基于OpenMP的矩阵乘法实现及效率提升分析
一. 矩阵乘法串行实现
例子选择两个1024*1024的矩阵相乘,根据矩阵乘法运算得到运算结果。其中,两个矩阵中的数为double类型,初值由随机数函数产生。代码如下:
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
#include <time.h>
#include <stdlib.h> using namespace std; #define MatrixOrder 1024
#define FactorIntToDouble 1.1; //使用rand()函数产生int型随机数,将其乘以因子转化为double型; double firstParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double secondParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double matrixMultiResult [MatrixOrder] [MatrixOrder] = {0.0}; //计算matrixMultiResult[row][col]
double calcuPartOfMatrixMulti(int row,int col)
{
double resultValue = ;
for(int transNumber = ; transNumber < MatrixOrder ; transNumber++) {
resultValue += firstParaMatrix [row] [transNumber] * secondParaMatrix [transNumber] [col] ;
}
return resultValue;
} /* * * * * * * * * * * * * * * * * * * * * * * * *
* 使用随机数为乘数矩阵和被乘数矩阵赋double型初值 *
* * * * * * * * * * * * * * * * * * * * * * * * */
void matrixInit()
{
for(int row = ; row < MatrixOrder ; row++ ) {
for(int col = ; col < MatrixOrder ;col++){
srand(row+col);
firstParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
secondParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
}
}
} /* * * * * * * * * * * * * * * * * * * * * * *
* 实现矩阵相乘 *
* * * * * * * * * * * * * * * * * * * * * * * */
void matrixMulti()
{
for(int row = ; row < MatrixOrder ; row++){
for(int col = ; col < MatrixOrder ; col++){
matrixMultiResult [row] [col] = calcuPartOfMatrixMulti (row,col);
}
}
} int main()
{
matrixInit(); clock_t t1 = clock(); //开始计时;
matrixMulti();
clock_t t2 = clock(); //结束计时
cout<<"time: "<<t2-t1<<endl; system("pause"); return ;
}
二 矩阵乘法并行实现
使用#pragma omp parallel for为for循环添加并行,使用num_threads()函数指定并行线程数。
使用VS2010编译,需要先在项目属性中选择支持openmp,在头文件中包含<omp.h>即可使用openmp为矩阵乘法实现并行。
代码如下:
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
#include <time.h>
#include <stdlib.h> using namespace std; #define MatrixOrder 1024
#define FactorIntToDouble 1.1; //使用rand()函数产生int型随机数,将其乘以因子转化为double型; double firstParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double secondParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double matrixMultiResult [MatrixOrder] [MatrixOrder] = {0.0}; //计算matrixMultiResult[row][col]
double calcuPartOfMatrixMulti(int row,int col)
{
double resultValue = ;
for(int transNumber = ; transNumber < MatrixOrder ; transNumber++) {
resultValue += firstParaMatrix [row] [transNumber] * secondParaMatrix [transNumber] [col] ;
}
return resultValue;
} /* * * * * * * * * * * * * * * * * * * * * * * * *
* 使用随机数为乘数矩阵和被乘数矩阵赋double型初值 *
* * * * * * * * * * * * * * * * * * * * * * * * */
void matrixInit()
{
#pragma omp parallel for num_threads(64)
for(int row = ; row < MatrixOrder ; row++ ) {
