四、归并排序 && 快速排序
一、归并排序 Merge Sort
1.1、实现原理
- 如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
- 归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
- 分治思想跟递归思想很像。分治算法一般都是用递归来实现的。 分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
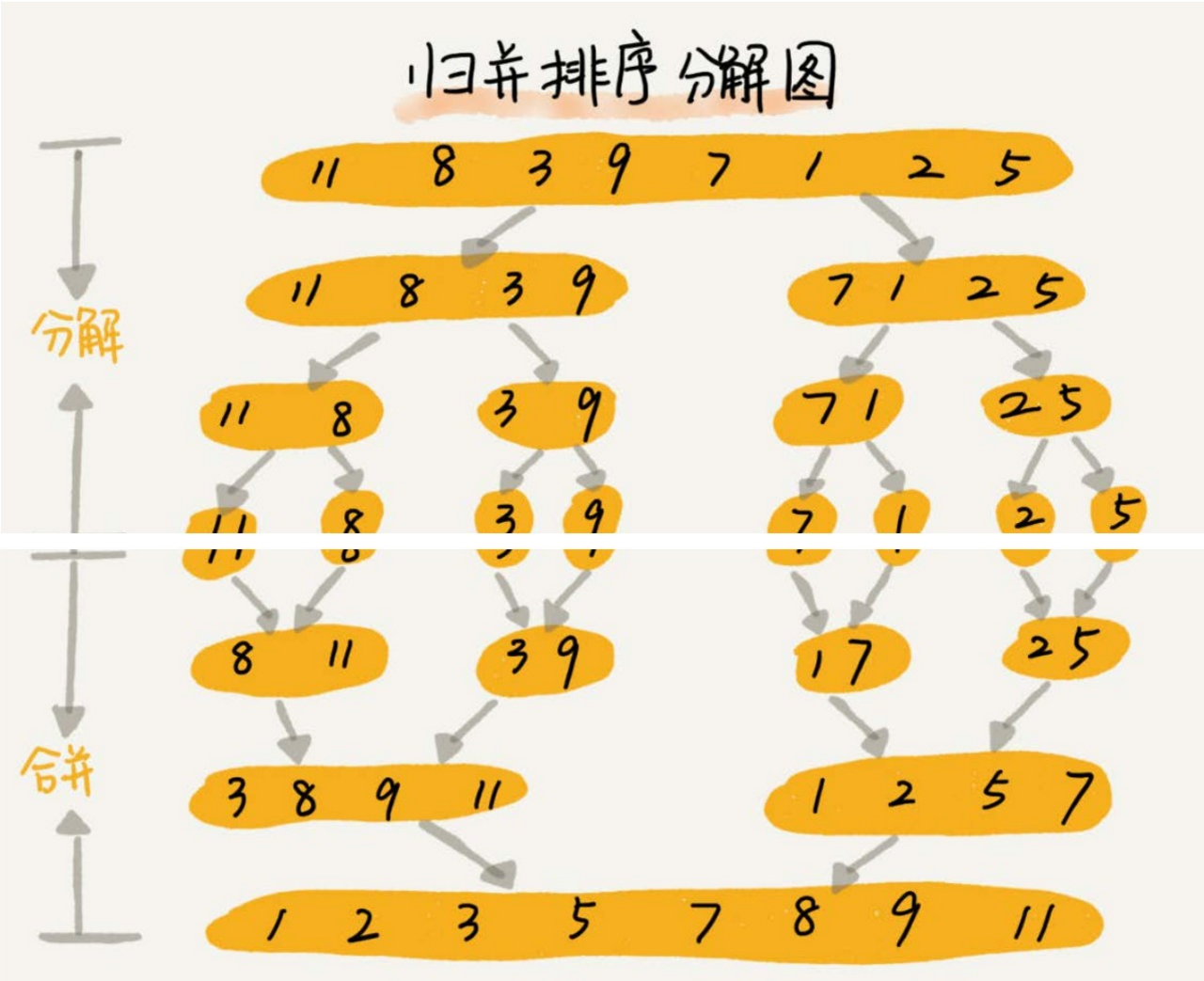
- 写递归代码的技巧就是,分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。所以,要想写出归并排序的代码,我们先写出归并排序的递推公式。
- 递推公式:erge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
- 终止条件:p >= r 不用再继续分解
- merge_sort(p…r)表示,给下标从 p 到 r 之间的数组排序。
- 我们将这个排序问题转化为了两个子问题, merge_sort(p…q) 和 merge_sort(q+1…r),其中下标 q 等于 p 和 r 的中间位置,也就是 (p+r)/2。
- 当下标从 p 到 q 和从 q+1 到 r 这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从 p 到 r 之间的数据就也排好序了。
- 实现思路如下:
/**
* 归并排序
* @param arr 排序数据
* @param n 数组大小
*/
public static void merge_sort(int[] arr, int n) {
merge_sort_c(arr, 0, n - 1);
}
// 递归调用函数
