给 K8s API “做减法”:阿里巴巴云原生应用管理的挑战和实践
作者 | 孙健波(天元) 阿里巴巴技术专家
本文整理自 11 月 21 日社群分享,每月 2 场高质量分享,点击加入社群。
早在 2011 年,阿里巴巴内部便开始了应用容器化,当时最开始是基于 LXC 技术构建容器,然后逐渐切换到 Docker,自研了大规模编排调度系统。到了 2018 年,我们团队依托 K8s 体系开始推进“轻量级容器化”,同时投入了工程力量跟开源社区一起解决了诸多规模与性能问题,从而逐步将过去“类虚拟机”的运维链路和阿里巴巴整体应用基础设施架构升级到了云原生技术栈。
到了 2019 年,Kubernetes 基础设施底盘在阿里巴巴经济体中已经覆盖了阿里巴巴方方面面的业务,规模化的接入了包括核心电商、物流、金融、外卖、搜索、计算、AI 等诸多头部互联网场景。这套技术底盘,也逐步成为了阿里巴巴支撑 618、双11 等互联网级大促的主力军之一。
目前,阿里巴巴与蚂蚁金服内部运行了数十个超大规模的 K8s 集群,其中最大的集群约 1 万个机器节点,而其实这还不是能力上限。每个集群都会服务上万个应用。在阿里云 Kubernetes 服务(ACK)上,我们还维护了上万个用户的 K8s 集群,这个规模和其中的技术挑战在全世界也是首屈一指的。
我们的 Kubernetes 面临的新挑战
在规模和性能等基础设施领域问题逐步解决的同时,规模化铺开 Kubernetes 的过程中,我们逐步发现这套体系里其实还有很多意想不到的挑战。这也是今天分享的主题。
第一个是 K8s 的 API 里其实并没有“应用”的概念
而且,Kubernetes API 的设计把研发、运维还有基础设施关心的事情全都糅杂在一起了。这导致研发觉得 K8s 太复杂,运维觉得 K8s 的能力非常凌乱、零散,不好管理,只有基础设施团队(也就是我们团队)觉得 Kubernetes 比较好用。但是基础设施团队也很难跟研发和运维解释清楚 Kubernetes 的价值到底是什么。
我们来看个实际的例子。

就拿上图中的 replica 为 3 来说,开发人员怎么知道实例数应该配几个呢?如果运维想要改replica,敢不敢改?能不能改?如果 replica 还能理解的话,那像 shareProcessNamespace 这种字段真是灵魂拷问了。 开发人员仅从字面意思知道这个可能跟容器进程共享有关,那么配置了这个应用会有什么影响呢?会不会有安全问题?
在阿里巴巴内部,很多 PaaS 平台只允许开发填 Deployment 的极个别字段。为什么允许填的字段这么少?是平台能力不够强吗?其实不是的,本质原因在于业务开发根本不想理解这众多的字段。
所以这个 PaaS 平台只允许用户填个别字段,其实反倒是帮助业务开发人员避免了这些灵魂拷问。但反过来想,屏蔽掉大量字段真的就解决问题了吗?这种情况下,整个组织的基础设施能力还如何演进?应用开发和应用运维人员的诉求又该怎么传递给基础设施呢?
实际上,归根到底,Kubernetes 是一个 Platform for Platform 项目,它的设计是给基础设施工程师用来构建其他平台用的(比如 PaaS 或者 Serverless),而不是直面研发和运维同学的。从这个角度来看,Kubernetes 的 API,其实可以类比于 Linux Kernel 的 System Call,这跟研发和运维真正要用的东西(Userspace 工具)完全不是一个层次上的。你总不能让本来写 Java Web 的同学每天直接调用着 Linux Kernel System Call,还给你点赞吧?
第二, K8s 实在是太灵活了,插件太多了,各种人员开发的 Controller 和 Operator 也非常多。
这种灵活性,让我们团队开发各种能力很容易,但也使得对于应用运维来说, K8s 的这些能力管理变得非常困难。比如一个环境里的不同运维能力,实际上有可能是冲突的。
我们来看一个例子,基础设施团队最近开发上线了一个新的插件,叫做 CronHPA,一个具体的 Spec 如下所示。

作为基础设施团队,我们觉得这种 K8s 插件很简单, CRD 也很容易理解。就像这个 CronHPA 的功能,从早上六点开始到下午七点钟这个实例最少有 20 个、最多有 25 个,到第二天早上六点钟最少 1 个、最多有 9 个,在每个阶段会根据 CPU 这个指标衡量调整实例数。
然而,就在我们美滋滋的上线这个插件后不久,应用运维同学就开始跟我们抱怨了:
- “这个能力到底该怎么使用呢?它的使用手册在哪里?是看 CRD 还是看文档呢?”
- “我怎么知道这个插件在某个集群里有没有装好呢?”
