Python内存分配器(如何产生一个对象的过程)
内存分配器
Python中,当要分配内存时,不单纯使用malloc/free,而是在其基础上堆放三个独立的分层,有效的进行分配。
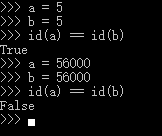
举个栗子:c语言中申请一片空间就需要使用malloc当释放这个空间的时候就要使用free。Python把这一操作放在最底层也就是0层来实现。那么0层之上是用来做什么呢?我们可能遇到过在python里新建了a=5,b=5两个对象,但是这两个对象id是一样的。这就是Python内存分配器的特点之一,它可以不使用malloc申请空间,而是把对象池里已有的对象返回给你。当这个数字足够大比如说a=560000,b=560000,这时候就会发现两个对象的id是不一样的。这其实就是用了0层的malloc了。
Python分配器分层

第0层往下是OS的功能。-2是隐含和机器的物理性相关联的部分,OS的虚拟内存管理器负责这部分功能。-1层是与机器实际进行交互的部分,OS会执行这部分功能。
第3层到第0层调用了一些具有代表性的函数,下图示:以生成字典对象为例

我们可以看到,生成字典它从第三层的分配器,一直走,层层调用。直到使用malloc申请空间。
第零层--通用的基础分配器
以Linux为例,第0层就是指glibc的malloc()。对系统内存进行申请。
Python中并不是在生成所有对象时都去调用malloc(),而是根据要分配的内存大小来改变分配方法。申请的内存大小如果大于256字节(源码中规定为256,可查看源码),就是用malloc();如果小于256就是用1层或者2层。
Objects/obmalloc.c
#define SMALL_REQUEST_THRESHOLD 256
第一层--低级内存分配器
Python中的对象基本上都是小于等于256字节的,并且几乎都是产生后马上就要被废弃的对象。
在这种情况下,如过逐次从0层分配器开始,就会频繁的malloc和free。效率上会有折扣。
因此再分配小对象时,Python内部就会有特殊的处理。实际上执行这一过程的正是第一层和第二层内存分配器。当需要分配小于等于256字节的对象时,就利用第一层的内存分配器,在这一层会事先从第0层开始迅速保留内存空间,将其蓄积起来。第一层的作用就是管理蓄积的空间。(其实就是一个对象池,上层对它进行管理,以应对频繁产生又释放的对象。)
内存结构
根据管理的空间不同,他们各自的叫法也不同。他们之间的关系式包含关系。
- 最小的单位为block,最终给申请者的就是block的地址。
- 比他大的是pool(pool包含block)。
- 最大的是arena(arena包含pool)。
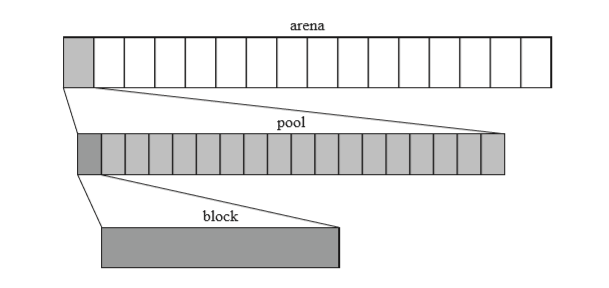
arena > pool >block。为避免频繁的嗲用malloc和free,第0层分配器会以最大的单位arena来保留内存。pool是用于有效管理空的block的。
arena
Objects/objmalloc.c
struct arena_object {
/* malloc后的arena的地址*/
uptr address;
/* 将arena的地址用于给pool使用而对齐的地址 */
block* pool_address;
/* 此arena中空闲的pool数量 */
uint nfreepools;
/* 此arena中pool的总数 */
uint ntotalpools;
/* 连接空闲pool的单向链表 */
struct pool_header* freepools;
/* 稍后说明 */
struct arena_object* nextarena;
struct arena_object* prevarena;
};
以上就是 arena_object结构体,它管理者arena。
- arena_object的成员address保存的是使用第0层内存分配器分配的arena地址。arena大小固定为256k。此大小也是宏定义好的。
- arena_object的成员pool_address中保存的是arena里开头的pool地址。这里有个问题,为什么除了域address之外还要一个pool地址呢?arena的地址和其中第一个的pool地址应该是一致的呀!这是因为我们用到了系统中的页,为了使用页的功能,所以要和页对齐才导致arena地址不是第一个pool地址。(之后又详细说明)
