SparkStreaming整合flume
SparkStreaming整合flume
在实际开发中push会丢数据,因为push是由flume将数据发给程序,程序出错,丢失数据。所以不会使用不做讲解,这里讲解poll,拉去flume的数据,保证数据不丢失。
1.首先你得有flume
比如你有:【如果没有请走这篇:搭建flume集群(待定)】
这里使用的flume的版本是 apache1.6 cdh公司集成
apache1.6 cdh公司集成
这里需要下载
(1).我这里是将spark-streaming-flume-sink_2.11-2.0.2.jar放入到flume的lib目录下
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib
(ps:我的flume安装目录,使用ftp工具上传上去,我使用的是finalShell支持ssh也支持ftp(需要的小伙伴,点我下载))
(2)修改flume/lib下的scala依赖包(保证版本一致)
我这里是将spark中jar安装路径的scala-library-2.11.8.jar替换掉flume下的scala-library-2.10.5.jar
删除scala-library-2.10.5.jar
rm -rf /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib/scala-library-2.10.5.jar
cp /export/servers/spark-2.0.2/jars/scala-library-2.11.8.jar /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib/
(3)编写flume-poll.conf文件
创建目录
mkdir /export/data/flume
创建配置文件
vim /export/logs/flume-poll.conf
编写配置,标注发绿光的地方需要注意更改为自己本机的(flume是基于配置执行任务)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true
#channel
a1.channels.c1.type =memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity=5000
#sinks
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname=192.168.52.110
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize= 2000
底行模式wq保存退出
执行flume
flume-ng agent -n a1 -c /opt/bigdata/flume/conf -f /export/logs/flume-poll.conf -Dflume.root.logger=INFO,console
在监视的/export/data/flume下放入文件 (黄色对应的是之前创建的配置文件)
执行成功
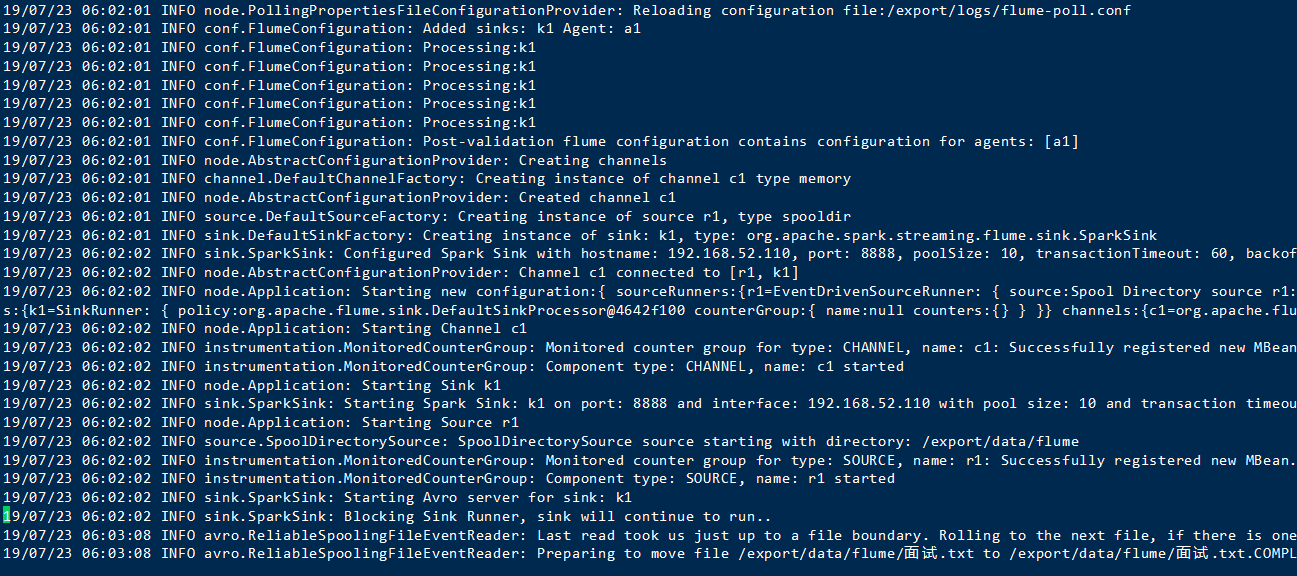
代表你flume配置没有问题,接下来开始编写代码
1.导入相关依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.0.2</version>
</dependency>
2.编码
package SparkStreaming import SparkStreaming.DefinedFunctionAdds.updateFunc
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} object SparkStreamingFlume {
def main(args: Array[String]): Unit = {
//创建sparkContext
val conf: SparkConf = new SparkConf().setAppName("DefinedFunctionAdds").setMaster("local[2]")
val sc = new SparkContext(conf) //去除多余的log,提高可视率
sc.setLogLevel("WARN") //创建streamingContext
val scc = new StreamingContext(sc,Seconds(5)) //设置备份
scc.checkpoint("./flume") //receive(task)拉取数据
val num1: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(scc,"192.168.52.110",8888)
//获取flume中的body
val value: DStream[String] = num1.map(x=>new String(x.event.getBody.array()))
//切分处理,并附上数值1
val result: DStream[(String, Int)] = value.flatMap(_.split(" ")).map((_,1)) //结果累加
val result1: DStream[(String, Int)] = result.updateStateByKey(updateFunc) result1.print()
//启动并阻塞
scc.start()
scc.awaitTermination()
} def updateFunc(currentValues:Seq[Int], historyValues:Option[Int]):Option[Int] = {
val newValue: Int = currentValues.sum+historyValues.getOrElse(0)
Some(newValue)
} }
运行

加入新的文档到监控目录 结果

成功结束!