- “我们运维不小心把 CronHPA 和 HPA 绑定给同一个应用,结果发现这个应用是会抽风的。为什么你们 K8s 非要等到这种冲突发生的时候才报错呢?你们就不能设计个机制自动检查一下这些插件的使用过程有没有发生冲突吗?”其实这个我们后来确实做了,解决方法是给我们的 K8s 加了 20 多个 Admission Hook。
第三,也是阿里巴巴上云之后我们团队特别痛的一个点。
我们需要处理的应用的交付场景,除了公有云以外,还会有专有云、混合云、IoT 等各种复杂的环境。各种各样的云服务在这种复杂场景下,连 API 都是不统一的,这个时候我们就需要专门的交付团队来进行弥补,一个一个的去对接、去交付应用。对他们来说这是一件非常痛苦的事情:“不是说好的 Docker 化了之后就能‘一次打包、随处运行’了吗?”说白了,K8s 现在并没有一个统一的、平台无关的应用描述能力。
阿里巴巴的解决办法
在 2019 年,我们团队开始思考如何通过技术手段解决上述应用管理与交付相关的问题,到现在已经取得了一定的成果。
不过,在讲解阿里巴巴如何解决上述问题的方案之前,有必要先介绍一下我们推进所有这些方案的理论基础。在这里,我们主要遵循的是 CNCF 倡导的“应用交付分层模型”,如下图所示:

这个模型的基础假设是:Kubernetes 本身并不提供完整的应用管理体系。换句话说,基于 K8s 的应用管理体系,不是一个开箱即用的功能,而是需要基础设施团队基于云原生社区和生态自己构建出来的。这里面就需要引入很多开源项目或者能力。
而上面这个模型的一个重要作用,就是能够把这些项目和能力以及它们的协作关系,非常清晰地分类和表达出来。
比如 Helm 就是位于整个应用管理体系的最上面,也就是第 1 层,还有 Kustomize 等各种 YAML 管理工具,CNAB 等打包工具,它们都对应在第 1.5 层;
然后有 Tekton、Flagger 、Kepton 等应用交付项目,包括发布部署的流程,配置管理等,目前比较流行的是基于 GitOps 的管理,通过 git 作为“the source of truth”,一切都面向终态、透明化的管理,也方便对接,对应在第 2 层;
而 Operator 以及 K8s 的各种工作负载组件(Deployment、StatefulSet 等),具体来说就像某个实例挂了这些组件自动拉起来一个弥补上原来所需要三个的实例数,包括一些自愈、扩缩容等能力,对应在第 3 层;
最后一层则是平台层,包括了所有底层的核心功能,负责对工作负载的容器进行管理、封装基础设施能力、对各种不同的工作负载对接底层基础设施提供 API 等。
这些层次之间,通过相互之间的紧密协作,共同构建出一套高效、简洁的应用管理与交付体系。在这些层次当中,目前阿里巴巴在今年 KubeCon 时已经宣布开源了第三层的 OpenKruise项目。最近,我们则正在联合微软等更广泛的生态,和整个社区一起推进第一层“应用定义”相关的工作。
应用定义到底该怎么做?
其实,关于应用定义,无论是开源社区还是在阿里巴巴内部,都已经做了不少尝试,比如一开始我提到 Docker 解决了单机应用交付,它就通过 Docker 镜像把单机应用定义的很好。