public static void merge_sort_c(int[] arr, int p, int r) {
// 递归终止条件
if (p >= r) {
return;
}
// 取p到r之间的中间位置q
int q = (p + r) / 2;
// 分治递归
merge_sort_c(arr, p, q);
merge_sort_c(arr, q + 1, r);
// 将 arr[p...q] 和 arr[q+1...r] 合并为 arr[p...r]
merge(arr[p...r],arr[p...q],arr[q + 1...r]);
}
- merge(arr[p...r], arr[p...q], arr[q + 1...r]) 这个函数的作用就是,将已经有序的 arr[p…q] 和 arr[q+1…r] 合并成一个有序的数组,并且放入 arr[p…r]。
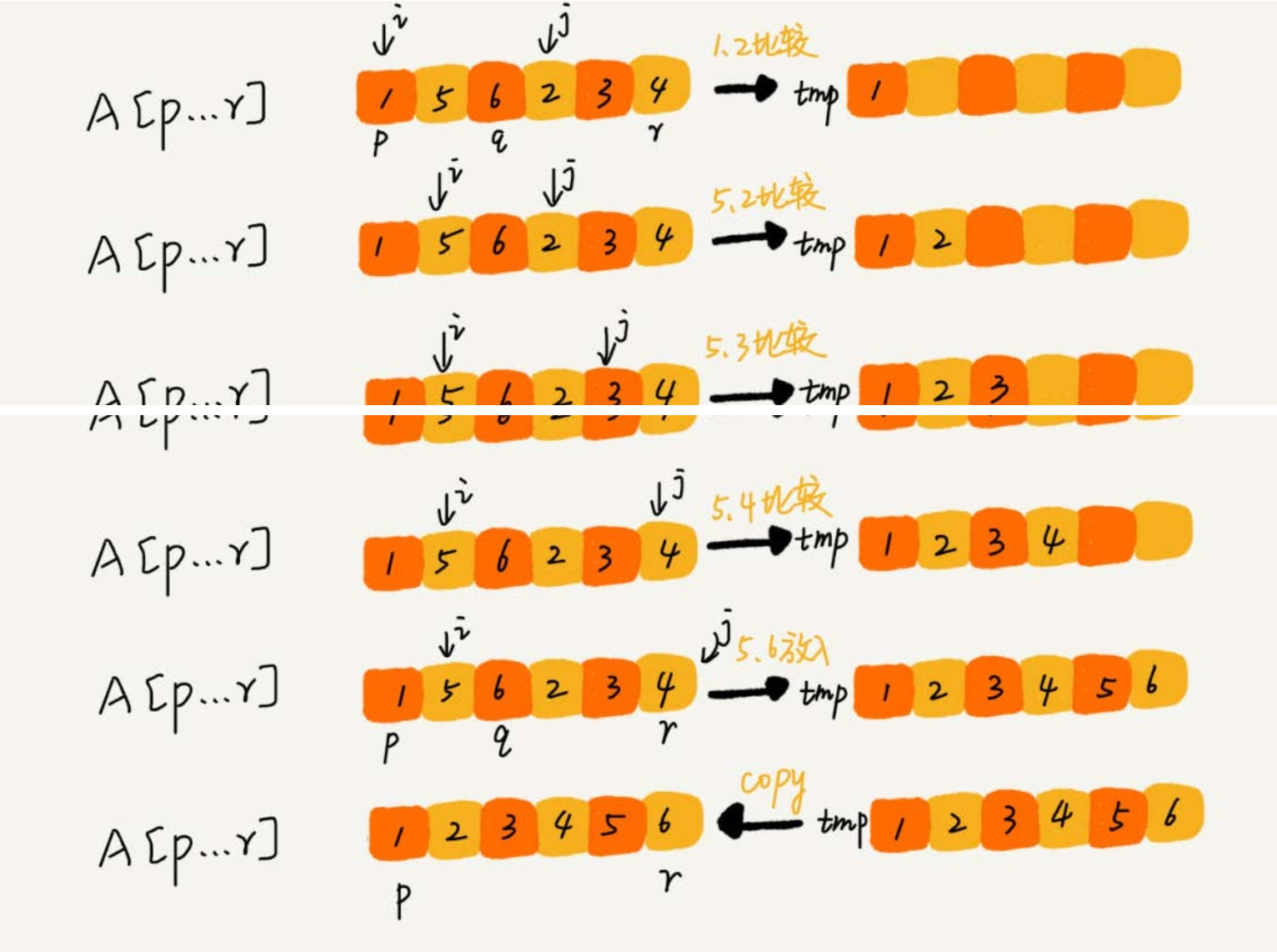
- 如下图所示,我们申请一个临时数组 tmp,大小与 arr[p…r] 相同。
- 我们用两个游标 i 和 j,分别指向 arr[p…q] 和 arr[q+1…r] 的第一个元素。
- 比较这两个元素 arr[i] 和 arr[j],如果 arr[i] <= arr[j],我们就把 arr[i] 放入到临时数组 tmp,并且 i 后移一位,否则将 arr[j] 放入到数组 tmp,j 后移一位。
- 继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。
- 最后再把临时数组 tmp 中的数据拷贝到原数组 arr[p…r] 中。
/**
* merge 合并函数
* @param arr 数组
* @param p 数组头
* @param q 数组中间位置
* @param r 数组尾
*/
public static void merge(int[] arr, int p, int q, int r) {
