k8s-3-容器云监控系统
apollo小结

课程目录

一、容器云监控prometheus概述

https://prometheus.io/docs/introduction/overview/ #官方文档
https://github.com/prometheus/prometheus #代码github官网
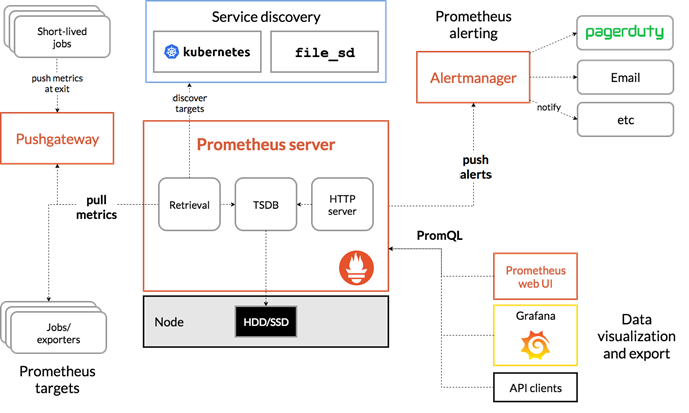
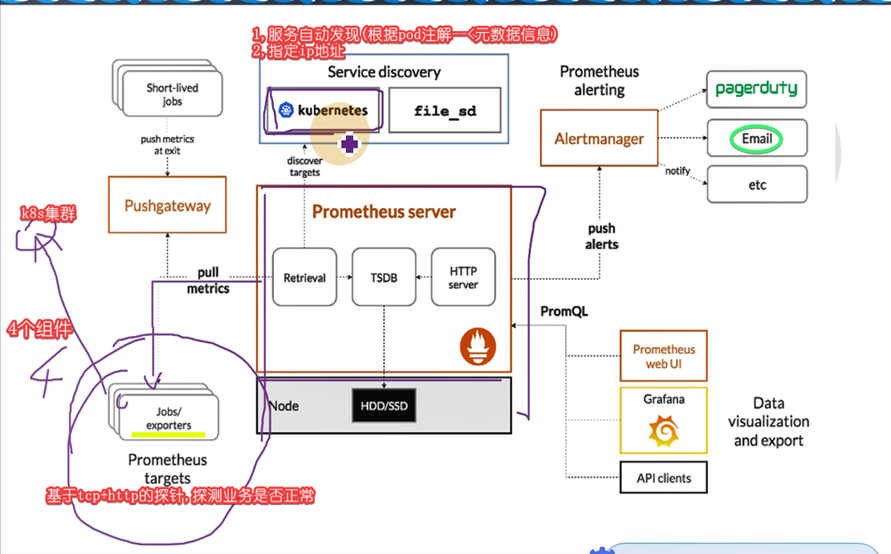
原理

Exporter相当于监控通信的中间件
Pushgateway比pull速度快,让job主动将数据发送给pushgateway
服务发现(难度大) ,静态配置发现目标
Grafana专门做数据展示
架构介绍

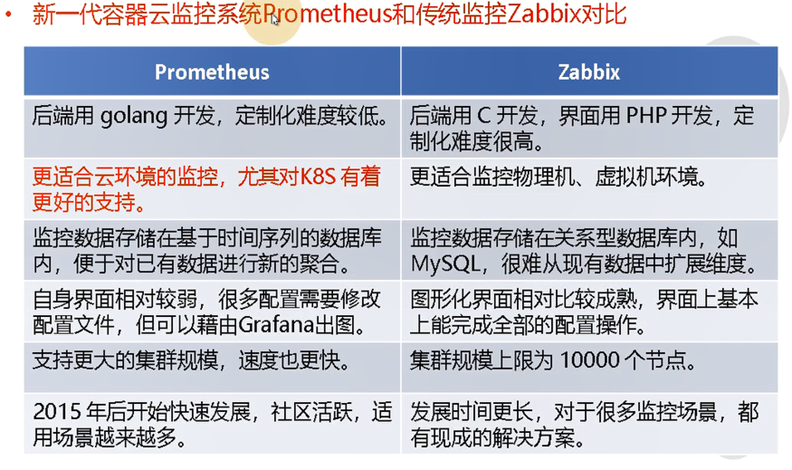
Promtheus对比zabbix
二、监控必备exporter
部署kube-state-metrics
监控k8s基础信息,有多少个dp,svc,有哪些pod,通过这些基础数据,访问集群元数据
拉取上传镜像
运维主机HDSS7-200.host.com上:
[root@hdss7-200 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.5.0
v1.5.0: Pulling from coreos/kube-state-metrics
cd784148e348: Pull complete
f622528a393e: Pull complete
Digest: sha256:b7a3143bd1eb7130759c9259073b9f239d0eeda09f5210f1cd31f1a530599ea1
Status: Downloaded newer image for quay.io/coreos/kube-state-metrics:v1.5.0
[root@hdss7-200 ~]# docker tag 91599517197a harbor.od.com/public/kube-state-metrics:v1.5.0
[root@hdss7-200 ~]# docker push harbor.od.com/public/kube-state-metrics:v1.5.0
资源配置清单rbac
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/kubu-state-metrics
[root@hdss7-200 kubu-state-metrics]# cat rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- extensions
resources:
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
资源配置清单deploy
[root@hdss7-200 kubu-state-metrics]# cat dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "2"
labels:
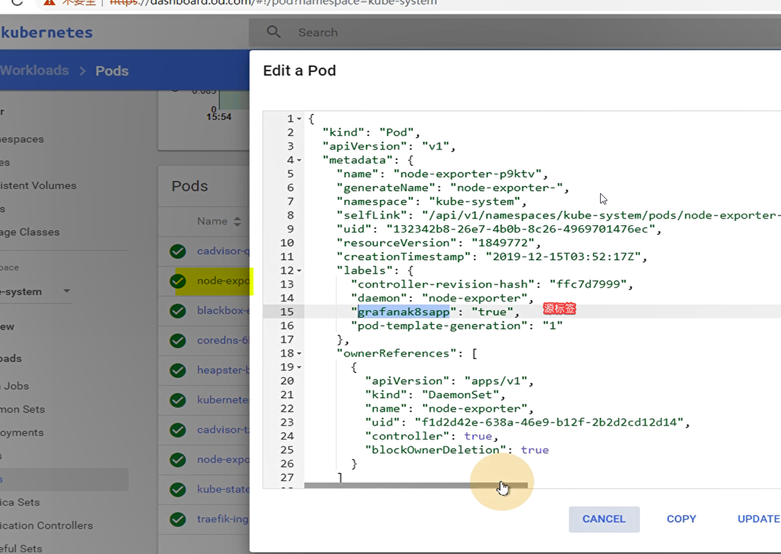
grafanak8sapp: "true"
app: kube-state-metrics
name: kube-state-metrics
namespace: kube-system
spec:
selector:
matchLabels:
grafanak8sapp: "true"
app: kube-state-metrics
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
grafanak8sapp: "true"
app: kube-state-metrics
spec:
containers:
- image: harbor.od.com/public/kube-state-metrics:v1.5.0
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
protocol: TCP
readinessProbe: #就绪性探针,对于不可达pod资源不提供访问资源.不断检查该pod是否正常,防止pod关了网页404.
failureThreshold: 3
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
imagePullPolicy: IfNotPresent
imagePullSecrets:
- name: harbor
restartPolicy: Always
serviceAccount: kube-state-metrics
serviceAccountName: kube-state-metrics
应用资源配置清单
kubectl apply -f http://k8s-yaml.od.com/kubu-state-metrics/rbac.yaml
kubectl apply -f http://k8s-yaml.od.com/kubu-state-metrics/dp.yaml
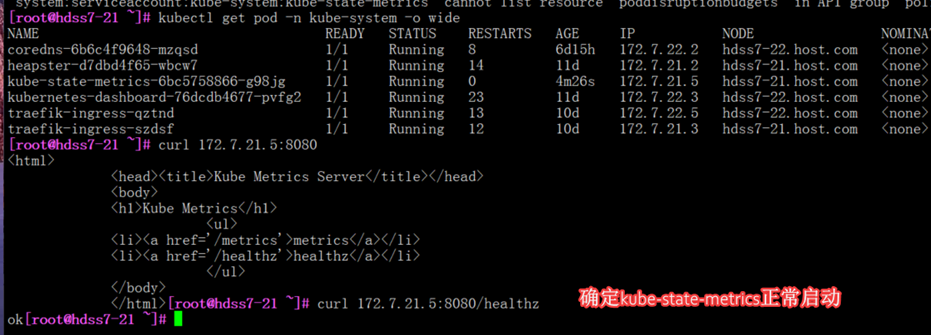
判断正常启动
部署node-exporter
#作用:监控运算节点宿主机资源,cpu,内存等宿主机资源
拉取上传镜像
运维主机HDSS7-200.host.com上:
[root@hdss7-200 kubu-state-metrics]# docker pull prom/node-exporter:v0.15.0
docker tag b3e7f67a1480 harbor.od.com/public/node-exporter:v0.15.0
[root@hdss7-200 kubu-state-metrics]# docker push harbor.od.com/public/node-exporter:v0.15.0
[root@hdss7-200 kubu-state-metrics]# mkdir /data/k8s-yaml/node-exporter/
资源配置清单daemonset
Daemonset会在每个运算节点开一个pod
[root@hdss7-200 node-exporter]# vi ds.yaml
kind: DaemonSet
apiVersion: extensions/v1beta1
metadata:
name: node-exporter
namespace: kube-system
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
selector:
matchLabels:
daemon: "node-exporter"
grafanak8sapp: "true"
template:
metadata:
name: node-exporter
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
volumes:
- name: proc
hostPath:
path: /proc
type: ""
- name: sys
hostPath:
path: /sys
type: ""
containers:
- name: node-exporter
image: harbor.od.com/public/node-exporter:v0.15.0
args:
- --path.procfs=/host_proc
- --path.sysfs=/host_sys
ports:
- name: node-exporter
hostPort: 9100 #暴露的主机端口
containerPort: 9100
protocol: TCP
volumeMounts:
- name: sys
readOnly: true
mountPath: /host_sys
- name: proc
readOnly: true
mountPath: /host_proc
imagePullSecrets:
- name: harbor
restartPolicy: Always
hostNetwork: true
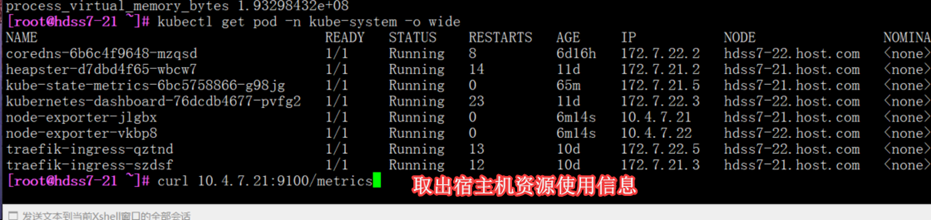
[root@hdss7-21 ~]# curl 10.4.7.21:9100/metrics #取出宿主机资源使用信息
确认安装成功
应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/node-exporter/ds.yaml
部署cadivisor
监控pop使用资源,cpu,内存等
注意版本,与grafana有些地方有bug,28版本比较推荐
运维主机HDSS7-200.host.com上:
拉取上传镜像
[root@hdss7-200 node-exporter]# docker pull google/cadvisor:v0.28.3
[root@hdss7-200 node-exporter]# docker tag 75f88e3ec333 harbor.od.com/public/cadvisor:v0.28.3
[root@hdss7-200 ~]# docker push !$
资源配置清单daemonset
[root@hdss7-200 node-exporter]# mkdir /data/k8s-yaml/cadvisor
vi ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cadvisor
namespace: kube-system
labels:
app: cadvisor
spec:
selector:
matchLabels:
name: cadvisor
template:
metadata:
labels:
name: cadvisor
spec:
hostNetwork: true
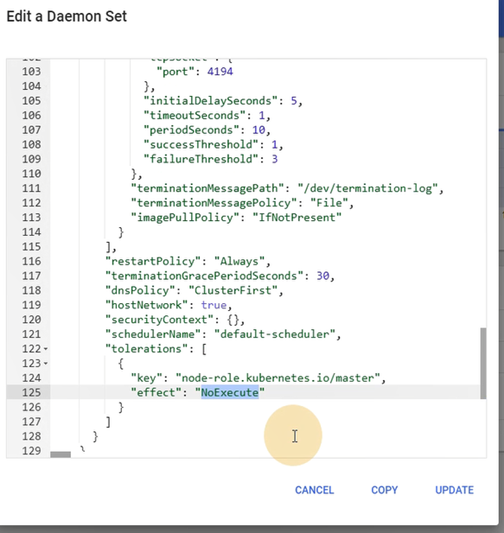
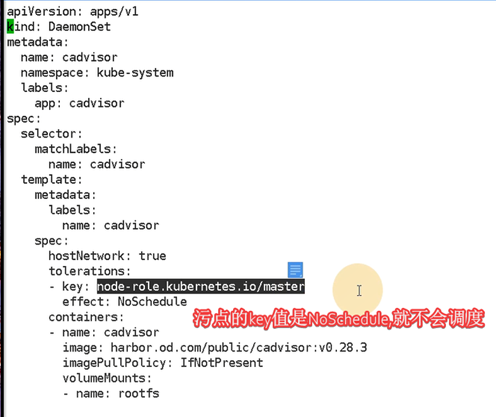
tolerations: #容忍污点节点,在污点节点允许创建pod,系统会尽量将pod放在污点节点上运行
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: cadvisor
image: harbor.od.com/public/cadvisor:v0.28.3
imagePullPolicy: IfNotPresent
volumeMounts:
- name: rootfs
mountPath: /rootfs
readOnly: true
- name: var-run
mountPath: /var/run
- name: sys
mountPath: /sys
readOnly: true
- name: docker
mountPath: /var/lib/docker
readOnly: true
ports:
- name: http
containerPort: 4194
protocol: TCP
readinessProbe:
tcpSocket:
port: 4194
initialDelaySeconds: 5
periodSeconds: 10
args:
- --housekeeping_interval=10s
- --port=4194
terminationGracePeriodSeconds: 30
volumes:
- name: rootfs
hostPath:
path: /
- name: var-run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /data/docker
修改运算节点软连接
所有运算节点上:
mount -o remount,rw /sys/fs/cgroup/ #remount重新挂载,不需要加设备
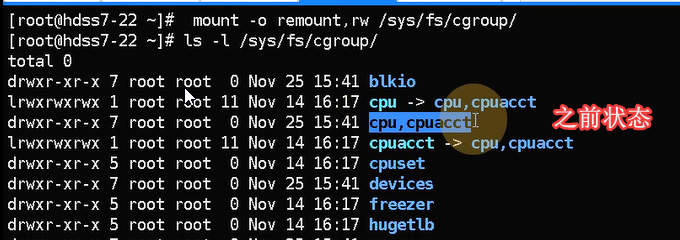
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu #创建一个新的软链接,修改后状态,容器用的目录名称