围绕 Kubernetes 我们也试过使用 Helm 以及 Application CRD 来定义应用。但是现在的云原生应用,往往会依赖云上的资源,像数据库会依赖 RDS、访问会依赖 SLB,Helm 和 Application CRD 只是单纯地将 K8s 的 API 组合在一起,无法描述我们对云上面资源的依赖,当我们用 CRD 来描述云上资源依赖的时候,它其实是 freestyle 的,没有一个很好的规范和约束,无论是用户、开发、运维还是平台资源提供方都没有一个共识,自然也就无法协作和复用。
另一方面,它们既然是简单的对 K8s API 的组合,那么 K8s API 本身“不面向应用研发和运维设计”的问题就依然存在,这并不符合我们所希望的“应用定义”应该走的方向。此外,像 Application CRD,它虽然是 K8s 社区的项目,但是却明显缺乏社区活跃度,大多数修改都停留在一年前。
试了一圈,我们发现“应用定义”这个东西,在整个云原生社区里其实是缺失的。这也是为什么阿里巴巴内部有很多团队开始尝试设计了自己的“定义应用”。简单地说,这个设计其实就是把应用本身的镜像、启动参数、依赖的云资源等等全部描述起来,分门别类的进行放置,并通过一个模板,最终渲染出一个配置文件,文件里有上千个字段,完整描述了一个应用定义的所有内容。这个配置文件大概长下面这个样子:
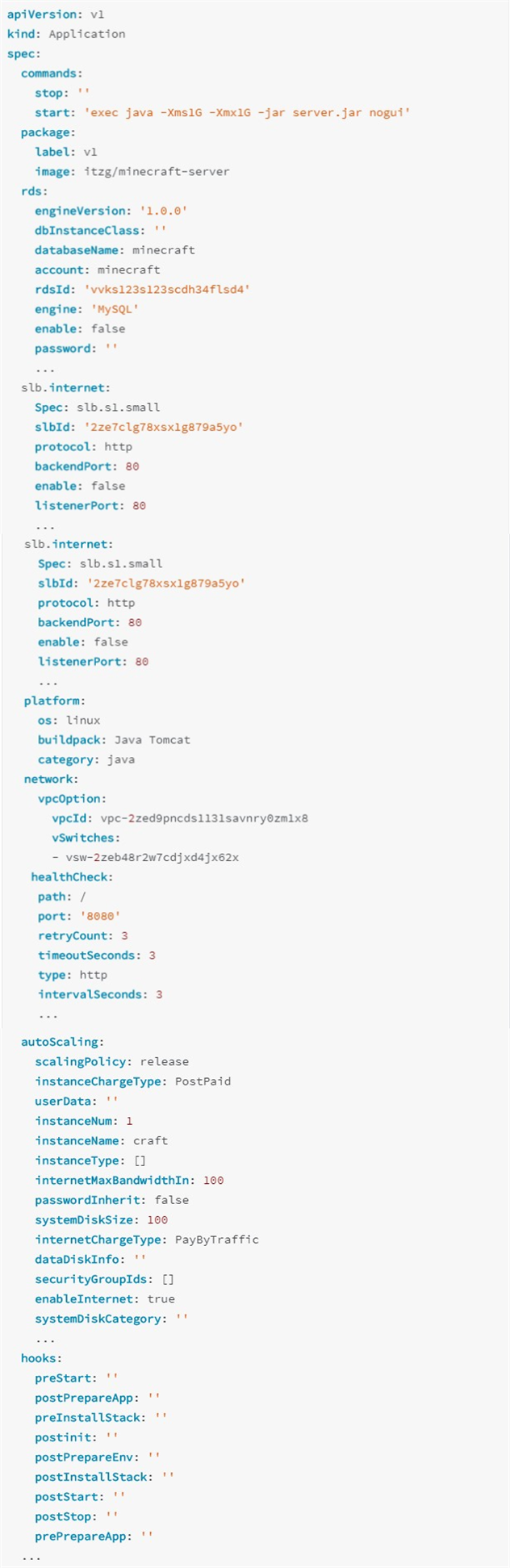
除了基本的 Deployment 描述字段,这种 in-house 应用定义往往还会包含云上资源的声明,比如使用哪种 ECS 套餐、如何续费、使用的是哪种磁盘和规格等等一系列额外的描述。这些资源的定义是一大块,并且上面的例子里我们已经尽量精简了;另一大块就是运维能力的描述,比如自动扩缩容、流量切换、灰度、监控等,涉及到一系列的规则。
然而,你也不难看到,这种定义方式最终所有的配置还是会全部堆叠到一个文件里,这跟 K8s API all-in-one 的问题是一样的,甚至还更严重了。而且,这些应用定义最终也都成为了黑盒,除了对应项目本身可以使用,其他系统基本无法复用,自然就更无法使得多方协作复用了。
吸取了这些教训以后,我们团队决定从另一个方向开始设计一个新的应用定义。
具体来说,相比于其他“应用定义”给 K8s 做加法、做整合的思路,我们认为,真正良好的应用定义,应该给 K8s API 做“减法”。更准确的说,是我们应该通过“做减法”,把开发者真正关心的 API 给暴露出来,把运维、平台关心的 API 给封装起来。
也就是说,既然 K8s API 为了方便基础设施工程师,已经选择把各方的关注点混在了一起。那么,当基础设施工程师想要基于 K8s 来服务更上层应用开发和运维人员时,其实应该考虑把这些关注点重新梳理出来,让应用管理的各个参与方重新拿到属于自己的 API 子集。