if (r <= p) return;
// 初始化变量i j k
int i = p;
int j = q + 1;
int k = 0;
// 申请一个大小跟A[p...r]一样的临时数组
int[] tmp = new int[r - p + 1];
// 比较排序移动到临时数组
while ((i <= q) && (j <= r)) {
if (arr[i] <= arr[j]) {
tmp[k++] = arr[i++];
} else {
tmp[k++] = arr[j++];
}
}
// 判断哪个子数组中有剩余的数据
int start = i, end = q;
if (j <= r) {
start = j;
end = r;
}
// 将剩余的数据拷贝到临时数组tmp
while (start <= end) {
tmp[k++] = arr[start++];
}
// 将tmp中的数组拷贝回 arr[p...r]
for (int a = 0; a <= r - p; a++) {
arr[p + a] = tmp[a];
}
}
1.2、性能分析
- 归并排序稳不稳定关键要看 merge() 函数,也就是两个有序子数组合并成一个有序数组的那部分代码。
- 在合并的过程中,如果 arr[p…q] 和 arr[q+1…r] 之间有值相同的元素,那我们可以像伪代码中那样,先把 arr[p…q] 中的元素放入 tmp 数组。
- 这样就保证了值相同的元素,在合并前后的先后顺序不变。所以,归并排序是一个稳定的排序算法。
- 其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
- 归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。
- 尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。
