20分钟了解Epoll + 聊天室实战
我们知道,计算机的硬件资源由操作系统管理、调度,我们的应用程序运行在操作系统之上,我们的程序运行需要访问计算机上的资源(如读取文件,接收网络请求),操作系统有内核空间和用户空间之分,所以数据读取,先由内核读取数据到内核缓冲区,然后才会从操作系统的内核空间拷贝到用户空间,这个就是缓存I/O,又被称作标准I/O。
几种常见的IO模式:阻塞I/O、非阻塞I/O、I/O多路复用
1、阻塞I/O
用户进程向内核发起I/O系统调用,内核去准备所需的数据,直到数据都准备好了(需要一段时间)返回给用户进程,在这期间,用户进程一直处于阻塞状态,拿到所需数据,才会继续向下执行。
2、非阻塞I/O
用户进程向内核发起I/O系统调用,内核发现数据还没准备好,立即返回error,用户进程拿到error,可以再次向内核发起请求,直到获取所需数据
3、I/O多路复用
下面详细介绍
一、I/O多路复用
定义:I/O multiplexing allows us to simultaneously monitor multiple file descriptors to see if I/O is possible on any of them.
1、为什么要同时监视多个文件描述符?
传统的阻塞I/O模型可以满足大部分的应用程序使用场景,但有的时候,一些应用程序会同时需要如下特性:
- 检查文件I/O是否已经ready,如果没有,不阻塞,直接返回
- 同时监视多个文件描述符,判断他们中的任意一个的I/O是否已经ready
比如一个web服务器,可能同时打开了几千个连接,每accept一个连接,操作系统产生一个fd(文件描述符),我们的服务器需要监听这些文件描述符,当客户端发来新的数据的时候,我们需要处理请求数据,并给出响应,正常的实现方式可能如下:
connections = [fd1, fd2, fdn];
for (c in connections) {
if (hasNewInput(x)) {
processInput(x);
}
}
这样实现的问题是,我们自己维护着所有的连接,需要主动的去轮寻判断I/O是否已经ready以便进行读写,但事实上并不是所有连接都是活跃状态(建立的连接并没有数据交互),如果我们轮寻的频率很低,那用户获取响应的时间可能长的无法忍受,如果轮寻的频率非常的高,则会浪费CPU的时间。
所以如果可以将主动遍历所有连接,判断每一个的IO状态,改为将这些文件描述符(fd)交给内核去监视,然后当一个或多个文件描述符IO ready的时候,内核来告诉我们,这样效率就大大提高了,因此我们需要IO多路复用。
2、I/O多路复用的几种实现
IO多路复用的实现比较普遍的有两个:select和poll,相比较poll,select更为普遍,最早与BSD socket api一起出现,已被纳入SUSV3标准规范,epoll是只属于Linux的特性,最早的API出现在Linux2.6。
名字叫I/O多路复用,所谓的复用,复用的是同一个进程(线程),也就是在同一个进程中“并发“的完成多个文件描述符的I/O。
2.1、select
select系统调用会阻塞,直到一个或多个文件描述符I/O ready
1>定义:
#include <sys/time.h> /* For portability */
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
2>参数:
- nfds:应设置为大于等于下面三个fds监听的文件描述符的总和
- readfds:需要监听输入事件的文件描述符集合
- writefds:需要监听输出事件的文件描述符集合
- exceptfds:需要被监听是否有异常情况发生的文件描述符集合
- timeout:,阻塞;设置为0,检查一遍文件描述符状态立即返回;设置为NULL或者非0值,会一直阻塞直到:
- 三种fds中有至少一个文件描述符进入ready状态
- 被信号处理中断
- 到达指定的超时时间
3>返回值:
- 返回-1:产生错误
- 返回0:超时返回了,这期间没有文件描述符ready
- 返回正数:返回的数值就是已经ready的文件描述符的数量
4>小示例
#include <stdio.h>
#include <string.h>
#include <sys/time.h>
#include <sys/select.h>
int main(int argc, char *argv[])
{
fd_set readfds, writefds;
int ready, nfds, fd, numRead, j;
struct timeval timeout;
struct timeval *pto;
char buf[10];
//判断参数是否包含短斜线,包含timeout设置NULL
if (strcmp(argv[1], "-") == 0) {
pto = NULL;
} else {
pto = &timeout;
pto.tv_sec = atoi(argv[1]);
pto.tv_usec = 0;
}
//准备监听文件描述符集合
nfds = 0;
//用select 提供的宏初始化fd_set
FD_ZERO(&readfds);
FD_ZERO(&writefds);
for (j = 2; j < argc; j++) {
numRead = sscanf(argv[j], "%d%2[rw]", &fd, buf);
if (numRead != 2) {
printf("error");
