Hadoop之集群搭建
准备
- 需要准备多台主机(已经安装并且配置好hadoop和jdk)
- 需要配置ssh免密服务
下面我们开始进行配置,拿到已经准备好的主机,主机名分别为:
- centos101
- centos102
- centos103
先说下为什么需要进行ssh免密码配置:
我们在操作集群时,经常需要在各台主机上进行数据传输、主机切换等工作,如果直接进行切换等操作需要每次输入密码,当操作频繁
时,就显得很复杂,所以需要配置ssh免密码,让主机间自动检验账号密码。
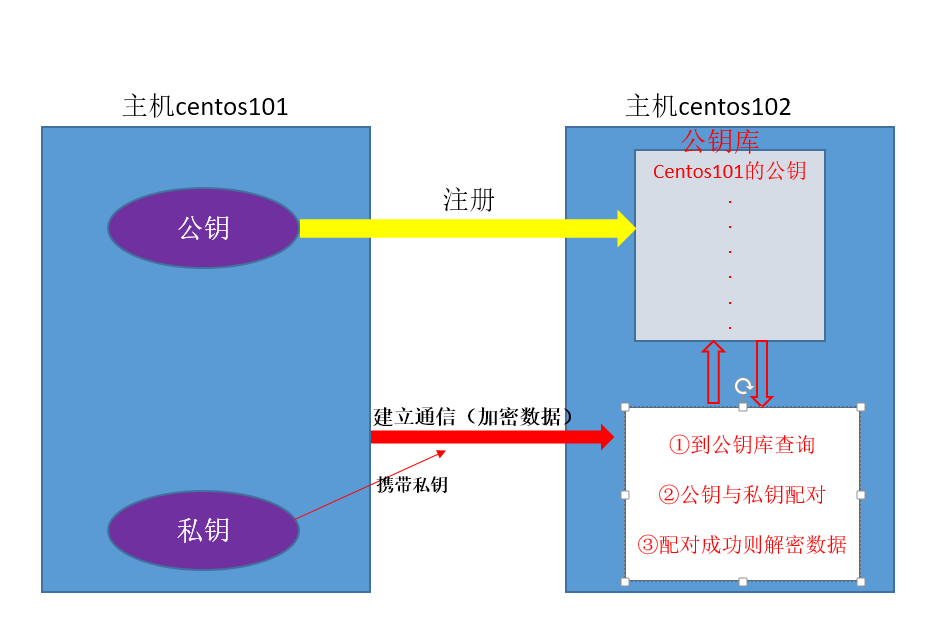
主机间进行ssh通信的原理图
配置ssh免密
①在主机centos101上访问其它主机,保证有访问记录,访问记录存在 /home/ljm/.ssh下的known_hosts文件中
用命令:ssh 主机 访问过的记录都在该文件中
②生成密钥,产生本台主机的公钥和私钥
命令:ssh-keygen -t rsa , 一直回车 生成了三个新文件
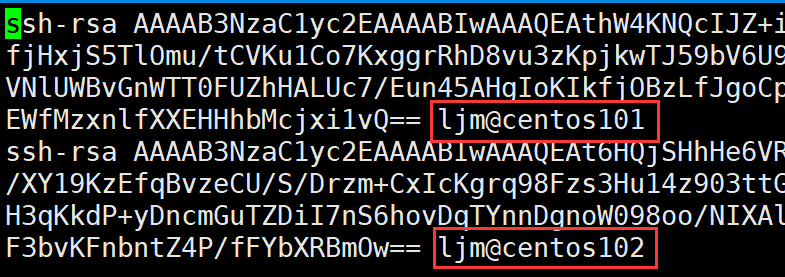
- authorized_keys:保存已经注册过的主机(即把公钥备份到本机的其它主机)
- id_rsa :私钥
- id_rsa.pub : 公钥

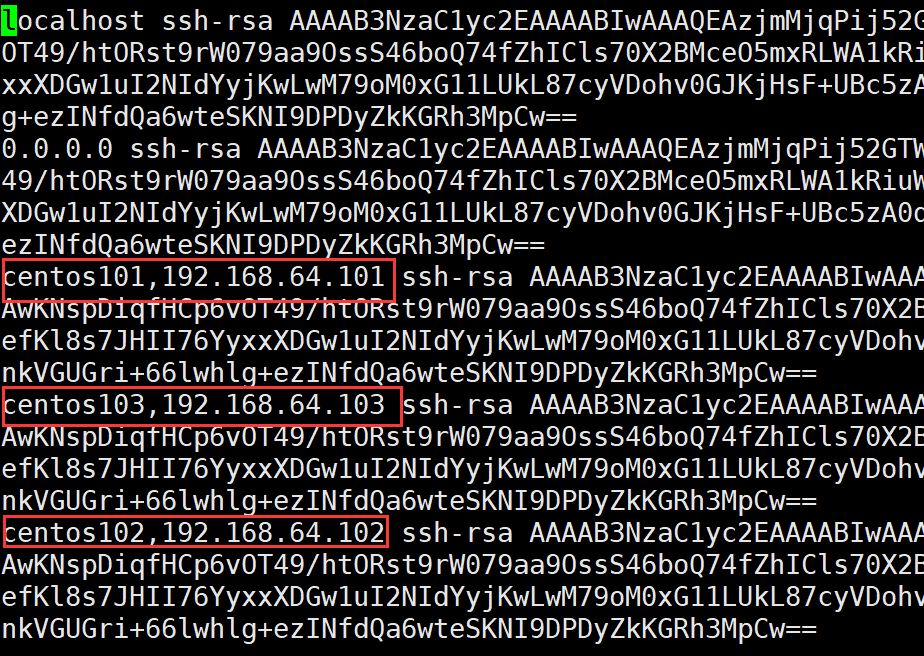
③将公钥复制到其它主机,复制时按照known_hosts中访问记录进行自动复制,复制后保存在其他主机的authorized_keys文件中
命令: ssh-copy-id 主机
以下是centos103主机的authorized_keys文件,可以看出centos101和centos102对它注册过
到这里已经完成了centos101对centos102和cenot103的免密配置了
注意:
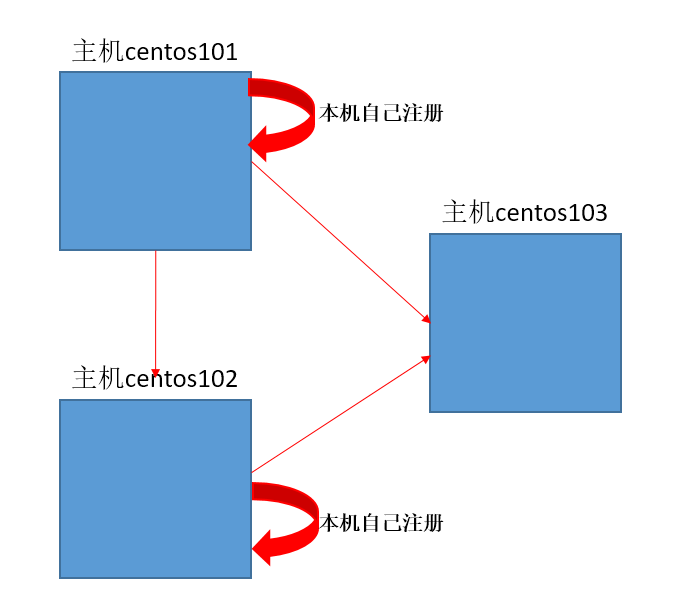
①本主机也要对本主机注册,简单说,就是哪里需要免密就配置到哪里
②同一台主机上的不同用户配置不同(如user用户配置了ssh免密,root用户并没有权利使用它的配置)
③两台主机间只要一方往另一方配置了,双方便可以相互免密访问
我三台主机的ssh配置结构如下:
配置hadoop集群
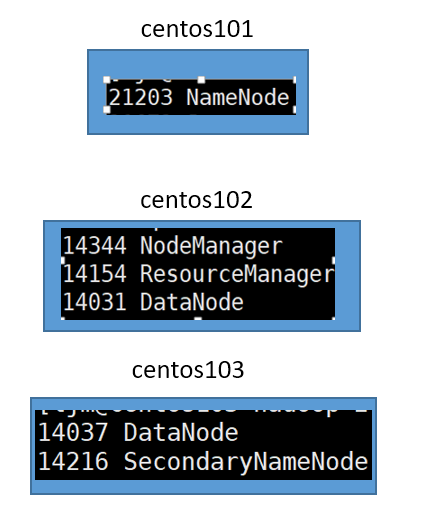
我的集群结构图:
基本配置文件(这些配置在hadoop根目录/etc/hadoop下):
- core-site.xml配置
- HDFS配置(hadoop-env.sh hdfs-site.xml slaves)
- YARN配置 (yarn-env.sh yarn-site.xml)
- MapReduce配置(mapred-env.sh mapred-site.xml)
①配置core-site.xml
每台主机都需要配置该文件,内容如下:
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos101:8020</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value> //缓存目录
</property>
</configuration>
②HDFS配置
每台主机都配置 hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置hdfs-site.xml,其它主机清空<configuration></configuration>中内容
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos103:50090</value>
</property>
</configuration>
只有主机centos101配置slaves,该文件默认localhost,centos101中slaves指定生成子节点datanode的主机
注意:格式要求严格,有空格都会导致出错
centos102
centos103
③YARN配置
每台主机都配置 yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置yarn-site.xml,其它主机清空<configuration></configuration>中内容
注意:yarn.resourcemanager.hostname指的是生成resourcemanager的节点主机,启动resourcemanager时必须在指定的主机启动
例如下面的配置,只能在主机centos102上启动resourcemanager
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos102</value>
</property>
</configuration>
④MapReduce的配置
每台主机都配置 mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置mapred-site.xml,其它主机清空<configuration></configuration>中内容
注意:mapred-site.xml并没有,需要将mapred-site-template.xml改为mapred-site.xml再进行配置
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
到这里,一个简单的集群已经配置好了,下面去启动集群吧!