- 临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n),不是原地排序算法。
二、快速排序 Quicksort
2.1、实现原理
- 快排的思想是:如果要排序数组中下标从 p 到 r 之间的一组数据,可以选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
- 遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。
- 经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
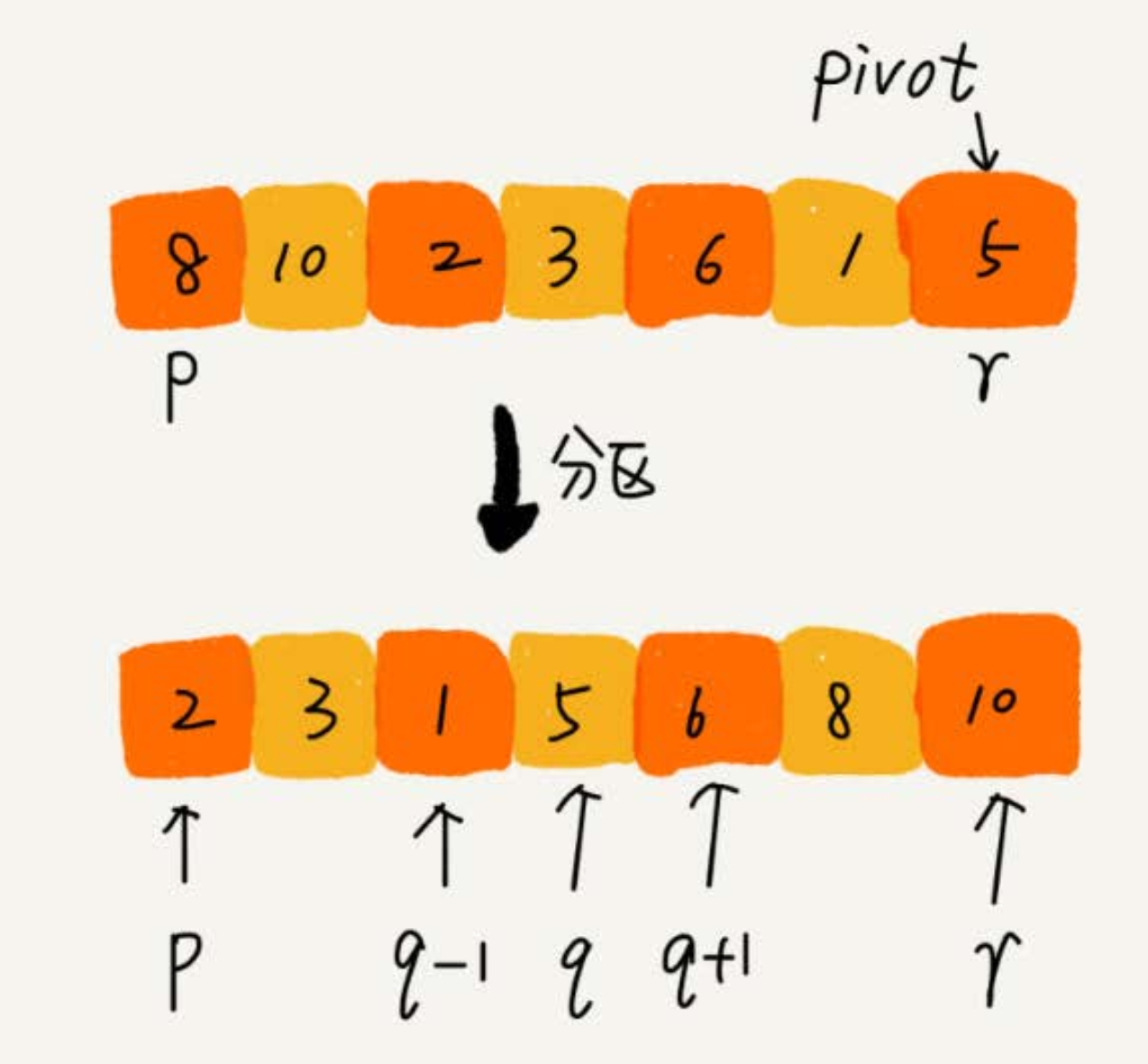
- 根据分治、递归的处理思想,可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
- 用递推公式来将上面的过程写出来的话,就是这样:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1, r)。
- 终止条件:p >= r
/**
* 快速排序
* @param arr 排序数组
* @param p 数组头
* @param r 数组尾
*/
public static void quickSort(int[] arr, int p, int r) {
if (p >= r)
return;
// 获取分区点 并移动数据
int q = partition(arr, p, r);
quickSort(arr, p, q - 1);
quickSort(arr, q + 1, r);
}
partition() 分区函数:
- 是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素),然后对 arr[p…r] 分区,并将小于 pivot 的放右边,大于的放左边,函数返回 pivot 的下标。
