Hadoop记录-MRv2(Yarn)运行机制
1.MRv2结构—Yarn模式运行机制
Client---客户端提交任务
ResourceManager---资源管理
---Scheduler调度器-资源分配Containers
----在Yarn中有三种调度器可以选择:FIFO Scheduler先进先出调度器 ,Capacity Scheduler容量调度器,FairS cheduler公平调度器。
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
---ApplicationManager-接收Job提交请求,分配第一个Container来运行ApplicationMaster并监控ApplicationMaster状态
NodeManager---节点代理、与ResourceManager交互分配具体的Container,监控Container使用情况并报告给ResourceManager做好记录,以便于其他Job申请Container使用。
ApplicationMaster---向RM申请Container,NM分配具体的Container给AM,AM监控Job的整个过程(运行状态、运行进度等)
Container---一组CPU和内存资源
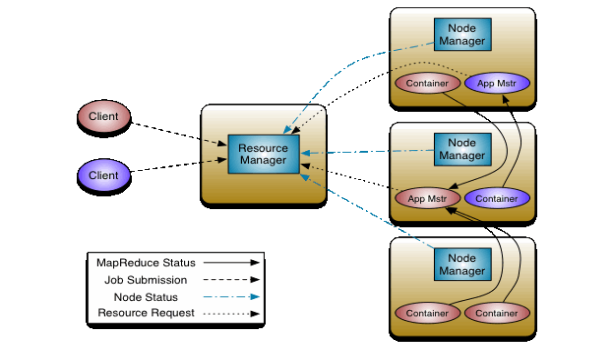
Yarn运行机制描述如下:
1.Client提交任务给ResourceManager,ResoureManager下的ApplicationManager接收请求,分配第一个Container来运行ApplicationMaster,ApplicationManager监控ApplicationMaster状态;
2.ApplicationMaster向ResourceManager申请Container,ResouceManager下的Scheduler告知有哪些Container可用,并告知slaves下的NodeManager分配具体的Container给ApplicationMaster;
3.ApplicationMaster请求slaves下的NodeManager分配具体的Container,ApplicationMaster获得具体的Container给任务,并跟踪监控该任务的全部过程(运行状态、运行进度等);
4.NodeManager监控Container(CPU、内存)的使用情况,并告知ResourceManager下的Scheduler做好记录,以方便其他任务申请资源。
----------------------------------------------------------------------------------------------------------------------------------------------------------
在MR1中,JobTracker即负责job的监控,又负责系统资源的分配。而在MR2中,资源的调度分配由ResourceManager专门进行管理,而每个job或应用的管理、监控交由相应的分布在集群中的ApplicationMaster,如果某个ApplicationMaster失败,ResourceManager还可以重启它,这大大提高了集群的拓展性。MR1中的TaskTracker负责监控任务状态和机器资源使用情况,并报告给JobTracker。
MRv1缺点:
1、JobTracker是Map-reduce的集中处理点,存在单点故障
2、JobTracker完成了太多的任务,造成了过多的资源消耗,当map-reduce job非常多的时候,会造成很大的内存开销,潜在来说,也增加了JobTracker fail的风险,这也是业界普遍总结出老hadoop 的Map-Reduce只能支持4000节点主机的上限。
3、在TaskTracker端,以map/reduce task的数目作为资源的表示过于简单,没有考虑到cpu/内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OOM
4、在TaskTracker端,把资源强制划分为map task slot和reduce task slot如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费,也就是前面提到过的集群资源利用的问题。
5、源代码非常难读,因为一个类做了太多的事情,而代码量过多,造成class的任务不清晰,增加bug的修复和版本维护的难读。
MRv2(Yarn)优点:
1、大大减小了JobTracker(也就是现在的ResourceManager)的资源消耗,并且让检测每一个Job子任务(tasks)状态的程序分布式化了。更安全、更优美
2、在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的ApplicationMaster,让更多类型的编程模型能够跑在Hadoop集群中。
3、对于资源的表示以内存为单位,比之前以剩余slot数目更合理
4、老的框架中,JobTracker一个很大的负担就是监控kob下的tasks的运行状况,现在,这个部分就扔给ApplicationMaster了,而ResourceManager中有一个模块叫做ApplicationsMaster,它是检测ApplicationMaster的运行状况,如果出问题,会将其在其他机器上重启
5、Container是Yarn为了将来做资源隔离而提出的一个框架,这一点应该借鉴了Mesos的工作,目前是一个框架,仅仅提供Java虚拟机内存的隔离,hadoop团队的设计思路应该后续能支持更多的资源调度和控制,既然资源表示成内存量,那就没有了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况。
1、大大减小了JobTracker(也就是现在的ResourceManager)的资源消耗,并且让检测每一个Job子任务(tasks)状态的程序分布式化了。更安全、更优美
2、在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的ApplicationMaster,让更多类型的编程模型能够跑在Hadoop集群中。
3、对于资源的表示以内存为单位,比之前以剩余slot数目更合理
4、老的框架中,JobTracker一个很大的负担就是监控kob下的tasks的运行状况,现在,这个部分就扔给ApplicationMaster了,而ResourceManager中有一个模块叫做ApplicationsMaster,它是检测ApplicationMaster的运行状况,如果出问题,会将其在其他机器上重启
5、Container是Yarn为了将来做资源隔离而提出的一个框架,这一点应该借鉴了Mesos的工作,目前是一个框架,仅仅提供Java虚拟机内存的隔离,hadoop团队的设计思路应该后续能支持更多的资源调度和控制,既然资源表示成内存量,那就没有了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况。
Hadoop记录-MRv2(Yarn)运行机制的更多相关文章
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Hadoop_19_MapReduce&&Yarn运行机制
1.YARN的运行机制 1.1.概述: Yarn集群:负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager.NodeManager Yarn是一个资源调度(作业调度和集群资 ...