return 0;
}
if (fd >= nfds) {
nfds += 1;
}
//判断是监听读还是写
if (strchr(buf, 'r') != NULL) {
FD_SET(fd, &readfds);
}
if (strchr(buf, 'w') != NULL) {
FD_SET(fd, &writefds);
}
}
//调用select函数
ready = select(nfds, &readfds, &writefds, NULL, pto);
if (ready == -1) {
printf("select error\n");
return 0;
}
for (fd = 0; fd < nfds; fd++) {
//打印ready 状态
printf("%d: %s%s\n", fd, FD_ISSET(fd, &readfds) ? "r" : "", FD_ISSET(fd, &writefds) ? "w" : "");
}
return 0;
}
使用文件描述符0 也就是标准输入测试,首先编译一下这段代码gcc -o select select.c
运行./select 10 0r 代表select阻塞最多10秒超时返回,监听标准输入的 读ready状态,会发现程序处于阻塞状态,直到10秒后select返回,打印 0:,也就是没有ready
运行./select - 0r 代表select不会超时直到 标准输入 读ready,程序会一直挂起,直到我们敲回车,返回0:r
运行./select 5 0r 1w 代表最多5秒超时,同时监听标准输入的读状态,和标准输出的写状态,返回0: 1:w
2.2、poll
poll跟select机制基本一样,不同点在于select将监听的文件描述符分开到3个集合中,poll只需一个文件描述符列表
1>定义
#include <poll.h>
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
2>参数
- struct pollfd fds:文件描述符数组
struct pollfd {
int fd; /* File descriptor */
short events; /* Requested events bit mask */
short revents; /* Returned events bit mask */
};
- nfds:fds数组中文件描述符的总数
- timeout:超时时间,传-1阻塞直到有文件描述符ready,传0不阻塞,传>0的值,不管有没有ready的文件描述符,到指定时间超时返回
3>返回值
- 返回-1:有错误产生
- 返回0:没有任何文件描述符ready
- 返回正数:fds元素revents不为0的文件描述的个数
3、poll和select存在哪些问题?
1、每次调用poll()或select(),内核必须检查传过来的所有文件描述符,当文件描述符超过一定数量后,光是检查这一步就已经非常耗时了
2、每次调用poll()或select(),需要从用户态初始化文件描述符的数据结构,然后传递到内核态,在内核态检查IO状态,然以将状态更新到文件描述符数据结构,再返回这个数据结构,数据需不断的在用户态和内核态间拷贝,同样当文件描述符数量很大时,非常耗费CPU时间
3、每次调用完poll()或select(),还要遍历返回的所有文件描述符,判断状态,浪费时间
解决以上问题的关键是:1)不要每次都在内核态和用户态复制这些监听的文件描述符数据 2)只返回IO ready 的文件描述符,不要只标识状态,自己还需要再遍历一遍,因此,Linux给了我们epoll。
二、Epoll
Linux的epoll,也是I/O多路复用的一种实现方式,同样是同时监听多个文件描述符的I/O状态,他有如下几个优势:
- 同时监听的大量文件描述符,效率高于select和epoll
- epoll api同时提供了水平触发通知和边缘触发通知可选,select和epoll只有水平触发通知的方式(两种通知方式后面会讲)
- 对于监听文件描述的具体事件(读、写等,通过bit mask的方式),更为灵活
不像select和poll直接就是系统调用的函数,epoll由3个系统调用函数组成
1、epoll的3个函数
1.1、epoll_create
通过调用epoll_create,创建一个新的epoll内核数据结构实例,返回该实例的文件描述符,然后,调用进程可以使用这个文件描述符向epoll实例添加、删除或修改它想要监视的其他文件描述符。
#include <sys/epoll.h>
int epoll_create(int size);
1.2、epoll_ctl
进程可以通过调用epoll_ctl向epoll实例添加它希望监视的文件描述符,所有这些文件描述符由epoll实例维护在interest list中。当被监视的文件描述符为I/O做好准备时,他们就进入到ready list,ready list是interest list的一个子集
定义:
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
参数:
- epfd:epoll_create返回的文件描述符
- fd:准备加入监视列表(interest list)的文件描述符
- op:要对这个fd做什么操作,有3种
- 添加:EPOLL_CTL_ADD
- 删除:EPOLL_CTL_DEL
- 修改:EPOLL_CTL_MOD