partition() 的实现有两种方式:
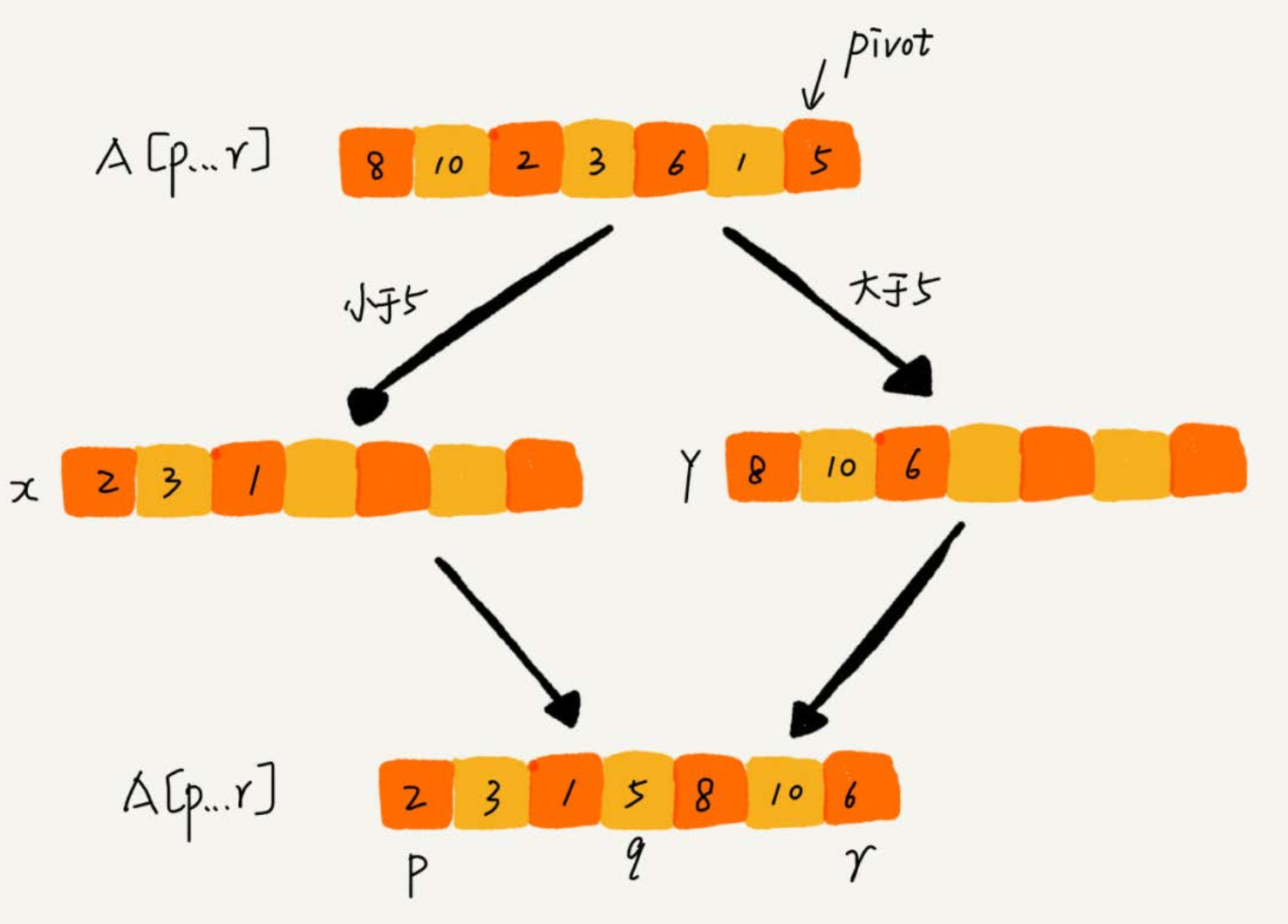
一种是不考虑空间消耗,此时非常简单。
- 申请两个临时数组 X 和 Y,遍历 arr[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到arr[p…r]。
/**
* 分区函数方式一
*
* @param arr 数组
* @param p 上标
* @param r 下标
* @return 函数返回 pivot 的下标
*/
public static int partition1(int[] arr, int p, int r) {
int[] xArr = new int[r - p + 1];
int x = 0; int[] yArr = new int[r - p + 1];
int y = 0; int pivot = arr[r]; // 将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y
for (int i = p; i < r; i++) {
// 小于 pivot 的存入 xArr 数组
if (arr[i] < pivot) {
xArr[x++] = arr[i];
}
// 大于 pivot 的存入 yArr 数组
if (arr[i] > pivot) {
yArr[y++] = arr[i];
}
} int q = x + p;
// 再将数组 X 和数组 Y 中数据顺序拷贝到 arr[p…r]
for (int i = 0; i < x; i++) {
arr[p + i] = xArr[i];
}
arr[q] = pivot;
for (int i = 0; i < y; i++) {
arr[q + 1 + i] = yArr[i];