ll /sys/fs/cgroup/ | grep cpu
应用资源配置清单
任意运算节点上:
kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml
netstat -luntp|grep 4194 #检查ds暴露的端口是否开启
污点节点
加角色标签
标签可以过滤某些节点
[root@hdss7-21 cert]# kubectl label node hdss7-21.host.com node-role.kubernetes.io/master=
[root@hdss7-21 cert]# kubectl label node hdss7-21.host.com node-role.kubernetes.io/node=
[root@hdss7-22 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready master,node 15h v1.15.2
hdss7-22.host.com Ready master,node 12m v1.15.2
影响k8s调度策略的三种方法:
1.污点,容忍度方法
2.容忍度:pod是否能够荣仍污点
Nodename:让pod运行在指定在node上
Nodeselector: 通过标签选择器,让pod运行指定的一类node上

运算节点打污点
针对于调度器schedule,不使用主节点调度器,使用资源清单的调度规则

#污染21节点,不使用系统调度规则
#这个污点的key为node-role.kubernetes.io/master value为master,,,动作为:NoSchedule
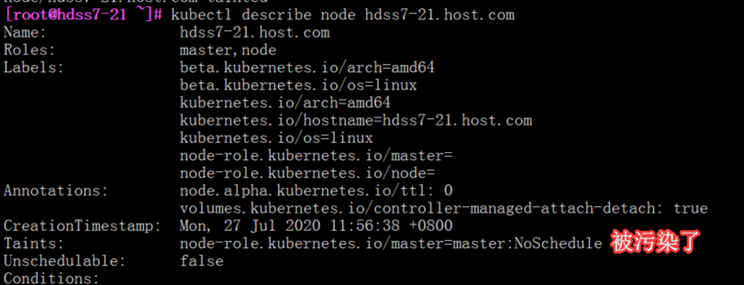
[root@hdss7-21 ~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master=master:NoSchedule
node/hdss7-21.host.com tainted

污点使用小结
Key-value,value可以为空,为空时匹配的规则就是key值相同
污点: 针对node--->运算节点node上的污点
容忍: 针对pod资源清单加的容忍污点,匹配到的节点污点规则相同,将能够在该污点节点上运行
删除污点
[root@hdss7-21 ~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master- #删除污点,注意master-
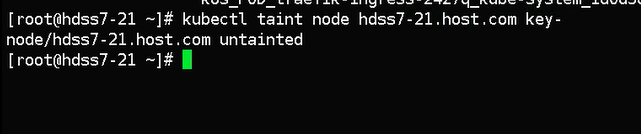
删除污点使用key-就可以删除
污点容忍度补充
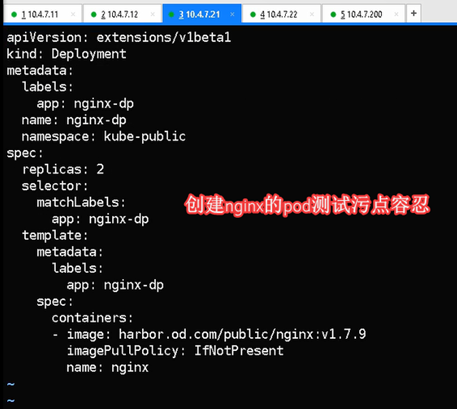
#在2个节点上创建2个pod后,缩容成1个,再到没有该pod的21节点打污点测试
#在21节点上加污点
#打了一个污点,污点的key叫quedian,value叫buxijiao,匹配到这个key-value后执行的动作是noschedule
Kubectl taint node hdss7-21.host.com quedian=buxijiao:NoSchedule
Kubectl describe node hdss7-21.host.com
容忍污点资源清单配置
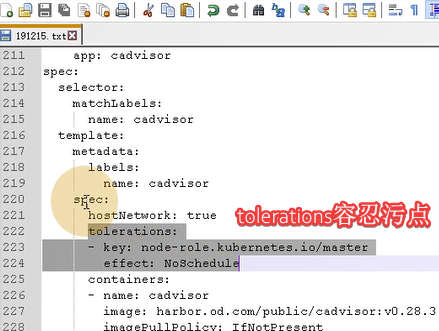

#写在container上面,第二个spec下面
污点容忍后,就可以在打了污点的节点上运行
污点2种动作:
Kubectl taint node hdss7-21.host.com quedian=buxijiao:NoSchedule #对于没匹配到的不允许调度到该污点节点
Kubectl taint node hdss7-21.host.com quedian=buxijiao:NoExecute #对于匹配到的,允许调度到该节点,但不允许你运行你的pod
# 被打了NoExecute的污点,如果有其他节点正常,一般也不会调度过去.

