Java集合 HashSet的原理及常用方法
一. HashSet概述
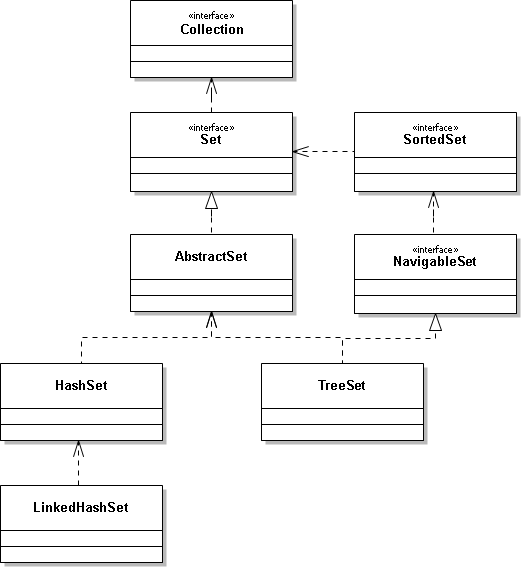
HashSet是Java集合Set的一个实现类,Set是一个接口,其实现类除HashSet之外,还有TreeSet,并继承了Collection,HashSet集合很常用,同时也是程序员面试时经常会被问到的知识点,下面是结构图
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{}
二. HashSet构造
HashSet有几个重载的构造方法,我们来看一下
private transient HashMap<E,Object> map;
//默认构造器
public HashSet() {
map = new HashMap<>();
}
//将传入的集合添加到HashSet的构造器
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//明确初始容量和装载因子的构造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//仅明确初始容量的构造器(装载因子默认0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
通过上面的源码,我们发现了HashSet就TM是一个皮包公司,它就对外接活儿,活儿接到了就直接扔给HashMap处理了。因为底层是通过HashMap实现的,这里简单提一下:
HashMap的数据存储是通过数组+链表/红黑树实现的,存储大概流程是通过hash函数计算在数组中存储的位置,如果该位置已经有值了,判断key是否相同,相同则覆盖,不相同则放到元素对应的链表中,如果链表长度大于8,就转化为红黑树,如果容量不够,则需扩容(注:这只是大致流程)。
如果对HashMap原理不太清楚的话,可以先去了解一下
三. add方法
HashSet的add方法时通过HashMap的put方法实现的,不过HashMap是key-value键值对,而HashSet是集合,那么是怎么存储的呢,我们看一下源码
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
看源码我们知道,HashSet添加的元素是存放在HashMap的key位置上,而value取了默认常量PRESENT,是一个空对象,至于map的put方法,大家可以看HashMap原理(二) 扩容机制及存取原理。

四. remove方法
HashSet的remove方法通过HashMap的remove方法来实现
//HashSet的remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//map的remove方法
public V remove(Object key) {
Node<K,V> e;
//通过hash(key)找到元素在数组中的位置,再调用removeNode方法删除
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
/**
*
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//步骤1.需要先找到key所对应Node的准确位置,首先通过(n - 1) & hash找到数组对应位置上的第一个node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//1.1 如果这个node刚好key值相同,运气好,找到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 运气不好,在数组中找到的Node虽然hash相同了,但key值不同,很明显不对, 我们需要遍历继续
* 往下找;
*/
else if ((e = p.next) != null) {
//1.2.1 如果是TreeNode类型,说明HashMap当前是通过数组+红黑树来实现存储的,遍历红黑树找到对应node
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//1.2.2 如果是链表,遍历链表找到对应node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//通过前面的步骤1找到了对应的Node,现在我们就需要删除它了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* 如果是TreeNode类型,删除方法是通过红黑树节点删除实现的,具体可以参考【TreeMap原理实现
* 及常用方法】
*/
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
/**
* 如果是链表的情况,当找到的节点就是数组hash位置的第一个元素,那么该元素删除后,直接将数组
* 第一个位置的引用指向链表的下一个即可
*/
else if (node == p)
tab[index] = node.next;
/**
* 如果找到的本来就是链表上的节点,也简单,将待删除节点的上一个节点的next指向待删除节点的
* next,隔离开待删除节点即可
*/
else
p.next = node.next;
++modCount;
--size;
//删除后可能存在存储结构的调整,可参考【LinkedHashMap如何保证顺序性】中remove方法
afterNodeRemoval(node);
return node;
}
}
return null;
}
removeTreeNode方法具体实现可参考 TreeMap原理实现及常用方法
afterNodeRemoval方法具体实现可参考LinkedHashMap如何保证顺序性
五. 遍历
HashSet作为集合,有多种遍历方法,如普通for循环,增强for循环,迭代器,我们通过迭代器遍历来看一下
public static void main(String[] args) {
HashSet<String> setString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
打印出来的结果如何呢?