} return q;
}
另外一种有点类似选择排序。
- 我们通过游标 i 把 arr[p…r-1] 分成两部分。arr[p…i-1] 的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,arr[i…r-1] 是“未处理区间”。
- 我们每次都从未处理的区间 arr[i…r-1] 中取一个元素 arr[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 arr[i]的位置。
- 在数组某个位置插入元素,需要搬移数据,非常耗时。此时可以采用交换,在 O(1) 的时间复杂度内完成插入操作。需要将 arr[i] 与 arr[j] 交换,就可以在 O(1)时间复杂度内将 arr[j] 放到下标为 i 的位置。

/**
* 分区函数方式二
* @param arr 数组
* @param p 上标
* @param r 下标
* @return 函数返回pivot的下标
*/
public static int partition2(int[] arr, int p, int r) {
int pivot = arr[r];
int i = p;
for (int j = p; j < r; j++) {
if (arr[j] < pivot) {
if (i == j) {
++i;
} else {
int tmp = arr[i];
arr[i++] = arr[j];
arr[j] = tmp;
}
}
}
int tmp = arr[i];
arr[i] = arr[r];
arr[r] = tmp;
return i;
}
2.2、性能分析
- 因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6, 8, 7, 6, 3, 5, 9, 4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是稳定的排序算法。
