kafka消息队列、环境搭建与使用(.net framework)
一:kafka介绍
kafka(官网地址:http://kafka.apache.org)是一种高吞吐量的分布式发布订阅的消息队列系统,具有高性能和高吞吐率。
1.1 术语介绍
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
主题:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
分区:Partition是物理上的概念,每个Topic包含一个或多个Partition.(一般为kafka节点数cpu的总核数)
Producer
生产者,负责发布消息到Kafka broker
Consumer
消费者:从Kafka broker读取消息的客户端。
Consumer Group
消费者组:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
1.2 基本特性
可扩展性
在不需要下线的情况下进行扩容
数据流分区(partition)存储在多个机器上
高性能
单个broker就能服务上千客户端
单个broker每秒种读/写可达每秒几百兆字节
多个brokers组成的集群将达到非常强的吞吐能力
性能稳定,无论数据多大
Kafka在底层摒弃了Java堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合Zero-Copy的特性极大地改善了IO性能。
1.3 消息格式
一个topic对应一种消息格式,因此消息用topic分类
一个topic代表的消息有1个或者多个patition(s)组成
一个partition应该存放在一到多个server上,如果只有一个server,就没有冗余备份,是单机而不是集群;如果有多个server,一个server为leader(领导者),其他servers为followers(跟随者),leader需要接受读写请求,followers仅作冗余备份,leader出现故障,会自动选举一个follower作为leader,保证服务不中断;每个server都可能扮演一些partitions的leader和其它partitions的follower角色,这样整个集群就会达到负载均衡的效果
消息按顺序存放;消息顺序不可变;只能追加消息,不能插入;每个消息都有一个offset,用作消息ID, 在一个partition中唯一;offset有consumer保存和管理,因此读取顺序实际上是完全有consumer决定的,不一定是线性的;消息有超时日期,过期则删除
1.4 原理解析