所以,我们开始在 K8s API 的基础上增加了一层很薄的抽象,从而把原始的 K8s API 按照现实中的协作逻辑进行合理的拆分和分类,然后分别暴露给研发和运维去使用。这里的原则是:研发拿到的 API 一定是研发视角的、没有任何基础设施的概念在里面;而运维拿到的 API,一定是对 K8s 能力的模块化、声明式的描述。这样,在理想情况下,运维(或者平台)就能够对这些来自双方的 API 对象进行组合,比如:应用 A + Autoscaler X,应用 B + Ingress Y。这样组合完成后的描述对象,其实就可以完整的来描述“应用”这个东西了。
Open Application Model (OAM)
在同社区进行交流和验证中,我们发现:上面的这个思路正好跟当时微软 Brendan Burns (Kubernetes 项目创始人)和 Matt Butcher (Helm 项目创始人)团队的思路不谋而合。所以我们双方在面对面交流了几次之后,很快就决定共建这个项目并把它开源出来,跟整个社区生态一起来推进这件非常具有意义的事情。
今年 10 月 17 号,阿里云小邪和微软云 CTO Mark 共同对外宣布了这个项目的开源,它的官方名字叫做Open Application Model(OAM),同时我们还宣布了 OAM 对应的 K8s 实现——Rudr 项目。
具体来说,在设计 OAM 的时候,我们希望这个应用定义应该解决传统应用定义的三个问题:
第一,不能有运行时锁定。一套应用定义,必须可以不加修改跑到不同运行环境当中,无论是不是基于 K8s,这是解决我们在应用交付时所遇到的问题的关键。这才是真正的“一次定义、随处运行”;
第二,这个应用定义必须要区分使用角色,而不是继续延续 K8s 的 all-in-one API。 我们已经深刻了解到,我们所服务的应用开发人员,实际上很难、也不想关心运维以及 K8s 底层的各种概念,我们不应该让他们原本已经很苦逼的日子变得更糟;
最后一个,这个应用定义必须不是在一个 YAML 里描述所有东西。一旦一个应用定义里把所有信息全部耦合在一起,就会造成应用描述和运维描述被杂糅在一起,从而导致这个定义的复杂度成倍提升,也会让这个定义完全无法复用。我们希望这些不同领域的描述能够分开,然后平台可以自由地组合搭配。
在这个思路下,我们最后设计出来的应用定义主要分为三个大块:
第一部分是应用组件的描述,包括应用组件怎么运行和该组件所依赖的各种资源。这个部分是开发负责编写的;
第二部分是运维能力的描述,比如应用怎么 scale、怎么访问、怎么升级等策略。这个部分是运维负责编写的;
第三部分是把上述描述文件组合在一起的一个配置文件。比如:“ 一个应用有两个组件,组件 A 需要运维能力 X 和能力 Y,组件 B 需要运维能力 X”。所以这个配置文件,其实才是最终的“应用”。这个配置文件,也是运维编写,并且提交给平台去运行的,当然,平台也可以自动生成这个文件。
下面我们通过实例来看下以上三个部分对应的 YAML 文件到底长什么样子?它们究竟怎么玩儿?
备注:如果你想跟我一样实际操作体验这个流程,你只需要在 K8s 集群里装上 Rudr 项目就可以实操了。
第一部分:Component