for(int col = ; col < MatrixOrder ;col++){
srand(row+col);
firstParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
secondParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
}
}
//#pragma omp barrier
} /* * * * * * * * * * * * * * * * * * * * * * *
* 实现矩阵相乘 *
* * * * * * * * * * * * * * * * * * * * * * * */
void matrixMulti()
{ #pragma omp parallel for num_threads(64)
for(int row = ; row < MatrixOrder ; row++){
for(int col = ; col < MatrixOrder ; col++){
matrixMultiResult [row] [col] = calcuPartOfMatrixMulti (row,col);
}
}
//#pragma omp barrier
} int main()
{
matrixInit(); clock_t t1 = clock(); //开始计时;
matrixMulti();
clock_t t2 = clock(); //结束计时
cout<<"time: "<<t2-t1<<endl; system("pause"); return ;
}
三 效率对比
运行以上两种方法,对比程序运行时间。
当矩阵阶数为1024时,串行和并行中矩阵乘法耗费时间如下:
串行:

并行:

可看出,阶数为1024时并行花费的时间大约是串行的五分之一。
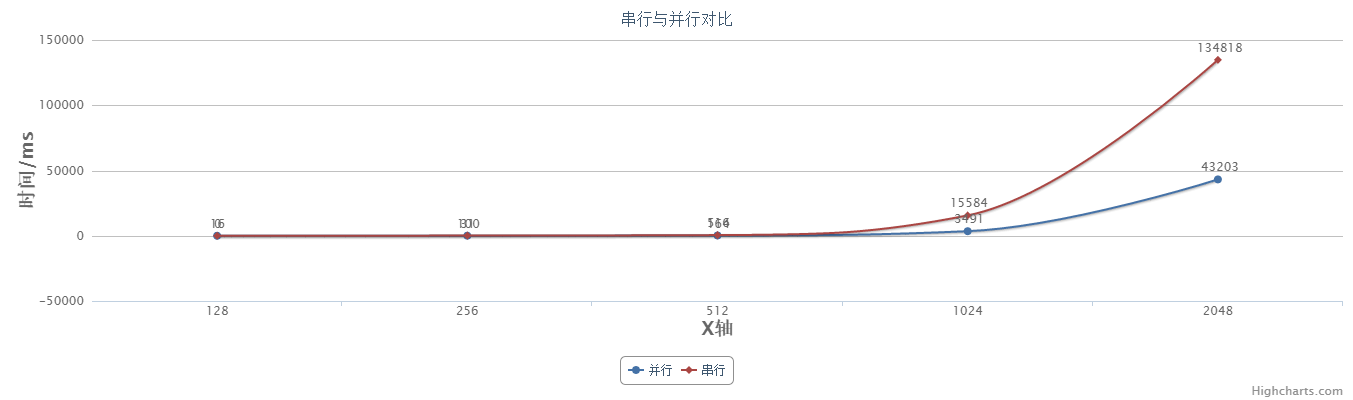
当改变矩阵阶数,并行和串行所花费时间如下:
|
128 |
256 |
512 |
1024 |
2048 |
|
|
并行 |
0 |
31 |
164 |
3491 |
43203 |
|
串行 |
16 |
100 |
516 |
15584 |
134818 |
画成折线图如下:
加速比曲线如下(将串行时间除以并行时间):

从以上图表可以看出当矩阵规模不大(阶数小于500)时,并行算法与串行算法差距不大,当阶数到达1000、2000时,差距就非常明显。而且,并非随着矩阵规模越大,加速比就会越大。在本机硬件条件下,并行线程数为64时,大约在1024附近会有较高加速比。
四 矩阵分块相乘并行算法
将矩阵乘法的计算转化为其各自分块矩阵相乘而后相加,能够有效减少乘数矩阵和被乘数矩阵调入内存的次数,可加快程序执行。
代码如下:
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
#include <time.h>
#include <stdlib.h> using namespace std; #define MatrixOrder 2048
#define FactorIntToDouble 1.1; //使用rand()函数产生int型随机数,将其乘以因子转化为double型; double firstParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double secondParaMatrix [MatrixOrder] [MatrixOrder] = {0.0};
double matrixMultiResult [MatrixOrder] [MatrixOrder] = {0.0}; /* * * * * * * * * * * * * * * * * * * * * * * * *
* 使用随机数为乘数矩阵和被乘数矩阵赋double型初值 *
* * * * * * * * * * * * * * * * * * * * * * * * */
void matrixInit()
{
//#pragma omp parallel for num_threads(64)
for(int row = ; row < MatrixOrder ; row++ ) {
for(int col = ; col < MatrixOrder ;col++){
srand(row+col);
firstParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
secondParaMatrix [row] [col] = ( rand() % ) * FactorIntToDouble;
}
}
//#pragma omp barrier
} void smallMatrixMult (int upperOfRow , int bottomOfRow ,
int leftOfCol , int rightOfCol ,
int transLeft ,int transRight )
{
int row=upperOfRow;
int col=leftOfCol;
int trans=transLeft; #pragma omp parallel for num_threads(64)
for(int row = upperOfRow ; row <= bottomOfRow ; row++){
for(int col = leftOfCol ; col < rightOfCol ; col++){
for(int trans = transLeft ; trans <= transRight ; trans++){
matrixMultiResult [row] [col] += firstParaMatrix [row] [trans] * secondParaMatrix [trans] [col] ;
}
}
}
//#pragma omp barrier
} /* * * * * * * * * * * * * * * * * * * * * * *
* 实现矩阵相乘 *
* * * * * * * * * * * * * * * * * * * * * * * */