producer创建一个topic时,可以指定该topic为几个partition(默认是1,配置num.partitions),然后会把partition分配到每个broker上,分配的算法是:a个broker,第b个partition分配到b%a的broker上,可以指定有每个partition有几分副本Replication,副本的分配策略为:第c个副本存储在第(b+c)%a的broker上。一个partition在每个broker上是一个文件夹,文件夹中文件的命名方式为:topic名称+有序序号。每个partition中文件是一个个的segment,segment file由.index和.log文件组成。两个文件的命名规则是,上一个segmentfile的最后一个offset。这样,可以快速的删除old文件。
producer往kafka里push数据,会自动的push到所有的分区上,消息是否push成功有几种情况:1,接收到partition的ack就算成功,2全部副本都写成功才算成功;数据可以存储多久,默认是两天;producer的数据会先存到缓存中,等大小或时间达到阈值时,flush到磁盘,consumer只能读到磁盘中的数据。
consumer从kafka里poll数据,poll到一定配置大小的数据放到内存中处理。每个group里的consumer共同消费全部的消息,不同group里的数据不能消费同样的数据,即每个group消费一组数据。
consumer的数量和partition的数量相等时消费的效率最高。这样,kafka可以横向的扩充broker数量和partitions;数据顺序写入磁盘;producer和consumer异步
二:环境搭建(windows)
Win10下kafka简单安装及使用
新手教程,老鸟忽略
使用具体参见http://kafka.apache.org/quickstart#quickstart_multibroker文档使用说明,如有问题欢迎交流。
kafka依赖于zookeeper,官网下载的kafka内置了zookeeper依赖。
1.进入kafka官网下载页面http://kafka.apache.org/downloads进行下载,选择二进制文件,再选择任意一个镜像文件下载。

下载成功后解压到本地文件夹D:\Kafka下面

2.关键配置
只需关注bin目录和config目录
在kafka根目录下新建data和kafka-logs文件夹,后面要用到,作为kafka快照和日志的存储文件夹
进入到config目录,修改service.properties里面log.dirs路径未log.dirs=E:\\Kafka\\kafka_2.12-2.0.0\\kafka-logs(注意:文件夹分割符一定要是”\\”)
