Hadoop之HDFS概述
一、HDFS产生背景及定义
1、HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2、HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二、HDFS优缺点
1、优点
1)高容错性
a、数据自动保存多个副本。它通过增加副本的形式,提高容错性。

b、某个副本丢失以后,它可以自动恢复。

2)适合处理大数据
a、数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
b、文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
2、缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
a、存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
b、小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。
a、一个文件只能有一个写,不允许多个线程同时写;
b、仅支持数据append(追加),不支持文件的随机修改。
三、HDFS架构组成
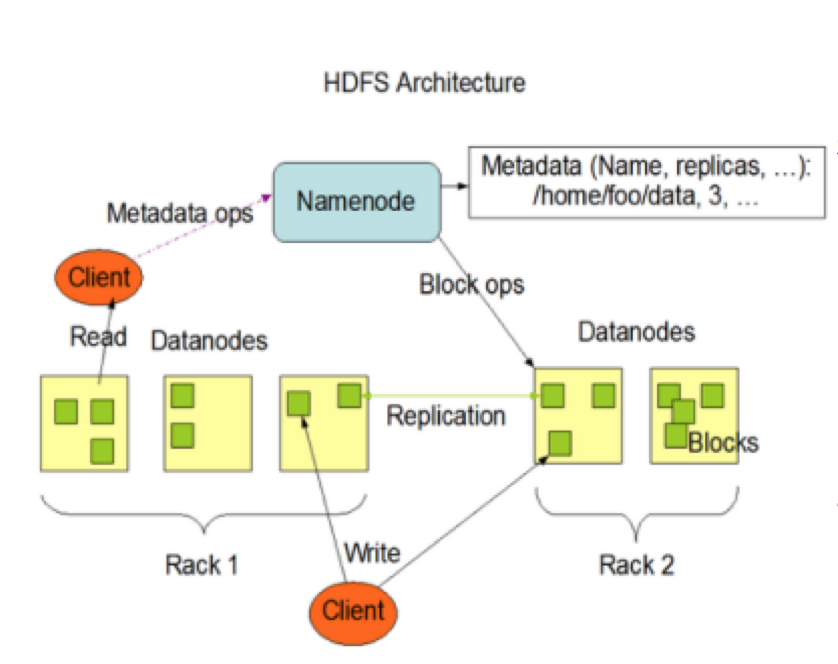
1、NameNode(nn):在整个集群中是Master,它是一个主管、管理者。
1)管理HDFS的名称空间;
2)配置副本策略
3)管理数据块(Block)映射信息
4)处理客户端读写请求
2、DataNode(dn):它是Slave,NameNode下达命令,DataNode执行实际的操作。
1)存储实际的数据块;
2)执行数据块的读/写操作
3、Client:客户端
1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
2)与NameNode交互,获取文件的位置信息
3)与DataNode交互,读取或者写入数据
4)Client提供一些命令来管理HDFS,比如NameNode格式化
5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
4、Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
2)在紧急情况下,可辅助恢复NameNode。
四、HDFS文件块大小
HDFS的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来设定,默认大小在Hadoop2.x版本中是128M,老版本中是64M。

思考:为什么块的大小不能设置太小,也不能设置太大?
1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需时间,导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
Hadoop之HDFS概述的更多相关文章
- Hadoop(5)-HDFS概述
HDFS产生背景 HDFS优缺点 HDFS组成架构 HDFS文件块大小
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。
一.Hadoop环境配置概述 三台虚拟机,操作系统为:Ubuntu 16.04. Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72. ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
- HDFS概述
HDFS概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS产出背景及定义 1>.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- hadoop之hdfs架构详解
本文主要从两个方面对hdfs进行阐述,第一就是hdfs的整个架构以及组成,第二就是hdfs文件的读写流程. 一.HDFS概述 标题中提到hdfs(Hadoop Distribute File Syst ...
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- Hadoop之HDFS介绍
1. 概述 HDFS是一种分布式文件管理系统. HDFS的使用场景: 适合一次写入,多次读出的场景,且不支持文件的修改: 适合用来做数据分析,并不适合用来做网盘应用: 1.2 优缺点 优点: 高容错性 ...
随机推荐
- 项目从.net core 2.1.0升级到.net core 2.2.4,原有项目出错及解决方案
... 1.Controller中的形参命名为query.pager,且里面实体中的参数也有Query.Pager参数时,Query.Pager 就会无数据. 解决方案: 形参query.pager ...
- 打开word出现setup error,怎么解决?
方法1:打开"C:\Program Files\Common Files\Microsoft Shared\OFFICE12\Office Setup Controller" 文件 ...
- 如何共享联盟cookie
接上一篇阿里妈妈账号登录状态如何长时间保存 既然我们获取到了cookie, 如果有多个程序都要使用到联盟帐号的时候, 如果不共享cookie, 那么每个程序都需要登录一次, 真的很浪费资源. 如何共享 ...
- zw-clay字王胶泥体系列
zw-clay字王胶泥体系列 zw-clay字王胶泥体系列,2018新版,也是在2012版本的基础上升级的. 字王胶泥体系列的idea,源自黏土动画电影的制作模式.同样,字王胶泥体系列,也非常适合于动 ...
- 常用MSSQL语句
现在很少用SQL 写东西,但有时真用起来半天想不起来,看来还是有必要记录一下... 新建表: create table [表名] ( [自动编号字段] int IDENTITY (1,1) PRIMA ...
- Machine Learning 第一二周
# ML week 1 2 一.关于machine learning的名词 学习 从无数数据提供的E:experience中找到一个函数使得得到T:task后能够得到P:prediction 监督学习 ...
- 浏览器对象模型BOM总结
BOMwindows对象document对象location对象screen对象 Windows对象 1.窗口操作 移动指定的距离:window.moveBy(10,20); //向右移动10像素,向 ...
- GO : 斐波纳契数列
package main import "fmt" // fibonacci is a function that returns // a function that retur ...
- python 文件重命名
将文件夹中的.jsp重命名为.html import os def rename(path): files = os.listdir(path) for file in files: dir = os ...
- 简单快速部署nexus3私服
本文适用范围:用户规模不大,不需要考虑maven仓库负载均衡的群体. 为何部署nexus3 之前由于懒某些原因,所有开发人员自己定义.m2的settings,大多使用ali提供的maven仓库,但是最 ...