搭建Hadoop的全分布模式
此教程仅供参考
注意:此文档目的是为了本人方便以后复习,不适合当教程,以免误导萌新...
1、安装三台Linux
2、在每台机器上安装JDK
3、配置每台机器的免密码登录
(*) 生成每台机器的公钥和私钥
hadoop112: ssh-keygen -t rsa
hadoop113: ssh-keygen -t rsa
hadoop114: ssh-keygen -t rsa
(*) 把hadoop112的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
(*) 把hadoop113的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
(*) 把hadoop114的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
4、在主节点(hadoop112)配置Hadoop
(*) 加压: tar -zxvf hadoop-2.4.1.tar.gz -C ~/training/
(*) 设置环境变量方式1
vi ~/.bash_profile
HADOOP_HOME=/opt/hadoop-2.6.4
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效
source ~/.bash_profile
设置环境变量方式2
vi /etc/profile
HADOOP_HOME=/opt/hadoop-2.6.4
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效ii
source /etc/profile
(*) 修改配置文件
(1)hadoop-env.sh
第25行: export JAVA_HOME=/opt/modules/jdk1.8.0_91

(2) hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
(3) core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.8.101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.4/tmp</value>
</property>
(4) mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5) yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.8.101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(6) slaves 从节点
192.168.8.101
192.168.8.102
192.168.8.103
(*) 进行格式化
hdfs namenode -format
出现日志:说明格式化成功
Storage directory /root/training/hadoop-2.4.1/tmp/dfs/name has been successfully formatted.
(*) 把配置好的Hadoop(112机器上),拷贝到101,102,103上