修改zookeeper.properties里面dataDir路径为dataDir=E:\\Kafka\\kafka_2.12-2.0.0\\data
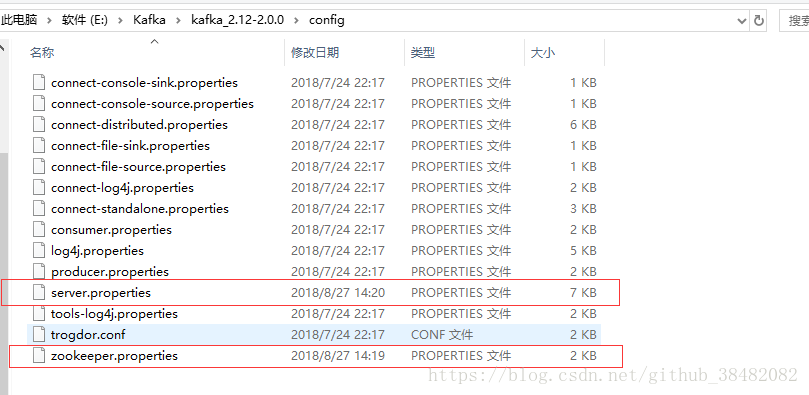

【service.properties】
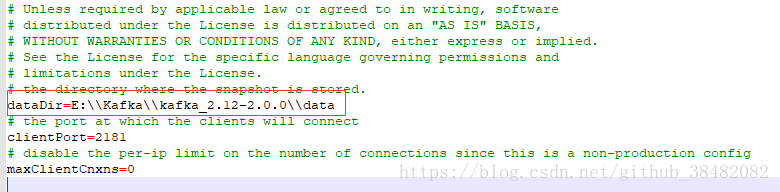
【zookeeper.properties】
3.进行单机实例测试简单使用
windows使用的是路径E:\Kafka\kafka_2.12-2.0.0\bin\windows下批处理命令,如有问题,参见
步骤:
1)启动kafka内置的zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties

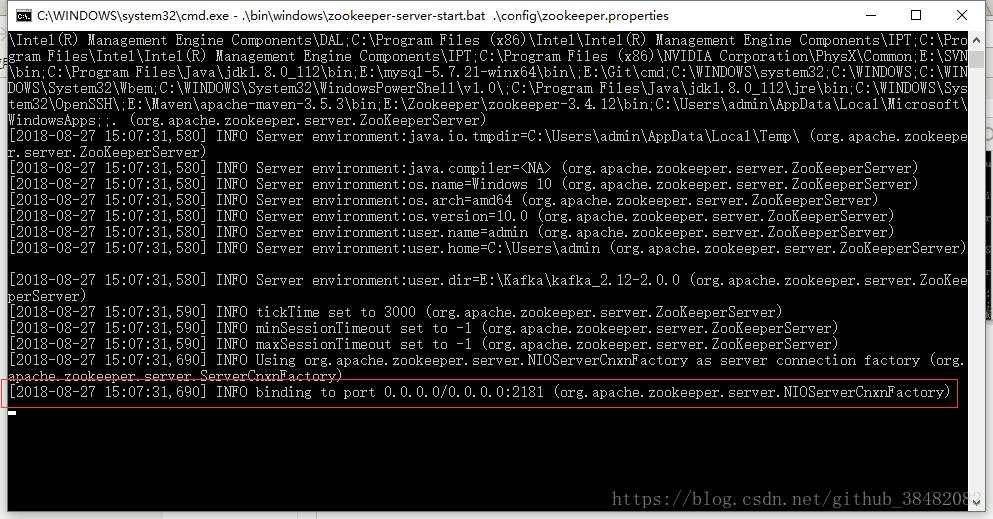
出现binding to port ...表示zookeeper启动成功,不关闭页面
2)kafka服务启动 ,成功不关闭页面
.\bin\windows\kafka-server-start.bat .\config\server.properties

3)创建topic测试主题kafka,成功不关闭页面
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

4)创建生产者产生消息,不关闭页面
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
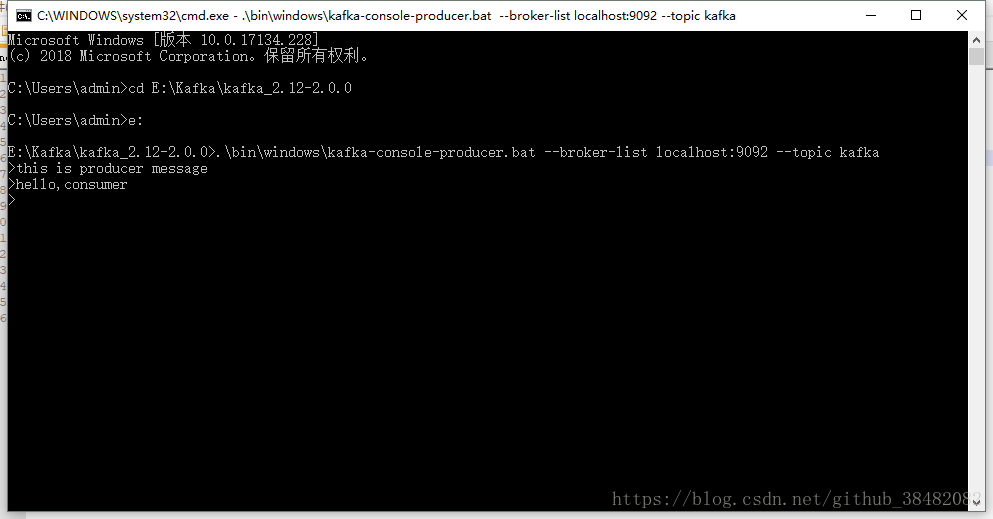
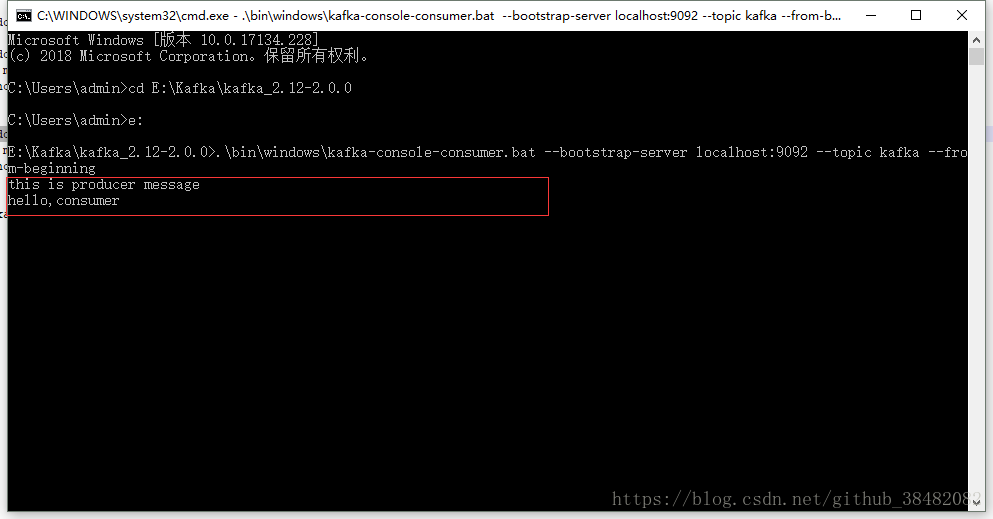
5)创建消费者接收消息,不关闭页面
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
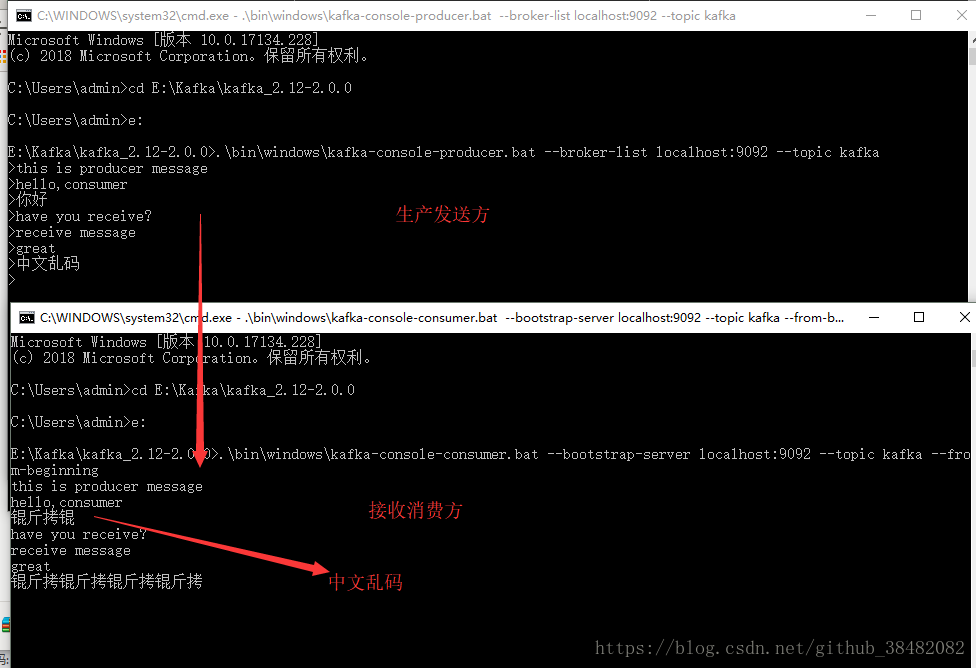
kafka消息队列、环境搭建与使用(.net framework)的更多相关文章
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- kafka 集群环境搭建 java
简单记录下kafka集群环境搭建过程, 用来做备忘录 安装 第一步: 点击官网下载地址 http://kafka.apache.org/downloads.html 下载最新安装包 第二步: 解压 t ...
