【数学建模】day11-典型相关分析
这与主成分分析有点相似。
0. 基本思想
主成分分析(PCA)是把原始有相关性变量,线性组合出无关的变量(投影),以利用主成分变量进行更加有效的分析。
而典型相关分析(CCA)的思想是:分析自变量组 X = [x1,x2,x3…xp],因变量组 Y = [y1,y2,y3…yq] 之间的相关性。(注意这里X的每一个自变量x1是个列向量,代表有多个观测值)。
如果采用传统的相关分析,只要求X的每一个变量与Y的每一个变量的相关系数,从而组成相关系数矩阵 R = [rij]p*q ,rij表示第i个自变量xi与第j个因变量yj之间的相关系数。
然而,这是有缺陷的:只粗暴的考虑了X与Y的关系,却忽略了X自变量之间也可能有相关关系,Y因变量之间亦如此。
解决的方法类似于主成分分析,我们可以把X提取出主成分,Y也提取出主成分,从而X、Y内部线性不相关了,这样利用主成分研究X与Y之间相关性就解决了上述缺点。
1. 典型相关分析
典型相关分析:
假设
自变量组:X = [x1,x2,x3…xp]
因变量组:Y = [y1,y2,y3…yq]
注意,xi与yj都是相同维度的列向量。
要求
分析X与Y之间的相关性
2 直观描述
首先在X中找出线性组合u1, 在Y中找出线性组合v1,使得 r(u1,v1)达到最大。
其次,在X中找第二个线性组合u2,Y中找第二个线性组合v2,要求使得u2与u1线性不相关,v2与v1线性不相关,并且: r(u2,v2)达到次大。
继续。直到两组变量之间的相关性被提取完毕。
3 数学描述
数学描述:
线性组合得到的变量称作典型变量。
4. 典型相关模型的分析
需要分析原始变量与典型变量之间的相关性。
原始变量xi与典型变量uj之间的相关性为:
式中,α是典型变量系数。
同理可求得原始变量xi与典型变量vj、yi与vj、yi与uj之间的相关系数。
建模时可以列出这四个相关系数表格。
进而,我们要对典型变量对各组原始变量解释能力做分析,因为原始变量-->典型变量毕竟会有信息的损失。
Def:
其中,ρ(ui,xk) 是指原始变量xk与电影变量ui之间的相关系数。
注:
1)这个解释能力是指,原始变量—>典型变量后,某个典型变量 ui 对原始变量<x1,x2,…xp>的解释能力。因为如果采用比较少的典型变量,就会有更多的信息损失,这与PCA分析中主成分贡献率类似。
2) 计算方法是:某个典型变量ui与所有xk(k=1 to p)的相关系数的平方和,再除以变量个数。这是方差比例。
我们还要进行典型相关系数的检验。
这一步是建模必须的。
计算典型相关系数用到的是,X与X之间的协方差矩阵、X与Y之间的协方差矩阵、Y与Y之间的协方差矩阵。而这些协方差矩阵其实是未知的,我们只是用一些样本对总体进行了近似。这个近似是有误差的,需要进行有关的假设检验。
即:整体检验:检验X与Y之间的协方差矩阵是否为0。若是0,则显然X与Y不相关。否则X与Y具有相关性,即说明至少第一对典型变量之间的相关性显著。
部分检验:检验部分典型相关系数为0的检验:也就是第k对典型相关变量之间相关关系不显著。
下面进行检验:
1)整体检验
2)部分总体典型相关系数为零的检验
5 Summary:典型相关分析步骤
步骤如下:
设标准化后,X、Y增广阵为Z:
step1:计算原始变量X、Y增广阵的相关系数矩阵R,并且剖分为:
,其中,R11是X的协方差矩阵,R12是X与Y的协方差矩阵。
step2:求典型相关系数以及典型变量。
step3:进行典型相关系数λi的显著性检验。有整体检验与部分检验,详情见上。
step4:典型结构与典型冗余分析。
这其实是计算:
典型结构分析:其实就是X组原始变量被ui解释分方差比例,Y组原始变量被vi解释的方差比例
典型冗余分析:其实就是X组原始变量被vi解释分方差比例,Y组原始变量被ui解释的方差比例
6. MATLAB实现。
MATLAB进行典型相关分析命令:
先查看一下Matlab help命令解释:
canoncorr Canonical correlation analysis.