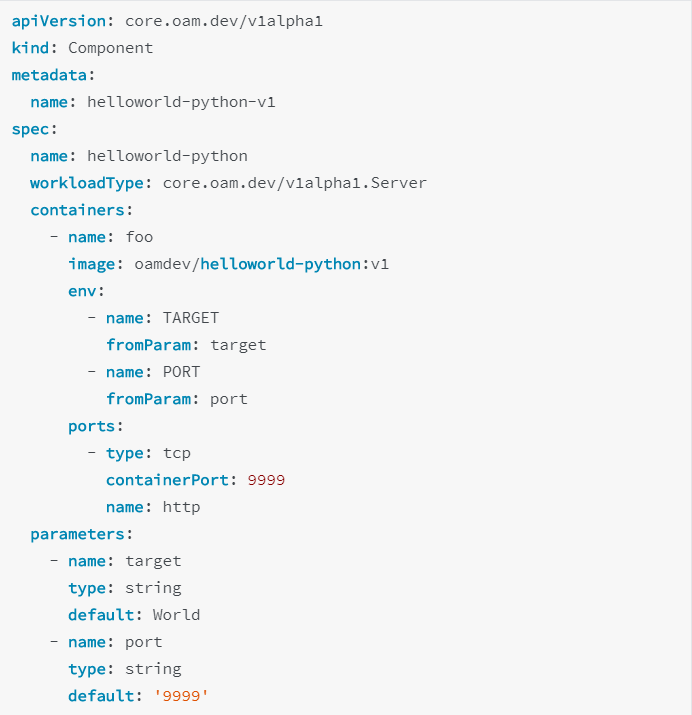
首先我们可以看到,Component 定义的是开发关心的事情,没有任何运维相关的概念。
它的 Spec 主要分为两大块:
第一个参数块是应用描述,包括 WorkloadType 字段,这个字段就是表达应用使用什么 Workload 运行,在我们设计里有六种默认 Workload,分别是 Server、Worker、Job 以及他们对应的单例模式,Workload 也可以扩展。Server 代表这是一个可以自动伸缩的,并且有一个端口可以访问的模式。接下来就是容器的镜像、启动参数之类的,这部分包含完整的 OCI spec。
第二块是 parameters 如何运行可扩展的参数,如环境变量和端口号。这一块参数的特点是:它们虽然是开发定义的,但是都允许运维后续覆盖。这里的关键点是,关注点分离并不等于完全割裂。所以,我们设计了 parameters 列表,其实就是希望开发能告诉运维,哪些参数后续可以被运维人员覆盖掉。这样的话就很好地联动起来了,开发人员可以向运维人员提出诉求,比如运维应该使用哪些参数、参数代表什么意思。
像这样一个 Component 可以直接通过 kubectl 安装到 K8s 中。

然后我们可以通过 kubectl 工具查看到已经安装好的组件有哪些:

所以说,我们当前的 K8s 集群,支持两种“应用组件”。需要指出的是,除了我们内置支持的组件之外,开发自己可以自由定义各种各样的组件然后提交给我们。Component Spec 里的 Workload Type 是可以随意扩展的,就跟 K8s 的 CRD 机制一样。
第二部分: Trait
说完了开发能用的 API,我们再来看运维用的 API 长什么样。
在设计应用的运维能力定义的过程中,我们重点关注的是运维能力怎么发现和管理的问题。
为此,我们设计了一个叫做 Trait 的概念。所谓 Trait,也就是应用的“特征”,其实就是一种运维能力的声明式描述。我们能通过命令行工具发现一个系统里支持哪些 Traits(运维能力)。

这时候,运维要查看具体的运维能力该怎么使用,是非常简单的:

可以看到,他可以在 Trait 定义里清晰的看到这个运维能力可以作用于哪种类型的 Workload,包括能填哪些参数?哪些必填?哪些选填?参数的作用描述是什么? 你也可以发现,OAM 体系里面,Component 和 Trait 这些 API 都是 Schema,所以它们是整个对象的字段全集,也是了解这个对象描述的能力“到底能干吗?”的最佳途径(反正基础设施团队的文档写的也不咋地)。
上面这些 Trait 也都是用过 kubectl apply 就可以安装到集群当中的。
既然 Component 和 Trait 都是 Schema,那么它们怎么实例化成应用呢?
第三部分:Application Configuration
在 OAM 体系中,Application Configuration 是运维人员(或者系统本身也可以)执行应用部署等动作的操作对象。在 Application Configuration 里,运维人员可以将 Trait 绑定到 Component 上执行。