- arena_object还承担着保持被分配的pool的数量,将空pool连接到单向链表的功能。
- 此外arena_object被数组arenas管理。
Objects/obmalloc.c
/* 将arena_object作为元素的数组 */
static struct arena_object* arenas = NULL;
/* arenas的元素数量 */
static uint maxarenas = 0;

- arena_object中有uptr和block和uint。他们都是用宏定义 定义的别名。
#undef uchar
#define uchar unsigned char /* 约8位 unsigned表示无符号*/
#undef uint
#define uint unsigned int /* 约大于等于16位 */
#undef ulong
#define ulong unsigned long /* 约大于等于32位 */
#undef uptr
#define uptr Py_uintptr_t
typedef uchar block;
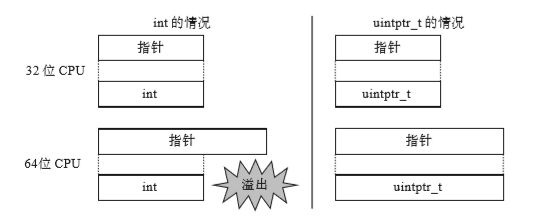
- 其中Py_uintptr_t是整数型的别名,用来存放指针的,根据编译环境的不同略有差异。定义如下
//Include/pyport.h
typedef uintptr_t Py_uintptr_t;
当cpu为32位时,指针几乎都是4字节,当64位时,指针则是8字节。我们在32位的机器上把指针转化为整数没问题(因为要把指针当整数存储),但是64位上时面对8字节的指针,4字节的int就会溢出。所以 出现了uintptr_t。它负责安全的根据环境变换成4字节或8字节,将指针安全的转化,避免发生溢出。
pool
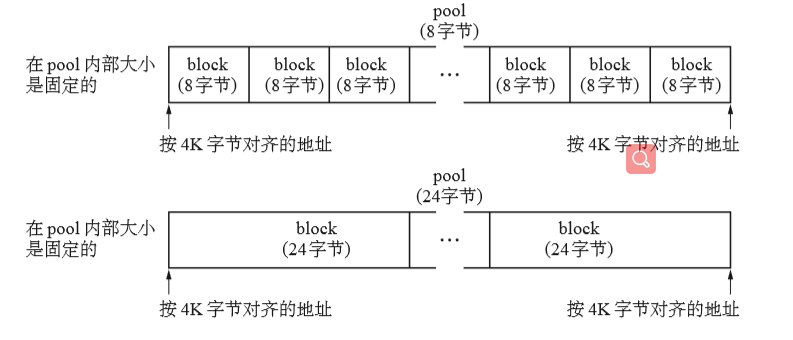
arena内部各个pool的大小固定为4k字节。(计算机内存中的页就是这么大,设置为4k字节)
大多数的OS都是以页为单位来管理内存的。把pool的大小和页设置为一样,就能让OS以pool为单位来管理内存。
arena内的pool内存被划分为4k字节的倍数进行对齐。也就是说,每个pool开头的地址为4k字节的倍数。在这里就发现了arena的地址和第一个pool的地址很有可能是不一样的。所以我们要把pool对齐在内存上。

我们来看看pool的头部存的信息。
struct pool_header {
/* 分配到pool里的block的数量 */
union { block *_padding;
uint count; } ref;
/* block的空闲链表的开头 */
block *freeblock;
/* 指向下一个pool的指针(双向链表) */
struct pool_header *nextpool;
/* 指向前一个pool的指针(双向链表) */
struct pool_header *prevpool;
/* 自己所属的arena的索引(对于arenas而言) */
uint arenaindex;
/* 分配的block的大小 */
uint szidx;
/* 到下一个block的偏移 */
uint nextoffset;
/* 到能分配下一个block之前的偏移 */
uint maxnextoffset;
};
结构体pool_header就跟它的名字一样,必须安排在各个pool开头。pool_header 在arena内将各个pool相连接,保持pool内的block的大小和个数。
new arena
生成arena的代码是用new_arena() 函数写的,所以我们先来粗略地看一下new_ arena() 函数的整体结构。
Objects/obmalloc.c:new_arena()
static struct arena_object*
new_arena(void) {
struct arena_object* arenaobj;
if (unused_arena_objects == NULL) {
/* 生成arena_object */
