机器学习实战之SVM
一引言:
支持向量机这部分确实很多,想要真正的去理解它,不仅仅知道理论,还要进行相关的代码编写和测试,二者想和结合,才能更好的帮助我们理解SVM这一非常优秀的分类算法
支持向量机是一种二类分类算法,假设一个平面可以将所有的样本分为两类,位于正侧的样本为一类,值为+1,而位于负一侧的样本为另外一类,值为-1。
我们说分类,不仅仅是将不同的类别样本分隔开,还要以比较大的置信度来分隔这些样本,这样才能使绝大部分样本被分开。比如,我们想通过一个平面将两个类别的样本分开,如果这些样本是线性可分(或者近视线性可分),那么这样的平面有很多,但是如果我们加上要以最大的置信度来将这些样本分开,那么这样的平面只有一条。那么怎么才能找到这样的平面呢?这里不得不提到几个概念
1 几何间隔
几何间隔的概念,简单理解就是样本点到分隔平面的距离
2 间隔最大化
想要间隔最大化,我们必须找到距离分隔平面最近的点,并且使得距离平面最近的点尽可能的距离平面最远,这样,每一个样本就都能够以比较大的置信度被分隔开
算法的分类预测能力也就越好
显然,SVM算法的关键所在,就是找到使得间隔最大化的分隔超平面(如果特征是高维度的情况,我们称这样的平面为超平面)
这里关于SVM学习,推荐两本书:统计学习方法(李航)和机器学习实战,二者结合,可以帮助我们理解svm算法
2 支持向量机
关于支持向量机的推导,无论是书上还是很多很优秀的博客都写的非常清楚,大家有兴趣可以看上面推荐的统计与学习方法书,写的浅显易懂,或者看这几篇博客
http://blog.csdn.net/app_12062011/article/details/50536369
机器学习算法支持向量机系列博客
http://blog.csdn.net/zouxy09/article/details/16955347
http://blog.csdn.net/zouxy09/article/details/17291543
http://blog.csdn.net/zouxy09/article/details/17291805
http://blog.csdn.net/zouxy09/article/details/17292011
这两位博主都重点讲解了SVM的推导过程。这里我就本着站在巨人的肩膀上的思想,不再赘述,我的侧重点在于实际的代码编写上,比较理论总归要回到实践上,这也是每个算法的归宿所在。
好了,下面我就简要写出简要介绍一下,线性支持向量机,近似线性支持向量机以及非线性支持向量机(核函数)
1 线性支持向量机
求解线性支持向量机的过程是凸二次规划问题,所谓凸二次规划问题,就是目标函数是凸的二次可微函数,约束函数为仿射函数(满足f(x)=a*x+b,a,x均为n为向量)。而我们说求解凸二次规划问题可以利用对偶算法--即引入拉格朗日算子,利用拉格朗日对偶性将原始问题的最优解问题转化为拉格朗日对偶问题,这样就将求w*,b的原始问题的极小问题转化为求alpha*(alpha>=0)的对偶问题的极大问题,即求出alpha*,在通过KKT条件求出对应的参数w*,b,从而找到这样的间隔最大化超平面,进而利用该平面完成样本分类
2 近似线性支持向量机
当数据集并不是严格线性可分时,即满足绝不部分样本点是线性可分,存在极少部分异常点;这里也就是说存在部分样本不能满足约束条件,此时我们可以引入松弛因子,这样这些样本点到超平面的函数距离加上松弛因子,就能保证被超平面分隔开来;当然,添加了松弛因子sigma,我们也会添加对应的代价项,使得alpha满足0=<alpha<=C
3 非线性支持向量机
显然,当数据集不是线性可分的,即我们不能通过前面的线性模型来对数据集进行分类。此时,我们必须想办法将这些样本特征符合线性模型,才能通过线性模型对这些样本进行分类。这就要用到核函数,核函数的功能就是将低维的特征空间映射到高维的特征空间,而在高维的特征空间中,这些样本进过转化后,变成了线性可分的情况,这样,在高维空间中,我们就能够利用线性模型来解决数据集分类问题
好了,我们就只讲这么写大致的概念,如果想要透彻理解SVM建议还是要看看上面的书和博客文章,篇幅有限,我这里的中心在于凸二次规划的优化算法--SMO(序列最小最优化算法)
3 SMO算法
SMO是一种用于训练SVM的强大算法,它将大的优化问题分解为多个小的优化问题来进行求解。而这些小优化问题往往很容易求解,并且对它们进行顺序求解和对整体求解结果是一致的。在结果一致的情况下,显然SMO算法的求解时间要短很多,这样当数据集容量很大时,SMO就是一致十分高效的算法
SMO算法的目标是找到一系列alpha和b,而求出这些alpha,我们就能求出权重w,这样就能得到分隔超平面,从而完成分类任务
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,那么就增大其中一个而减少另外一个。这里的"合适",意味着在选择alpha对时必须满足一定的条件,条件之一是这两个alpha不满足最优化问题的kkt条件,另外一个条件是这两个alpha还没有进行区间化处理
对于SMO算法编写,我们采用由简单到复杂的方法,层层递进,完成最终的SMO算法实现,最后通过实际的用例对SVM模型进行训练,并验证准确性
1 简化版SMO算法
简化版SMO算法,省略了确定要优化的最佳alpha对的步骤,而是首先在数据集上进行遍历每一个alpha,再在剩余的数据集中找到另外一个alpha,构成要优化的alpha对,同时对其进行优化,这里的同时是要确保公式:Σαi*label(i)=0。所以改变一个alpha显然会导致等式失效,所以这里需要同时改变两个alpha。接下来看实际的代码:
简易版SMO算法的辅助函数:
#SMO算法相关辅助中的辅助函数
#1 解析文本数据函数,提取每个样本的特征组成向量,添加到数据矩阵
#添加样本标签到标签向量
def loadDataSet(filename):
dataMat=[];labelMat=[]
fr=open(filename)
for line in fr.readlines():
lineArr=line.strip().split('\t')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append((float()lineArr[2]))
return dataMat,labelMat #2 在样本集中采取随机选择的方法选取第二个不等于第一个alphai的
#优化向量alphaj
def selectJrand(i,m):
j=i
while(j==i):
j=int(random.uniform(0,m))
return j #3 约束范围L<=alphaj<=H内的更新后的alphaj值
def clipAlpha(aj,H,L):
if aj>H:
aj=H
if L>aj:
aj=L
return aj
上面是简易版SMO算法需要用到的一些功能,我们将其包装成函数,需要时调用即可,接下来看算法的伪代码:
#SMO算法的伪代码
#创建一个alpha向量并将其初始化为0向量
#当迭代次数小于最大迭代次数时(w外循环)
#对数据集中每个数据向量(内循环):
#如果该数据向量可以被优化:
#随机选择另外一个数据向量
#同时优化这两个向量
#如果两个向量都不能被优化,退出内循环
#如果所有向量都没有被优化,增加迭代次数,继续下一次循环
实际代码如下:
#@dataMat :数据列表
#@classLabels:标签列表
#@C :权衡因子(增加松弛因子而在目标优化函数中引入了惩罚项)
#@toler :容错率
#@maxIter :最大迭代次数
def smoSimple(dataMat,classLabels,C,toler,maxIter):
#将列表形式转为矩阵或向量形式
dataMatrix=mat(dataMatIn);labelMat=mat(classLabels).transpose()
#初始化b=0,获取矩阵行列
b=0;m,n=shape(dataMatrix)
#新建一个m行1列的向量
alphas=mat(zeros((m,1)))
#迭代次数为0
iter=0
while(iter<maxIter):
#改变的alpha对数
alphaPairsChanged=0
#遍历样本集中样本
for i in range(m):
#计算支持向量机算法的预测值
fXi=float(multiply(alphas,labelMat).T*\
(dataMatrix*dataMatrix[i,:].T))+b
#计算预测值与实际值的误差
Ei=fXi-float(labelMat[i])
#如果不满足KKT条件,即labelMat[i]*fXi<1(labelMat[i]*fXi-1<-toler)
#and alpha<C 或者labelMat[i]*fXi>1(labelMat[i]*fXi-1>toler)and alpha>0
if((labelMat[i]*Ei<-toler)and(alpha<C))or\
((labelMat[i]*Ei>toler)and(alpha[i]>0))):
#随机选择第二个变量alphaj
j=selectJrand(i,m)
#计算第二个变量对应数据的预测值
fXj=float(multiply(alphas,labelMat).T*\
(dataMatrix*dataMatrix[j,:]).T)+b
#计算与测试与实际值的差值
Ej=fXj-float(label[j])
#记录alphai和alphaj的原始值,便于后续的比较
alphaIold=alphas[i].copy()
alphaJold=alphas[j].copy()
#如何两个alpha对应样本的标签不相同
if(labelMat[i]!=labelMat[j]):
#求出相应的上下边界
L=max(0,alphas[j]-alphas[i])
H=min(C,C+alphas[j]-alphas[i])
else:
L=max(0,alphas[j]+alphas[i]-C)
H=min(C,alphas[j]+alphas[i])
if L==H:print("L==H);continue
#根据公式计算未经剪辑的alphaj
#------------------------------------------
eta=2.0*dataMatrix[i,:]*dataMatrix[j,:].T-\
dataMatrix[i,:]*dataMatrix[i,:].T-\
dataMatrix[j,:]*dataMatrix[j,:].T
#如果eta>=0,跳出本次循环
if eta>=0:print("eta>=0"):continue
alphas[j]-=labelMat[j]*(Ei-Ej)/eta
alphas[j]=clipAlpha(alphas[j],H,L)
#------------------------------------------
