Kafka 0.9 新消费者API
kafka诞生之初,它自带一个基于scala的生产者和消费者客户端。但是慢慢的我们认识到这些API有很多限制。比如,消费者有一个“高级”API支持分组和异常控制,但是不支持很多更复杂的应用场景;它也有一个“低级”API,支持对细节的完全控制,但是要求码农自己控制失败和异常。所以重新设计了它们。
这个过程的第一阶段就是在0.8.1版本的时候重写了生产者API。在最近的0.9版本中完成了第二阶段,提供了消费者的新API。建立在新的分组协议只是,新的消费者带来以下好处:
- API更加简洁:新的消费者API综合了老版本的“高级”和“低级”API的功能,同时提供了分组机制和lower level access来实现自己的消费策略;
- 减少了依赖:新的消费者API是用纯java写的。没有了scala和zk的依赖,让代码工程更轻量级;
- 更安全:新的消费者API支持kafka0.9版本的安全机制;
- 新的消费者也增加了一系列的机制来控制组消费时的容错。老的API使用大量的java代码实现的(与ZK交互过多),复杂的逻辑很难让其他语言的消费者实现。新的API使这变得更简单。现在已经有C版本的客户端了。
虽然新的消费者是被重新设计过的和新的交互机制,但很多感念没有本质区别,所以熟悉老API的码农也不会觉得新API生硬。但是,也有一些特别细微的细节相对于组管理和线程模型需要在码代码的时候注意。
还有一个注意点:新的消费者API还是测试版本。(不稳定哦,随时会有BUG冒出来,伟大的踩坑者)
Getting Started
略过旧API中的分组消费介绍。。。
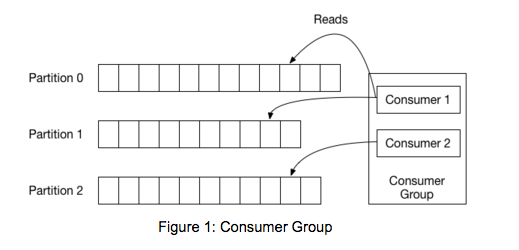
旧的API强依赖ZK做分组管理,新的API使用kafka自己的分组协调机制。针对每个消费组,会从所有的broker中挑选出一个出来充当这个组的“协调员”。协调员负责管理该组的状态。它的主要任务是,当新的组成员进入、老的组成员离开和元数据改变时进行分区的协调分配。这种重新分配分区的行为称之为“重新平衡组”。
当一个组首次被初始化,每个分区的消费者一般会从最早或最近的数据开始读。然后在每个分区的消息被依次读出。在消费过程中,消费者会提交已经成功处理了的消息的偏移量。例如,在下图中,消费者正在读的消息的偏移量是6,而它最近一次提交的偏移量是1:
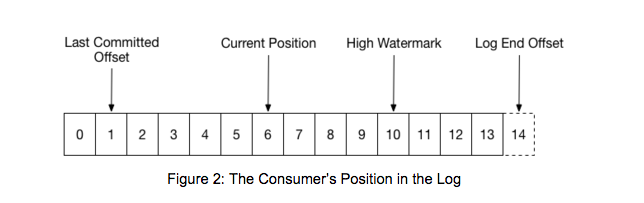
当一个分区被重新分配给组中的另一个消费者时,这个消费者会从上一个消费者最后一次提交的偏移量处开始读。如果上面例子中的消费者突然崩溃了,其他组成员读的时候会从1开始读。这种情况下,它会从1到6重新消费一遍。
上图中还标注了其他两个位置。Log End Offset标记了最后一条消息写入后的偏移量。High Watermark标记了最后被其他replicas同步成功了的偏移量。对于消费者来说,只能读到High Watermark处,这样为了防止未同步的消息被读了以后丢失掉。
配置和初始化
在开始使用新的消费者API之前,先把 kafka-clients 这个依赖加到工程中。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.1</version>
</dependency>
消费者通过Properties文件来配置消费属性,下面是一个最小配置:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "consumer-tutorial");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
与旧的消费者和生产者一样,我们需要配置broker连接参数。我们不需要提供集群中所有服务器的连接参数,客户端会根据给定的连接参数集合得到所有的存活broker。客户端还需要配置key和value的初始化类。最后配置group.id。
订阅TOPIC
在开始消费之前,必须先订阅一些需要读取消息的topic。下面的例子中,同时订阅了foo和bar两个topic:
consumer.subscribe(Arrays.asList("foo", "bar"));
订阅后,消费者会与组内其他消费者协调分区的分配。在开始消费消息的时候这些事自动完成的。稍后会展示如何使用分配API手动指定分区 。但是不能手动和自动一起用。
订阅topic的方法不能增量订阅:每次订阅必须包含要订阅的所有topic。可以随时改变订阅,新的订阅会替换旧的订阅。
基本的POLL循环
消费者需要并行化地读取数据,可能从分布在不同broker的不同topic的不同分区。为了做到这一点,新的API用了近似unix得pool或者select调用:一旦订阅了一些topic,所有未来的协调、重新平衡和数据获取都被一个调用事件所驱动。这需要单个线程掌控所有IO的一个简单而有效的实现。
订阅一个主题后,需要一个事件循环来接受分区的分配和数据的获取。听起来复杂,其实只需要在循环调用poll方法,然后消费者客户端就会处理剩下的事情。每次调用poll方法,都会收到(可能为空)被分配的分区里面的一系列数据。下面是基本例子:
try {
while (running) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
}
} finally {
consumer.close();
}
传进poll方法里面的参数是一个Long类型的,表示等待消息的时间:如果队列里面有消息,会立马返回,如果没有,会等待指定的时间然后返回。
消费者被设计成在自己的线程里面运行。没有外部同步的多线程是不安全的,也是不建议这样做的。
当消费完成后一定记得关闭它,这样会保证组内协调分配分区不会混乱(因为一个分区只能被组内的一个消费者消费)。
