map写数据到本地磁盘过程解析----spill和merge
如上次分析,其实map函数中的context.write()调用过程如下所示:

梳理下调用过程,context的write方法其实是调用了TaskInputOutputContext类的write方法,而在这个write方法内部又调用了output字段的write方法,这个output字段是NewOutputCollector类的一个对象,自然就回到了NewOutputCollector(reduce数量不是0)这个类的write方法,而这个方法内部又调用了本类的一个字段collector的collector方法,而collector字段是MapOutputBuffer类型,接下来就主要分析这两个类。
1)NewOutputCollector
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions;
在构造函数初始化这三个字段,collector初始化MapOutputBuffer的一个对象,partitions就是这次运行job的reduce数量,partitioner就是使用的分区器,利用partitioner对象的getPartitioner(K,V,partitions)就可以得到键值对对应的分区号,然后将这三个参数传给collector的collect方法。MapOutputBuffer才是重点,接下来对其分析。
2)MapOutputBuffer
map的结果并不是直接输入到硬盘的,而是先写入内存缓冲区,这个内存缓冲区是通过三个环形结构的数组组成的,这三个环形数组分别是kvoffsets,kvindices,kvbuffer。这个三个数组又有对应的指示器变量,首先给出三个的关系图:

kvoffsets和kvindices都是int[]型数组,而kvbuffer是byte[]类型。kvoffset数组中的一个元素就存储一个键值对对应的分区号在kvindices数组中的索引。而kvindices每次使用三个元素来一个键值对的先关信息:在kvbuffer中key的起始存储位置、在kvbuffer中value的起始存储位置、以及此键值对对应的分区号partition。而kvbuffer就负责存储键值对。需要注意的是,如上图所示,kvoffsets和kvindices存储信息的大小都是确定的,因为我们完全可以一个int型的正数存储索引值和分区号,但是kvbuffer中存储的key、value大小却不是确定的。所以我们在kvindices中只是存储了这些key、value的起始位置。我们不能发现,存储一个键值对会带来16个字节的额外开销(一个int型变量是4个字节),分别是kvoffsets中的1个int变量+kvindices中的3个int变量。
其实,这三个数组的大小是由"io.sort.mb"指定,默认io.sort.mb=100,也就是sortmb=100,那么有maxmemUsage=sortmb<<20,也就是100M。默认这100M中kvoffsets和kvindices占5M(由"io.sort.record.percent"指定,默认值是0.05)其中,kvoffsets与kvindices的比例是1:3(kvoffset中一个索引值对应kvindices中的三个元素)。
在kvbuffer中如果容量达到一个的比例就会触发spill(溢写)操作,这个比例由"io.sort.spill.percent"指定,默认值是0.8。同样的kvoffsets容量达到一定程度也会触发spill操作,也是由"io.sort.spill.percent"指定。那么为什么要达到一定的比例就spill,而不是写满在spill?原因很简单,如果是写满缓存才spill,那么在刷写磁盘的时候就不能写入(因为我要读取这个缓存区域,写之前“这块区域”就是归写线程所有,其他线程不能访问),那么写线程就会阻塞,map结果就要等待写入缓存,如果达到一定比例就spill,刷写磁盘的时候就只是缓存中一定比例的区域归写线程所有,其他的部分就可以通过写线程写入map的输出,提高了吞吐量。这样就又存在一个问题,如果写线程比spill的过程块,写线程的那块儿区域已经写满了,但是spill还没有完成,也要等待,虽然spill可能已经进行了一大半,spill区域的前半部分已经读取到磁盘。所以才把kvoffsets设计为逻辑上环形数组,写到末尾的时候通过查看下一个可写的位置(kvindex)来决定是否可以写入。如下图所示:
首先给出kvoffsets的相关变量:
kvoffsets:
private volatile int kvstart = 0; //表示当前已写的数据的开始位置
private volatile int kvend = 0; // 未执行spill是等于kvstart,执行spill是不等于kvstart(等于kvindex)
private int kvindex = 0; // 表示下一个可写的位置
private final int[] kvoffsets;