#如果改变后的alphaj值变化不大,跳出本次循环
if(abs(alphas[j]-alphaJold)<0.00001):print("j not moving\
enough");continue
#否则,计算相应的alphai值
alphas[i]+=labelMat[j]*labelMat[i]*(alphaJold-alphas[j])
#再分别计算两个alpha情况下对于的b值
b1=b-Ei-labelMat[i]*(alphas[i]-alphaIold)*\
dataMatrix[i,:]*dataMat[i,:].T-\
labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[i,:]*dataMatrix[j,:].T
b2=b-Ej-labelMat[i]*(alphas[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[j,:].T-\
labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[j,:]*dataMatrix[j,:].T
#如果0<alphai<C,那么b=b1
if(0<alphas[i]) and (C>alphas[i]):b=b1
#否则如果0<alphai<C,那么b=b1
elif (0<alphas[j]) and (C>alphas[j]):b=b2
#否则,alphai,alphaj=0或C
else:b=(b1+b2)/2.0
#如果走到此步,表面改变了一对alpha值
alphaPairsChanged+=1
print("iter: &d i:%d,paird changed %d",%(iter,i,alphaPairsChanged))
#最后判断是否有改变的alpha对,没有就进行下一次迭代
if(alphaPairsChanged==0):iter+=1
#否则,迭代次数置0,继续循环
else:iter=0
print("iteration number: %d" %iter)
#返回最后的b值和alpha向量
return b,alphas
上面的代码量看起来很多,但事实上只要理解了SVM算法的理论知识,就很容易理解,其只不过是将理论转化为机器可以运行的语言而已。
上面代码在一台性能一般的笔记本上对100个样本的数据集上运行,收敛时间14.5秒,取得了令人满意的分类效果

当然,上面的代码通过对整个数据集进行两次遍历的方法来寻找alpha对的方法,显然存在一定的不足,如果数据集规模较小的情况下,或许还可以满足要求。但是对于大规模的数据集而言,上面的代码显然收敛速度非常慢,所以,接下来我们在此基础上对选取合适的alpha对方法进行改进,采用启发式的方法来选取合适的alpha对,从而提升运算效率。
2 启发式选取alpha变量的SMO算法
启发式的SMO算法一个外循环来选择第一个alpha值,并且其选择过程会在下面两种方法之间进行交替:
(1)在所有数据集上进行单遍扫描
(2)另一种方法是在间隔边界上样本点进行单遍扫描,所谓间隔边界上的点即为支持向量点。
显然,对于整个数据集遍历比较容易,而对于那些处于间隔边界上的点,我们还需要事先将这些点对应的alpha值找出来,存放在一个列表中,然后对列表进行遍历;此外,在选择第一个alpha值后,算法会通过一个内循环来选择第二个值,在优化的过程中依据alpha的更新公式αnew,unc=aold+label*(Ei-Ej)/η,(η=dataMat[i,:]*dataMat[i,:].T+dataMat[j,:]*dataMat[j,:].T-2*dataMat[i,:]*dataMat[j,:].T),可知alpha值的变化程度更Ei-Ej的差值成正比,所以,为了使alpha有足够大的变化,选择使Ei-Ej最大的alpha值作为另外一个alpha。所以,我们还可以建立一个全局的缓存用于保存误差值,便于我们选择合适的alpha值
下面是创建的一个数据结构类,便于我们存取算法中需要用到的重要数据:
#启发式SMO算法的支持函数
#新建一个类的收据结构,保存当前重要的值
class optStruct:
def __init__(self,dataMatIn,classLabels,C,toler):
self.X=dataMatIn
self.labelMat=classLabels
self.C=C
self.tol=toler
self.m=shape(dataMatIn)[0]
self.alphas=mat(zeros((self.m,1)))
self.b=0
self.eCache=mat(zeros((self.m,2)))
#格式化计算误差的函数,方便多次调用
def calcEk(oS,k):
fXk=float(multiply(oS.alphas,oS.labelMat).T*\
(oS.X*oS.X[k,:].T))+oS.b
Ek=fXk-float(oS.labelMat[k])
return Ek
#修改选择第二个变量alphaj的方法
def selectJ(i,oS,Ei):
maxK=-1;maxDeltaE=-;Ej=0
#将误差矩阵每一行第一列置1,以此确定出误差不为0
#的样本
oS.eCache[i]=[1,Ei]
#获取缓存中Ei不为0的样本对应的alpha列表