- event:指向epoll_event结构体的指针,结构体中存储着我们实际想要监视fd的哪些事件
epoll_event结构:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events:
事件的成员是位掩码,比如fd是一个socket,我们可能希望监视他,以获取套接字缓冲区上的新数据(使用EPOLLIN),如果希望事件的通知机制使用边缘触发的方式,可以使用EPOLLET。也就是读操作就绪,使用边缘触发的通知方式,需要这样指定events:EPOLLIN | EPOLLET
所有可以指定的events见http://man7.org/linux/man-pages/man2/epoll_ctl.2.html
data:
epoll_data_t 是一个union,可以存储一些数据,当该文件描述符ready的时候,返回给调用监听的进程
typedef union epoll_data {
void *ptr; /* Pointer to user-defined data */
int fd; /* File descriptor */
uint32_t u32; /* 32-bit integer */
uint64_t u64; /* 64-bit integer */
} epoll_data_t;
返回值:返回0执行成功,-1发生错误
1.3、epoll_wait
通过调用epoll_wait,可以获取之前监听的所有事件(interest list)中I/O准备好的事件(ready list)
定义:
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
参数:
- epfd:epoll_create创建epoll实例,返回的文件描述符
- evlist:epoll_event数组,epoll_wait调用会阻塞,直到有文件描述符ready,ready的文件描述符及发生的事件会保存到evlist
- maxevents:evlist数组的长度
- timeout:指定epoll_wait将阻塞多长时间
- 设置为0,非阻塞模式,检查interest list是否有ready的文件描述符后立即返回
- 设置为-1,永远的阻塞直到1>interest list中的一个或多个文件描述符就绪 2>被信号处理程序终断
- 设置为正数:永远的阻塞直到1>interest list中的一个或多个文件描述符就绪 2>被信号处理程序终断 3> 指定的timeout毫秒到了,过期返回
2、深入epoll实例
2.1、先弄清文件描述符和打开文件的关系
为了弄清楚打开文件、文件描述符和epoll之间的关系,我们先看一下Linux操作系统中文件描述符(file descriptors)、打开文件描述(open file description)、和系统级文件inode表之间的关系,如图所示:

内核维护了3个数据结构:
- 每个进程打开的文件描述符(file descriptor table)
- fd flags:文件的flag,就是只读、只写等这些flag
- file ptr:指向文件描述的指针
- 系统中打开文件的描述(open file table)
- file offset:当前文件的offset
- status flags:对应open的flags参数
- inode ptr:指向i-node对象的指针
- 操作系统维护文件系统 (i-node table)
- file type:文件类型
- file locks:一个指向该文件锁相关的列表的指针
- 以及其它各种标识这个文件相关信息
图中可以看出:
- A进程的fd1和fd20这两个文件描述符的file ptr指向同一个同一个open file description(可能执行了dup系统调用复制了文件描述符)
- A进程fd2和B进程的fd2的file ptr也指向同一个open file description(B可能是A调用系统调用fork出来的子进程)
- A进程的fd0和B进程的fd3指向不同的file description,但是指向的是同一个i-node,也就说打开的是同一个文件
2.2、再看epoll_create
当调用了epoll_create,事实上内核在inode-table创建了一个新的inode(也就是epoll实例),以及在file description table中添加一条打开文件描述记录,并且返回给调用者一个文件描述符。
接下来我们就可以使用这个文件描述符,向epoll实例中添加需要监听的文件描述符,当调用epoll_ctl添加一个文件描述符到epoll实例的监听列表(interest list)的时候,事实上真正添加的不是文件描述符,而是其对应的文件描述(file description table)。基于这一点,结合上面文件描述符和打开文件关系的图:
假如进程A调用epoll_create,返回文件描述符fd8。
- 如果B是A fork出来的子进程,那么会继承A所有打开的文件描述符,包括fd8,所以进程A和进程B共享interest list,
- A fork完 B 之后,又打开了一个文件,返回文件描述符fd3,然后调用epoll_ctl添加到interest list中,这时B中并不包括A新打开的文件描述符fd3,但是当fd3有I/O 事件的时候,A或B进程调用epoll_wait,都会收到fd3 IO ready的通知
2.3、epoll为什么性能高于poll和select?