scp -r /opt/hadoop-2.6.4/ root@192.168.80.101:/opt
scp -r hadoop-2.4.1/ root@192.168.80.102:/root/training
scp -r hadoop-2.4.1/ root@192.168.80.103:/root/training
5、 修改101,102和103的环境变量
vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.4.1
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效
source ~/.bash_profile
环境变量配置方式2也可以
6、在主节点上(hadoop100)启动hadoop集群
start-dfs.sh

start-yarn.sh

只能在主节点上启动yarn,否则会报错!
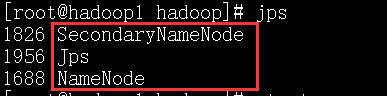
上面的图是主节点的截图.
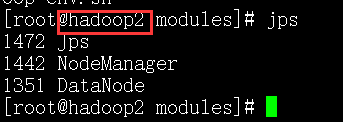
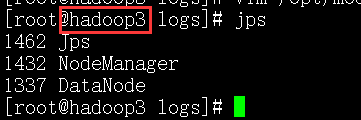
下面的是从节点的截图.
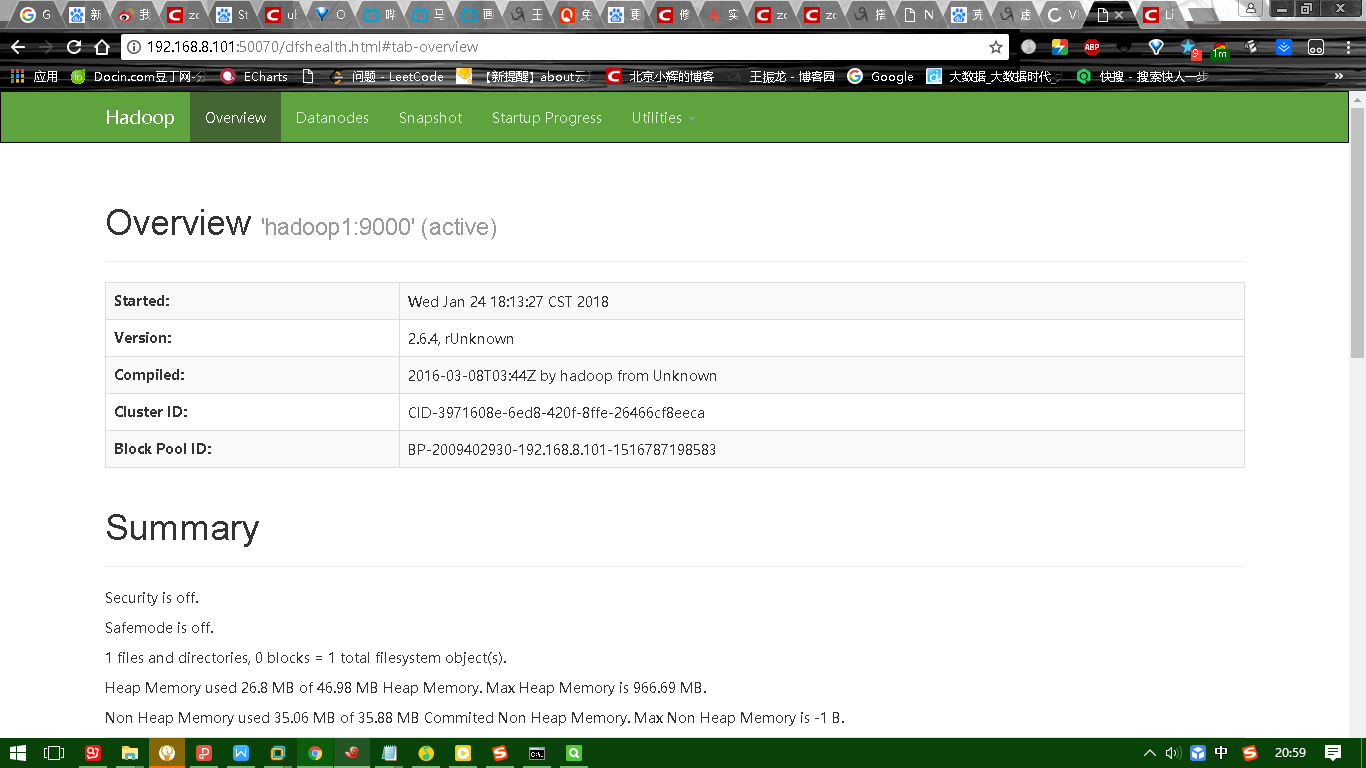
下图是HDFS的UI界面:
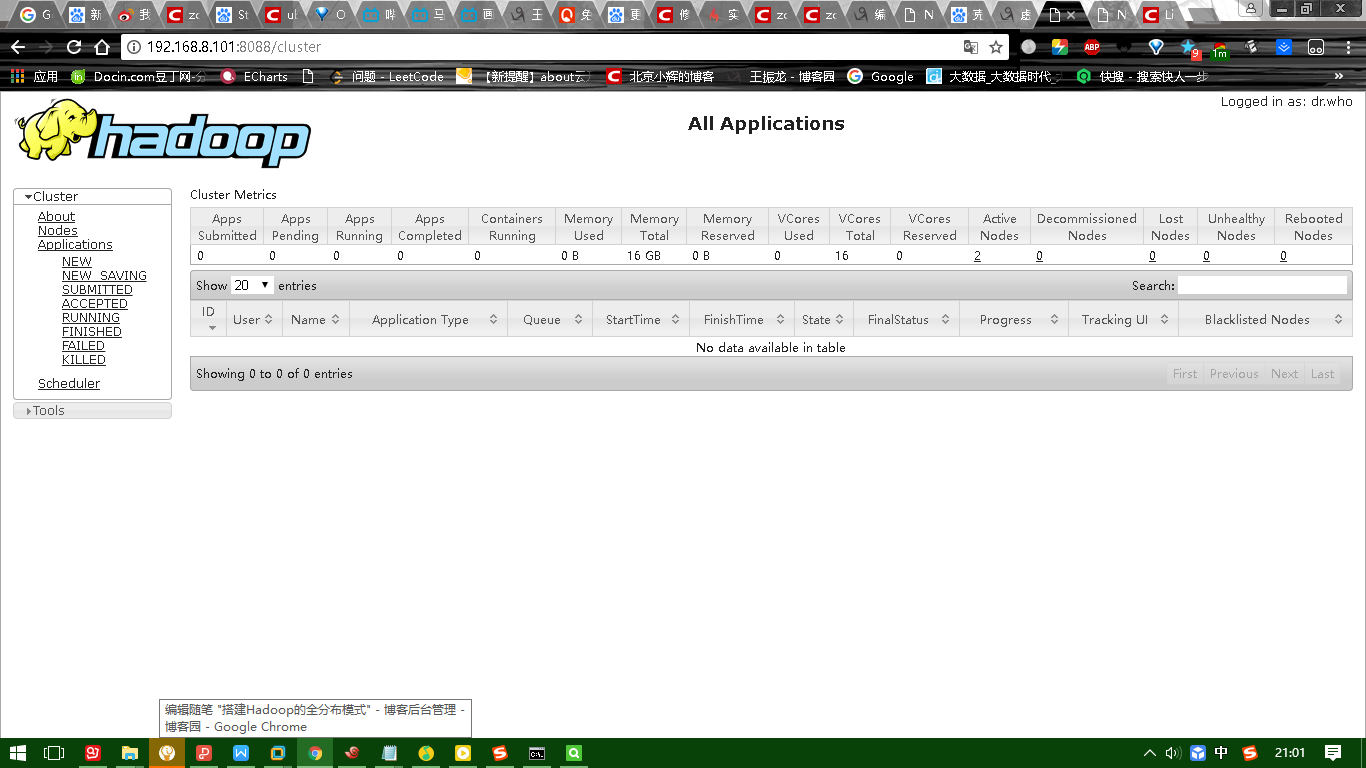
下图是yarn的UI界面:
7、日志:
Starting namenodes on [192.168.137.112]
192.168.137.112: starting namenode
192.168.137.113: starting datanode
192.168.137.114: starting datanode
starting resourcemanager
192.168.137.113: starting nodemanager
192.168.137.114: starting nodemanager
8、进程信息:
主节点: hadoop111
19589 ResourceManager
19458 SecondaryNameNode
19288 NameNode
从节点1:hadoop113
19220 NodeManager
19121 DataNode
从节点2:hadoop114
14159 NodeManager
13739 DataNode
9、错误:
org.apache.hadoop.hdfs.server.protocol.DisallowedDatanodeException: Datanode denied communication with namenode because hostname cannot be resolved
10、配置主机名(hadoop112 hadoop113 hadoop114)
vi /etc/hosts
192.168.8.101 Dog
192.168.8.102 Pig
192.168.8.103 Cat
11、web console:
HDFS: http://192.168.137.112:50070