validEcacheList=nonzero(oS.Cache[:,0].A)[0]
#在误差不为0的列表中找出使abs(Ei-Ej)最大的alphaj
if(len(validEcacheList)>0):
for k in validEcacheList:
if k ==i:continue
Ek=calcEk(oS,k)
deltaE=abs(Ei-Ek)
if(deltaE>maxDeltaE):
maxK=k;maxDeltaE=deltaE;Ej=Ek
return maxK,Ej
else:
#否则,就从样本集中随机选取alphaj
j=selectJrand(i,oS.m)
Ej=calcEk(oS,j)
return j,Ej
#更新误差矩阵
def updateEk(oS,k):
Ek=calcEk(oS,k)
oS.eCache[k]=[1,Ek]
好了,有了这些辅助性的函数,我们就可以很容易的实现启发式的SMO算法的具体代码:
#SMO外循环代码
def smoP(dataMatIn,classLabels,C,toler,maxIter,kTup=('lin',0)):
#保存关键数据
oS=optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter=0
enrireSet=True;alphaPairsChanged=0
#选取第一个变量alpha的三种情况,从间隔边界上选取或者整个数据集
while(iter<maxIter)and((alphaPairsChanged>0)or(entireSet)):
alphaPairsChanged=0
#没有alpha更新对
if entireSet:
for i in range(oS.m):
alphaPairsChanged+=innerL(i,oS)
print("fullSet,iter: %d i:%d,pairs changed %d",%\
(iter,i,alphaPairsChanged))
else:
#统计alphas向量中满足0<alpha<C的alpha列表
nonBoundIs=nonzero((oS.alphas.A)>0)*(oS.alphas.A<C))[0]
for i in nonBoundIs:
alphaPairsChanged+=innerL(i,oS)
print("non-bound,iter: %d i:%d,pairs changed %d",%\
(iter,i,alphaPairsChanged))
iter+=1
if entireSet:entireSet=False
#如果本次循环没有改变的alpha对,将entireSet置为true,
#下个循环仍遍历数据集
elif (alphaPairsChanged==0):entireSet=True
print("iteration number: %d",%iter)
return oS.b,oS.alphas
#内循环寻找alphaj
def innerL(i,oS):
#计算误差
Ei=calcEk(oS,i)
#违背kkt条件
if(((oS.labelMat[i]*Ei<-oS.tol)and(oS.alphas[i]<oS.C))or\
((oS.labelMat[i]*Ei>oS.tol)and(oS.alphas[i]>0))):
j,Ej=selectJ(i,oS,Ei)
alphaIold=alphas[i].copy();alphaJold=alphas[j].copy()
#计算上下界
if(oS.labelMat[i]!=oS.labelMat[j]):
L=max(0,oS.alphas[j]-oS.alphas[i])
H=min(oS.C,oS.C+oS.alphas[j]-oS.alphas[i])
else:
L=max(0,oS.alphas[j]+oS.alphas[i]-oS.C)
H=min(oS.C,oS.alphas[j]+oS.alphas[i])
if L==H:print("L==H");return 0
#计算两个alpha值
eta=2.0*oS.X[i,:]*oS.X[j,:].T-oS.X[i,:]*oS.X[i,:].T-\
oS.X[j,:]*oS.X[j,:].T
if eta>=0:print("eta>=0");return 0
oS.alphas[j]-=oS.labelMat[j]*(Ei-Ej)/eta
oS.alphas[j]=clipAlpha(oS.alphas[j],H,L)
updateEk(oS,j)
if(abs(oS.alphas[j]-alphaJold)<0.00001):
print("j not moving enough");return 0
oS.alphas[i]+=oS.labelMat[j]*oS.labelMat[i]*\
(alphaJold-oS.alphas[j])
updateEk(oS,i)
#在这两个alpha值情况下,计算对应的b值
#注,非线性可分情况,将所有内积项替换为核函数K[i,j]
b1=oS.b-Ei-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\
oS.X[i,:]*oS.X[i,:].T-\
oS.labelMat[j]*(oS.alphas[j]-alphaJold)*\
oS.X[i,:]*oS.X[j,:].T