[A,B] = canoncorr(X,Y) computes the sample canonical coefficients for
the N-by-P1 and N-by-P2 data matrices X and Y. X and Y must have the
same number of observations (rows) but can have different numbers of
variables (cols). A and B are P1-by-D and P2-by-D matrices, where D =
min(rank(X),rank(Y)). The jth columns of A and B contain the canonical
coefficients, i.e. the linear combination of variables making up the
jth canonical variable for X and Y, respectively. Columns of A and B
are scaled to make COV(U) and COV(V) (see below) the identity matrix.
If X or Y are less than full rank, canoncorr gives a warning and
returns zeros in the rows of A or B corresponding to dependent columns
of X or Y. [A,B,R] = canoncorr(X,Y) returns the -by-D vector R containing the
sample canonical correlations. The jth element of R is the correlation
between the jth columns of U and V (see below). [A,B,R,U,V] = canoncorr(X,Y) returns the canonical variables, also
known as scores, in the N-by-D matrices U and V. U and V are computed
as U = (X - repmat(mean(X),N,))*A and
V = (Y - repmat(mean(Y),N,))*B. [A,B,R,U,V,STATS] = canoncorr(X,Y) returns a structure containing
information relating to the sequence of D null hypotheses H0_K, that
the (K+)st through Dth correlations are all zero, for K = :(D-).
STATS contains seven fields, each a -by-D vector with elements
corresponding to values of K: Wilks: Wilks' lambda (likelihood ratio) statistic
chisq: Bartlett's approximate chi-squared statistic for H0_K,
with Lawley's modification
pChisq: the right-tail significance level for CHISQ
F: Rao's approximate F statistic for H0_K
pF: the right-tail significance level for F
df1: the degrees of freedom for the chi-squared statistic,
also the numerator degrees of freedom for the F statistic
df2: the denominator degrees of freedom for the F statistic Example: load carbig;
X = [Displacement Horsepower Weight Acceleration MPG];
nans = sum(isnan(X),) > ;
[A B r U V] = canoncorr(X(~nans,:), X(~nans,:)); plot(U(:,),V(:,),'.');
xlabel('0.0025*Disp + 0.020*HP - 0.000025*Wgt');
ylabel('-0.17*Accel + -0.092*MPG') See also pca, manova1.
典型相关分析函数:[a,b,r,u,v,stats] = cononcorr(x,y):
param:
x:原始变量x矩阵,每列一个自变量指标,第i列是 xi 的样本值
y:原始变量y矩阵,每列一个因变量指标,第j列是 yj 的样本值
return:
a:自变量x的典型相关变量系数矩阵,每列是一组系数。
列数为典型相关变量数
b:因变量y的典型相关变量系数矩阵,每列是一个系数
r: 典型相关系数。即第一对<u1,v1>之间的相关系数、第二对<u2,v2>之间的相关系数…
u:对于X的典型相关变量的值
v:对于Y的典型相关变量的值
stats:假设检验的值<详细用一下就知道了>
也可以使用MATLAB按照原理直接编写程序,一个实现的例子如下:
实现程序:
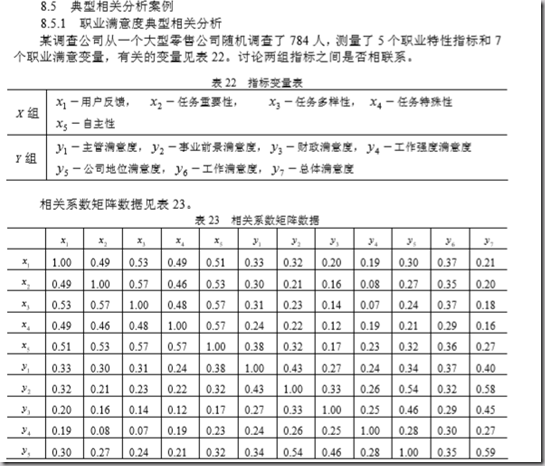
这个典型相关系数表中,第一列0.5537是第<u1,v1>的相关系数。

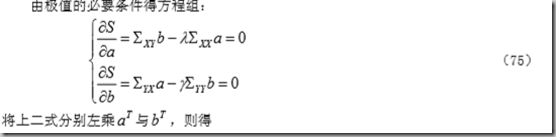



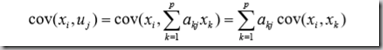













【数学建模】day11-典型相关分析的更多相关文章
- 多视图学习利器----CCA(典型相关分析)及MATLAB实现
Hello,我是你们人见人爱花见花开的小花.又和大家见面了,今天我们来聊一聊多视图学习利器------CCA. 一 典型相关分析的基本思想 当我们研究两个变量x和y之间的相关关系的时候,相关系数(相关 ...