在 Application Configuration YAML 里面,运维可以把 Component 和 Trait 组装起来,从而得到一个可以部署的“应用”:
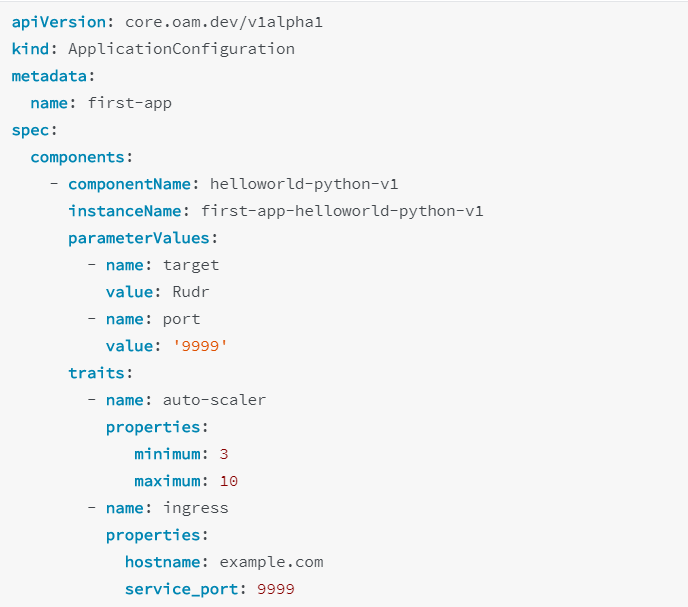
在这里我们可以看到,运维实例化的应用里面包含了一个叫 hellowworld-python-v1 的 Component,它有两个参数:一个是环境变量 target,一个是port。需要注意的是,这两个参数是运维人员覆盖了原先 Component yaml 中开发定义的两个可覆盖变量。
同时,这个 Component 绑定了 2 个运维能力:一个是水平扩容,一个是 Ingress 域名访问。
运维人员通过 kubectl 即可把这样一个应用部署起来:

这时候在 K8s 里面,你就可以看到 OAM 插件会自动为你创建出对应的 Deployment。

同时,这个应用需要的 Ingress 也被自动创建起来了:

这里其实是前面提到的 Rudr 插件在起作用,在拿到 OAM 的 Application Configuration 文件以后,识别出其中的 Component 和 Trait,将其映射到 K8s 上的资源并拉起,K8s 资源相应的生命周期都随着 OAM 的配置去管理。当然,由于 OAM 定义是平台无关的,所以除了 K8s 本身的资源,Rudr 插件的实现中也会加入外部资源的拉起。
OAM YAML 文件 = 一个自包含的软件安装包
最终我们可以通过像乐高积木一样组装复用 OAM 的不同模块,实例化出一个 OAM 的应用出来。更重要的是,这个 OAM 应用描述文件是完全自包含的,也就是说通过 OAM YAML,作为软件分发商,我们就可以完整地跟踪到一个软件运行所需要的所有资源和依赖。
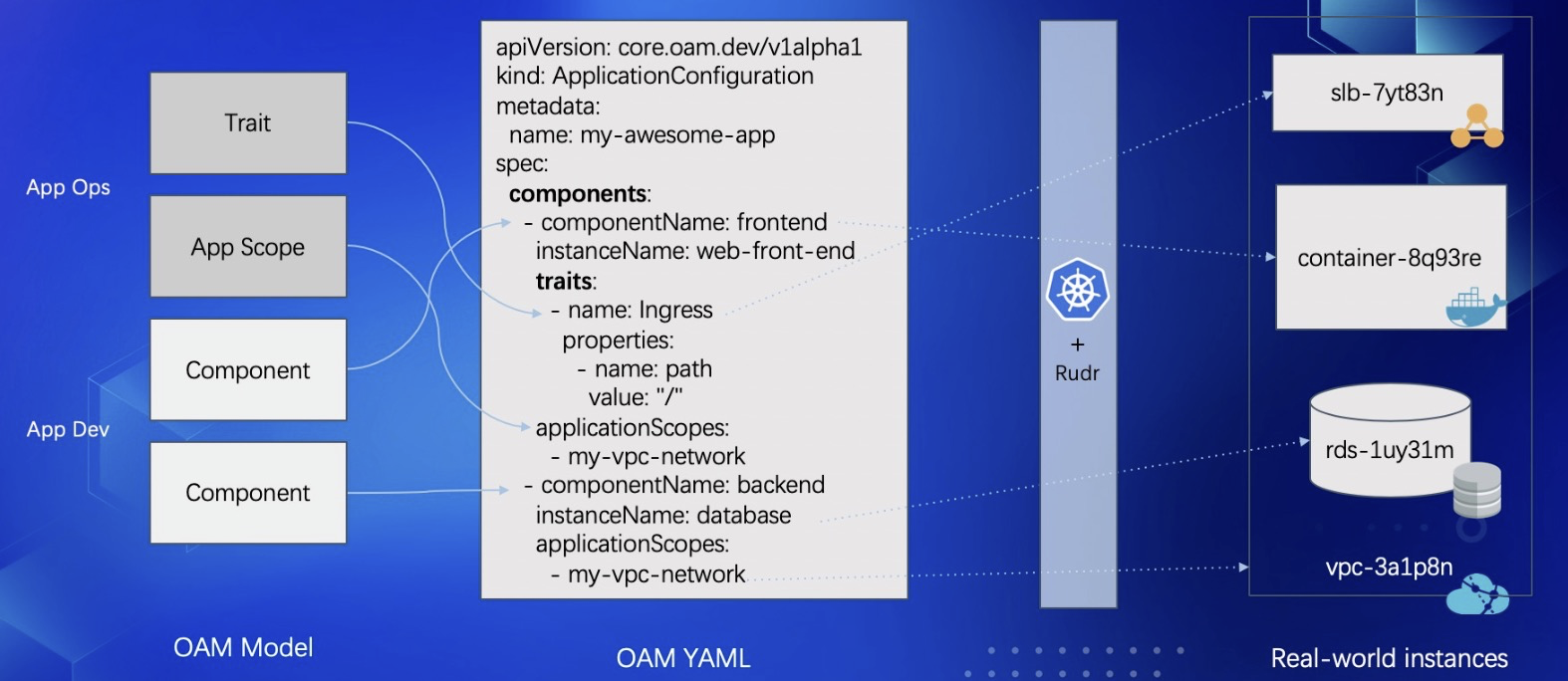
这就使得现在对于一个应用,大家只需要一份 OAM 的配置文件,就可以快速、在不同运行环境上把应用随时运行起来,把这种自包含的应用描述文件完整地交付到任何一个运行环境中。
这不仅让我们前面提到的软件交付难题得到了很好的解决,也让更多非 K8s 平台比如 IoT、游戏分发、混合环境软件交付等场景,能享受到云原生应用管理的畅快。
最后
OAM 是一个完全属于社区的应用定义模型,我们非常希望大家都能参与进来。

(钉钉扫码加入交流群)
一方面,如果你有任何场景感觉 OAM 无法满足的,欢迎你在社区提出 issue 来描述你的案例;
另一方面,OAM 模型也正在积极的同各个云厂商、开源项目进行对接。
我们期待能与大家一起共建这个全新的应用管理生态。
Q & A
Q1:OAM spec 中目前还没有看到属于 Infra Operator 的管理对象(补充:Component 是面向 App Developer,Traits 和 AppConfiguration 面向 App Operator,哪个对象是面向 Infra Operator 的?)