b2=oS.b-Ej-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\
oS.X[i,:]*oS.X[j,:].T-\
oS.labelMat[j]*(oS.alphas[j]-alphaJold)*\
oS.X[j,:]*oS.X[j,:].T
if(0<oS.alphas[i])and (oS.C>oS.alphas[i]):oS.b=b1
elif(0<oS.alphas[j])and (oS.C>oS.alphas[j]):oS.b=b2
else:oS.b=(b1+b2)/2.0
#如果有alpha对更新
return 1
#否则返回0
else return 0
显然,上面的SMO完整代码是分为内外两个循环函数来编写的,采取这样的结构可以更方便我们去理解选取两个alpha的过程;既然,我们已经计算出了alpha值和b值,那么显然我们可以利用公式w*=Σαi*label[i]*dataMat[i,:]计算出相应的权值参数,然后就可以得到间隔超平面的公式w*x+b*来完成样本的分类了,由于SVM算法是一种二类分类算法,正值为1,负值为-1,即分类的决策函数为跳跃函数sign(w*x+b*)
然后,我们可以编写一小段测试代码,来利用SMO算法得到的alpha值和b值,计算分类决策函数,从而实现具体的预测分类了
#求出了alpha值和对应的b值,就可以求出对应的w值,以及分类函数值
def predict(alphas,dataArr,classLabels):
X=mat(dataArr);labelMat=mat(classLabels)
m,n=shape(X)
w=zeros((n,1))
for i in range(m):
w+=multiply(alphas[i]*labelMat[i],X[i,:].T)
result=dataArr[0]*mat(ws)+b
return sign(result)
看一下分类效果:

3 核函数
核函数的目的主要是为了解决非线性分类问题,通过核技巧将低维的非线性特征转化为高维的线性特征,从而可以通过线性模型来解决非线性的分类问题。
如下图,当数据集不是线性可分时,即数据集分布是下面的圆形该怎么办呢?
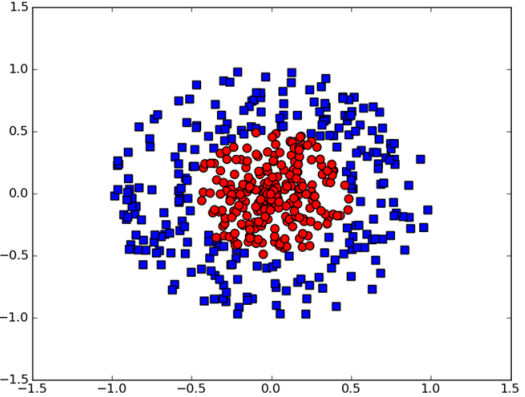
显然,此时数据集线性不可分,我们无法用一个超平面来将两种样本分隔开;那么我们就希望将这些数据进行转化,转化之后的数据就能够通过一个线性超平面将不同类别的样本分开,这就需要核函数,核函数的目的主要是为了解决非线性分类问题,通过核技巧将低维的非线性特征转化为高维的线性特征,从而可以通过线性模型来解决非线性的分类问题。
而径向基核函数,是SVM中常用的一个核函数。径向基核函数是一个采用向量作为自变量的函数,能够基于向量距离运算输出一个标量。径向基核函数的高斯版本公式为:
k(x,y)=exp(-||x-y||2/2σ2),其中,σ为到达率,决定了函数值跌落至0的速度
下面通过代码编写高斯核函数:
#径向基核函数是svm常用的核函数
#核转换函数
def kernelTrans(X,A,kTup):
m,n=shape(X)
K=mat(zeros((m,1)))
#如果核函数类型为'lin'
if kTup[0]=='lin':K=X*A.T
#如果核函数类型为'rbf':径向基核函数
#将每个样本向量利用核函数转为高维空间
elif kTup[0]=='rbf'
for j in range(m):
deltaRow=X[j,:]-A
K[j]=deltaRow*deltaRow.T
K=exp(K/(-1*kTup[1]**2))
else:raise NameError('Houston we Have a Problem -- \
That Kernel is not recognised')
return K #对核函数处理的样本特征,存入到optStruct中
class optStruct:
def __init__(self,dataMatIn,classLabels,C,toler,kTup):
self.X=dataMatIn
self.labelMat=classLabels
self.C=C
self.tol=toler
self.m=shape(dataMatIn)[0]
self.alphas=mat(zeros((self.m,1)))
self.b=0
self.eCache=mat(zeros((self.m,2)))
self.K=mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i]=kernelTrans(self.X,self.X[i,:],kTup)
需要说明的是,这里引入了一个变量kTup,kTup是一个包含核信息的元组,它提供了选取的核函数的类型,比如线性'lin'或者径向基核函数'rbf';以及用户提供的到达率σ
有了高斯核函数之后,我们只要将上面的SMO算法中所有的内积项替换为核函数即可,比如讲dataMat[i,:]*dataMat[j,:].T替换为k[i,j]即可,替换效果如下:
def innerL(i,oS):
#计算误差
Ei=calcEk(oS,i)
#违背kkt条件
if(((oS.labelMat[i]*Ei<-oS.tol)and(oS.alphas[i]<oS.C))or\