去掉污点就是,key-,,,value可以不写的,污点区分主要是靠key
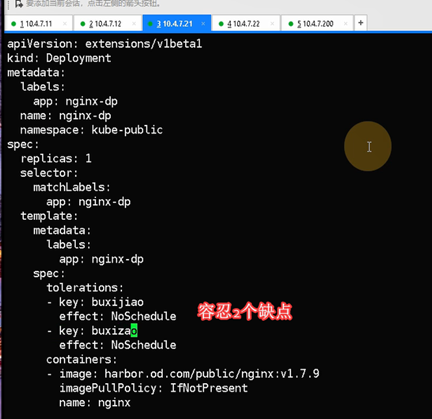
#因为21节点上有2个污点,不洗脚和不洗澡,pod也得容忍2个这样的污点才能调度过去. #只容忍1个污点调度不过去
应用场景
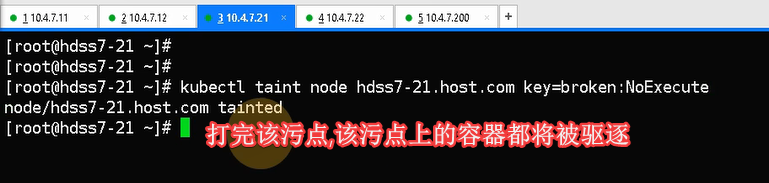
1. 针对io密集型来区分到不同磁盘类型的节点
2. ,还可以根据占用内存特别多的promtheus单独跑一个节点
3. 某个运算节点要下线维修,将该节点打上污点,将pod驱逐;
Kubectl taint node hdss7-21.host.com key=broken:NoExecute
部署blackbox-expoter
最常用的监控组件:监控业务容器的存活性,promtheus带着参数来请求blackbox
探测项目存活性,如果项目有http接口,一般走http,没有走tcp,只能走这2种接口.
Blackbox探测项目时,需要在项目pod资源清单加上annotion或者label的匹配规则,供promtheus匹配
#tcp监控项
#http监控项

伸缩并不会报警,因为annotation在pod资源清单中,缩容后,annotation也会消失.
下载上传镜像
运维主机HDSS7-200.host.com上:
[root@hdss7-200 blackbox-exporter]# docker pull prom/blackbox-exporter:v0.15.1
[root@hdss7-200 blackbox-exporter]# docker tag 81b70b6158be harbor.od.com/public/blackbox-exporter:v0.15.1
[root@hdss7-200 ~]# docker push harbor.od.com/public/blackbox-exporter:v0.15.1
准备资源配置清单
• ConfigMap
• Deployment
• Service
• Ingress
mkdir /data/k8s-yaml/blackbox-exporter/
vi /data/k8s-yaml/blackbox-exporter/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: kube-system
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
timeout: 2s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200,301,302]
method: GET
preferred_ip_protocol: "ip4"
tcp_connect:
prober: tcp
timeout: 2s
vi /data/k8s-yaml/blackbox-exporter/deployment.yaml
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: blackbox-exporter
namespace: kube-system
labels:
app: blackbox-exporter
annotations:
deployment.kubernetes.io/revision: 1
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
volumes:
- name: config
configMap:
name: blackbox-exporter
defaultMode: 420
containers:
- name: blackbox-exporter
image: harbor.od.com/public/blackbox-exporter:v0.15.1
args:
- --config.file=/etc/blackbox_exporter/blackbox.yml
- --log.level=debug
- --web.listen-address=:9115
ports:
- name: blackbox-port
containerPort: 9115
protocol: TCP
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: 100m
memory: 50Mi
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
readinessProbe: #就绪性探针,对于不存活的节点不提供访问
tcpSocket:
port: 9115
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
imagePullPolicy: IfNotPresent
imagePullSecrets:
- name: harbor
restartPolicy: Always
vi /data/k8s-yaml/blackbox-exporter/service.yaml
kind: Service
apiVersion: v1
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
selector:
app: blackbox-exporter
ports:
- protocol: TCP
port: 9115
name: http
vi /data/k8s-yaml/blackbox-exporter/ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
rules:
- host: blackbox.od.com
http:
paths:
- backend:
serviceName: blackbox-exporter
servicePort: 9115
解析域名
HDSS7-11.host.com上
复制/var/named/od.com.zone
blackbox A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-21 ~]# dig -t A blackbox.od.com @192.168.0.2 +short
10.4.7.10
应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/configmap.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/deployment.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/service.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/ingress.yaml
浏览器访问
http://blackbox.od.com
三、部署prometheus及其配置详解
部署prometheus
# docker pull prom/prometheus:v2.14.0
# docker tag 7317640d555e harbor.od.com/infra/prometheus:v2.14.0
# docker push harbor.od.com/infra/prometheus:v2.14.0
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/prometheus
[root@hdss7-200 ~]# cd /data/k8s-yaml/prometheus
资源配置清单-rbac
[root@hdss7-200 prometheus]# cat rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
namespace: infra
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: infra
资源配置清单-dp
加上--web.enable-lifecycle启用远程热加载配置文件
调用指令是curl -X POST http://localhost:9090/-/reload
storage.tsdb.min-block-duration=10m #只加载10分钟数据到内存
storage.tsdb.retention=72h #保留72小时数据
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "5"
labels:
name: prometheus
name: prometheus
namespace: infra
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 7
selector:
matchLabels:
app: prometheus
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: prometheus
spec:
nodeName:
hdss7-21.host.com #与jenkins毫内存大的错开,指定pod运行位置
containers:
- name: prometheus
image: harbor.od.com/infra/prometheus:v2.14.0
imagePullPolicy: IfNotPresent
command:
- /bin/prometheus #启动promtheus命令
args:
- --config.file=/data/etc/prometheus.yml #配置文件
- --storage.tsdb.path=/data/prom-db #容器里目录
- --storage.tsdb.min-block-duration=10m #只加载10分钟数据到内存,虚拟机测试
- --storage.tsdb.retention=72h #存多少时间的数据,测试环境
- --web.enable-lifecycle
#启用远程热加载配置文件
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /data #容器挂载目录
name: data
resources: #限制容器资源的一种配置方法
requests:#申请
cpu: "1000m" #1000m=1000毫核=1核
memory: "1.5Gi"
limits: #不能超过
cpu: "2000m"
memory: "3Gi"
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
serviceAccountName: prometheus
volumes:
- name: data
nfs:
server: hdss7-200
path: /data/nfs-volume/prometheus #宿主机目录,上面的容器目录挂载到该目录
资源配资清单-svc
vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: infra
spec:
ports:
- port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
资源配置清单-ingress
vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: traefik
name: prometheus
namespace: infra
spec:
rules:
- host: prometheus.od.com
http:
paths:
- path: /
backend:
serviceName: prometheus
servicePort: 9090
拷贝证书
在200主机上
创建必要的目录,prometheus挂载出来的目录
# mkdir -p /data/nfs-volume/prometheus/{etc,prom-db}
拷贝配置文件中用到的证书
# cd /data/nfs-volume/prometheus/etc/
# cp /opt/certs/ca.pem ./
# cp /opt/certs/client.pem ./
# cp /opt/certs/client-key.pem ./
准备prometheus的配置文件
在运维主机hdss7-200.host.com上:
修改prometheus配置文件:别问为啥这么写,问就是不懂~
# vi /data/nfs-volume/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'etcd'
tls_config:
ca_file: /data/etc/ca.pem
cert_file: /data/etc/client.pem
key_file: /data/etc/client-key.pem
scheme: https
static_configs:
- targets:
- '10.4.7.12:2379'
- '10.4.7.21:2379'
- '10.4.7.22:2379'
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
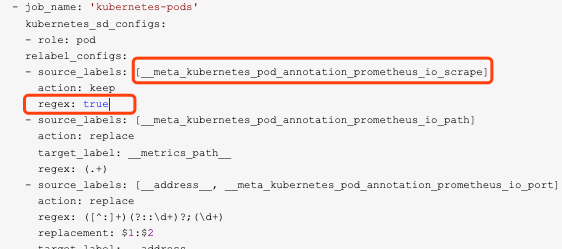
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:10255
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:4194
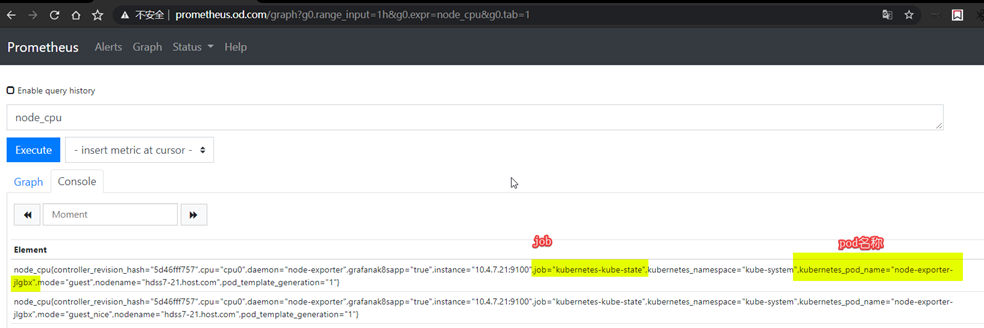
- job_name: 'kubernetes-kube-state'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
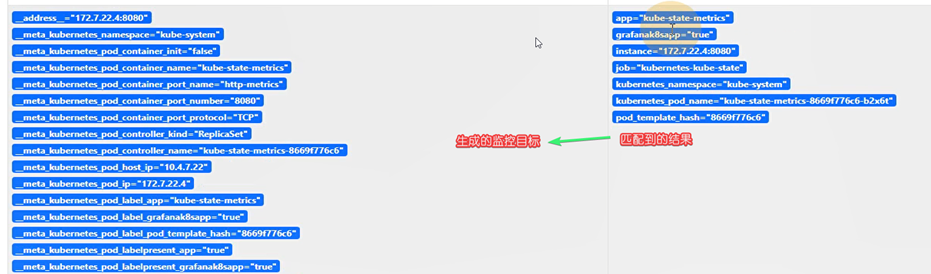
- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]
regex: .*true.*
action: keep
- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']
regex: 'node-exporter;(.*)'
action: replace
target_label: nodename
- job_name: 'blackbox_http_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: http
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+);(.+)
replacement: $1:$2$3
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox_tcp_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [tcp_connect]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: tcp
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'traefik'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: keep
regex: traefik
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
添加dns解析:
[root@hdss7-11 ~]# vi /var/named/od.com.zone
prometheus A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# dig -t A prometheus.od.com @10.4.7.11 +short
10.4.7.10
应用资源配置清单
# kubectl apply -f http://k8s-yaml.od.com/prometheus/rbac.yaml
# kubectl apply -f http://k8s-yaml.od.com/prometheus/dp.yaml
# kubectl apply -f http://k8s-yaml.od.com/prometheus/svc.yaml
# kubectl apply -f http://k8s-yaml.od.com/prometheus/ingress.yaml
检查:
[root@hdss7-21 ~]# kubectl logs prometheus-7f656dbdcd-svm76 -n infra