/* 把生成的arena_object 补充到arenas和unused_arena_objects里 */
}
/* 把arena分配给未使用的arena_object */
/* 把arena内部分割成pool */
return arenaobj; /* 返回新的arena_object */ }
具体怎么分配的,这里就不细说了。
usable_arenas和unused_arena_objects
管理arena的全局变量usable_arenas和unused_ared_arena_objects。我们来看看他俩的功能。
unused_arena_objects
将现在未被使用的arena_object连接到单向链表。
(可以说arena还未得到保留)
arena_object是从new_arena()内列表的开头取的。
此外,在 PyObject_Free()时arena为空的情况下,arena_object会被追加到这个列表的开头。
注意:只有当结构体arena_object的成员address为0时,才将其存入这个列表。
usable_arenas
这是持有arena的arena_object的双向链表,其中arena分配了可利用的pool。
这个pool正在等待被再次使用,或者还未被使用过。
这个链表按照block数量最多的arena的顺序排列。
(基于成员nfreepools升序排列)
这意味着下次分配会从使用得最多的arena开始取。
然后它也会给很多将几乎为空的arena返回系统的机会。
根据我的测试,这项改善能够在很大程度上释放arena。
在没有能用的arena时,我们使用unused_arena_objects。如果在分配时没有arena就从这个链表中取出一个arena_object,分配一个新的arena。
当没有能用的pool时,则使用usable_arenas。如果再分配时没有pool,就从这个链表中取出arena_object,从分配的arena中拿一个pool。
unused_arena_objects是单向链表,usable_arenas是双向链表。当我们采用unused_aren_objects时,只能使用结构体arena_object的成员nextarena;而当我们采用usable_arenas时,则可以使用成员nextarena和成员pervarena。其中成员nextarena和成员pervarena。在不同情况下用法是不同的。
第一层总结
第一层分配器的任务就是生成arena和pool,将其存入arenas里,或者连接到unused_arena_objects,用一句话来说就是管理arena。
第二层--对象分配器
第二层的分配器是负责管理pool内的block的。这一层将block的开头地址返回给申请者,并释放block等。
block
- pool被分割成一个个block,Python的对象最终都会是这个block(在不大于256字节的情况下)
- block划分的大小在pool初始化的时候就决定了,我们将每个block大小定位8的倍数,相应的地址也就是8的倍数了。
- 为什么要使用8个字节呢?我们之前说过兼容性的一个问题。block设置为8在64位和32位cpu中都是兼容的,当然有兴趣也可以设置为24。但是如果不这样做就有可能出现“非法对齐的情况”。
申请的大小和对应的block大小如下表示:
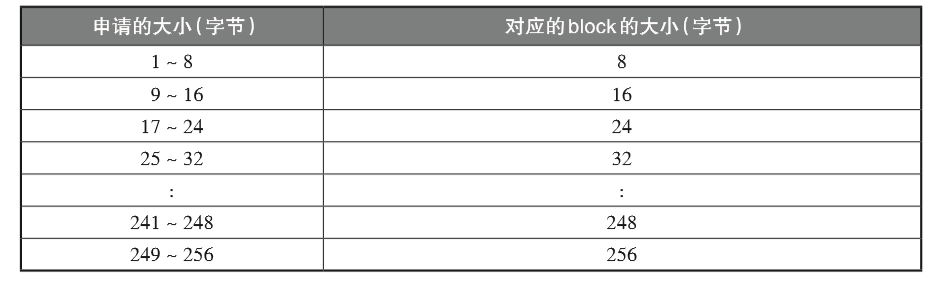
利用地址对齐的hack
假设结构体存入某个指针,如果malloc()返回的地址是按8字节对齐的,那么指针低三位肯定为0。于是我们想用它来做标志使用。当我们真的要访问这个指针时,就将低三位设为0,无视标识。
usedpools
Python的分配器采用Best-fit的策略,也就是说尽可能的分配大小接近的块。因此在一开始就要找到适合大小的block的pool。而且搜索这个pool必须是高速的,否则会影响程序的性能。
翻过来,当我们找到pool后,不管大小如何,只要在发现的pool内找到一个空的block就能轻松地划分block。那么怎么实现告诉搜索pool呢?这就是我们要介绍的usedpools。
usedpools是保持pool的数组,其结果如下图示:
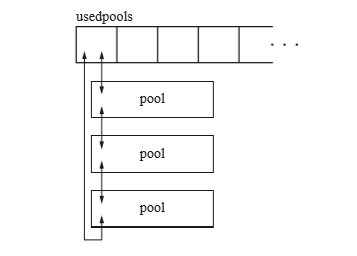