((oS.labelMat[i]*Ei>oS.tol)and(oS.alphas[i]>0))):
j,Ej=selectJ(i,oS,Ei)
alphaIold=alphas[i].copy();alphaJold=alphas[j].copy()
#计算上下界
if(oS.labelMat[i]!=oS.labelMat[j]):
L=max(0,oS.alphas[j]-oS.alphas[i])
H=min(oS.C,oS.C+oS.alphas[j]-oS.alphas[i])
else:
L=max(0,oS.alphas[j]+oS.alphas[i]-oS.C)
H=min(oS.C,oS.alphas[j]+oS.alphas[i])
if L==H:print("L==H");return 0
#计算两个alpha值
eta=2.0*oS.K[i,j]-oS.K[i,i]-oS.K[j,j]
if eta>=0:print("eta>=0");return 0
oS.alphas[j]-=oS.labelMat[j]*(Ei-Ej)/eta
oS.alphas[j]=clipAlpha(oS.alphas[j],H,L)
updateEk(oS,j)
if(abs(oS.alphas[j]-alphaJold)<0.00001):
print("j not moving enough");return 0
oS.alphas[i]+=oS.labelMat[j]*oS.labelMat[i]*\
(alphaJold-oS.alphas[j])
updateEk(oS,i)
#在这两个alpha值情况下,计算对应的b值
#注,非线性可分情况,将所有内积项替换为核函数K[i,j]
b1=oS.b-Ei-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\
oS.K[i,i]-\
oS.labelMat[j]*(oS.alphas[j]-alphaJold)*\
oS.k[i,j]
b2=oS.b-Ej-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\
oS.k[i,j]-\
oS.labelMat[j]*(oS.alphas[j]-alphaJold)*\
oS.k[i,j]
if(0<oS.alphas[i])and (oS.C>oS.alphas[i]):oS.b=b1
elif(0<oS.alphas[j])and (oS.C>oS.alphas[j]):oS.b=b2
else:oS.b=(b1+b2)/2.0
#如果有alpha对更新
return 1
#否则返回0
else return 0
有了核函数,我们就能对非线性的数据集进行分类预测了,接下来就是编写代码利用核函数进行测试,需要说明的是,在优化的过程中,我们仅仅需要找到支持向量和其对应的alpha值,而对于其他的样本值可以不用管,甚至可以舍弃,因为这些样本将不会对分类预测函数造成任何影响。这也就是SVM相比KNN算法的优秀的地方所在
#测试核函数
#用户指定到达率
def testRbf(k1=1.3):
#第一个测试集
dataArr,labelArr=loadDataSet('testSetRBF.txt')
b,alphas=smoP(dataArr,labelArr,200,0.0001,10000,('rbf',k1))
dataMat=mat(dataArr);labelMat=mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=dataMat[svInd]
labelSV=labelMat[svInd]
print("there are %d Support Vectors",%shape(sVs)[0])
m,n=shape(dataMat)
errorCount=0
for i in range(m):
kernelEval=kernelTrans(sVs,dataMat[i,:],('rbf',k1))
predict=kernelEval.T*multiply(labelSV,alphas[svInd])+b
if sign(predict)!=sign(labelArr[i]):errorCount+=1
print("the training error rate is: %f",%(float(errorCount)/m))
#第二个测试集
dataArr,labelArr=loadDataSet('testSetRBF2.txt')
dataMat=mat(dataArr);labelMat=mat(labelArr).transpose()
errorCount=0
m,n=shape(dataMat)
for i in range(m):
kernelEval=kernelTrans(sVs,dataMat[i,:],('rbf',k1))
predict=kernelEval.T*multiply(labelSV,alphas[svInd])+b
if sign(predict)!=sign(labelArr[i]):errorCount+=1
print("the training error rate is: %f",%(float(errorCount)/m))
当用户输入σ=1.3时的实验结果为:
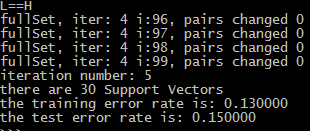