//volatile修改的字段表示此字段可以被不同线程访问和修改

kvbuffer:
private volatile int bufstart = 0; // marks beginning of spill
private volatile int bufend = 0; // marks beginning of collectable
private volatile int bufvoid = 0; // marks the point where we should stop
// reading at the end of the buffer
private int bufindex = 0; // marks end of collected
private int bufmark = 0; // marks end of record
private byte[] kvbuffer;
bufstart、bufend、bufindex与kvsetoffs中对应的变量意义是相同的,不过又增加了两个变量:bufvoid和bufmark。bufvoid表示实际使用的缓存的最尾部,由于键值对的大小是不确定的,所以使用bufmark来标记一个键值对的结束,每当写入一个键值对,就更新这个值。
map输出的键值对存入缓存之前要首先经过序列化,序列化之后此才存储到缓存中。因为我们是先将序列化的key存入缓存,再将序列化了的value存入缓存,这就存在一个问题:剩下的空间存不下key或者value。
a.如果说存不下value,就会抛出MapBufferTooSmallException异常(这就是触发spill,开始spill过程了)。
b.如果存不下key,那么就要采取措施了。上张图:
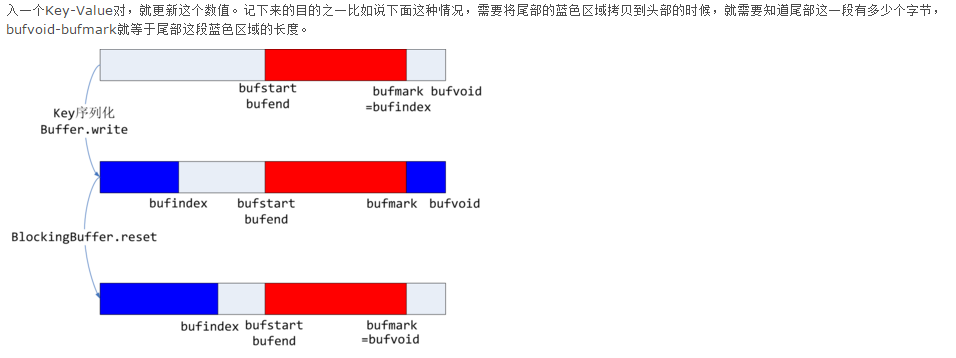
红色区域表示已经写入的键值对,第一个图中bufvoid-bufindex即使当前剩余的存储空间,而第二章图中的两块蓝色部分就是存入序列化的key所需要的空间,很明显key的存储跨越了缓存的尾端和首端,但是执行spill的之后我们需要使用RawComparator方法按照key对键值对排序,而这个方法只能对连续的二进制内存buffer进行排序,也就需要每个key都是连续存储的,因此就需要调用BlockingBuffer的reset方法尾端的蓝色部分移动到首端,此时更新bufvoid的值。
c.上面是情况是可以存下key,如果key存不下呢,那么就会直接输出key、value,也就是调用spill线程将键值对写入到文件(这就是触发了spill机制,开始spil了呀!)。
3)在spill之前需要将kvbuffer中的数据排序,先按照分区排序,在分区内再按照key排序,排序和spill的操作都是在MapOutputBuffer类中的sortAndSpill中进行的:
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
long size = (bufend >= bufstart
? bufend - bufstart
: (bufvoid - bufend) + bufstart) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename); final int endPosition = (kvend > kvstart)
? kvend
: kvoffsets.length + kvend;
sorter.sort(MapOutputBuffer.this, kvstart, endPosition, reporter);
int spindex = kvstart;
IndexRecord rec = new IndexRecord();
InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
writer = new Writer<K, V>(job, out, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < endPosition &&
kvindices[kvoffsets[spindex % kvoffsets.length]
+ PARTITION] == i) {
final int kvoff = kvoffsets[spindex % kvoffsets.length];
getVBytesForOffset(kvoff, value);
key.reset(kvbuffer, kvindices[kvoff + KEYSTART],
(kvindices[kvoff + VALSTART] -
kvindices[kvoff + KEYSTART]));
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < endPosition &&
kvindices[kvoffsets[spindex % kvoffsets.length]