void matrixMulti(int upperOfRow , int bottomOfRow ,
int leftOfCol , int rightOfCol ,
int transLeft ,int transRight )
{
if ( ( bottomOfRow - upperOfRow ) < )
smallMatrixMult ( upperOfRow , bottomOfRow ,
leftOfCol , rightOfCol ,
transLeft , transRight ); else
{
#pragma omp task
{
matrixMulti( upperOfRow , ( upperOfRow + bottomOfRow ) / ,
leftOfCol , ( leftOfCol + rightOfCol ) / ,
transLeft , ( transLeft + transRight ) / );
matrixMulti( upperOfRow , ( upperOfRow + bottomOfRow ) / ,
leftOfCol , ( leftOfCol + rightOfCol ) / ,
( transLeft + transRight ) / + , transRight );
} #pragma omp task
{
matrixMulti( upperOfRow , ( upperOfRow + bottomOfRow ) / ,
( leftOfCol + rightOfCol ) / + , rightOfCol ,
transLeft , ( transLeft + transRight ) / );
matrixMulti( upperOfRow , ( upperOfRow + bottomOfRow ) / ,
( leftOfCol + rightOfCol ) / + , rightOfCol ,
( transLeft + transRight ) / + , transRight );
} #pragma omp task
{
matrixMulti( ( upperOfRow + bottomOfRow ) / + , bottomOfRow ,
leftOfCol , ( leftOfCol + rightOfCol ) / ,
transLeft , ( transLeft + transRight ) / );
matrixMulti( ( upperOfRow + bottomOfRow ) / + , bottomOfRow ,
leftOfCol , ( leftOfCol + rightOfCol ) / ,
( transLeft + transRight ) / + , transRight );
} #pragma omp task
{
matrixMulti( ( upperOfRow + bottomOfRow ) / + , bottomOfRow ,
( leftOfCol + rightOfCol ) / + , rightOfCol ,
transLeft , ( transLeft + transRight ) / );
matrixMulti( ( upperOfRow + bottomOfRow ) / + , bottomOfRow ,
( leftOfCol + rightOfCol ) / + , rightOfCol ,
( transLeft + transRight ) / + , transRight );
} #pragma omp taskwait
}
} int main()
{
matrixInit(); clock_t t1 = clock(); //开始计时; //smallMatrixMult( 0 , MatrixOrder - 1 , 0 , MatrixOrder -1 , 0 , MatrixOrder -1 );
matrixMulti( , MatrixOrder - , , MatrixOrder - , , MatrixOrder - ); clock_t t2 = clock(); //结束计时
cout<<"time: "<<t2-t1<<endl; system("pause"); return ;
}
由于task是openmp 3.0版本支持的特性,尚不支持VS2010,2013,2015,支持的编译器包括GCC,PGI,INTEL等。
程序大致框架与前面并行算法区别不大,只是将计算的矩阵大小约定为512,大于512的矩阵就分块,直到小于512.具体大小可根据实际情况而定。
五 小结
本文首先实现基于串行算法的高阶矩阵相乘和基于OpenMP的并行算法的高阶矩阵相乘。接着,对比了128,256,512,1024,2049阶数下,两种算法的耗费时间,并通过表格和曲线图的形式直观表现时间的差别,发现,两种算法并非随着阶数的增大,加速比一直增大,具体原因应该和本机运行环境有关。最后,根据矩阵分块能有效减少数据加载进内存次数,完成了矩阵分块相乘并行算法的代码。考虑到编译环境的限制,未及时将结果运行出来。下一步可装linux虚拟机,使用gcc编译器得出算法的运行时间,进行进一步的分析对比。
基于OpenMP的矩阵乘法实现及效率提升分析的更多相关文章
- 基于MapReduce的矩阵乘法
参考:http://blog.csdn.net/xyilu/article/details/9066973文章 文字未得及得总结,明天再写文字,先贴代码 package matrix; import ...
- 【BZOJ-4386】Wycieczki DP + 矩阵乘法
4386: [POI2015]Wycieczki Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 197 Solved: 49[Submit][Sta ...
- 基于MPI的大规模矩阵乘法问题
转载请注明出处. /* Function:C++实现并行矩阵乘法; Time: 19/03/25; Writer:ZhiHong Cc; */ 运行方法:切到工程文件x64\Debug文件下,打开命令 ...