上例中使用了一个较小的超时时间为了保证不会有太多延时去关闭消费者。下面这个例子中使用了很长的超时时间和用wakeup API来跳出循环:
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + “: ” + record.value());
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
consumer.close();
}
wakeup操作是线程安全的:
/**
* Wakeup the consumer. This method is thread-safe and is useful in particular to abort a long poll.
* The thread which is blocking in an operation will throw {@link org.apache.kafka.common.errors.WakeupException}.
*/
@Override
public void wakeup() {
this.client.wakeup();
}
整合到一起:
public class ConsumerLoop implements Runnable {
private final KafkaConsumer<String, String> consumer;
private final List<String> topics;
private final int id;
public ConsumerLoop(int id,
String groupId,
List<String> topics) {
this.id = id;
this.topics = topics;
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put(“group.id”, groupId);
props.put(“key.deserializer”, StringDeserializer.class.getName());
props.put(“value.deserializer”, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(props);
}
@Override
public void run() {
try {
consumer.subscribe(topics);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records) {
Map<String, Object> data = new HashMap<>();
data.put("partition", record.partition());
data.put("offset", record.offset());
data.put("value", record.value());
System.out.println(this.id + ": " + data);
}
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
consumer.close();
}
}
public void shutdown() {
consumer.wakeup();
}
}
测试这里例子的话需要造一些数据。最简单的方式是使用kafka-verifiable-producer.sh这个脚本。
# bin/kafka-topics.sh --create --topic consumer-tutorial --replication-factor --partitions --zookeeper localhost: # bin/kafka-verifiable-producer.sh --topic consumer-tutorial --max-messages --broker-list localhost:
然后是驱动类:
public static void main(String[] args) {
int numConsumers = 3;
String groupId = "consumer-tutorial-group"
List<String> topics = Arrays.asList("consumer-tutorial");
ExecutorService executor = Executors.newFixedThreadPool(numConsumers);
final List<ConsumerLoop> consumers = new ArrayList<>();
for (int i = 0; i < numConsumers; i++) {
ConsumerLoop consumer = new ConsumerLoop(i, groupId, topics);
consumers.add(consumer);
executor.submit(consumer);
}
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
for (ConsumerLoop consumer : consumers) {
consumer.shutdown();
}
executor.shutdown();
try {
executor.awaitTermination(5000, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace;
}
}
});
}