每个pool用双向链表相连,形成了一个双循环链表,usedpools里存储的是指向开头pool的指针。usedpools负责从众多pool里返回适和申请的pool。那么申请空间的大小和对应的pool对应关系如下图示:
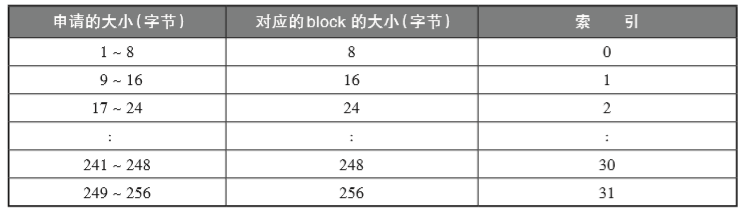
也就是说,如果申请大小为20字节,根据上表索引出2的元素中的pool。这样我们就能以O(1)的搜索时间申请符合大小的pool了。
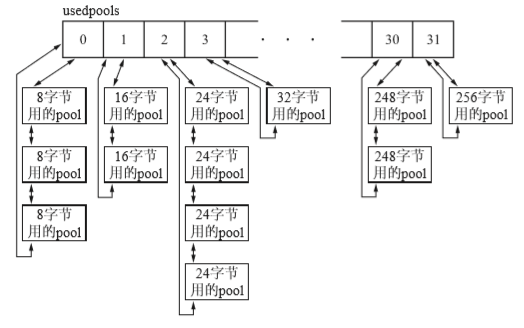
这个usedpools内的pool链表是双向链表连接的,事实上,一旦pool内部的所有block被释放,就会将这个空pool返回给arena。但是我们并不知道那个pool释放的block,因此这就增加了pool链表的中途释放block的可能性。
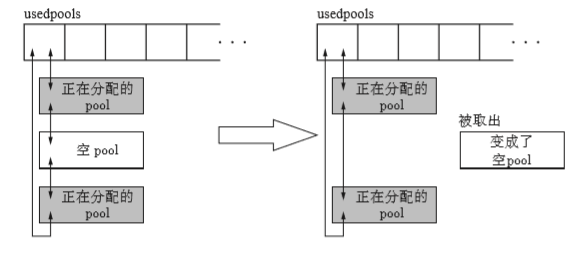
在这种情况下,我们就必须从链表中取出pool。
在实际情况中usedpools并不是我们上图所示,应该是如下图示才对:
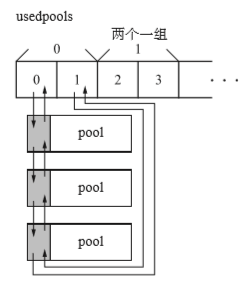
而且每一pool都有pool_header,保存它的相关信息。
struct pool_header {
union { block *_padding;
uint count; } ref;
block *freeblock;
struct pool_header *nextpool;
struct pool_header *prevpool;
uint arenaindex;
uint szidx;
uint nextoffset;
uint maxnextoffset;
};
这里有成员nextpool和prevpool。就是双向链表的下和上。

上面的过程有一点是想不通的,为什么不直接那usedpools来当结构体pool_header的数组?我们来想想为什么不让他存信息。加入说我们要缓存used_pools呢?那是不是usedpools就会变得很大,难以被缓存。所以我们觉得不给它里面放入信息,减轻缓存的压力,这种思路在以后也是用得到的。
block状态管理
pool内被block完全填满了,那么pool是怎么进行状态管理的呢?block状态分为以下三种。
- 已经分配
- 使用完毕 使用过一次,已经被释放的block。
- 未使用 一次都没有使用过的block。
当mutator申请分配block时,pool必须迅速的把使用完毕或者未使用的block传过去。pool中分别使用不同方法来管理使用完毕的pool和未使用的pool。
使用完毕的pool:会被连接到一个叫做freeblock的空闲链表进行管理。block是在释放的时候会被连接到空闲链表的。因为使用完毕的block肯定会经过了使用-》释放的流程,所以释放时空闲链表开头的地址就会被直接写入作为释放对象的block内。之后我们将释放完毕的block的地址存入freeblock中,这个freeblock是由pool_header定义的。我们将freeblock放在开头,形成block的空闲链表。
未使用的block:因为他没有使用过,因此我们使用从pool开头的偏移量来进行管理。pool_header的成员nextoffset中保留着偏移量。
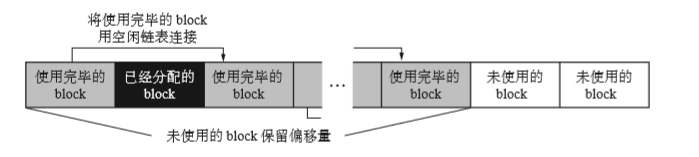
此我们分配的未使用的block是连续的block。因为分配时是从pool的开头开始分配 block 的,所以其中不会出现使用完毕的 block 和已经分配的 block。因此我们只要将偏移量 偏移到下一个 block,就知道它确实是未使用的 block 了。
PyObject_Malloc()
PyObject_Malloc()函数有三个作用,分配block,分配pool,分配arena。
函数功能如下Objects/obmalloc.c:PyObject_Malloc()
void* PyObject_Malloc(size_t nbytes) {
/* 是否小于等于256字节? */
if ((nbytes - 1) < SMALL_REQUEST_THRESHOLD) {