回顾上述poll()和select()存在的问题,可以看到epoll刚好解决了这些问题:
- 相比较poll和select,每次调用循环检查每一个文件描述符I/O状态,时间复杂度O(N),不管N大小,调用一次循环检查一次;epoll得益于监听的是文件描述符下一级的打开文件描述,并且每次调用epoll_wait的时候直接返回ready list就可以了,不需要循环
- 相比较poll和select,每次调用都需要传递监听文件描述符数据到内核,epoll调用epoll_ctl一次性添加到epoll实例,接下来调用epoll_wait不需要再传递这些文件描述符信息过去了
- 相比较poll()和select()返回所有的文件描述,epoll只返回ready的文件描述符
监听不同数量文件描述符,执行100000次状态检查select、poll、epoll性能对比:

3、关于level-trigger 和 edge-trigger
3.1、文件描述符准备就绪通知的两种模型:
- 水平触发:如果可以在不阻塞的情况下执行I/O系统调用,则认为文件描述符已经准备好了,触发通知
- 边缘触发:文件描述符被监控以来,有新的I/O活动(例如 新的输入),触发通知
3.2、不同的通知模型如何影响我们的程序设计?
水平触发
- 确定文件描述符的I/O状态已经ready
- 已经ready,对这个文件描述符执行一些I/O操作(比如读取几个字节数据),然后继续监视它的IO状态
- 仍然有未读取的数据,还会继续触发通知,也就是说不用一次执行完所有的IO操作(比如一次读取缓冲区的全部内容)
边缘触发:
- 只有新的IO事件发生时,才会触发通知
- 直到下次IO事件发生,不会再触发通知
注:对于边缘触发,当触发通知时,我们并不知道有多少IO可用(例如有多少字节可以读),所以一般使用边缘触发通知方式要遵循如下规则:
- 接收到事件通知后,程序应该尽可能多的执行IO(读写),因为仅仅通知这一次,不读取完毕,数据可能就丢失了
- 为了避免IO阻塞,每个被监视的文件描述符应该是非阻塞模式打开的,然后收到事件通知后,重复的执行IO直到返回错误信息
接下来的聊天室的实例,我们使用边缘触发的方式
三、Epoll实战:聊天室
了解完epoll的基础和原理,使用一个精简版的聊天室的小实例来巩固学习。
主要思路:一个服务端,可以接收多个客户端的连接,客户端发送的消息会同步到所有聊天室内的客户端
1、服务端设计与实现
第一步:服务端创建socket服务
第二步:创建epoll实例,将socket服务fd加入interest list