- 按照上面的第二种分区方式,快速排序只涉及交换操作,所以空间复杂度为 Q(1),是原地排序算法。
- 时间复杂度为 Q(nlogn),最差为Q(n²)。
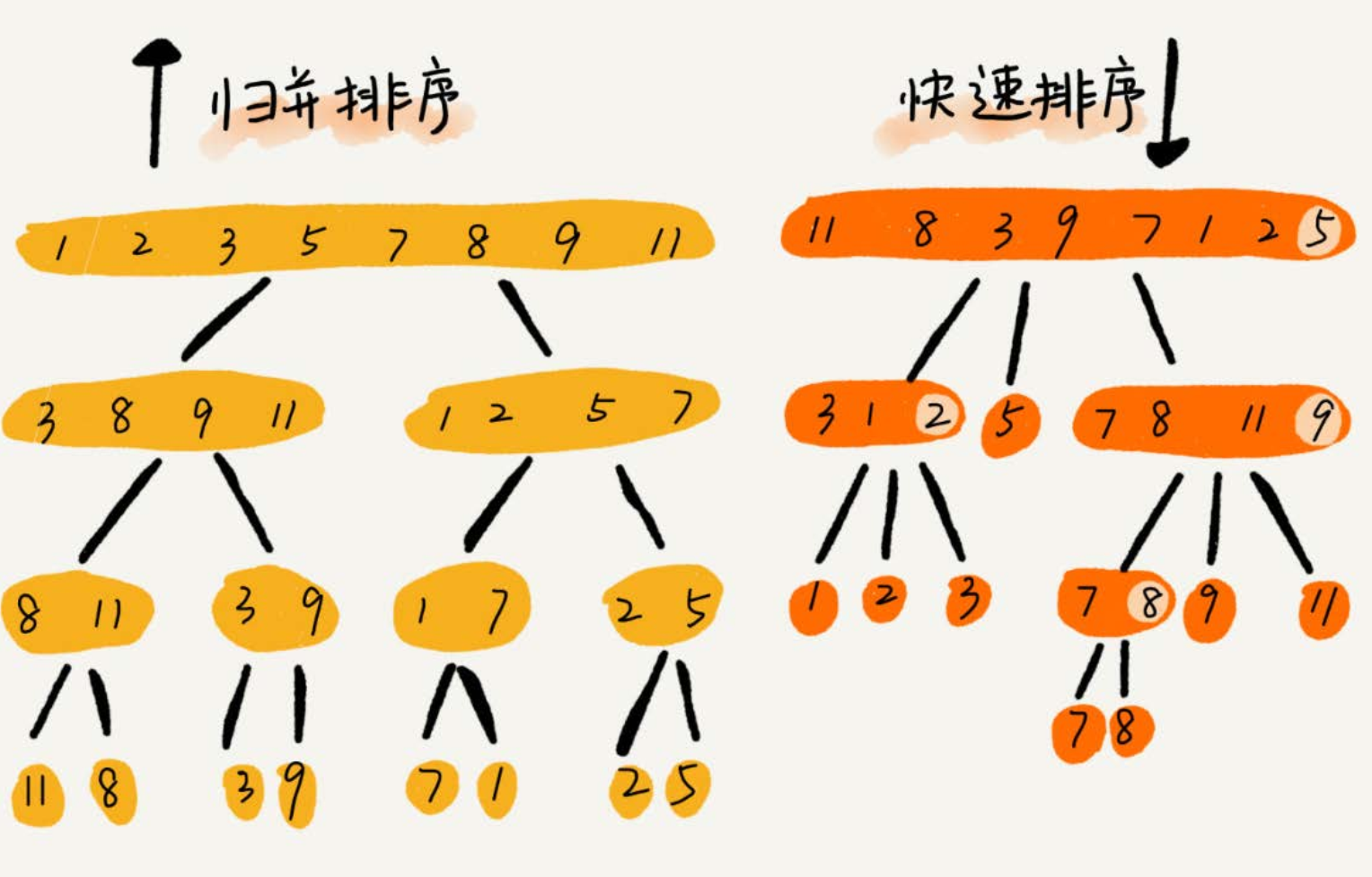
三、两者对比
| 归并排序 | 快速排序 | |
|---|---|---|
| 排序思想 | 处理过程由下到上,先处理子问题,然后在合并 | 由上到下,先分区,在处理子问题 |
| 稳定性 | 是 | 否 |
| 空间复杂度 | Q(n) | Q(1) 原地排序算法 |
| 时间复杂度 | 都为 O(nlogn) | 平均为 O(nlogn),最差为 O(n²) |
- 归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
- 归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
四、归并排序 && 快速排序的更多相关文章
- 程序员必知的8大排序(四)-------归并排序,基数排序(java实现)
程序员必知的8大排序(一)-------直接插入排序,希尔排序(java实现) 程序员必知的8大排序(二)-------简单选择排序,堆排序(java实现) 程序员必知的8大排序(三)-------冒 ...
- php基础排序算法 冒泡排序 选择排序 插入排序 归并排序 快速排序
<?php$arr=array(12,25,56,1,75,13,58,99,22);//冒泡排序function sortnum($arr){ $num=count($arr); ...
- 归并排序 & 快速排序
归并排序 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用. 将已有序的子序列合并,得到完全有序的序列:即先使每个子序列有 ...