/* 将申请的字节数,通过公式转化成usedpools的索引。
拿到索引后判断pool是否已经连接到了索引指定的usedpools的
如果已经连接到了,pool和pool->nextpool的地址就会不同。
*/
if (pool != pool->nextpool) {
/* 如果已经连接到了(pool已经被分配) */
/* 从空闲链表上取出block,当block内的链表下一个空block地址为NULL时,通过偏移量取出block*/
/*拿到block后 return*/
}
/* 是否存在可以使用的arena?pool未被分配 */
if (usable_arenas == NULL) {
/* 使用new_arena()方法产生新的arena
/* 将新的arena_object设置到usable_arenas中。 */
}
/* 从arena取出使用完毕的pool */
pool = usable_arenas->freepools;
/* 是否存在使用完毕的pool? */
if (pool != NULL) {
/* 从arnea中取出使用完毕的pool */
/* 对arena中可用的pool数进行减一*/
/*判断arena中还有没有可用的pool,如果没有我们将下一个arena_object设置到usable_arenas里。因为我们设置的新arena是在链表的开头,所以他没有prevarena,所以要设置为NULL.
/* 将pool连接到usedpools开头 */
/* 比较申请的大小和pool中固定的block大小*/
/*如果是旧的pool,就有合适的大小,取出对应的block并返回。*/
/*否则,就要初始化block*/
/*返回合适的block地址*/
}
/* 初始化空pool */
/* 将pool连接到usedpools开头 */
/* 比较申请的大小和pool中固定的block大小*/
/*如果是旧的pool,就有合适的大小,取出对应的block并返回。*/
/*否则,就要初始化block*/
/*返回合适的block地址*/
}
redirect:
/* 当大于等于256字节时,按一般情况调用malloc */
return (void *)malloc(nbytes); }
PyObject_Free()
该函数有三个作用,释放block,释放pool,释放arena
函数功能如下Objects/obmalloc.c:PyObject_Free()
void PyObject_Free(void *p) {
pool = POOL_ADDR(p);
if (Py_ADDRESS_IN_RANGE(p, pool)) {
LOCK();
/* 把作为释放对象的block连接到freeblock开头 */
/* 这个pool中最后free的block是否为NULL? */
if (lastfree) {
/* pool中有已经分配的block */
if (--pool->ref.count != 0) {
/* 不执行任何操作 */
UNLOCK();
return;
}
/* 当pool中所有的block为空时候将pool返回给arena,连接到freepools。 */
/* 当arena内所有pool为空时 */
if (nf == ao->ntotalpools) {
/* 这时候就要释放arena,从used_arenas取出对象arena_object,将其连接到unused_arena_objects */
/*之后释放arena,在释放后,为了识别arena没由被分配,将其arena_object的成员address设为0*/
return;
}
/* arena还剩一个空pool */
if (nf == 1) {
/* 将arena_object连接到useable_arenas的开头 */
return;
}
/* 针对usable_arenas,将空pool少的arenas排在前面。 */
return;
}
/* 当lastfree为NULL时,也就是说,将要执行释放block操作的时候。*/
/* 在usedpools的开头插入pool */
return;
}
/* 释放其他空间 */
free(p);
}
arena和pool的释放策略