当σ=0.1时实验结果为:

通过输入不同的σ值(当然,迭代次数也会有一定的影响,我们只讨论σ值),我们发现测试错误率,训练误差率,支持向量个数都会发生变化,在一定的范围内,支持向量数目的下降,会使得训练错误率和测试错误率都下降,但是当抵达某处的最优值时,再次通过增大σ值的方法减少支持向量,此时训练错误率下降,而测试误差上升
简言之,对于固定的数据集,支持向量的数目存在一个最优值,如果支持向量太少,会得到一个很差的决策边界;而支持向量太多,也相当于利用整个数据集进行分类,就类似于KNN算法,显然运算速度不高。
三,SVM实例:手写识别问题
相较于第二张的KNN算法,尽管KNN也能取得不错的效果;但是从节省内存的角度出发,显然SVM算法更胜一筹,因为其不需要保存真个数据集,而只需要其作用的支持向量点,而取得不错的分类效果。
#实例:手写识别问题
#支持向量机由于只需要保存支持向量,所以相对于KNN保存整个数据集占用更少内存
#且取得可比的效果 #基于svm的手写数字识别
def loadImages(dirName):
from os import listdir
hwLabels=[]
trainingFileList=listdir(dirName)
m=len(trainingFileList)
trainingMat=zeros((m,1024))
for i in range(m):
fileNameStr=trainingFileList[i]
fileStr=fileNameStr.split('.')[0]
classNumStr=int(fileStr.split('_')[0])
if classNumStr==9:hwLabels.append(-1)
else:hwLabels.append(1)
trainingMat[i,:]=img2vector('%s/%s',%(dirName,fileNameStr))
return hwLabels,trainingMat #将图像转为向量
def img2vector(fileaddir):
featVec=zeros((1,1024))
fr=open(filename)
for i in range(32):
lineStr=fr.readline()
for j in range(32):
featVec[0,32*i+j]=int(lineStr[j])
return featVec #利用svm测试数字
def testDigits(kTup=('rbf',10)):
#训练集
dataArr,labelArr=loadDataSet('trainingDigits')
b,alphas=smoP(dataArr,labelArr,200,0.0001,10000,kTup)
dataMat=mat(dataArr);labelMat=mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=dataMat[svInd]
labelSV=labelMat[svInd]
print("there are %d Support Vectors",%shape(sVs)[0])
m,n=shape(dataMat)
errorCount=0
for i in range(m):
kernelEval=kernelTrans(sVs,dataMat[i,:],kTup)
predict=kernelEval.T*multiply(labelSV,alphas[svInd])+b
if sign(predict)!=sign(labelArr[i]):errorCount+=1
print("the training error rate is: %f",%(float(errorCount)/m))
#测试集
dataArr,labelArr=loadDataSet('testDigits.txt')
dataMat=mat(dataArr);labelMat=mat(labelArr).transpose()
errorCount=0
m,n=shape(dataMat)
for i in range(m):
kernelEval=kernelTrans(sVs,dataMat[i,:],('rbf',k1))
predict=kernelEval.T*multiply(labelSV,alphas[svInd])+b
if sign(predict)!=sign(labelArr[i]):errorCount+=1
print("the training error rate is: %f",%(float(errorCount)/m))
下面来看一下,在kTup=('rbf',20)情况下的测试误差率和支持向量个数情况
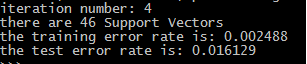
并且通过尝试不同的σ值,以及尝试了线性核函数,可以得到关于不同σ值的书写数字识别性能:
| 内核模式,设置 | 训练错误率(%) | 测试错误率(%) | 支持向量数 |
| rbf,0.1 | 0 | 52 | 402 |
| rbf,5 | 0 | 3.2 | 402 |
| rbf,10 | 0 | 0.5 | 99 |
| rbf,50 | 0.2 | 2.2 | 41 |
| rbf,100 | 4.5 | 4.3 | 26 |
| Linear | 2.7 | 2.2 | 38 |