- 排序算法四:快速排序(Quicksort)
快速排序(Quicksort),因其排序之快而得名,虽然Ta的平均时间复杂度也是O(nlgn),但是从后续仿真结果看,TA要比归并排序和堆排序都要快. 快速排序也用到了分治思想. (一)算法实现 pr ...
- 八大排序算法的python实现(四)快速排序
代码: #coding:utf-8 #author:徐卜灵 #交换排序.快速排序 # 虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤.因此我的对快速排序作了进一步的说明: ...
- 排序算法总结(四)快速排序【QUICK SORT】
感觉自己这几篇都是主要参考的Wikipedia上的,快排就更加是了....wiki上的快排挺清晰并且容易理解的,需要注意的地方我也添加上了注释,大家可以直接看代码.需要注意的是,wikipedia上快 ...
- 数据结构(四十四)交换排序(1.冒泡排序(O(n²))2.快速排序(O(nlogn))))
一.交换排序的定义 利用交换数据元素的位置进行排序的方法称为交换排序.常用的交换排序方法有冒泡排序和快速排序算法.快速排序算法是一种分区交换排序算法. 二.冒泡排序 1.冒泡排序的定义 冒泡排序(Bu ...
- MIT算法导论——第四讲.Quicksort
本栏目(Algorithms)下MIT算法导论专题是个人对网易公开课MIT算法导论的学习心得与笔记.所有内容均来自MIT公开课Introduction to Algorithms中Charles E. ...
- 程序员必知的8大排序(三)-------冒泡排序,快速排序(java实现)
程序员必知的8大排序(一)-------直接插入排序,希尔排序(java实现) 程序员必知的8大排序(二)-------简单选择排序,堆排序(java实现) 程序员必知的8大排序(三)-------冒 ...
随机推荐
- (Python基础教程之十二)Python读写CSV文件
Python基础教程 在SublimeEditor中配置Python环境 Python代码中添加注释 Python中的变量的使用 Python中的数据类型 Python中的关键字 Python字符串操 ...
- js 延迟加载的几种方法
1. defer 属性HTML 4.01 为 <script>标签定义了 defer属性. 用途:表明脚本在执行时不会影响页面的构造.也就是说,脚本会被延迟到整个页面都解析完毕之后再执行. ...
- React:JSX 深入
React入门的的时候,我们(我自己啦)喜欢都跟着例子来,用标签的语法写JSX,比如:<Mycomponent key={this.props.id} onClick={this.props ...
- vue 基于elment UI tree 组件实现带引导、提示线
实现样式 准备工作,先实现 树状组件的基本样式 <span style="height:500px; display:block; overflow-y:auto;" cla ...
- 获取MP4媒体文件时长
由于之前上传MP4文件没有保存视频时长,现在有需要,所以只好写代码读取时长.找了几个发现是 c/c++ 实现,或者是借助 FFmpeg 实现. 一个偶然在 GitHub 上面发现一个 c 文件,由于获 ...
- PIC16F887的LCD
RS RA5 RW RA4 RD RA3 将引脚设置为输出的时候要对ANS5 ANS4 ANS3 设置为0
- 【C++】常见易犯错误之数值类型取值溢出与截断(1)
1. 数据类型数值范围溢出 如标题所述,该错误出现的原因是由于变量的值超出该数据类型取值范围而导致的错误. 例题如下: (IDE环境:C-Free,编译器为mingw5,如下图) # include ...
- MRCTF 2020 WP
MRCTF 2020 WP 引言 周末趁上课之余,做了一下北邮的CTF,这里记录一下做出来的几题的WP ez_bypass 知识点:MD5强类型比较,is_numeric()函数绕过 题目源码: I ...
- Java IO(十五)FilterReader 和 FilterWriter、FilterReader 子类 PushBackReader
Java IO(十五)FilterReader 和 FilterWriter.FilterReader 子类PushBackReader 一.介绍 FilterReader 和 FilterWrite ...
- for循环结构的使用
/* for循环格式: for(①初始化条件; ②循环条件 :③迭代部分){ //④循环体 } 执行顺序:①-②-④-③---②-④-③-----直至循环条件不满足 退出当前循环 * */ publi ...