在PyObject_Free() 函数中我们用到了几个小技巧,其中的一个就是“优先使用被利用最多的内存空间”。 在插入 pool 的过程中,当从 usedpools取出的pool通过释放 block 的操作返回 usedpools 时,这个 pool 已经被插入了usedpools的元素内的开头。
这样的操作,可以使一些不经常使用的内存空间变为空,将其回收。同时也提高了内存的利用率。
从block搜索pool的技巧
我们来看看一个宏定义。
#define POOL_ADDR(P) (P & 0xfffff000)
之前我们说过,pool地址是按4k对齐的,也就是说只要从pool内部某处block地址开始用0xffff000标记,肯定能取到pool的开头。
计算和顺序查找嘛。(一般来说采用计算会比较快一点)
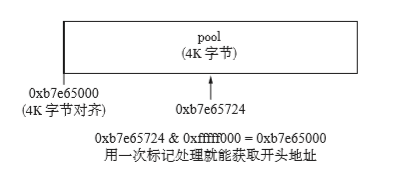
一般认为从地址去找所属的 pool 是一项非常花时间的处理。比较笨的办法就是取出一个 pool,检查其范围内是否有对象的地址,如果没有就再取出下一个pool……但是这样一来, 每次 pool 增加时计算量也会相应地增加。
第三层--对象特有的分配器
对象有列表和元组等类型。在生成他们的时候要使用个自特有的分配器。下面以字典为例。
Objects/dictobject.c
#ifndef PyDict_MAXFREELIST
#define PyDict_MAXFREELIST 80
#endif
static PyDictObject *free_list[PyDict_MAXFREELIST];
static int numfree = 0;
这里将空闲链表定义为有80个元素的数组,使用完毕的链表对象会被初始化并存入空闲链表中。
负责释放字典对象的函数如下示:
Objects/dictobject.c
static void
dict_dealloc(register PyDictObject *mp)
{ /* 省略部分:释放字典对象内的元素 */
/* 检查空闲链表是否为空 */ /* 检查释放对象是否为字典型 */ if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type)
free_list[numfree++] = mp;
else
Py_TYPE(mp)->tp_free((PyObject *)mp);
}
如果释放字典对象时空闲链表有空间,那么就将使用完毕的字典对象存入空链表。另一方面如果使用完毕的字典对象吧用于空闲链表的数组填满了,就认为没有必要再去保留这个对象了,直接进行释放操作。
分配字典对象 Objects/dictobject.c
PyObject *
PyDict_New(void)
{
register PyDictObject *mp;
/* 检查空闲链表内是否有对象 */
if (numfree) {
mp = free_list[--numfree];
_Py_NewReference((PyObject *)mp);
} else {
/* 如果没有对象就新分配对象 */
mp = PyObject_GC_New(PyDictObject, &PyDict_Type);
if (mp == NULL)
return NULL;
}
return (PyObject *)mp;
}
如果空闲链表有对象,函数就返回它。如果空闲链表里没有对象,那就分配对象。用到这个空闲链表的分配器就是第一次的“对象特有的分配器”。
这个对象特有的分配器还实现了列表,元组等。这些类型都会频繁的生产和销毁对象。因此我们都采用这种方法通过使用链表就能重复利用一定个数的对象。
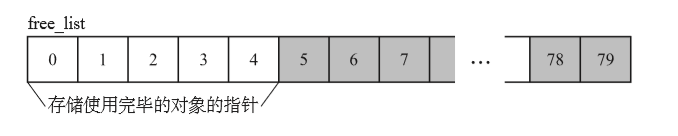
这个空闲链表和栈一样采用FILO(First In Last Out)。
分配器总结
Python再生产字典对象时,分配器的交互如下图示:

Python内存分配器(如何产生一个对象的过程)的更多相关文章
- 【python测试开发栈】—python内存管理机制(二)—垃圾回收
在上一篇文章中(python 内存管理机制-引用计数)中,我们介绍了python内存管理机制中的引用计数,python正是通过它来有效的管理内存.今天来介绍python的垃圾回收,其主要策略是引用计数 ...