- 在数学建模中学MATLAB
为期三周的数学建模国赛培训昨天正式结束了,还是有一定的收获的,尤其是在MATLAB的使用上. 1. 一些MATLAB的基础性东西: 元胞数组的使用:http://blog.csdn.net/z1137 ...
- 【数学建模】偏最小二乘回归分析(PLSR)
PLSR的基本原理与推导,我在这篇博客中有讲过. 0.偏最小二乘回归集成了多元线性回归.主成分分析和典型相关分析的优点,在建模中是一个更好的选择,并且MATLAB提供了完整的实现,应用时主要的问题是: ...
- 2018年中国研究生数学建模竞赛C题 二等奖 赛题论文
2018年中国研究生数学建模竞赛C题 对恐怖袭击事件记录数据的量化分析 恐怖袭击是指极端分子或组织人为制造的.针对但不仅限于平民及民用设施的.不符合国际道义的攻击行为,它不仅具有极大的杀伤性与破坏力, ...
- 2017年研究生数学建模D题(前景目标检测)相关论文与实验结果
一直都想参加下数学建模,通过几个月培训学到一些好的数学思想和方法,今年终于有时间有机会有队友一起参加了研究生数模,but,为啥今年说不培训直接参加国赛,泪目~_~~,然后比赛前也基本没看,直接硬刚.比 ...
- Matlab与数学建模
一.学习目标. (1)了解Matlab与数学建模竞赛的关系. (2)掌握Matlab数学建模的第一个小实例—评估股票价值与风险. (3)掌握Matlab数学建模的回归算法. 二.实例演练. 1.谈谈你 ...
- Python数学建模-01.新手必读
Python 完全可以满足数学建模的需要. Python 是数学建模的最佳选择之一,而且在其它工作中也无所不能. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数学 ...
- Python小白的数学建模课-03.线性规划
线性规划是很多数模培训讲的第一个算法,算法很简单,思想很深刻. 要通过线性规划问题,理解如何学习数学建模.如何选择编程算法. 『Python小白的数学建模课 @ Youcans』带你从数模小白成为国赛 ...
- Python小白的数学建模课-05.0-1规划
0-1 规划不仅是数模竞赛中的常见题型,也具有重要的现实意义. 双十一促销中网购平台要求二选一,就是互斥的决策问题,可以用 0-1规划建模. 小白学习 0-1 规划,首先要学会识别 0-1规划,学习将 ...
随机推荐
- 微信小程序项目实战 - 菜谱大全
1. 项目简介 最近研究小程序云开发,上线了一个有关菜品查询的小程序.包括搜索.分享转发.收藏.查看历史记录等功能.菜谱 API 来自聚合数据.云开发为开发者提供完整的云端支持,弱化后端和运维概念,无 ...
- FineUIMvc v1.4.0 发布了(ASP.NET MVC控件库)!
FineUIMvc v1.4.0 已经于 2017-06-30 发布,FineUIMvc 是基于 jQuery 的专业 ASP.NET MVC 控件库,是我们的新产品.由于和 FineUI(专业版)共 ...
- node express 静态资源
实例代码 const express = require('express') const path = require('path') const app = express() app.use(e ...
- Item 26: 避免对universal引用进行重载
本文翻译自<effective modern C++>,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 如果你需要写一个以名字作为参数,并记录下当前日期和 ...
- LeetCode 905. Sort Array By Parity
905. Sort Array By Parity Given an array A of non-negative integers, return an array consisting of a ...
- Hadoop重新格式化HDFS的方法
1.查看hdfs-site.xml: <property> <name>dfs.name.dir</name> <value>/home/hadoop/ ...
- win10 再次重装系统
去年经历了一次硬盘损坏,一蹶不振,伤了元气, 生产环境的系统一直没有好好的维护,我个人也是,有时一闪而过的窗口总让我觉得有什么不对,现在终于出现问题,XNA项目突然无法编译 提示: 严重性 代码 说明 ...
- 软件工程(FZU2015) 学生博客列表(最终版)
FZU:福州大学软件工程 张老师的博客:http://www.cnblogs.com/easteast/ 经过前两周选课,最后正式选上课程的所有学生博客如下: 序号 学号后3位 博客 1 629 li ...
- Hadoop生态的配置
网盘下载地址 链接: https://pan.baidu.com/s/19qWnP6LQ-cHVrvT0o1jTMg 密码: 44hs Hadoop伪分布式配置 Hadoop 可以在单节点上以伪分布 ...
- 实时采集新加坡交易所A50指数
http://www.investing.com/indices/ftse-china-a50 前段时间有人问我如何得到这个网页的实时指数变化,经过抓包发现该网站提供的指数实时变化是通过Websock ...