)》——2.4 双路组相联高速缓存...的更多相关文章
- UNIX 系统上的文本操作简介
http://www.oschina.net/question/129540_53561 UNIX 的基本哲学之一就是创建只做一件事并将这一件事做好的程序(或进程).这一哲学要求认真考虑接口以及结合这 ...
- 使用apache daemon让java程序在unix系统上以服务方式运行
通过使用apache_commons_daemon,可以让Java程序在unix系统上以服务器的方式运行. 当然,通过wrapper也是可以达到这样的目的,wrapper还可以指定java应用中用到的 ...
- UNIX系统上的抓包工具tcpdump常用命令说明
tcpdump 介绍 tcpdump采用命令行方式对接口的数据包进行筛选抓取,其丰富特性表现在灵活的表达式上. 不带任何选项的tcpdump,默认会抓取第一个网络接口,且只有将tcpdump进程终止才 ...
- Unix及类Unix系统文本编辑器的介绍
概述 Vim是一个类似于Vi的著名的功能强大.高度可定制的文本编辑器,在Vi的基础上改进和增加了很多特性.VIM是纯粹的自由软件. Vim普遍被推崇为类Vi编辑器中最好的一个,事实上真正的劲敌来自Em ...
- Vi (Unix及Linux系统下标准的编辑器)VIM (Unix及类Unix系统文本编辑器)
Vi是Unix及Linux系统下标准的编辑器.学会它后,您将在Linux的世界里畅行无阻.基本上vi可以分为三种状态,分别是命令模式.插入模式,和底行模式. vi编辑器是所有Unix及Linux系统下 ...
- 《Linux/Unix系统编程手册》读书笔记9(文件属性)
<Linux/Unix系统编程手册>读书笔记 目录 在Linux里,万物皆文件.所以文件系统在Linux系统占有重要的地位.本文主要介绍的是文件的属性,只是稍微提及一下文件系统,日后如果有 ...
- 《Linux/Unix系统编程手册》读书笔记3
<Linux/Unix系统编程手册>读书笔记 目录 第6章 这章讲进程.虚拟内存和环境变量等. 进程是一个可执行程序的实例.一个程序可以创建很多进程. 进程是由内核定义的抽象实体,内核为此 ...
- 学习《Unix/Linux编程实践教程》(1):Unix 系统编程概述
0.目录 1.概念 2.系统资源 3.学习方法 4.从用户的角度来理解 Unix 4.1 登录--运行程序--注销 4.2 目录操作 4.3 文件操作 5.从系统的角度来理解 Unix 5.1 网络桥 ...
- 如何在unix系统中用别的用户运行一个程序?
1.问题的缘由 实际开发系统的时候,经常需要用别的用户运行一个程序.比如,有些系统为保证系统安全,不允许使用root来运行.这里,我们总结了unix系统下如何解决这个问题的一些方法.同时,我们还讨论如 ...
随机推荐
- Halo博客的搭建
今日主题:搭建一个私人博客 好多朋友和我说,能不能弄一个简单的私人博客啊,我说行吧,今天给你们一份福利啦! 搭建一个私人博客,就可以在自己的电脑上写博客了 Halo Halo 是一款现代化的个人独立博 ...
- pyecharts数据可视化模块
目录 安装 柱状图-Bar 饼图-Pie 箱体图-Boxplot 折线图-Line 雷达图-Rader 散点图-scatter 我们都知道python上的一款可视化工具matplotlib,而前些阵子 ...
- android的volley学习
更简单的一种方式是在build.gradle中引入依赖[推荐这种方式] compile 'com.android.volley:volley:1.1.1' StringRequest的用法接下来我们看 ...
- MTK Android 源码目录分析
Android 源码目录分析 Android 4.0 |-- abi (application binary interface:应用二进制接口)|-- art (average retrieval ...
- docker win10 基本指令
一.镜像操作 docker images 本地镜像 docker pull imagename 获取网上获取镜像 docker run 创建docker容器 docker rmi imagename ...
- Ubuntu 安装配置Dosbox
1.安装dosbox sudo apt-get install dosbox 方法一: 2.挂载虚拟空间到dosbox的c盘 在linux终端输入dosbox,进入dosbox后输入 mount c ...
- 数据结构-Python 列表(List)
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现 一.列表常用方法 1.创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可. eg:list1 = ['1', ' ...
- spark error Caused by: java.io.NotSerializableException: org.apache.hadoop.hdfs.DistributedFileSystem
序列化问题多事rdd遍历过程中使用了没有序列化的对象. 1.将未序列化的变量定义到rdd遍历内部.如定义入数据库连接池. 2.常量定义里包含了未序列化对象 ,提出去吧 如下常量要放到main里,不能放 ...
- web.xml中通过contextConfigLocation的读取spring的配置文件
web.xml中通过contextConfigLocation的读取spring的配置文件 博客分类: web.xml contextConfigLocationcontextparamxmlvalu ...
- Codeup 25609 Problem I 习题5-10 分数序列求和
题目描述 有如下分数序列 2/1,3/2,5/3,8/5,13/8,21/13 - 求出次数列的前20项之和. 请将结果的数据类型定义为double类型. 输入 无 输出 小数点后保留6位小数,末尾输 ...