启动集群
①将每台主机上的缓存文件夹和logs文件删除,我的配置中为 : /opt/module/hadoop-2.7.2/data/tmp
②初始化主节点centos101,命令:bin/hdfs namenode -format
③主节点上开启HDFS 命令:sbin/start-dfs.sh
④在指定生成resourcemanager的节点主机上,开启YARN 命令: sbin/start-yarn.sh
⑤用jps到每台主机上查看是否启动成功
Hadoop之集群搭建的更多相关文章
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop+HBase 集群搭建
Hadoop+HBase 集群搭建 1. 环境准备 说明:本次集群搭建使用系统版本Centos 7.5 ,软件版本 V3.1.1. 1.1 配置说明 本次集群搭建共三台机器,具体说明下: 主机名 IP ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- hadoop+spark集群搭建
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- hadoop+eclipse集群搭建及测试
前段时间搭了下hadoop,每次都会碰到很多问题,也没整理过,每次搜索都麻烦,现在整理下 一.准备工作 1.准备俩计算机,安装linux系统,分别装好jdk(虚拟机操作一样) nano /etc/ho ...
随机推荐
- Global.asax文件
转载:http://www.cnblogs.com/I-am-Betty/archive/2010/09/06/1819558.html 概述: Global.asax文件也叫做asp.net应用程序 ...
- 108、如何使用 Secret? (Swarm15)
参考https://www.cnblogs.com/CloudMan6/p/8068057.html 我们经常要想容器传递敏感信息,最常见的就是密码.比如: docker run -e MYS ...
- GO语言(golang)官方网站!
GO语言官方网站,在上面可以查看所有API文档.使用在线工具编写程序,你可以去看看!! https://golang.org/
- 解决跨域问题,前端 live-server --port=1802 后端启动 localhost:1801,以及解决 vue 的 axios 请求整合
测试的源码文件内容点击跳转 前端引入 vue.js 与 axios.min.js <script src="https://cdn.bootcss.com/vue/2.6.10/vue ...
- Nginx实用整理
1. nginx 简述 1.1Nginx是轻量级高并发HTTP服务器和反向代理服务器:同时也是一个IMAP.POP3.SMTP代理服务器:Nginx可以作为一个HTTP服务器进行网站的发布处理,另外N ...
- SVN 安装教程
安装包:http://pan.baidu.com/s/1kTTcbJp 安装步骤看这个博主的就好了: http://www.cnblogs.com/xing901022/p/4399382.html ...
- Balancing Act POJ - 1655 (树的重心)
Consider a tree T with N (1 <= N <= 20,000) nodes numbered 1...N. Deleting any node from the t ...
- 【HEOI2015】小Z的房间
题意 https://www.luogu.org/problemnew/show/P4111 题解 前置知识:矩阵树定理 不要问证明,我不会,用就完事了(反正一般也不会用到) 因为矩阵树定理就是求一张 ...
- mysql和oracle的语法差异(网络收集)
oracle没有offet,limit,在mysql中我们用它们来控制显示的行数,最多的是分页了.oracle要分页的话,要换成rownum. oracle建表时,没有auto_increment,所 ...
- nmap脚本(nse)使用总结
nmap脚本主要分为以下几类,在扫描时可根据需要设置--script=类别这种方式进行比较笼统的扫描: auth: 负责处理鉴权证书(绕开鉴权)的脚本 broadcast: 在局域网内探查更多服务 ...