- Canal Server发送binlog消息到Kafka消息队列中
Canal Server发送binlog消息到Kafka消息队列中 一.背景 二.需要修改的地方 1.canal.properties 配置文件修改 1.修改canal.serverMode的值 2. ...
- kafka消息队列的简单理解
kafka在大数据.分布式架构中都很流行.kafka可以进行流式计算,也可以做为日志系统,还可以用于消息队列. 本篇主要是消息队列相关的知识. 零.kafka作为消息队列的优点: 分布式的系统 高吞吐 ...
- Kafka单机Windows环境搭建
Kafka单机Windows环境搭建 1,安装jdk1.8:安装目录不能有中文空格: 2,下载zookeeper,https://mirrors.cnnic.cn/apache/zookeeper/z ...
- 初试kafka消息队列中间件二(采用java代码收发消息)
初试kafka消息队列中间件二(采用java代码收发消息) 上一篇 初试kafka消息队列中间件一 今天的案例主要是将采用命令行收发信息改成使用java代码实现,根据上一篇的接着写: 先启动Zooke ...
- 使用Cloudera Manager部署Kafka消息队列
使用Cloudera Manager部署Kafka消息队列 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载需要安装的Kafka版本 1>.查看Cloudera Dis ...
- Kafka:docker安装Kafka消息队列
安装之前先看下图 Kafka基础架构及术语 Kafka基本组成 Kafka cluster: Kafka消息队列(存储消息的队列组件) Zookeeper: 注册中心(kafka集群依赖zookee ...
- Kafka基础教程(四):.net core集成使用Kafka消息队列
.net core使用Kafka可以像上一篇介绍的封装那样使用(Kafka基础教程(三):C#使用Kafka消息队列),但是我还是觉得再做一层封装比较好,同时还能使用它做一个日志收集的功能. 因为代码 ...
随机推荐
- ps ww
[root@ma ~]# ps ww -p 1 PID TTY STAT TIME COMMAND 1 ? Ss 0:01 /sbin/init[root@ma ~]# ps -p 1 PID TTY ...
- 【Linux】服务器识别ntfs移动磁盘方法
Linux服务器无法识别ntfs磁盘 如果想识别的话,需要安装一个包ntfs-3g 安装好后,将移动磁盘插入到服务器的usb口中 新建一个目录,将磁盘挂载在新建的目录上 挂载命令如下: mount - ...
- File Inclusion - Pikachu
概述: 文件包含,是一个功能.在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件. 比如 在PHP中,提供了: include(),inclu ...
- 三种梯度下降算法的区别(BGD, SGD, MBGD)
前言 我们在训练网络的时候经常会设置 batch_size,这个 batch_size 究竟是做什么用的,一万张图的数据集,应该设置为多大呢,设置为 1.10.100 或者是 10000 究竟有什么区 ...
- Py变量,递归,作用域,匿名函数
局部变量与全局变量 全局变量:全局生效的变量,在顶头的,无缩进的定义的变量. 局部变量:函数内生效的变量,在函数内定义的变量. name='1fh' def changename(): name='s ...
- Matlab GUI学习总结
从简单的例子说起吧. 创建Matlab GUI界面通常有两种方式: 1,使用 .m 文件直接动态添加控件 2. 使用 GUIDE 快速的生成GUI界面显然第二种可视化编辑方法算更适合 ...
- Docker数据目录迁移解决方案
场景 在docker的使用中随着下载镜像越来越多,构建镜像.运行容器越来越多, 数据目录必然会逐渐增大:当所有docker镜像.容器对磁盘的使用达到上限时,就需要对数据目录进行迁移. 如何避免: 1. ...
- 从输入URL到页面展示,这中间都发生了什么?
前言 在浏览器里,从用户输入URL到页面展示,这中间都发生了什么?这是一道非常经典的面试题.这里边涉及很多知识点,比如:网络协议.页面渲染.操作系统等.所以这是很好很全面的考察一个前端的知识.下面我将 ...
- Python学习【第2篇】:基本数据类型
基本数据类型 字符串 ---------n1 = "xiaoxing" n2 = "admin" n3 = "123" n4 = & ...
- 【题解】 CF767E Change-free
洛谷链接 这个题翻译忘了输入,我看的英语原文...... 首先,这是一道贪心题 我的大致方法:pair+堆优 题目分析: 从第一天开始,到最后一天,每天可以选择找钱或者不找钱. 如果不找钱,则零钱数m ...