- python内存管理(通俗易懂,详细可靠)
python内存管理 python3.6.9 内存管理的官方文档 https://docs.python.org/zh-cn/3.6/c-api/memory.html 一.变量存哪了? x = 10 ...
- 转发:[Python]内存管理
本文为转发,原地址为:http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html 本文主要为了解释清楚python的内存管理 ...
- 使用gc、objgraph干掉python内存泄露与循环引用!
Python使用引用计数和垃圾回收来做内存管理,前面也写过一遍文章<Python内存优化>,介绍了在python中,如何profile内存使用情况,并做出相应的优化.本文介绍两个更致命的问 ...
- [转] 使用gc && objgraph 优化python内存
转自https://www.cnblogs.com/xybaby/p/7491656.html 使用gc.objgraph干掉python内存泄露与循环引用! 目录 一分钟版本 python内存管 ...
- Python内存管理机制及优化简析(转载)
from:http://kkpattern.github.io/2015/06/20/python-memory-optimization-zh.html 准备工作 为了方便解释Python的内存管理 ...
- 从零开始写STL-内存部分-内存分配器allocator
从零开始写STL-内存部分-内存分配器allocator 内存分配器是什么? 一般而言,c++的内存分配和释放是这样操作的 >>class Foo{ //...}; >>Foo ...
- 记一次调试python内存泄露的问题
转载:http://www.jianshu.com/p/2d06a1a01cc3 这两天由于公司需要, 自己编写了一个用于接收dicom文件(医学图像文件)的server. 经过各种coding-de ...
- Python深入之python内存管理机制(重点)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:醍醐三叶 关于python的存储问题, (1)由于python中 ...
随机推荐
- [转]Adobe CC 2018 下载链接 Creative Cloud 2018 - Creative Cloud 2018 – Adobe CC 2018 Download Links
Creative Cloud 2018 – Adobe CC 2018 Download Links – ALL Languages Adobe CC 2018Direct Downloads Win ...
- 对比学习用 Keras 搭建 CNN RNN 等常用神经网络
Keras 是一个兼容 Theano 和 Tensorflow 的神经网络高级包, 用他来组件一个神经网络更加快速, 几条语句就搞定了. 而且广泛的兼容性能使 Keras 在 Windows 和 Ma ...
- Caffe Loss分析
Caffe_Loss 损失函数为深度学习中重要的一个组成部分,各种优化算法均是基于Loss来的,损失函数的设计好坏很大程度下能够影响最终网络学习的好坏.派生于 \(LossLayer\),根据不同的L ...
- HDU 1754 I Hate It【线段树 单点更新】
题意:给出n个数,每次操作修改它的第s个数,询问给定区间的数的最大值 把前面两道题结合起来就可以了 自己还是敲不出来------------- #include<iostream> #in ...
- tp框架--------where("1")
今天看代码的时候看到一个令我难以理解的sql查询语句,这是tp框架里的 return $this->where("1")->order('ar_id desc')-&g ...
- eclipse界面更改为黑色
效果如下: 更改很简单,该两个配置就行了,如下图: 1.在window中打开Preferences,然后跟下图一样配置就行了.
- Hdu 2586 树链剖分求LCA
Code: #include<cstdio> #include<cstring> #include<vector> #include<algorithm> ...
- [备忘]js-xlsx 操作 Excel 插件
github地址:https://github.com/SheetJS/js-xlsx oss地址:http://oss.sheetjs.com/js-xlsx/xlsx.full.min.js
- Ajax通过script src特性加载跨域文件 jsonp
<!DOCTYPE html><html><head> <meta charset="UTF-8"> <title>Do ...
- thttpd 在S3C6410的移植-web服务程序的应用
1. 在VMWare 虚拟机上将arm-linux-gcc 4.3.1配置好:2. 下载thttpd软件包并解压:3. 在thttpd根目录下运行: ./configure:4. ...