+ PARTITION] == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
} // close the writer
writer.close(); // record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength();
rec.partLength = writer.getCompressedLength();
spillRec.putIndex(rec, i); writer = null;
} finally {
if (null != writer) writer.close();
}
} if (totalIndexCacheMemory >= INDEX_CACHE_MEMORY_LIMIT) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
}
}
其实排序事实上只是交换kvoffsets的值,比较对kvoffsets的排序比kvbuffer更快。上图:

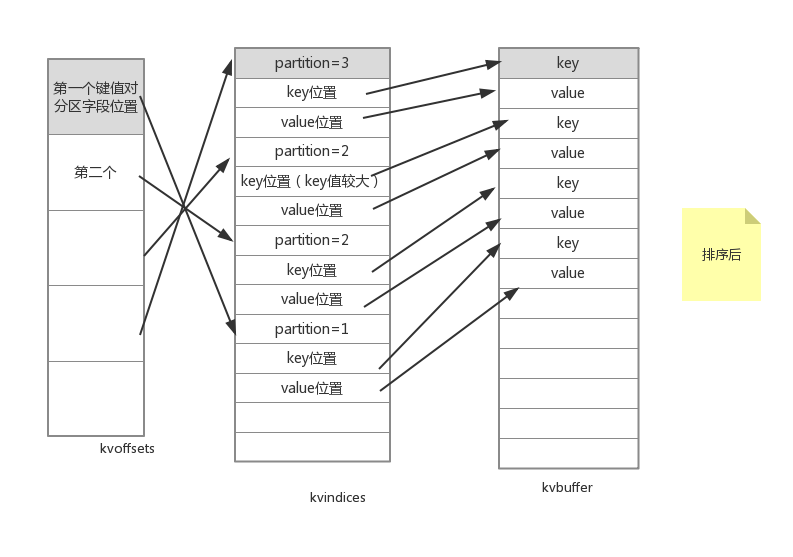
排序默认是升序。继续看代码:
for (int i = 0; i < partitions; ++i) {//循环访问各个分区
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
writer = new Writer<K, V>(job, out, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < endPosition &&
kvindices[kvoffsets[spindex % kvoffsets.length]
+ PARTITION] == i) {
final int kvoff = kvoffsets[spindex % kvoffsets.length];
getVBytesForOffset(kvoff, value);
key.reset(kvbuffer, kvindices[kvoff + KEYSTART],
(kvindices[kvoff + VALSTART] -
kvindices[kvoff + KEYSTART]));
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < endPosition &&
kvindices[kvoffsets[spindex % kvoffsets.length]
+ PARTITION] == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength();
rec.partLength = writer.getCompressedLength();
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
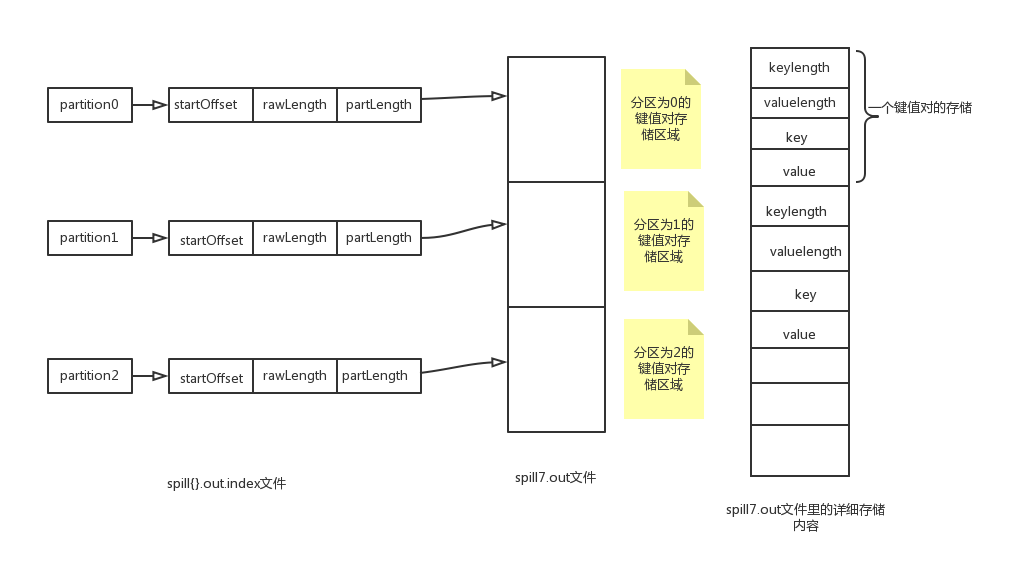
可以看出再排序完成之后,循环访问内存中的每个分区,如果没有定义combine的话就直接把这个分区的键值对spill写出到磁盘。spill文件的内容形式如下图所示:

可以看到,spill的文件就是分区的。先是分区顺序存储,在分区内又是按照key顺序存储。
但是,这又存在一个问题,那就是我怎么才能识别出这个spill文件中的各个分区呢?查看上述的42-45行代码:
rec.startOffset = segmentStart;
43 rec.rawLength = writer.getRawLength();
44 rec.partLength = writer.getCompressedLength();
45 spillRec.putIndex(rec, i);
而rec和spillRec的定义如下:
final SpillRecord spillRec = new SpillRecord(partitions);
IndexRecord rec = new IndexRecord();
IndexRecord有三个字段:
startOffset;//数据的起始位置,也就是一个分区的键值对的起始位置
rawLength;//数据原始长度
partLength;//数据压缩后的长度(采用压缩技术)
其实一个IndexRecord就对应一个分区内的键值对在spill文件的索引信息。
SpilRecord是以分区数量partitions作为初始化参数,很明显,SpillRecord的就是由一个个IndexRecord组成的,由上面第45行代码也可以看出。所以除了spill文件,我们还需要一个索引文件,这个索引文件的内容就是SpillRecord中的内容,索引文件格式是spill{$}.out.index,而spill的文件格式是spill{$}.out,l另外,虽然写完了spill文件之后,就会把SpillRecord的内如写入一个Spill索引文件,不过这个写不是写一个spill文件就对应写一个spill索引文件,而是超过了一个界限(1MB)再写index文件:
if (totalIndexCacheMemory >= INDEX_CACHE_MEMORY_LIMIT) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
而totalIndexCacheMemory和INDEX_CACHE_MEMORY_LIMIT的定义分别如下,均是MapOutputBuffer的字段:
private static final int INDEX_CACHE_MEMORY_LIMIT = 1024 * 1024;
private int totalIndexCacheMemory;
而MAP_OUTPUT_INDEX_RECORD_LENGTH和indexCacheList的定义如下:
private ArrayList<SpillRecord> indexCacheList;
private int MAP_OUTPUT_INDEX_RECORD_LENGTH=24;
不难看出,每次spill产生的索引信息存储在spillRec中,虽然没有创建每次spill文件对应的索引文件,但是将这个包含索引信息的对象添加到了indexCacheList中,这个对象是SpillRecord类型的容器,如果本次没有不创建索引文件,那么totalIndexCacheMemory就会被更新。
totalIndexCacheMemory += spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
最后的最后,当Map输入数据处理完毕之后,会调用flush方法将缓存中的数据刷写道磁盘。
spill文件和其索引文件的形式以及对应关系如下所示:
不过,一个map会产生很多的spill文件,当MapTask正常退出之前这些文件会被合并一个大out文件和一个大的index文件,如果想看到中间的spill文件就需要修改一些参数值:
io.sort.mb=;//用于存储map输出键值对的缓存,默认值是100(100M)
io.sort.spill.percent=0.1;//缓存spill的比例,默认是0.8.
//将以上两个参数修改之后就可以使map更多的spill数据到硬盘上,一个直观的效果就是spill的文件有很多。我们知道IO是很耗时间的,相当于“拖慢”了map的速度。
//另外,还有一个参数:
io.sort.factor=;//这个参数默认是10,表示执行合并spill文件的时候最多一次可以合并多少个spill文件,调下这个值可以看到合并的过程,也就是看到file.out(所有spill文件合并后的大文件)和spill.out并存
上图:

以下是spill文件的路径:


spill是mapreduce的中间结果,存储在数据节点的本地磁盘上,存储路径由以下参数指定:
hadoop.tmp.dir="/home/hadoop/HadoopData/tmp/";//这是hadoop的临时基础目录,很对目录都依赖它
mapred.local.dir=${hadoop.tmp.dir}/mapred/local;//这是默认值,也就是mapred的中间数据文件的存储目录。
最后要把所有的spill文件和index文件合并,合并之后就是这样:
3)Merge
Merge就是将多个spill文件合并成一个大的file.out文件,首先读取若干spill文件的内容到内存,然后对其排序,排序方法时多路归并排序,首先按照分区号排序,在按照key排序(默认是快排),归并过程简要描述如下:

以上就是map输出到磁盘的过程,这些中间文件(fiel.out,file.out.inde)将来是要等着Reducer取走的,不过并不是Reducer取走之后就删除的,因为Reducer可能会运行失败,在整个Job完成之后,JobTracker通知Mapper可以删除了才会将这些中间文件删掉.向硬盘中写数据的时机:
(1)当内存缓冲区不能容下一个太大的kv对时。spillSingleRecord方法。
(2)内存缓冲区已满时。SpillThread线程。
(3)Mapper的结果都已经collect了,需要对缓冲区做最后的清理。Flush方法。
感谢:
http://www.cnblogs.com/esingchan/p/3947156.html
http://zheming.wang/hadoop-mapreduce-zhi-xing-liu-cheng-xiang-jie.html
http://www.cnblogs.com/forfuture1978/archive/2010/11/19/1882279.html
map写数据到本地磁盘过程解析----spill和merge的更多相关文章
- hive将数据导致本地磁盘
hive -e "select * from wyp" >> local/wyp.txt 其中我更喜欢弄好临时表,然后交互式查询时让相关人员自己去按逻辑处理数据,最 ...