星期二
星期三
星期四
星期五
星期一
意料之中吧,HashSet是通过HashMap来实现的,HashMap通过hash(key)来确定存储的位置,是不具备存储顺序性的,因此HashSet遍历出的元素也并非按照插入的顺序。
六. 合计合计
按照我前面的规划,应该每一块主要的内容都单独写一下,如集合ArrayList,LinkedList,HashMap,TreeMap等。不过我在写这篇关于HashSet的文章时,发现有前面对HashMap的讲解后,确实简单,HashSet就是一个皮包公司,在HashMap外面加了一个壳,那么LinkedHashSet是否就是在LinkedHashMap外面加了一个壳呢,而TreeSet是否是在TreeMap外面加了一个壳?我们来验证一下
先看一下LinkedHashSet
最开始的结构图已经提到了LinkedHashSet是HashSet的子类,我们来看源码
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
上面就是LinkedHashSet的所有代码了,是不是感觉智商被否定了,这基本上没啥东西嘛,构造器还全部调用父类的,下面就是其父类HashSet的对此的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
大家也看出来,和我们的猜测一样,没有深究下去的必要了。如果有兴趣可以看看LinkedHashMap如何保证顺序性
在看一下TreeSet
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
}
确实如我们所猜测,TreeSet也完全依赖于TreeMap来实现,如果有兴趣可以看看TreeMap原理实现及常用方法
七. 总结
本来想三章的内容,一章就算完了,虽然Set实现有点赖皮,毕竟他祖辈是Collection而不是Map,在Map的实现类上穿了一层衣服就成了Set,然后出于某种目的埋伏在Collection中,哈哈,开个玩笑,本文主要介绍了HashSet的原理以及主要方法,同时简单介绍了LinkedHashSet和TreeSet,若有不对之处,请批评指正,望共同进步,谢谢!
Java集合 HashSet的原理及常用方法的更多相关文章
- 3.Java集合-HashSet实现原理及源码分析
一.HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持,它不保证set的迭代顺序很久不变.此类允许使用null元素 二.HashSet的实现: 对于Ha ...
- Java集合 -- HashSet 和 HashMap
HashSet 集合 HashMap 集合 HashSet集合 1.1 Set 接口的特点 Set体系的集合: A:存入集合的顺序和取出集合的顺序不一致 B:没有索引 C:存入集合的元素没有重复 1. ...
- java 集合 HashSet 实现随机双色球 HashSet addAll() 实现去重后合并 HashSet对象去重 复写 HashCode()方法和equals方法 ArrayList去重
package com.swift.lianxi; import java.util.HashSet; import java.util.Random; /*训练知识点:HashSet 训练描述 双色 ...
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- java集合对象实现原理
1.集合包 集合包是java中最常用的包,它主要包括Collection和Map两类接口的实现. 对于Collection的实现类需要重点掌握以下几点: 1)Collection用什么数据结构实现? ...
- Java 集合 - HashSet
一.源码解析 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable ...
- Java集合---HashSet的源码分析
一. HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.它不保证set 的迭代顺序:特别是它不保证该顺序恒久不变.此类允许使用null元素. 二. ...
- java集合-HashSet源码解析
HashSet 无序集合类 实现了Set接口 内部通过HashMap实现 // HashSet public class HashSet<E> extends AbstractSet< ...
- Java集合:ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
随机推荐
- Mariadb的安装与使用
一.安装Mariadb 参考博客:https://www.cnblogs.com/pyyu/p/9467289.html 安装软件的三中方式 yum原码编译安装下载rpm安装 yum与原码编译安装安装 ...
- spring boot单元测试之MockMvc
spring单元测试之MockMvc,这个只是模拟,并不是真正的servlet,所以session.servletContext是没法用的. @RunWith(SpringRunner.class) ...
- python列表和字典的迭代
1.列表和字典的迭代 程序开发中,对列表和字典进行迭代是非常常见的事情. 字典一般可以选择对key进行迭代.对value迭代和对key/value一起迭代 >>> d = {'a': ...
- windows下nginx的安装和使用
LNMP的安装与配置 windows下的nginx安装和使用 1.1 去官网下载相应的安装包:http://nginx.org/en/download.html 1.2 解压后进入PowerShell ...
- Powerdesigner 从Oracle到mssql2008
database->update model for database> ->系统数据源->选择用户,选择表,确定... 1.database->change Curre ...
- Django多对多表的三种创建方式,MTV与MVC概念
MTV与MVC MTV模型(django): M:模型层(models.py) T:templates V:views MVC模型: M:模型层(models.py) V:视图层(views.py) ...
- Hive —— 安装部署
一.安装Hive 1.1 下载并解压 下载所需版本的Hive,这里我下载版本为cdh5.15.2.下载地址:http://archive.cloudera.com/cdh5/cdh/5/ # 下载后进 ...
- Hive 学习之路(七)—— Hive 常用DML操作
一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (p ...
- spring boot 2.x 系列 —— spring boot 实现分布式 session
文章目录 一.项目结构 二.分布式session的配置 2.1 引入依赖 2.2 Redis配置 2.3 启动类上添加@EnableRedisHttpSession 注解开启 spring-sessi ...
- 系统学习 Java IO (五)----使用 SequenceInputStream 组合多个流
目录:系统学习 Java IO---- 目录,概览 SequenceInputStream 可以将两个或多个其他 InputStream 合并为一个. 首先,SequenceInputStream 将 ...