- hadoop Yarn运行机制
- Flink on Yarn运行机制
从图中可以看出,Yarn的客户端需要获取hadoop的配置信息,连接Yarn的ResourceManager.所以要有设置有 YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOO ...
- 一文了解 Hadoop 运行机制
大数据技术栈在当下已经是比较成熟的了,Hadoop 作为大数据存储的基石,其重要程度不言而喻,作为一个想从 java 后端转向大数据开发的程序员来说,打好 Hadoop 基础,就相当于夯实建造房屋的地 ...
- Spark记录-实例和运行在Yarn
#运行实例 #./bin/run-example SparkPi 10 #./bin/spark-shell --master local[2] #./bin/pyspark --master l ...
- day1--大数据概念,hadoop介绍,hdfs整体运行机制
1.什么是大数据 基本概念 在互联网技术发展到现今阶段,大量日常.工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用 ...
- 经典MapReduce作业和Yarn上MapReduce作业运行机制
一.经典MapReduce的作业运行机制 如下图是经典MapReduce作业的工作原理: 1.1 经典MapReduce作业的实体 经典MapReduce作业运行过程包含的实体: 客户端,提交MapR ...
- Hadoop记录-Yarn命令
概述 YARN命令是调用bin/yarn脚本文件,如果运行yarn脚本没有带任何参数,则会打印yarn所有命令的描述. 使用: yarn [--config confdir] COMMAND [--l ...
随机推荐
- C# 中颜色和名称样式对照表
WPF中的画刷也一样适用 System.Windows.Media.Brushes.名称 (如:System.Windows.Media.Brushes.AliceBlue) :first-child ...
- Maven修改默认JDK
Maven修改默认JDK 问题: 1.创建maven项目的时候,jdk版本是1.5版本,而自己安装的是1.7或者1.8版本. 2.每次右键项目名-maven->update project 时候 ...
- 牛客OI周赛7-提高组
https://ac.nowcoder.com/acm/contest/371#question A.小睿睿的等式 #include <bits/stdc++.h> using names ...
- [转帖]Linux内核为大规模支持100Gb/s网卡准备好了吗?并没有
Linux内核为大规模支持100Gb/s网卡准备好了吗?并没有 之前用 千兆的机器 下载速度 一般只能到 50MB 左右 没法更高 万兆的话 可能也就是 200MB左右的速度 很难更高 不知道后续的服 ...
- 删除Mac上的mysql数据库
sudo rm /usr/local/mysqlsudo rm -rf /usr/local/mysql*sudo rm -rf /Library/StartupItems/MySQLCOMsudo ...
- [转]ubuntu中查找软件的安装位置
原博客地址:http://www.cnblogs.com/zhuyatao/p/4060559.html ubuntu中的软件可通过图形界面的软件中心安装,也可以通过命令行apt-get instal ...
- windows部分常用命令
dir 查看内容 md 新建目录 copy 复制 del 删文件 cls 清屏 tasklist 查看运行进程 taskkill /pid xxx 杀死进程xxx taskmgr 打开任务管理器 ms ...
- Tree 菜单 递归
转载:http://www.cnblogs.com/igoogleyou/archive/2012/12/17/treeview2.html 一,通过查询数据库的方法 ID 为主键,PID 表明数据之 ...
- 洛谷P2054 [AHOI2005]洗牌(扩展欧几里德)
洛谷题目传送门 来个正常的有证明的题解 我们不好来表示某时刻某一个位置是哪一张牌,但我们可以表示某时刻某一张牌在哪个位置. 设数列\(\{a_{i_j}\}\)表示\(i\)号牌经过\(j\)次洗牌后 ...
- 洛谷 P2420 让我们异或吧 解题报告
P2420 让我们异或吧 题目描述 异或是一种神奇的运算,大部分人把它总结成不进位加法. 在生活中-xor运算也很常见.比如,对于一个问题的回答,是为1,否为0.那么: (A是否是男生 )xor( B ...