例子中启动了三个线程来消费消息,每个线程给一个单独的ID,这样就能清楚的看到哪个线程消费到了哪些信息。shutdown hook会调用线程的wakeup方法来结束消费。在IDE里面可以点击关闭或者在命令行里面使用Ctrl-C。输出结果:
2: {partition=0, offset=928, value=2786}
2: {partition=0, offset=929, value=2789}
1: {partition=2, offset=297, value=891}
2: {partition=0, offset=930, value=2792}
1: {partition=2, offset=298, value=894}
2: {partition=0, offset=931, value=2795}
0: {partition=1, offset=278, value=835}
2: {partition=0, offset=932, value=2798}
0: {partition=1, offset=279, value=838}
1: {partition=2, offset=299, value=897}
1: {partition=2, offset=300, value=900}
1: {partition=2, offset=301, value=903}
1: {partition=2, offset=302, value=906}
1: {partition=2, offset=303, value=909}
1: {partition=2, offset=304, value=912}
0: {partition=1, offset=280, value=841}
2: {partition=0, offset=933, value=2801}
Consumer Liveness
当组内的一个消费者消费某个分区的时候,这些分区上会有一个基于组的锁,即一个组里面一个消费者正在消费某个分区,组内的其他消费者就不能消费这个分区,如果这个消费者一直健康的运行当然最好,如果因为某些原因死掉,你需要把这个锁解掉,然后把分区分给其他消费者。
kafka的组协调机制使用了心跳机制来解决这个问题。每次重新平衡分区分配后,组内消费者开始向组协调员(某个broker)发送心跳。组协调员持续收到某个消费者的心跳,它就认为这个消费者是健康的。协调员每次收到心跳,都会启动一个计时器。当计时器到时间后还没有收到后面的心跳,就认为这个消费者已经挂掉了,就会把这个分区分配给其他合适的消费者。计时器的持续时间是被称为会话超时,由客户端的session.timeout.ms配置。
props.put("session.timeout.ms", "60000");
会话超时机制能保证当消费者挂掉或者网络故障的时候,分区的锁会被释放,并分配给其他消费。老的消费者再发送心跳也不认为它是健康的。
心跳发送线程和poll线程是一起的,正常poll数据的时候才会发送心跳,否则不会发。
会话超时时间默认是30秒,在网络延时大的集群中可以适当调大这个参数,避免非异常情况下的重新分配分区。
Delivery Semantics
当一个组刚创建时,它的初始化offset是根据 auto.offset.reset 这个配置属性来获取的(在0.8中就加入了这个配置项)。一旦消费者开始消费,它根据应用的需求来提交offset。每次组内重新平衡partition以后,读offset的位置就是上一次最后提交的offset。如果一个应用成功处理了某条消息,但是在成功提交offset之前就崩溃掉了,那么下一个消费者将重新读这条消息,造成重复读。当然,offset的提交频率越快,这种损失就越小。
当我们将 enable.auto.commit 属性设置为true时(默认为true),消费者会在配置属性 auto.commit.interval.ms 的时间间隔后自动提交offset。时间间隔越小,崩溃造成的损失越小,随之影响性能。
如果要自己手动控制offset的提交,则必须将 auto.offset.reset 设置为false。
手动提交offset的API现在还是测试版,但是重要的是如果将它集成到poll循环中。下面代码是一个例子:
try {
while (running) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
try {
consumer.commitSync();
} catch (CommitFailedException e) {
// application specific failure handling
}
}
} finally {
consumer.close();
}
上例中使用了commitSync API来提交,它会在成功返回或者遇到错误之前阻塞。你需要关心的主要错误就是消息处理的时间超过session的时间造成超时。当这种事情真正发生的时候,这个消费者会被踢出去,然后造成CommitFailedException异常。应用应该处理这种异常,在上次成功提交offset之后和失败提交offset之后的消息造成的改变进行回滚。
另外你应该保证必须在消息成功处理后再提交offset。
译自:http://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0.9-consumer-client
Kafka 0.9 新消费者API的更多相关文章
- Kafka 0.11新功能介绍:空消费组延迟rebalance
Kafka 0.11新功能介绍:空消费组延迟rebalance 在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer inst ...