Yarn: http://192.168.137.112:8088/
二、小结:HDFS和MapReducer
(一)什么是大数据?
(*) 天气预报
(*) 商品推荐
(*) 问题:(1)如何存储?如何找到? ----> 分布式的文件系统
(2)如何计算? ----> PageRank ---> MapReduce
(二)数据仓库:就是一个数据库,一般只做查询
(三)OLTP和OLAP
OLTP: online transaction processing
OLAP: online analyse processing
(四)Google的三篇论文
(1) GFS
(2) PageRank
(3) Bigtable ---> HBase
(五)搭建环境
(1) 本地模式:不具备HDFS的功能,只能测试MapReduce程序
(2) 伪分布模式:具备Hadoop的所有功能,在一台机器模拟分布式的环境
(3) 全分布模式:三台机器,具备Hadoop的所有功能
(六)HDFS
(1) 操作:命令行,JAVA API,Web Console(端口:50070)
(2) 上传数据和下载数据过程
(3) NameNode: 接收客户端请求
维护文件的元信息,默认在内存中,保存1000M的元信息
DataNode: 数据节点
SeondaryNameNode: 第二名称节点,元信息的合并(edits和fsimage)
(4) edits文件:日志文件,记录了客户端操作
使用edits viewer查看 hdfs oev *****
(5) fsimage文件:HDFS中文件的元信息文件
使用image viewer查看 hdfs ofv
(6) 高级特性:回收站(时间) ----> Oracle数据库的回收站 drop table---> 闪回 flashback
快照
配额:名称配额,空间配额
权限: 4种方式
安全模式:HDFS只读,检查数据块的副本率(0.999)
(7) RPC和动态代理(包装设计模式,增强方法的功能---> Proxy类)
(七)MapReduce(Yarn)
(1) ResourceManager:分配任务和资源
NodeManager:从DataNode获取数据(就近原则),执行任务
(2)Yarn调度任务的过程
(3) WordCount:(*)数据的流动
(*)Mapper Reducer Job
(4)序列化:WritableComparable,写的顺序和读的顺序一样
(5)排序:按照Key2排序、自然排序(LongWritable.Compartor)
多个列排序
对象排序(WritableComparable)
(6)合并Combiner:谨慎使用,不能改变原来的逻辑,是一种特殊的Reducer
(7)分区Parition
(8)Shuffle过程
(9)案例:(*)数据去重
(*)单表关联(自连接)
(*)多表关联(等值连接)
(*)倒排索引(Combiner不能改变原来的逻辑)
搭建Hadoop的全分布模式的更多相关文章
- hadoop备战:一台x86计算机搭建hadoop的全分布式集群
主要的软硬件配置: x86台式机,window7 64位系统 vb虚拟机(x86的台式机至少是4G内存,才干开3台虚机) centos6.4操作系统 hadoop-1.1.2.tar.gz jdk- ...