- [转]OpenBLAS项目与矩阵乘法优化
课程内容 OpenBLAS项目介绍 矩阵乘法优化算法 一步步调优实现 以下为公开课完整视频,共64分钟: 以下为公开课内容的文字及 PPT 整理. 雷锋网的朋友们大家好,我是张先轶,今天主要介绍一下我 ...
- OpenGL学习进程(12)第九课:矩阵乘法实现3D变换
本节是OpenGL学习的第九个课时,下面将详细介绍OpenGL的多种3D变换和如何操作矩阵堆栈. (1)3D变换: OpenGL中绘制3D世界的空间变换包括:模型变换.视图变换.投影变换和视口 ...
- 4-2.矩阵乘法的Strassen算法详解
题目描述 请编程实现矩阵乘法,并考虑当矩阵规模较大时的优化方法. 思路分析 根据wikipedia上的介绍:两个矩阵的乘法仅当第一个矩阵B的列数和另一个矩阵A的行数相等时才能定义.如A是m×n矩阵和B ...
- 2.3CUDA矩阵乘法
CPU 矩阵乘法 能相乘的两个矩阵,必须满足一个矩阵的行数和第二个矩阵的列数相同. A(N*P) * B(P*M) = C(N*M). 其中P是行数,N是列数, 从宽高的角度来说,即 A的宽度和B的高 ...
- poj3233之经典矩阵乘法
Matrix Power Series Time Limit: 3000MS Memory Limit: 131072K Total Submissions: 12346 Accepted: ...
- MapReduce实现矩阵乘法
简单回想一下矩阵乘法: 矩阵乘法要求左矩阵的列数与右矩阵的行数相等.m×n的矩阵A,与n×p的矩阵B相乘,结果为m×p的矩阵C.具体内容能够查看:矩阵乘法. 为了方便描写叙述,先进行如果: 矩阵A的行 ...
随机推荐
- Unieap3.5Java端通过SQL语句直接查询DataStore
通过sql查询dataStore 例子见 /mcss/src/com/neusoft/mcss/base/todo/dao/WorkTodoDaoImpl.java getWorksTodo() ID ...
- NC V6 安装目录各文件夹作用描述
ant:存放Apache Ant,用来执行EJB的构建. bin: 存放nc部署和系统监控等命令.configsys.log部署日志(包含NC中间件.WAS中间件等部署信息)以及NC_Client文件 ...
- DNS服务器:主要介绍DNS的服务原理以及安装及其主从配置
DNS服务器:主要介绍DNS的服务原理以及安装及其主从配置 一.DNS简介 1.DNS DNS是域名系统(Domain Name System)的简称,它是一个将域名和IP相互映射的分布式数据库 ...
- 无法运行maven项目
tomcat Server Location 选择 User Tomcat installation 设置CATALINA_HOME环境变量(tomcat start.bat启动不了)1.CATALI ...
- C#中List〈string〉和string[]数组之间的相互转换
1,从System.String[]转到List<System.String> System.String[] str={"str","string" ...
- c# 实现串口编程-操作LED屏幕
串口编程主要用到SerialPort这个类,主要实现对串口发送字节数组然后点阵屏显示相关信息,其实这个功能很简单下面给大家把整体思路用流程图展现如下:. 其实整体思路就如流程图.下面是整个流程图的一个 ...
- IIS安装错误导致网站访问不了
如下图,网站正常但就是访问不了,原因是IIS配置不正确,把ASP.NET4.5等相关勾选上就可以了,不要用默认的勾选,要自己手动勾选.
- C++primer 阅读点滴记录(三)
14章 操作符重载和转换 重载操作符是具有特殊名称的函数:保留字operator后接需要定义的操作符符号. 1.重载的操作符名: + – * / % ^ & | ~ ! , = < & ...
- [习题]日历(Calendar)控件的障眼法(.Visible属性),使用时才出现?不用就消失?
原文出處 http://www.dotblogs.com.tw/mis2000lab/archive/2013/09/02/calendar_icon_visible.aspx [习题]日历(Cal ...
- 访问svc 文件,编译器错误消息: CS0016,未能写入输出文件
编译错误 说明: 在编译向该请求提供服务所需资源的过程中出现错误.请检查下列特定错误详细信息并适当地修改源代码. 编译器错误消息: CS0016: 未 ...