A1:OAM 本身就是基础设施运维手里的武器,包括 Kubernetes、Terraform 等一系列平台层的开源项目,基础设施运维可以通过这些开源项目构建 OAM 的实现(如 Rudr 基于 Kubernetes)。所以 OAM 的实现层就是基础设施运维提供的,他们不需要额外的对象来使用 OAM。
Q2:OAM Controller和 admission controller 的分工标准是什么?
A2:OAM 项目中的 admission controller 用于转换和检验 spec,完全等价于 K8s 中 admission controller。目前实现的功能包括转换 [fromVariable(VAR)] 这种 spec 中的函数,检验 AppConfig、Component、Trait、Scope 等 CR 是否符合规范,是否合法等。OAM Controller,即目前的开源项目 Rudr,就是整个 OAM 的实现层,它负责解释 OAM 的 spec 并转换为真实运行的资源,这里的资源可以是 K8s 原有的一些,也可以是像阿里云上的 RDS 这类云资源。目前 Rudr 项目是 Rust 语言写的,考虑到 K8s 生态大多数都是用 Go 语言写的,我们后续也会开源一个 Go 语言编写的 OAM-Framework,用于快速实现像 Rrudr 这样的 OAM 实现层。
Q3:计划啥时候开源 Go 的 OAM-Framework 呀?
A3:我们需要一点时间进一步打磨 OAM-Framework ,让它适配大家的场景。但是应该很快就会跟大家见面。
Q4:阿里是如何降低 K8s 的复杂度来满足运维和研发一些共性诉求的?在 K8s 中的用户 user 角色可能是开发也可能是运维。
A4:目前我们遇到的大多数场景都能区分哪些是运维要关心的,哪些是研发要关心的。OAM 降低 K8s 复杂度的主要方法就是关注点分离,给 K8s 的 API 做减法,尽量让某一方可以少关注一些内容。如果你有这样一个无法分割的场景,其实我们也很感兴趣,欢迎把 case 提出来一起探讨。另一方面,我们并不是屏蔽掉 K8s,OAM Spec 预留了充足的扩展性,完全可以把K8s原有的能力提供给用户。
Q5:我认为 OAM 是基于 K8s 针对于不同应用上的抽象层,现在我们有很多应用都是用 Helm 包包装好的,如果切换成 OAM 的话,我们需要注意哪些地方呢?
A5:其实我们上半年一直在推广 Helm 在国内的使用,包括提供了阿里巴巴的 Helm 镜像站(https://developer.aliyun.com/hub)等,所以 OAM 跟 Helm 也是相辅相成的。简单的说,OAM 其实就是 Helm 包里面 template 文件夹里面的内容。Helm 是 OAM 做参数渲染(template)和打包(chart)的工具。如果切换到 OAM,Helm 的使用方式不需要变,里面的 spec 换成 OAM 的 spec 即可。
Q6:请问,Rudr 用起来了吗,效果如何。Rudr 的架构有没更丰富的资料?
A6:Rudr 一直是可以用的,大家要是用不起来可以提 issue,想要什么方面的资料或者疑问也可以提 issue,我们也在完善文档。目前相关的材料都在这里:
https://github.com/oam-dev/rudr/tree/master/docs
Q7:我们一直在用 Helm 打包我们的应用,去做 gitops ,一个通用的 chart 对应不同的 values.yaml 做到了复用。听了分享,很期待 OAM,当然还有 Openkruise。
A7:Openkruise 是开源的哈,大家可以关注 https://github.com/openkruise/kruise 我们也一直在迭代。
Q8:OAM 有哪些公司在用?实际体验反馈如何?
A8:OAM 刚刚发布一个月左右,具体有哪些公司已经在使用我们还没有来得及统计。阿里巴巴和微软内部都已经在使用,并且都有对外的产品使用 OAM。就我们接触到的用户来说,无论是社区的用户还是阿里巴巴内部,都对 OAM 的关注点分离等理念非常认同,也都在积极落地。
社群分享文章整理
Vol 1 : 当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题?
Vol 2 : 超大规模商用 K8s 场景下,阿里巴巴如何动态解决容器资源的按需分配问题?
Vol 3 : 备战双 11!蚂蚁金服万级规模 K8s 集群管理系统如何设计?
Vol 4 : 带你上手一款下载超 10 万次的 IEDA 插件
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
给 K8s API “做减法”:阿里巴巴云原生应用管理的挑战和实践的更多相关文章
- 敢为人先,从阿里巴巴云原生团队实践Dapr案例,看分布式应用运行时前景
背景 Dapr是一个由微软主导的云原生开源项目,国内云计算巨头阿里云也积极参与其中,2019年10月首次发布,到今年2月正式发布V1.0版本.在不到一年半的时间内,github star数达到了1.2 ...