- Hadoop 全分布模式 平台搭建
现将博客搬家至CSDN,博主改去CSDN玩玩~ 传送门:http://blog.csdn.net/sinat_28177969/article/details/54138163 Ps:主要答疑区在本帖 ...
- 【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
阅读目录 ~/.ssh/authorized_keys 把公钥加到用于认证的公钥文件中,authorized_keys是用于认证的公钥文件 方式2: (未测试,应该可用) 基于空口令创建新的SSH密钥 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
- Linux环境搭建Hadoop伪分布模式
Hadoop有三种分布模式:单机模式.伪分布.全分布模式,相比于其他两种,伪分布是最适合初学者开发学习使用的,可以了解Hadoop的运行原理,是最好的选择.接下来,就开始部署环境. 首先要安装好Lin ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop概念学习系列之再谈hadoop集群里的本地模式、伪分布模式和全分布模式(三十七)
能看懂博主我此博文,相信你已经有了一定基础了. 对于本地模式.伪分布模式和全分布模式的概念,这里,我不多赘述.太多资料和博客,随便在网上一搜就好. 比如<hadoop实战 第二版>陆嘉恒老 ...
随机推荐
- HDU 4175 Class Schedule (暴力+一点dp)
pid=4175">HDU 4175 题意:有C座楼,每座楼有T个教室.一个人须要訪问C个教室.每座楼仅仅能訪问一个教室. 訪问教室须要消耗能量,从x点走到y点须要消耗abs(x-y) ...
- 题目1437:To Fill or Not to Fill(贪心算法)
题目描写叙述: With highways available, driving a car from Hangzhou to any other city is easy. But since th ...
- ORACLE 索引批量重建
按用户批量重建索引: 按用户将此用户下面非临时表上面的索引全部重建,此过程建议在SYS用户下面执行: CREATE OR REPLACE PROCEDURE BATCH_REBUILD_INDEX(U ...
- Ubuntu 18.04 关闭GUI
在安装显卡驱动时, 可能需要关闭GUI, 在终端中输入: sudo service gdm3 stop
- SharePoint 网站中定义的页面背景图片不起作用
If you are working on custom SharePoint 2013 master pages, designs and/or CSS, these little CSS clas ...
- 乌班图 之 设置镜像服务器 、设置屏幕分辨率QAQ
设置镜像服务器 Ubuntu 中的大部分软件安装都是用apt命令,从Ubuntu的服务器上直接安装的. 但是国外你懂的网速是硬伤,因此要搞个镜像服务器,内容当然都是一样的咯. 第一步:进入系统设置 第 ...
- 解码URLDecode和编码URLEnCode
在前台往后台传递参数的时候,在前台进行编码,在后台接收参数的时候,用Decode进行解码: 如果url中包含特殊字符如:&.html标签 <tr><td>等导致url无 ...
- HDU 4190 Distributing Ballot Boxes【二分答案】
题意:给出n个城市,n个城市分别的居民,m个盒子,为了让每个人都投上票,问每个盒子应该装多少张票 二分盒子装的票数, 如果mid<=m,说明偏大了,r应该向下逼近 ,r=mid 如果mid> ...
- 使用dispatch_group来进行线程同步
我的上篇文章iOS中多个网络请求的同步问题总结中用到了dispatch_group来进行线程同步,对用法不是特别熟悉所以整理这篇文章来加深记忆(闲着也是闲着). 一.简单介绍下将会用到的一些东西 英语 ...
- Centos 7 iptables 开放端口
MySQL 开放远程连接时, 已经打开了对应端口的安全组发现还是连接不上, 那么就需要 check 一下防火墙端口是否开放. firewall-cmd --zone=public --query-po ...