由上图可以看出,σ值在取10时取得了最好的分类效果,这也印证了我们上面的叙述。即对于固定的数据集,存在最优的支持向量个数,使得分类错误率最低。支持向量的个数会随着σ值的增大而逐渐减少,但是分类错误率确实一个先降低后升高的过程。即最小的分类错误率并不意味着最少的支持向量个数。
4 总结
支持向量机是一种通过求解凸二次规划问题来解决分类问题的算法,具有较低的泛化错误率。而SMO算法可以通过每次只优化两个alpha值来加快SVM的训练速度。
核技巧是将数据由低维空间映射到高维空间,可以将一个低维空间中的非线性问题转换为高维空间下的线性问题来求解。而径向基核函数是一个常用的度量两个向量距离的核函数。
最后,支持向量机的优缺点:
优点:泛化错误率低,计算开销不大
缺点:对参数调节和核函数的选择敏感,且仅适用于二类分类
机器学习实战之SVM的更多相关文章
- 06机器学习实战之SVM
对偶的概念 https://blog.csdn.net/qq_34531825/article/details/52872819?locationNum=7&fps=1 拉格朗日乘子法.KKT ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 《机器学习实战》学习笔记——第13章 PCA
1. 降维技术 1.1 降维的必要性 1. 多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯.2. 高维空间本身具有稀疏性.一维正态分布有68%的值落于正负 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 机器学习 支持向量机(SVM) 从理论到放弃,从代码到理解
基本概念 支持向量机(support vector machines,SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器.支持向量机还包括核技巧,这使它成为实质上的非线性分 ...
- 机器学习实战:用nodejs实现人脸识别
机器学习实战:用nodejs实现人脸识别 在本文中,我将向你展示如何使用face-recognition.js执行可靠的人脸检测和识别 . 我曾经试图找一个能够精确识别人脸的Node.js库,但是 ...
- 机器学习实战笔记7(Adaboost)
1:简单概念描写叙述 Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们须要简介几个概念. 1:弱学习器:在二分情况下弱分类器的错误率会低于50%. 事实 ...
随机推荐
- Cover
[题目描述] 有 N 个时间段,某个时间段可能包含其它时间段. 请找出能包含其它时间段最多的那个段,并计算出它包括的其它时间段有多少? [数据范围] 1 <= N <= 25,000 1 ...
- 【HDOJ5519】Kykneion asma(状压DP,容斥)
题意:给定n和a[i](i=0..4),求所有n位5进制数中没有前导0且i出现的次数不超过a[i]的数的个数 2<=n<=15000,0<=a[i]<=3e4 思路:设f(n, ...
- EnableViewState 属性
原文发布时间为:2009-10-25 -- 来源于本人的百度文章 [由搬家工具导入] 指示是否在页请求之间保持视图状态。如果要保持视图状态,则为 true;否则为 false。默认值为 true。 自 ...
- 多线程中sleep和wait的区别
前几天去UC笔试,有一道简答题问到了.之前还真一直没留意到这个问题,所以答得也不好. 无论学习什么都好,通过对比学习更有利于发现事物的共性和个性,对于知识点的理解更有明显效果(这也可能是UC笔试题上, ...
- SSRS的配置
SSRS是微软的报表服务管理器,本文讲述SSRS的配置:邮件和凭证. 一,配置SMTP 在报表服务配置管理器(Reporting Service Configuration Manager)中配置邮件 ...
- (8)ftp配置文档
1.vsftpd文件夹中的ftpusers文件的作用 它是一个黑名单,ftpusers不受任何配制项的影响 该文件存放的是一个禁止访问FTP的用户列表 管理员不希望一些拥有过大权限的帐号(比如root ...
- Swoole MySQL 连接池的实现
目录 概述 代码 扩展 小结 概述 这是关于 Swoole 入门学习的第八篇文章:Swoole MySQL 连接池的实现. 第七篇:Swoole RPC 的实现 第六篇:Swoole 整合成一个小框架 ...
- CVPR 2019|PoolNet:基于池化技术的显著性检测 论文解读
作者 | 文永亮 研究方向 | 目标检测.GAN 研究动机 这是一篇发表于CVPR2019的关于显著性目标检测的paper,在U型结构的特征网络中,高层富含语义特征捕获的位置信息在自底向上的传播过 ...
- codevs——1044 拦截导弹(序列DP)
1999年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description 某国为了防御敌国的导弹袭击 ...
- PHP的按位运算符是什么意思
按位运算符是什么意思? 按位运算符(Bitwise Operators)是用于对涉及单个位操作的位模式或二进制数字执行位操作的运算符. 按位运算符可以用于: 1.通信堆栈,其中标头中的各个位附加到数据 ...