- kafka中生产者和消费者API
使用idea实现相关API操作,先要再pom.xml重添加Kafka依赖: <dependency> <groupId>org.apache.kafka</groupId ...
- Kafka 0.9 新特性
Kafka发布0.9了,这一重磅消息,让小伙伴们激动不已,来看看这个版本有哪些值得关注的地方吧! 一.安全特性 在0.9之前,Kafka安全方面的考虑几乎为0,在进行外网传输时,只好通过Linux的防 ...
- 【cocos2d-js官方文档】五、Cocos2d-JS v3.0的新Action API
新增action中的方法 曾经,当我们须要反复一个action的时候,我们须要: sprite.runAction(cc.Repeat.create(action, 2)); 上面代码中创建了一个新的 ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- Kafka技术内幕 读书笔记之(四) 新消费者——消费者提交偏移量
消费组发生再平衡时分区会被分配给新的消费者,为了保证新消费者能够从分区的上一次消费位置继续拉取并处理消息,每个消费者需要将分区的消费进度,定时地同步给消费组对应的协调者节点 .新AP I为客户端提供了 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(二)
消费者拉取消息 消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互.一个生产者写入的分区和消费者分配的分区都可能有多个,同时多个分区的主副本有可能在同一个节 ...
- Kafka消费者APi
Kafka客户端从集群中消费消息,并透明地处理kafka集群中出现故障服务器,透明地调节适应集群中变化的数据分区.也和服务器交互,平衡均衡消费者. public class KafkaConsumer ...
- Apache Kafka 0.9消费者客户端
当Kafka最初创建时,它与Scala生产者和消费者客户端一起运送.随着时间的推移,我们开始意识到这些API的许多限制.例如,我们有一个“高级”消费者API,它支持消费者组并处理故障转移,但不支持许多 ...
随机推荐
- vsftpd安装与配置--研究tcp与防火墙
vsftpd的配置文件 /etc/vsftpd/vsftpd.conf 主配置文件 /usr/sbin/vsftpd Vsftpd的主程序 /etc/rc.d/init.d/vsftpd 启动脚本 / ...
- [LeetCode 题解]: ZigZag Conversion
前言 [LeetCode 题解]系列传送门: http://www.cnblogs.com/double-win/category/573499.html 1.题目描述 The string ...
- jquery实现简单抽奖功能
一直纠结要怎么用jquery实现抽奖功能,看别人很多都是用flash制作的,找了很多资料,最终找到一个比较适合需求的,我做了些许调整,以下是代码展示(复制下来可以直接使用). 先上图:
- Replication--发布属性immediate_sync
在创建发布时,如果选择立即初始化,会将immediate_sync属性设置为true.如果immediate_sync属性为true时,snapshot文件和发布事务及发布命令将一直保留到指定的事务保 ...
- Conditional Expressions
Conditional Expressions建立一些逻辑关系 The conditional expression classes from django.db import models clas ...
- kvm虚拟机磁盘文件读取小结
kvm虚拟机磁盘挂载还真不是一帆风顺的.xen虚拟化默认就raw格式的磁盘,可以直接挂载,kvm如果采用raw也可以直接挂载,与xen磁盘挂载方式一致. 1.kvm虚拟化相比xen虚拟化来说,工具与方 ...
- linux设置ip别名
修改文件 # vi /etc/hosts 添加地址和别名 192.168.222.126 s1 ##前面是机器ip,后面是别名 测试 [root@bogon /]# ping s1 PING s1 ( ...
- fastcgi main
main函数里 当kill -TERM pid 时, http://redfoxli.github.io/php-fpm-signals.html 这篇文章 说是 1)master主进程接收到sig ...
- NVIDIA TX1/TX2 对比
处理器方面,TX2由TX1的Tegra X1升至Tegra Parker处理器,该处理器由16nm工艺制造,6核心设计,CPU部分由2个丹佛+4个A57核心共同组成. GPU则采用Pascal架构,拥 ...
- Intellij idea maven 引用无法搜索远程仓库的解决方案
打开项目的POM文件,ALT+Insert键 出来添加引用的窗口 说明无法搜索到远程仓库,需要怎么设置呢? 在intellij idea 中配置好maven后 是这样的 如果加载失败,则需要自定义远程 ...