SparkStreaming整合flume的更多相关文章
- SparkStreaming整合Flume的pull报错解决方案
先说下版本情况: Spark 2.4.3 Scala 2.11.12 Flume-1.6.0 Flume配置文件: simple-agent.sources = netcat-source simpl ...
- SparkStreaming整合Flume的pull方式之启动报错解决方案
Flume配置文件: simple-agent.sources = netcat-source simple-agent.sinks = spark-sink simple-agent.channel ...
- 【Spark】SparkStreaming与flume进行整合
文章目录 注意事项 SparkStreaming从flume中poll数据 步骤 一.开发flume配置文件 二.启动flume 三.开发sparkStreaming代码 1.创建maven工程,导入 ...
- Spark学习之路(十五)—— Spark Streaming 整合 Flume
一.简介 Apache Flume是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming提供了以下两种方式用于Flu ...
- Spark 系列(十五)—— Spark Streaming 整合 Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- Spark Streaming 整合 Flume
Spark Streaming 整合 Flume 一.简介二.推送式方法 2.1 配置日志收集Flume 2.2 项目依赖 2.3 Spark Strea ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- 基于Java+SparkStreaming整合kafka编程
一.下载依赖jar包 具体可以参考:SparkStreaming整合kafka编程 二.创建Java工程 太简单,略. 三.实际例子 spark的安装包里面有好多例子,具体路径:spark-2.1.1 ...
随机推荐
- C#中增量类功能的方式之 继承与扩展
之前一次公司培训的时候,将它记录下来,https://www.cnblogs.com/AlvinLee/p/10180536.html这个博客上面比较全面. 1.扩展方法 扩展方法是一种特殊的静态方法 ...
- 松软科技带你学开发:SQL--FIRST() 函数
FIRST() 函数(原文链接 松软科技:www.sysoft.net.cn/Article.aspx?ID=3731) FIRST() 函数返回指定的字段中第一个记录的值. 提示:可使用 ORDER ...
- 关于vue-detools chorme创建安装完成,但是控制台不显示问题
搜了一下发现挺多人遇到这个问题的,绝大多数的回答都是在main.js中添加下面代码 Vue.config.devtools = true; 但是发现并不行. 后来看到有人说刷新然后在按F12就好了,居 ...
- Python 函數 Function
函數最初被設計出來,是用來減輕重複 coding 一段相同的代碼,這之間只有代碼 (方法,Method) 的重用,但還沒有物件導向OO整個Object 的屬性與方法被封裝重用的概念. 函數的定義很簡單 ...
- 【转载】Android 中 View 绘制流程分析
创建Window 在Activity的attach方法中通过调用PolicyManager.makeNewWindo创建Window,将一个View add到WindowManager时,Window ...
- 框架用多了真的会死人的,spring-cloud全家桶与mybitais 集成完整示例(附下载)
题外话: 看到这一长串包含各种技术名词的标题,一路走来感觉研发深深的被各种框架给绑架了,从我们刚出生最简单的jsp,servlet打天下,到spring mvc的盛行,再到现在spring-boo ...
- .Net Core 3.0开源可视化设计CMS内容管理系统建站系统
简介 ZKEACMS,又名纸壳CMS,是可视化编辑设计的内容管理系统.基于.Net Core开发可跨平台运行,并拥有卓越的性能. 纸壳CMS基于插件式设计,功能丰富,易于扩展,可快速创建网站. 布局设 ...
- java8-04-初识函数式接口
为什么用函数式接口 在函数式编程思想下,允许函数本身作为参数传入另一个函数.使用函数式接口实现"传递行为"的思想 ...
- 【使用篇二】SpringBoot使用JdbcTemplate操作数据库(12)
Spring对数据库的操作在jdbc上面做了深层次的封装,提供了JdbcTemplate模板. 在SpringBoot使用JdbcTemplate很简单: 引入数据库驱动包(mysql或oracle) ...
- echars line 底部图例强制不换行(滚动),修改图例样式
{ grid: { left: '5px', right: '10px', top: '10px', bottom: '40px', containLabel: true }, tooltip: { ...