- 腾讯大数据之TDW计算引擎解析——Shuffle
转自 https://www.csdn.net/article/2014-05-19/2819831-TDW-Shuffle/1 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,T ...
- HDFS的写数据过程分析
HDFS的写数据过程分析 我们通过FileSystem类可以操控HDFS, 那我们就从这里开始分析写数据到HDFS的过程. 在我们向 HDFS 写文件的时候,调用的是 FileSystem.creat ...
- 【大数据】深入源码解析Map Reduce的架构
这几天学习了MapReduce,我参照资料,自己又画了两张MapReduce的架构图. 这里我根据架构图以及对应的源码,来解释一次分布式MapReduce的计算到底是怎么工作的. 话不多说,开始! ...
- flink---实时项目--day01--1. openrestry的安装 2. 使用nginx+lua将日志数据写入指定文件中 3. 使用flume将本地磁盘中的日志数据采集到的kafka中去
1. openrestry的安装 OpenResty = Nginx + Lua,是⼀一个增强的Nginx,可以编写lua脚本实现⾮非常灵活的逻辑 (1)安装开发库依赖 yum install -y ...
- Hbase写数据,存数据,读数据的详细过程
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多 ...
- HDFS源码解析:教你用HDFS客户端写数据
摘要:终于开始了这个很感兴趣但是一直觉得困难重重的源码解析工作,也算是一个好的开端. 本文分享自华为云社区<hdfs源码解析之客户端写数据>,作者: dayu_dls. 在我们客户端写数据 ...
- 【ElasticSearch】ES 读数据,写数据与搜索数据的过程
ES读数据的过程: 1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node): 2.corrdinating node 对 doc id 对哈希,找出该文档对应 ...
- Tomcat服务器如何读取本地磁盘数据?
实际问题: 如何让用户下载本地磁盘的资源文件呢? 在server.xml文件中配置虚拟路径如下(以下代码放在Host标签之中即可): 例如: 具体含义: 把本地磁盘目录 "D:\uploa ...
随机推荐
- Sqlserver面试题
1.用一条SQL语句 查询出每门课都大于80分的学生姓名 name kecheng fenshu 张三 语文 81张三 数学 75李四 语文 ...
- 设计模式功能概述(Design Patterns)
1.Abstract Factory:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类. 2.Adapter:将一个类的接口转换成客户希望的另一个接口.Adapter模式使得原本由于 ...
- [洛谷P1040] 加分二叉树
洛谷题目链接:加分二叉树 题目描述 设一个n个节点的二叉树tree的中序遍历为(1,2,3,-,n),其中数字1,2,3,-,n为节点编号.每个节点都有一个分数(均为正整数),记第i个节点的分数为di ...
- 将setter方法与itemClick: 进行类比
https://www.evernote.com/shard/s227/sh/a0c3afa3-8792-4756-8594-d2387a7f57ad/b561ff665af9ad401c8e ...
- MongoDB简介以及下载安装
什么是MongoDB ? MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统.运行稳定,性能高 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在 ...
- 【bzoj1042】硬币购物
容斥 #include<bits/stdc++.h> #define N 100005 typedef long long ll; using namespace std; ll ans, ...
- 带你入门代理模式/SpringAop的运行机制
SpringAop 是spring框架中最重要的一项功能之一,同时也是企业级开发记录事物日志等不可或缺的一部分,如果说你的系统需要记录用户访问接口的操作,那SpringAop是很完美的了,当然,拦截器 ...
- BZOJ 3098
: Hash Killer II 时间限制: Sec 内存限制: MBSec Special Judge 提交: 解决: [提交][][] 题目描述 这天天气不错,hzhwcmhf神犇给VFleaKi ...
- Selenium2+python自动化45-18种定位方法(find_elements)【转载】
前言 江湖传言,武林中流传八种定位,其中xpath是宝刀屠龙,css是倚天剑. 除了这八种,其实还有十种定位方法,眼看就快失传了,今天小编让失传已久的定位方法重出江湖! 一.十八种定位方法 前八种是大 ...
- Linux命令之:tr
1. 用途: tr,translate的简写,主要用于压缩重复字符,删除文件中的控制字符以及进行字符转换操作. 2. 语法: tr [OPTION]... SET1 [SET2] 3. 参数: -s: ...