浏览器验证:prometheus.od.com
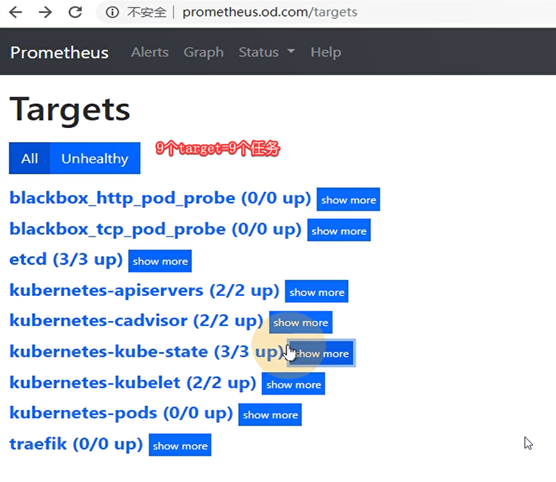
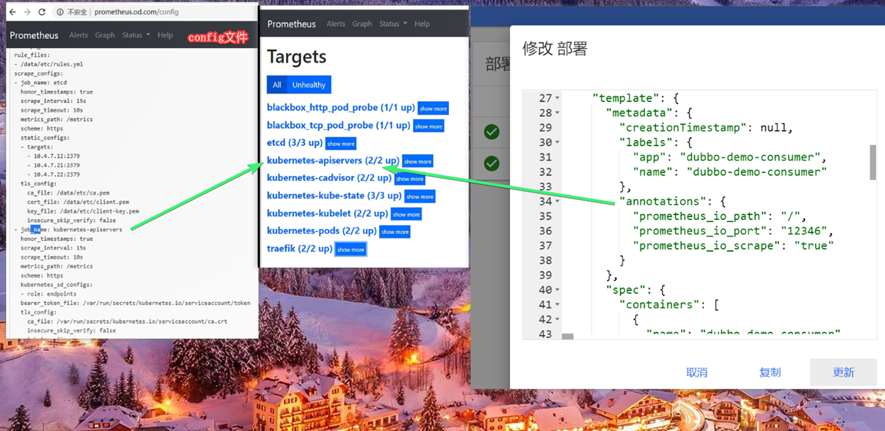
这里点击status-targets,这里展示的就是我们在prometheus.yml中配置的job-name,这些targets基本可以满足我们收集数据的需求。
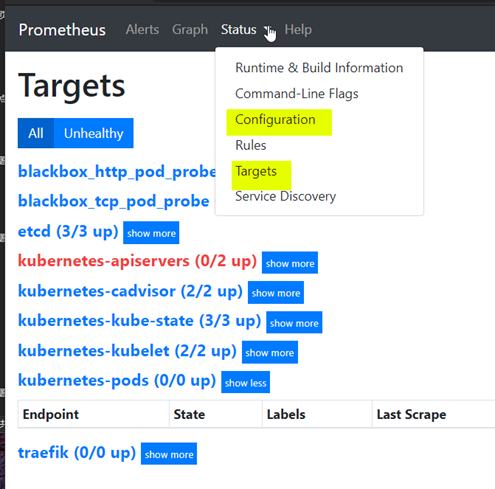
配置prometheus
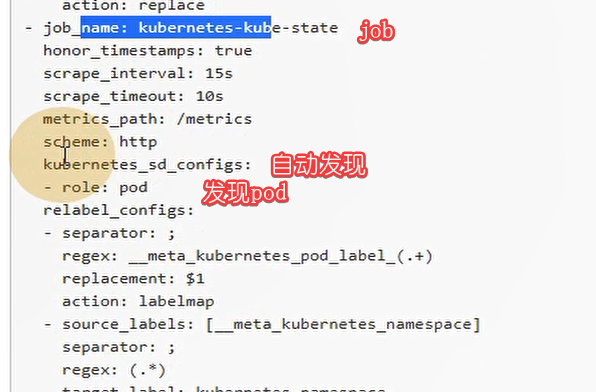
Configuration
决定了多少秒curl一下exporter组件,返回k8s集群信息
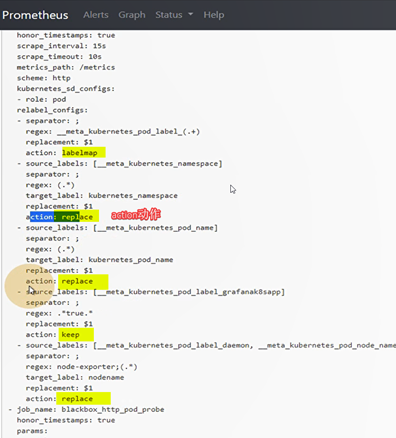