- 初探云原生应用管理(二): 为什么你必须尽快转向 Helm v3
系列介绍:这个系列是介绍如何用云原生技术来构建.测试.部署.和管理应用的内容专辑.做这个系列的初衷是为了推广云原生应用管理的最佳实践,以及传播开源标准和知识.在这个系列文章的开篇初探云原生应用管理(一 ...
- 初探云原生应用管理(一): Helm 与 App Hub
系列介绍:初探云原生应用管理系列是介绍如何用云原生技术来构建.测试.部署.和管理应用的内容专辑.做这个系列的初衷是为了推广云原生应用管理的最佳实践,以及传播开源标准和知识.通过这个系列,希望帮 ...
- 云原生应用 Kubernetes 监控与弹性实践
前言 云原生应用的设计理念已经被越来越多的开发者接受与认可,而Kubernetes做为云原生的标准接口实现,已经成为了整个stack的中心,云服务的能力可以通过Cloud Provider.CRD C ...
- 云原生应用管理,像管理手机APP一样管理企业应用
我们在使用智能手机的时候,手机APP从应用市场一键安装,安装好即点即用,当有新版本一键升级,如果不想用了长按图标删除,整个过程非常简单,小朋友都能熟练掌握.而对于企业应用,由于结构复杂.可用性要求高. ...
- 公有云上构建云原生 AI 平台的探索与实践 - GOTC 技术论坛分享回顾
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办,峰会聚焦 AI 与云原生两大以开源驱动的前沿技术领域,邀请国家级研究机构与顶级互联网公司的一线技术专家 ...
- 深度解读阿里巴巴云原生镜像分发系统 Dragonfly
Dragonfly 是一个由阿里巴巴开源的云原生镜像分发系统,主要解决以 Kubernetes 为核心的分布式应用编排系统的镜像分发难题.随着企业数字化大潮的席卷,行业应用纷纷朝微服务架构演进,并通过 ...
- 初探云原生应用管理之:聊聊 Tekton 项目
[编者的话]“人间四月芳菲尽,山寺桃花始盛开.” 越来越多专门给 Kubernetes 做应用发布的工具开始缤纷呈现,帮助大家管理和发布不断增多的 Kubernetes 应用.在做技术选型的时候,我们 ...
- 【云原生下离在线混部实践系列】深入浅出 Google Borg
Google Borg 是资源调度管理和离在线混部领域的鼻祖,同时也是 Kubernetes 的起源与参照,已成为从业人员首要学习的典范.本文尝试管中窥豹,简单从<Large-scale clu ...
随机推荐
- Spring Cloud 如何搭建Config
利用spring cloud 的 spring-cloud-config-server 组件 搭建自己的配置中心 config-server 配置文件可以存放在 github ,gitlab 等上面, ...
- [考试反思]1113csp-s模拟测试113:一念
在这么考下去可以去混女队了2333 两天总分rank14,退役稳稳的 的确就是没状态.满脑子都是<包围保卫王国>ddp/LCT/ST,没好好考试. 我太菜了写题也写不出来考试也考不好(显然 ...
- Luogu P2210 Haywire 题解
其实这题吧...有一种玄学解法 这题的要求的就是一个最小化的顺序 那么,我们就不进想到了一种显然的写法 就是random_shuffle 什么?这不是乱搞的非正解吗 然而,正如一句话说的好 一个算法, ...
- BOM的初级理解
1.什么是BOM,BOm有什么作用? BOM和DOM.ES是JavaScript的重要三个组成部分: 其中BOM是专门操作浏览器的API,其实他就是一种兼容性问题,这其中问题比较大就是IE浏览器,谁叫 ...
- IT兄弟连 HTML5教程 CSS3揭秘 CSS3属性2
3 背景属性 在CSS3中提供了多个背景属性,这里只介绍两个比较常用的属性,其他属性可以从手册中获取帮助.在CSS3中,通过background-image或者background属性可以为一个容器 ...
- 损失函数--KL散度与交叉熵
损失函数 在逻辑回归建立过程中,我们需要一个关于模型参数的可导函数,并且它能够以某种方式衡量模型的效果.这种函数称为损失函数(loss function). 损失函数越小,则模型的预测效果越优.所以我 ...
- Android 在Fragment中修改Activity中的控件
在当前的Fragment中调用getActivity方法获取依附着的那个Activity,然后再用获取到的Activity去findViewById拿到你需要的控件对其操作就行了.
- Monday
ssm项目 设计模式:上周(观察者模式,策略模式)
- Scrapy框架-爬虫程序相关属性和方法汇总
一.爬虫项目类相关属性 name:爬虫任务的名称 allowed_domains:允许访问的网站 start_urls: 如果没有指定url,就从该列表中读取url来生成第一个请求 custom_se ...
- 蓝色大气简约立体答辩ppt模板推荐
小编个人非常喜欢这个模版,大气深蓝色,具有科技感,非常适合学生的毕业答辩PPT模板. 模版来源:http://ppt.dede58.com/gongzuohuibao/26496.html