scrapy-redis 更改队列和分布式爬虫
这里分享两个技巧
1.scrapy-redis分布式爬虫
我们知道scrapy-redis的工作原理,就是把原来scrapy自带的queue队列用redis数据库替换,队列都在redis数据库里面了,每次存,取,删,去重,都在redis数据库里进行,那我们如何使用分布式呢,假设机器A有redis数据库,我们在A上把url push到redis里面,然后在机器B上启动scrapy-redis爬虫,在机器B上connect到A,有远程端口可以登入,在爬虫程序里,保存的时候注意启用追加模式,而不是每次保存都删除以前的东西,这样的话,我们可以在B上面多次运行同一个程序。
如图所示,其实连copy都不要,直接另开一个终端,接着运行同样的程序即可。
当然我们也可以在机器C上同样这样运行,所以这就是分布式爬虫。
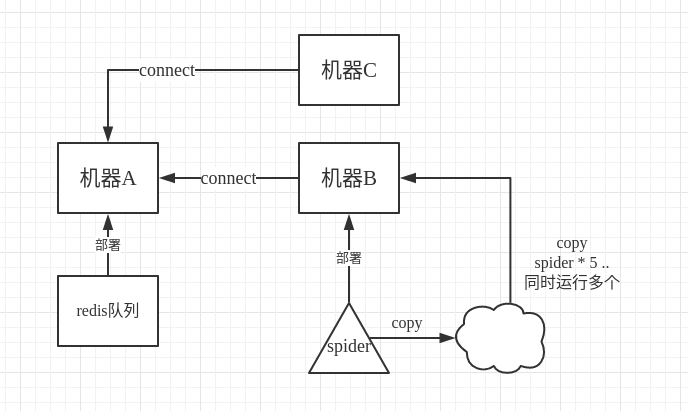
2.队列不存url改为关键字。
我们的redis队列里保存的是url,正常情况下没毛病,当我们的url不是通过extract网页获取的时候,而是通过构造关键字得到的时候,而且关键字还是很大量的情况下,我们就没有必要在redis里面保存url了,而是直接保存关键字,这样省很大 的内存空间,我们把构造url的任务放到即将要request的时候进行。
当然,这里是改了源码的,如果想这么操作的话,建议在虚拟python环境下进行,安全可靠。
site-packages/scrapy_redis/spiders.py
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis. By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding. Parameters
----------
data : bytes
Message from redis. """
data=data.split(',')
if data[1]=='':
a = data[0].strip()
vb = {}
vb['word'] = a
vb['sid'] = 'e13f45a56c8e03b5a2262a6fcab43082'
vb['pq'] = vb['word']
url2 = 'https://sug.so.360.cn/suggest?callback=suggest_so&encodein=utf-8&encodeout=utf-8&format=json&fields=word'
data2 = urllib.urlencode(vb)
geturl2 = url2 + '&' + data2
url = bytes_to_str(geturl2, self.redis_encoding)
return self.make_requests_from_url(url)
而在我们的push程序里,是这样子了:
for res in open(file_name,'r'):
client.lpush('%s:start_urls' % redis_key, res+',360')
这里只改写了scrapy_redis/spiders.py文件里的类RedisMixin的 make_request_from_data 函数,人家作者吧接口单独预留了,让我们能够看得很清楚,还是很厉害的。
另外,scrapy-redis框架储存内容的时候,是以list形式 储存的,client.lpush ,redis关于list的操作详见 Redis 列表
scrapy-redis 更改队列和分布式爬虫的更多相关文章
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- 基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置 1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些p ...
- scrapy分布式爬虫scrapy_redis一篇
分布式爬虫原理 首先我们来看一下scrapy的单机架构: 可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页 ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- 基于scrapy-redis的分布式爬虫
一.介绍 1.原生的scrapy框架 原生的scrapy框架是实现不了分布式的,其原因有: 1. 因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 爬虫--Scrapy-CrawlSpider&基于CrawlSpide的分布式爬虫
CrawlSpider 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调par ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- python蒙特卡洛算法模拟赌博模型
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- P2042 [NOI2005]维护数列 && Splay区间操作(四)
到这里 \(A\) 了这题, \(Splay\) 就能算入好门了吧. 今天是个特殊的日子, \(NOI\) 出成绩, 大佬 \(Cu\) 不敢相信这一切这么快, 一下子机房就只剩我和 \(zrs\) ...
- (转) linux下vim和bash配置文件
1.注释版 ~/.vimrc "去掉讨厌的有关vi一致性模式,避免以前版本的一些bug和局限 set nocompatible set autoread " 文件修改之后自动载入 ...
- MyEclipse和Eclipse中jsp、html格式化自动排版问题
一.myeclipse的漂亮排版设置 步骤: 在左侧快捷 “搜索” 框里面输入 html . 点击选中左侧HTML Source . line - width 是设置当前行里面有多少字符时,就换行.这 ...
- What Does “Neurons that Fire Together Wire Together” Mean?
What Does “Neurons that Fire Together Wire Together” Mean? I’ve heard the phrase “neurons that fire ...
- 男女通用的减肥计划 10分钟家庭hiit训练
在大城市的年轻人,一般都会比较忙,晚上下班吃完饭,到家就要8-9点了,再让他们去,有时候真的不太方便. 其实你如果想要,也不一定要,在家里做hiit运动,就可以了. hiit(高强度间歇运动),是目前 ...
- springboot中使用Scheduled定时任务
一:在程序入口类中添加注解@EnableScheduling @SpringBootApplication @EnableScheduling public class DemoApplication ...
- func_get_args()获取参数
php中func_get_args()可以获取多个参数,讲多个参数放在数组里面. <?php function show() { $attr = func_get_args();//获取输入的参 ...
- Hive笔记之数据库操作
创建数据库 hive创建数据库的最简单写法和mysql差不多: create database foo; 仅当名为foo的数据库当前不存在时才创建: create database if not ex ...
- vue dev开发环境跨域和build生产环境跨域问题解决
dev开发时解决请求跨域问题:config-index.js 配置代理dev: { env: require('./dev.env'), port: 8082, assetsSubDirectory: ...