动作action,keep,只保留匹配到的
动作action,drop,没标签,没匹配到的
函数使用方法
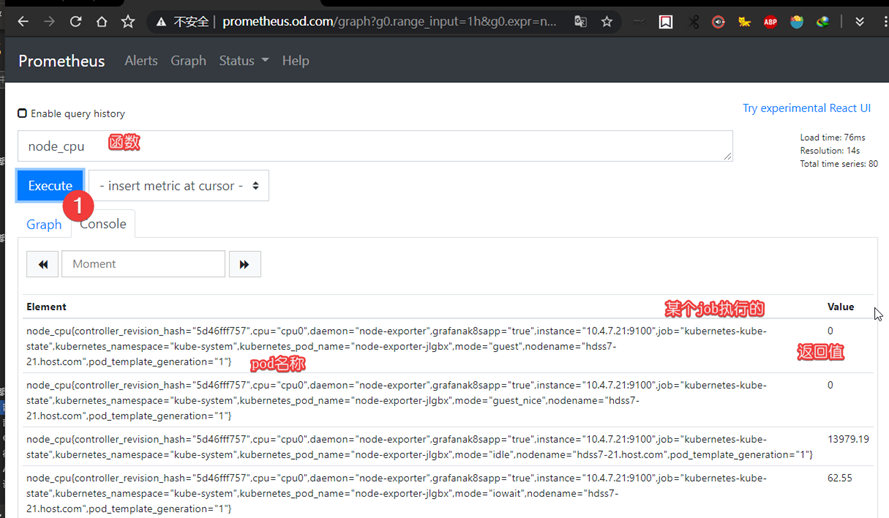
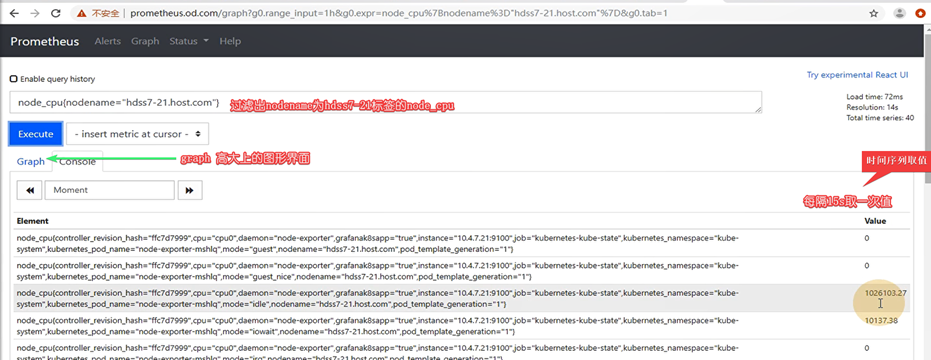
使pod匹配上promtheus的监控
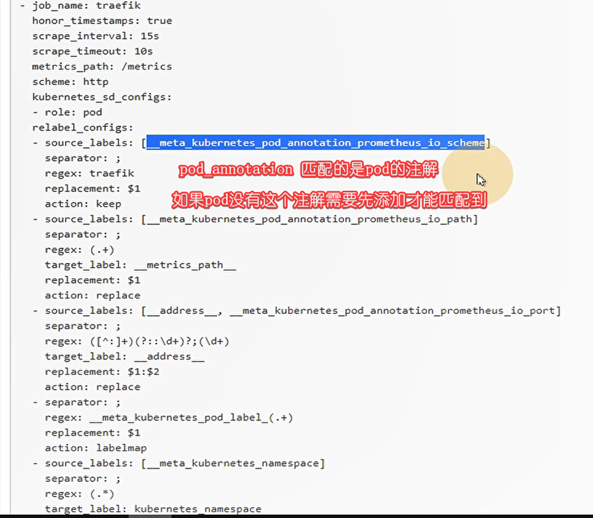
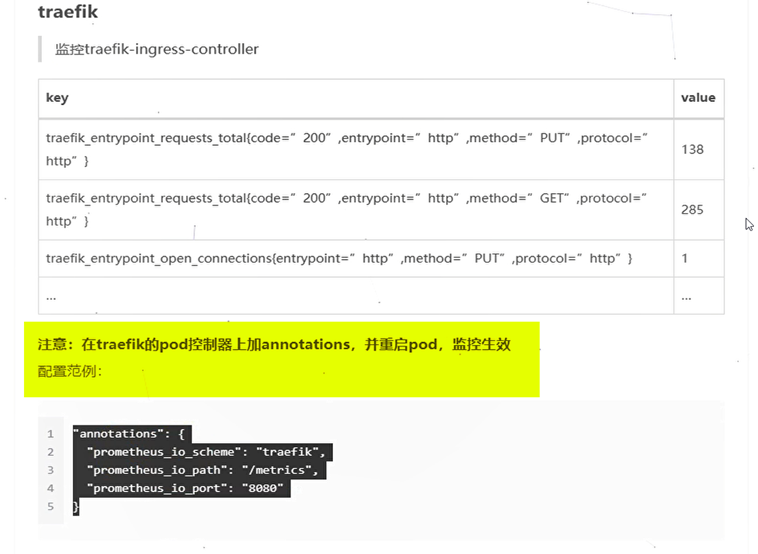
traefik匹配监控
修改traefik的yaml:
从dashboard里找到traefik的yaml,跟labels同级添加annotations
"annotations": {
"prometheus_io_scheme": "traefik",
"prometheus_io_path": "/metrics",
"prometheus_io_port": "8080"
}
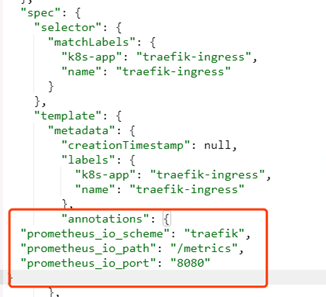
注意前面有个逗号,
Template-àmetadataàannotation
等待pod重启以后,在去prometheus上去看
[root@hdss7-21 ~]# kubectl delete pod traefik-ingress-9jcr9 -n kube-system
[root@hdss7-21 ~]# kubectl delete pod traefik-ingress-wb7cs -n kube-system
自动发现了
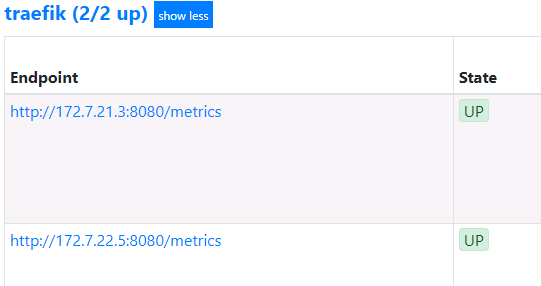

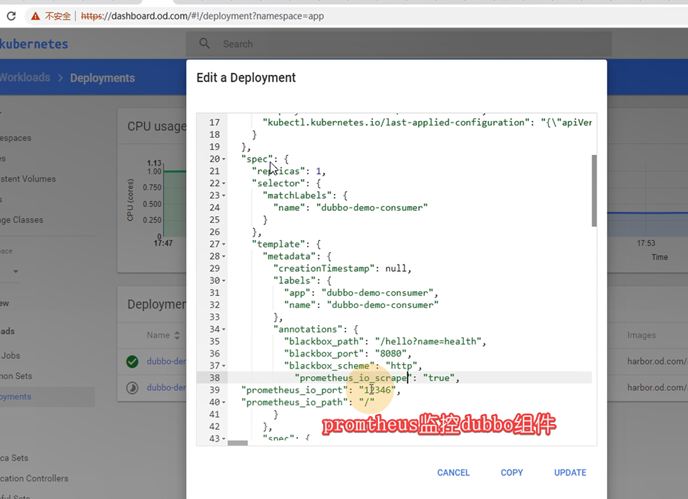
监控dubbo-service
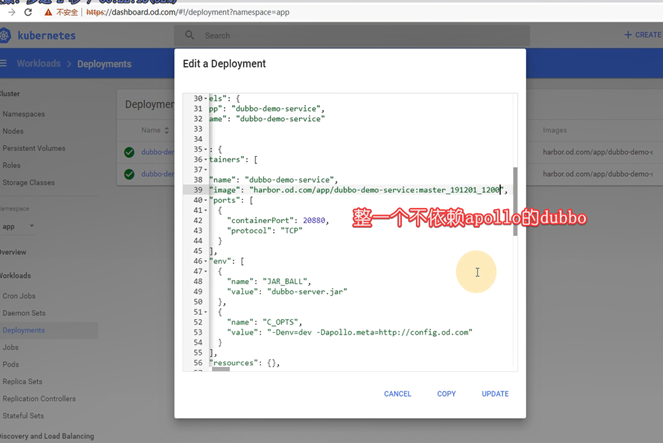
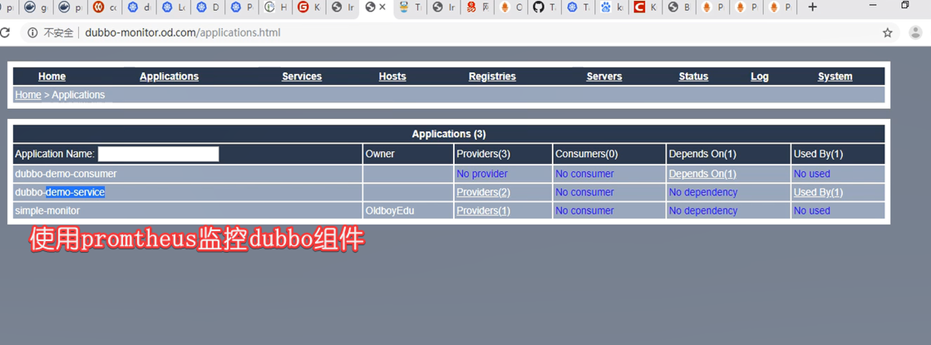
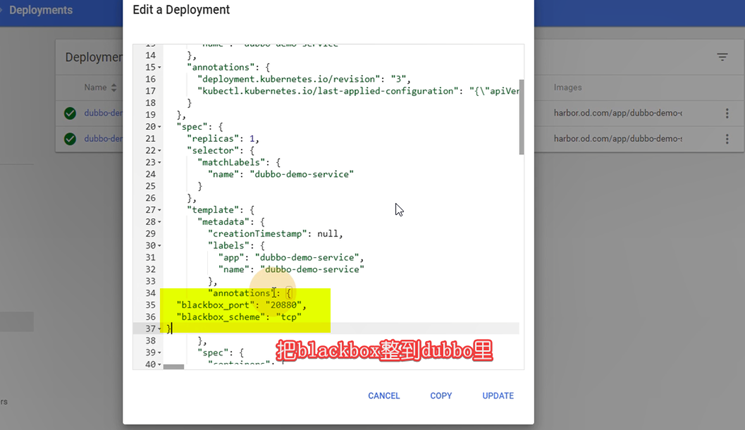
#现在就可以调用了,重启pod,就可以监控到

Endpoint使用的是svc_name
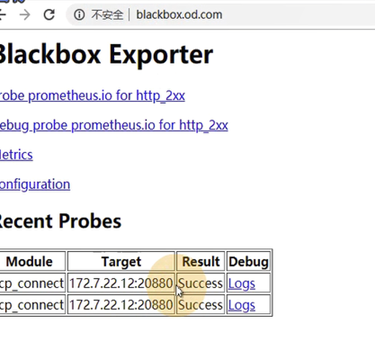
Blackbox相当于pod到promtheus的中间件,promtheus在blackbox取数据
blackbox:
这个是检测容器内服务存活性的,也就是端口健康状态检查,分为tcp和http
首先准备两个服务,将dubbo-demo-service和dubbo-demo-consumer都调整为使用master镜像,不依赖apollo的(节省资源)
等两个服务起来以后,首先在dubbo-demo-service资源中添加一个TCP的annotation:
"annotations": {
"blackbox_port": "20880",
"blackbox_scheme": "tcp"
}