第三步:循环调用epoll_wait看是否有ready的文件描述符,如果有并且是我们的socket服务fd,说明是有新的客户端连接加入,保存客户端fd,并将fd加入interest list;如果非socket 服务fd,说明是客户端有新消息发送至服务端,接收消息然后广播给保存的所有客户端fd
2、客户端设计与实现
第一步:创建socket连接服务端
第二步:创建管道,以便获取客户端输入
第三步:创建epoll实例,并把socket fd和管道fd加入interest list
第四步:fork子进程
第五步:父进程调用epoll_wait获取ready list,如果fd是服务端sockt,则直接打印广播消息;如果fd是管道则为用户输入,读取管道中的消息,发到服务端
3、涉及其他知识点
- socket
- fork
- pipe
- linked list(保存连接的客户端fd)
运行如图:
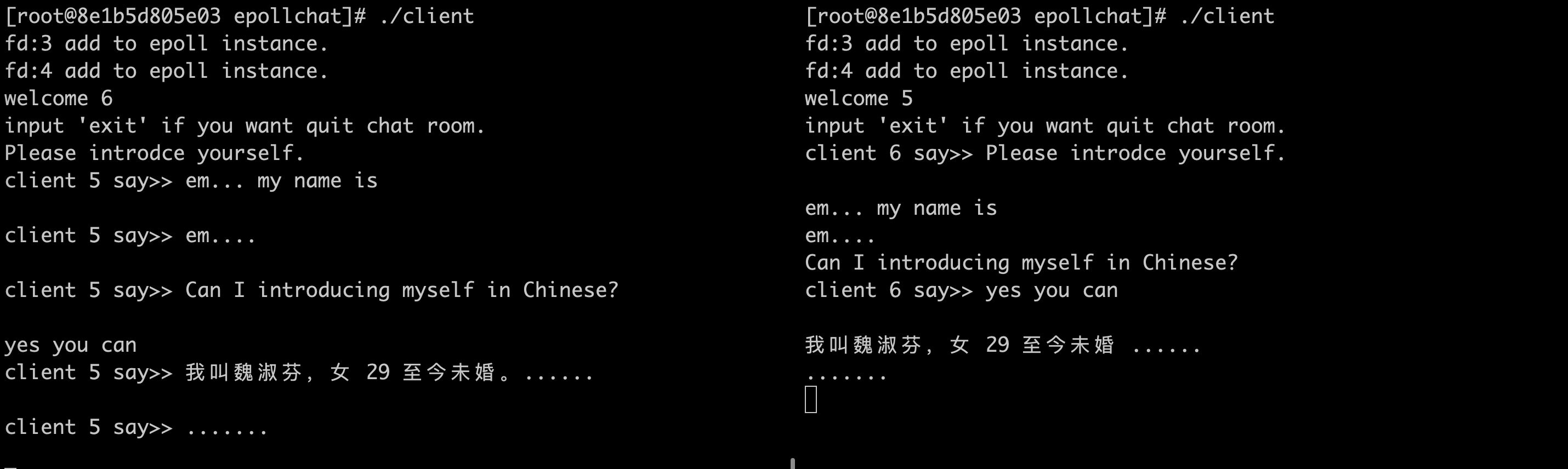
源码放到了Githubhttps://github.com/bigbignerd/epollchat
四、参考文献
1、《The linux programming interface》
2、Medium: The method to epoll's madness
如有表述错误之处,欢迎指正!
原文地址https://www.cnblogs.com/skyfynn/p/10644243.html
20分钟了解Epoll + 聊天室实战的更多相关文章
- ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室 实战系列。开源啦!!!
自此系列博客开写以来,好多同学关心开源问题,之前由于网络问题,发布到Github上老是失败,今天终于在精简了好多无用的文件之后发布上去了. 注意:layim源代码并不开源,由于版权问题,请大家去官网了 ...
- Netty网络聊天(一) 聊天室实战
首发地址; Netty网络聊天(一) 聊天室实战 之前做过一个IM的项目,里面涉及了基本的聊天功能,所以注意这系列的文章不是练习,不含基础和逐步学习的部分,直接开始实战和思想引导,基础部分需要额外的去 ...
- Netty 仿QQ聊天室 (实战二)
Netty 聊天器(百万级流量实战二):仿QQ客户端 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之15 [博客园 总入口 ] 源码IDEA工程获取链接:Java 聊天室 实战 源码 写在 ...
- epoll聊天室的实现
1.服务端 a. 支持多个用户接入,实现聊天室的基本功能 b. 使用epoll机制实现并发,增加效率 2. 客户端 a. 支持用户输入聊天消息 b. 显示其他用户输入的信息 c. 使用fork创建两个 ...
- ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室 实战系列
ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室(零) 前言 http://www.cnblogs.com/panzi/p/5742089.html ASP.NET S ...
- ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室 实战系列(不断更新中)
项目简介 利用ASP.NET SignalR技术与Layim前端im框架实现的一个简单的web聊天室,包括单聊,群聊,加好友,加群,好友搜索,管理,群组管理,好友权限设置等功能.涉及技术: Elast ...
- ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室 实战系列(内容已过期,阅读请慎重)
项目简介 利用ASP.NET SignalR技术与Layim前端im框架实现的一个简单的web聊天室,包括单聊,群聊,加好友,加群,好友搜索,管理,群组管理,好友权限设置等功能.涉及技术: Elast ...
- Netty高级应用及聊天室实战
Netty 高级应用 1. 编解码器 概念:在网络应用中,需要实现某种编解码器.将原始字节数据与自定义消息数据进行相互转换.网络中都是以字节码的形式传输的. 对Netty而言,编解码器由两部分组成:编 ...
- Netty聊天室(2):从0开始实战100w级流量应用
目录 客户端 Client 登录和响应处理 写在前面 客户端的会话管理 客户端的逻辑构成 连接服务器与Session 的创建 Session和 channel 相互绑定 AttributeMap接口的 ...
随机推荐
- Windows 下常见的反调试方法
稍稍总结一下在Crack或Rervese中比较常见的一些反调试方法,实现起来也比较简单,之后有写的Demo源码参考,没有太大的难度. ①最简单也是最基础的,Windows提供的API接口:IsDebu ...
- ASP.NET MVC5多语言切换快速实现方案
功能 实现动态切换语言,Demo做了三种语言库可以切换,包括资源文件的定义,实体对象属性设置,后台代码Controller,IAuthorizationFilter,HtmlHelper的实现,做法比 ...
- 程序员如何描述清楚线上bug
案例 一个管理后台的bug,把操作记录中的操作员姓名,写成了该操作员的id.原因是修改了一个返回操作人姓名的函数,返回了操作人的id.但是还有其他地方也用这个函数,导致其他地方把姓名字段填写成了操作员 ...
- c#中的Unity容器
DIP是依赖倒置原则:一种软件架构设计的原则(抽象概念).依赖于抽象不依赖于细节 IOC即为控制反转(Inversion of Control):传统开发,上端依赖(调用/指定)下端对象,会有依赖,把 ...
- webpack4.0各个击破(2)—— CSS篇
webpack作为前端最火的构建工具,是前端自动化工具链最重要的部分,使用门槛较高.本系列是笔者自己的学习记录,比较基础,希望通过问题 + 解决方式的模式,以前端构建中遇到的具体需求为出发点,学习we ...
- Java开发笔记(五十八)简单接口及其实现
前面介绍了抽象方法及抽象类的用法,看似解决了不确定行为的方法定义,既然叫唤动作允许声明为抽象方法,那么飞翔.游泳也能声明为抽象方法,并且鸡类涵盖的物种不够多,最好把这些行为动作扩展到鸟类这个群体,于是 ...
- Eureka相关知识点
本文讲述的是 Eureka server, 服务提供者.消费者的一些概念和配置说明. Eureka Server 服务注册中心 Eureka的高可用设计 Eureka侧重点是AP,高可用;Eureka ...
- SpringBoot的自动配置原理过程解析
SpringBoot的最大好处就是实现了大部分的自动配置,使得开发者可以更多的关注于业务开发,避免繁琐的业务开发,但是SpringBoot如此好用的 自动注解过程着实让人忍不住的去了解一番,因为本文的 ...
- JPasswordField密码框,JList列表框
[JPasswordField密码框] //导入Java类 import javax.swing.*; import java.awt.*; import java.awt.event.ActionE ...
- 容器化系列 - Zookeeper启动和配置 on Docker
本文简要说明了如何在Docker容器中启动和配置Zookeeper. 1 准备工作 1.1 下载zookeeper镜像 $ docker pull zookeeper:3.4 1.2 单点模式 安装D ...