这里会自动发现我们服务中,运行tcp port端口为20880的服务,并监控其状态
监控dubbo-demo-consumer
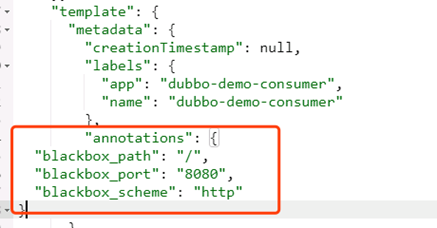
接下来在dubbo-demo-consumer资源中添加一个HTTP的annotation:
"annotations": {
"blackbox_path": "/hello?name=health",
"blackbox_port": "8080",
"blackbox_scheme": "http"
}
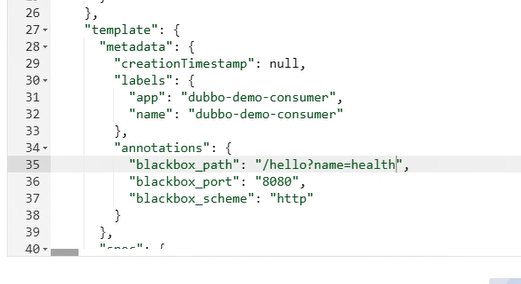
#检查接口要写对
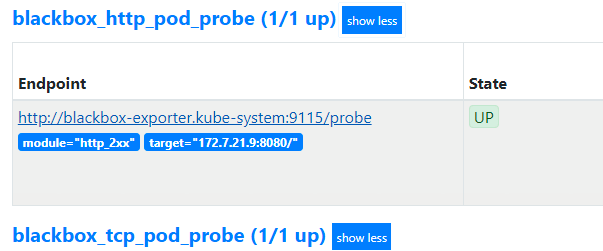
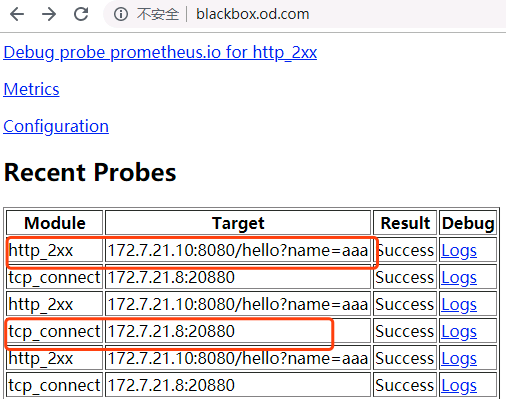
去检查blackbox.od.com
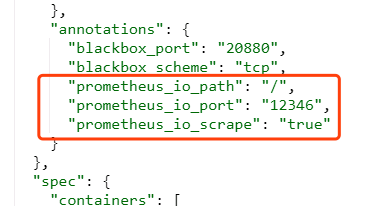
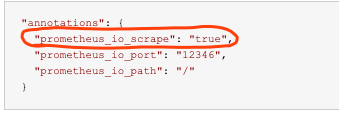
添加监控jvm信息的annotation:
"annotations": {
"prometheus_io_scrape": "true",
"prometheus_io_port": "12346",
"prometheus_io_path": "/"
}
dubbo-demo-service和dubbo-demo-consumer都添加:
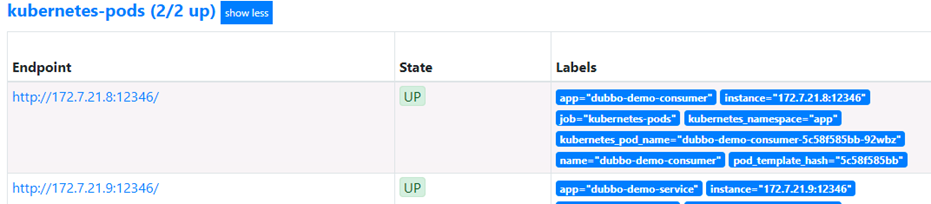
匹配规则,要去prometheus.yml中去看。
四、部署云监控展示平台Grafana
下载上传镜像:
# docker pull grafana/grafana:5.4.2
# docker tag 6f18ddf9e552 harbor.od.com/infra/grafana:v5.4.2
# docker push harbor.od.com/infra/grafana:v5.4.2
准备资源配置清单:
创建目录
# mkdir /data/nfs-volume/grafana
cd /data/k8s-yaml/grafana
1、rbac.yaml
vi rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
rules:
- apiGroups:
- "*"
resources:
- namespaces
- deployments
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana
subjects:
- kind: User
name: k8s-node
2、dp.yaml
vi dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
name: grafana
namespace: infra
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 7
selector:
matchLabels:
name: grafana
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: grafana
name: grafana
spec:
containers:
- name: grafana
image: harbor.od.com/infra/grafana:v5.4.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /var/lib/grafana
name: data
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
volumes:
- nfs:
server: hdss7-200
path: /data/nfs-volume/grafana
name: data
3、svc.yaml
vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: infra
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 3000
selector:
app: grafana
4、ingress.yaml
vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: infra
spec:
rules:
- host: grafana.od.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
域名解析:
[root@hdss7-11 ~]# vi /var/named/od.com.zone
grafana A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
应用资源配置清单:
# kubectl apply -f http://k8s-yaml.od.com/grafana/rbac.yaml
# kubectl apply -f http://k8s-yaml.od.com/grafana/dp.yaml
# kubectl apply -f http://k8s-yaml.od.com/grafana/svc.yaml
# kubectl apply -f http://k8s-yaml.od.com/grafana/ingress.yaml
五、Grafana配置及插件仪表盘制作

设置
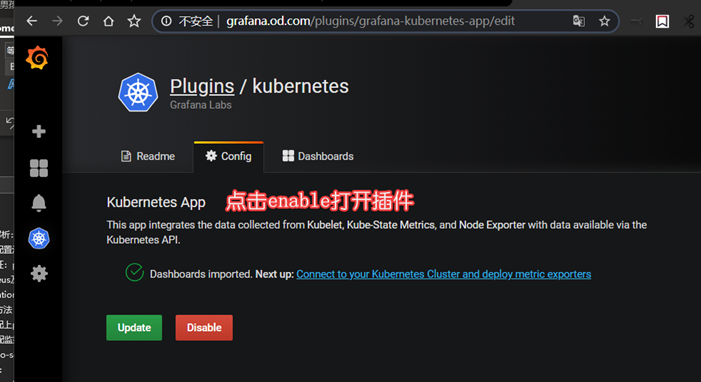
装插件
进入容器安装插件:
安装有点慢
# kubectl exec -it grafana-d6588db94-xr4s6 /bin/bash -n infra
grafana-cli plugins install grafana-kubernetes-app
grafana-cli plugins install grafana-clock-panel
grafana-cli plugins install grafana-piechart-panel
grafana-cli plugins install briangann-gauge-panel
grafana-cli plugins install natel-discrete-panel
删除grafana的pod,重启pod
[root@hdss7-21 ~]# kubectl delete pod grafana-d6588db94-7c66l -n infra

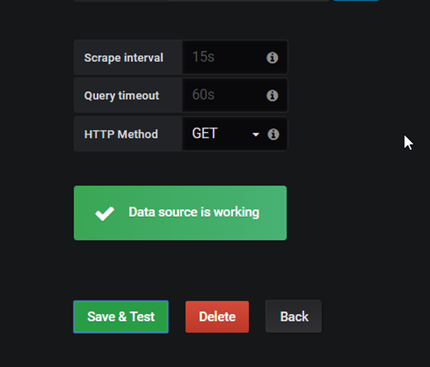
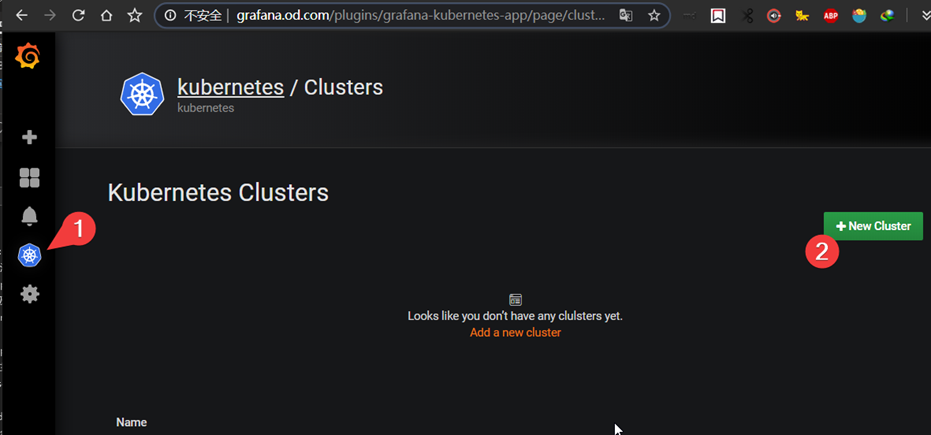
添加promtheus数据源
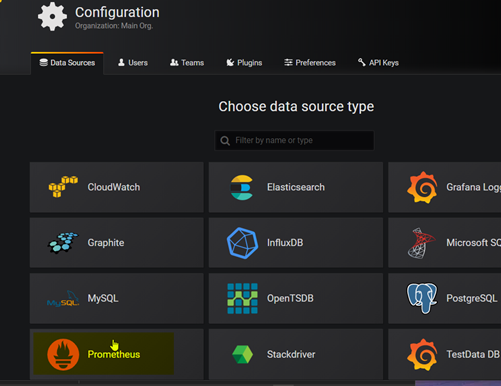
Add 数据集
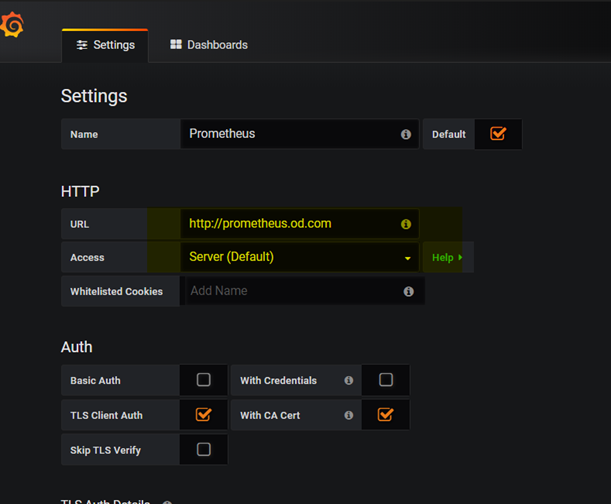
准备证书
[root@hdss7-200 certs]# cat /opt/certs/ca.pem
[root@hdss7-200 certs]# cat /opt/certs/client.pem
[root@hdss7-200 certs]# cat /opt/certs/client-key.pem

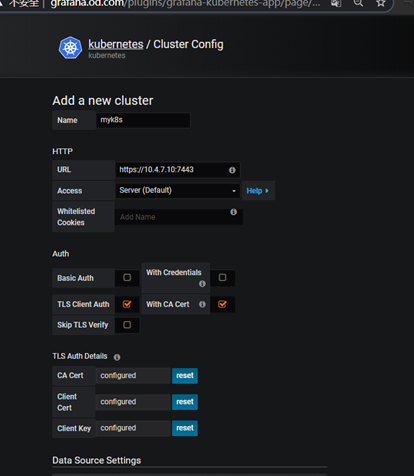
配置插件kubernetes
K8s插件配置
7443会代理到21,22的apiserver端口6443

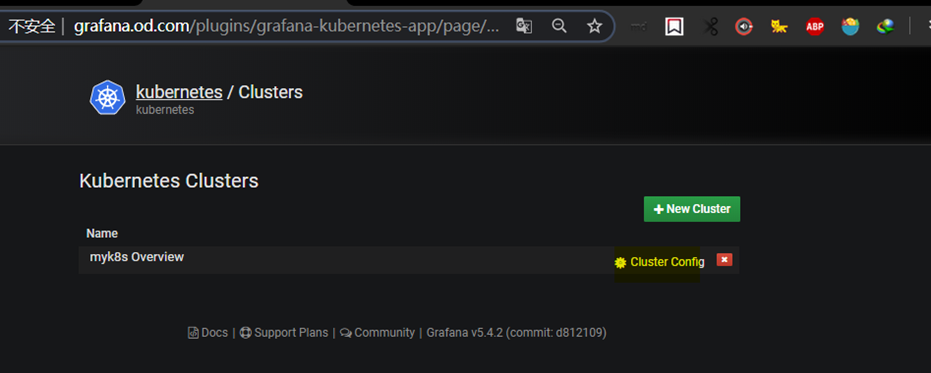
添加完需要稍等几分钟,在没有取到数据之前,会报http forbidden,没关系,等一会就好。大概2-5分钟。
Container不显示数据,改bug
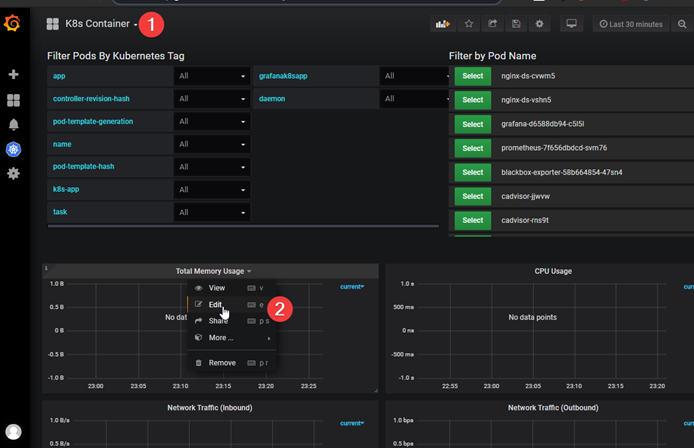
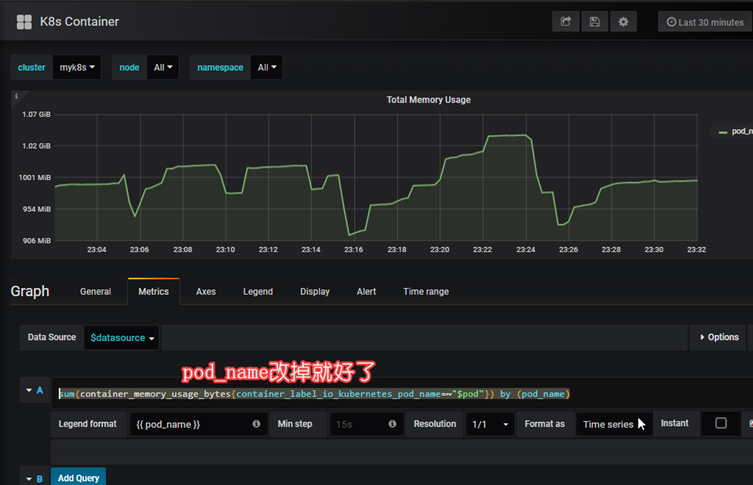
sum(container_memory_usage_bytes{container_label_io_kubernetes_pod_name=~"$pod"}) by (pod_name)
sum(container_memory_usage_bytes{container_label_io_kubernetes_pod_name=~"$pod"}) by (container_label_io_kubernetes_pod_name)
删除重建grafana-demo

加载其他dashboard
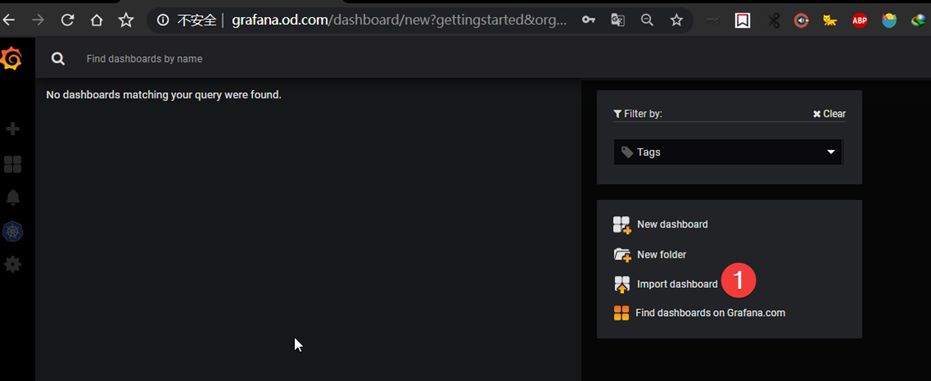
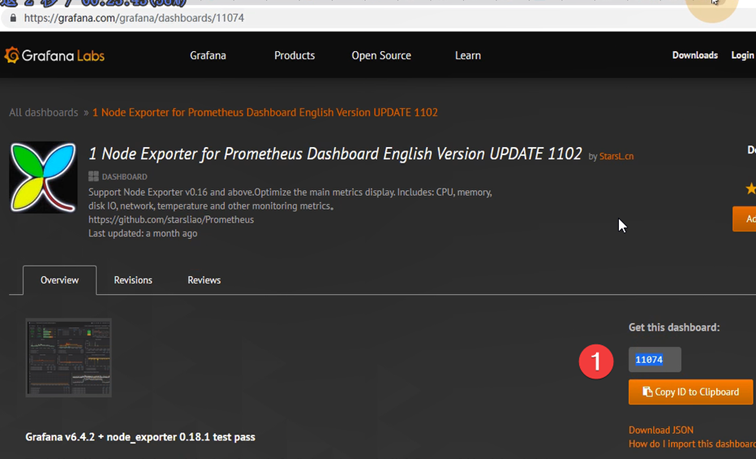

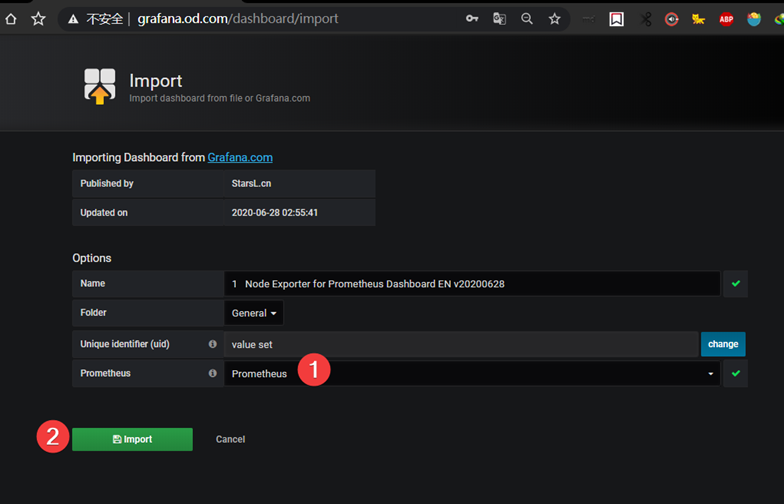 ''
''
监控dubbo-jvm
加完注解,自动拉到监控里,再根据grafana建立的仪表盘在promtheus取数据展示

六、微服务容器接入容器云监控原理
内容中在第五章,没细分
七、Alertmanager组件进行监控告警
配置alert告警插件:
# docker pull docker.io/prom/alertmanager:v0.14.0
# docker tag 23744b2d645c harbor.od.com/infra/alertmanager:v0.14.0
# docker push harbor.od.com/infra/alertmanager:v0.14.0
资源配置清单:
mkdir /data/k8s-yaml/alertmanager
1、cm.yaml
vi cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: infra
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com'
smtp_from: '731616192@qq.com'
smtp_auth_username: '731616192@qq.com'
smtp_auth_password: 'bdieyxrflckobcag'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '731616192@qq.com'
send_resolved: true
2、dp.yaml
vi dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: alertmanager
namespace: infra
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com/infra/alertmanager:v0.14.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
imagePullSecrets:
- name: harbor
3、svc.yaml
vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: infra
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 9093
应用资源配置清单
kubectl apply -f http://k8s-yaml.od.com/alertmanager/cm.yaml
kubectl apply -f http://k8s-yaml.od.com/alertmanager/dp.yaml
kubectl apply -f http://k8s-yaml.od.com/alertmanager/svc.yaml
配置基础报警规则:
vi /data/nfs-volume/prometheus/etc/rules.yml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
在prometheus.yml中添加配置:
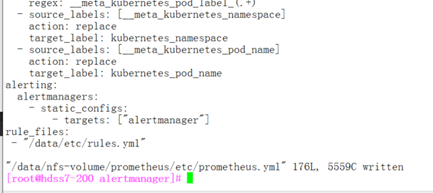
[root@hdss7-200 alertmanager]# vi /data/nfs-volume/prometheus/etc/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"

平滑重启promtheus
#修改完配置文件重启promtheus
#在21节点上(promtheus运行所在节点)
[root@hdss7-21 ~]# ps aux|grep prometheus
[root@hdss7-21 ~]# kill -SIGHUP 3441 #promtheus支持kill传递信号重载
重载配置:
# curl -X POST http://prometheus.od.com/-/reload
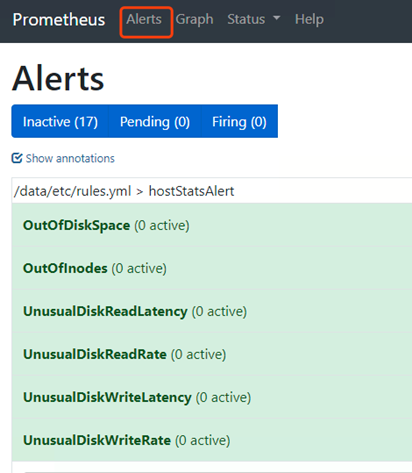
以上这些就是我们的告警规则
测试告警:
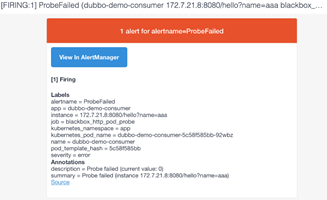
把app命名空间里的dubbo-demo-service给停掉:

看下blackbox里的信息:

看下alert:
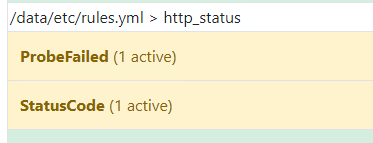
红色的时候就开会发邮件告警:
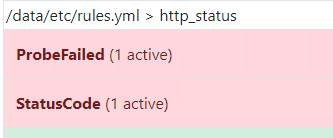
已经收到告警了,后续上生产,还会更新如何添加微信、钉钉、短信告警
如果需要自己定制告警规则和告警内容,需要研究一下promql,自己修改配置文件。
八、课程总结
对应关系
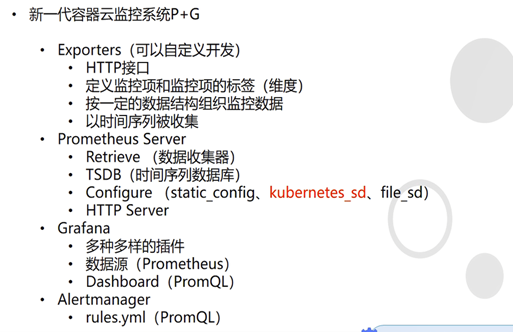
Exporter
4种,实现不同功能
Promtheus server
Retrieve(数据收集器)-à在exporter取数据-à存储到tsdb(时间序列数据库)
Configure 静态配置,动态服务发现,基于文件服务发现
Httpserver,promtheus提供的一个web访问界面
k8s-3-容器云监控系统的更多相关文章
- Kubernetes容器云平台建设实践
[51CTO.com原创稿件]Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署.大规模可伸缩.应用容器化管理.伴随着云原生技术的迅速崛起,如今Kubernetes 事实上已经 ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- 打造云原生大型分布式监控系统(四): Kvass+Thanos 监控超大规模容器集群
概述 继上一篇 Thanos 部署与实践 发布半年多之后,随着技术的发展,本系列又迎来了一次更新.本文将介绍如何结合 Kvass 与 Thanos,来更好的实现大规模容器集群场景下的监控. 有 Tha ...
- 容器编排系统K8s之Prometheus监控系统+Grafana部署
前文我们聊到了k8s的apiservice资源结合自定义apiserver扩展原生apiserver功能的相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/ ...
- 容器云平台No.7~kubernetes监控系统prometheus-operator
简介 prometheus-operator Prometheus:一个非常优秀的监控工具或者说是监控方案.它提供了数据搜集.存储.处理.可视化和告警一套完整的解决方案.作为kubernetes官方推 ...
- 微服务与K8S容器云平台架构
微服务与K8S容器云平台架构 微服务与12要素 网络 日志收集 服务网关 服务注册 服务治理- java agent 监控 今天先到这儿,希望对技术领导力, 企业管理,系统架构设计与评估,团队管理, ...
- Longhorn,企业级云原生容器分布式存储 - 监控(Prometheus+AlertManager+Grafana)
内容来源于官方 Longhorn 1.1.2 英文技术手册. 系列 Longhorn 是什么? Longhorn 企业级云原生容器分布式存储解决方案设计架构和概念 Longhorn 企业级云原生容器分 ...
- vivo 容器集群监控系统架构与实践
vivo 互联网服务器团队-YuanPeng 一.概述 从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实 ...
- [转帖]容器云之K8s自动化安装方式的选择
容器云之K8s自动化安装方式的选择 时间 2016-12-05 19:10:53 极客头条 原文 http://geek.csdn.net/news/detail/127426 主题 Kubern ...
随机推荐
- pg_rman的安装与使用
1.下载对应数据库版本及操作系统的pg_rman源码 https://github.com/ossc-db/pg_rman/releases 本例使用的是centos6.9+pg10,因此下载的是pg ...
- RocketMQ—消息队列入门
消息队列功能介绍 字面上说的消息队列是数据结构中"先进先出"的一种数据结构,但是如果要求消除单点故障,保证消息传输可靠性,应对大流量的冲击,对消息队列的要求就很高了.现在互联网的& ...
- 20V,24V转5V,20V,24V转3.3V降压芯片,IC介绍
常用的20V和24V转5V,3.3V的LDO稳压和DC-DC降压芯片: PW6206系列是一款高精度,高输入电压,低静态电流,高速,低压降线性稳压器具有高纹波抑制.输入电压高达40V,负载电流高达10 ...
- mysqldumpslow基本使用
参数解释 -s, 是表示按照何种方式排序 c: 访问计数 l: 锁定时间 r: 返回记录 t: 查询时间 al:平均锁定时间 ar:平均返回记录数 at:平均查询时间 -t, 是top n的意思,即为 ...
- vue的nuxt框架中使用vue-video-player
一.基本需求:使用nuxt框架,需要在移动端网页中播放视频. 二.文中解决的基本问题: 1.vue-video-player在nuxt中怎么使用. 2.由于为了适配移动端,使用了 ...
- udp 连接
在今天的内容里,我对 UDP 套接字调用 connect 方法进行了深入的分析.之所以对 UDP 使用 connect,绑定本地地址和端口,是为了让我们的程序可以快速获取异步错误信息的通知,同时也可以 ...
- How does Circus stack compare to a classical stack?
Frequently Asked Questions - Circus 0.15.0 documentation https://circus.readthedocs.io/en/latest/faq ...
- 【转载】【网络安全】渗透中 PoC、Exp、Payload 与 Shellcode 的区别
原文地址 渗透中 PoC.Exp.Payload 与 Shellcode 的区别 概念 PoC,全称"Proof of Concept",中文"概念验证",常指 ...
- 龙芯fedora28日常生存指南
2021-01-30 v0.0.5 从0.0.1开始改了非常多,一月余时间的花费渴望为其他人提供一点帮助,能够快速上手. 这主要是这一年来我从3B1500到3A4000再到福珑2的日常使用记录,是之前 ...
- LOJ10043
题目描述 原题来自:HNOI 2002 Tiger 最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger 拿出了公司的账本,账本上记录了公司成 ...