solr全文检索学习
序言:
前面我们说了全局检索Lucene,但是我们发现Lucene在使用上还是有些不方便的,例如想要看索引的内容时,就必须自己调api去查,再例如一些添加文档,需要写的代码还是比较多的
另外我们之前说过Lucene只是一个全文检索的工具包,并不算一个完整的搜索引擎。很多功能还是需要我们自己去完善,去实现的。
solr 和 ElasticSearch 是基于Lucene开发的功能比较完备的全文检索引擎。
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr实际上是一个Web应用,需要servlet容器,可以用Tomcat或者Jetty,新版本Solr默认是用Jetty的,如果要改Tomcat,则要自己做配置。
Solr提供了一些http接口,通过POST请求进行文档的操作,GET请求进行文档的查询。
要想是用solr,我们就需要先下载 https://lucene.apache.org/solr/
相关文档:https://lucene.apache.org/solr/guide/8_7/getting-started.html
solr目录说明:
下载后解压目录如下



整合Tomcat的你们自己百度,我直接用内置的Jetty
solr服务启动:
启动solr时,不要直接双击startup.cmd,不然窗口一闪而过,最后还是没有启动项目

在命令行里面执行,启动后不要关闭命令行,因为默认是后台进程,关闭命令行后服务器也会关闭
启动:solr start [-p 端口 -s home目录地址]
关闭:直接关闭命令行,或者,solr stop -all 关闭全部,或者,solr stop -p 8983 只关闭8983端口的服务器
重启:solr restart -p 端口
帮助:solr --help ,或者,solr start -help
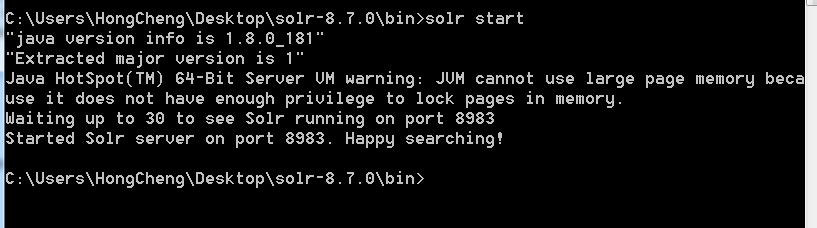
启动完后直接浏览器访问 http://localhost:8983/
一般来说solr的管理后台界面是不需要认证的,但是我们不可能让所有人都可以访问,所以我们需要修改认证
Jetty服务器启动认证:
首先在解压包的 /server/etc 目录中随便建个properties文件,文件名随意,填入用户密码角色
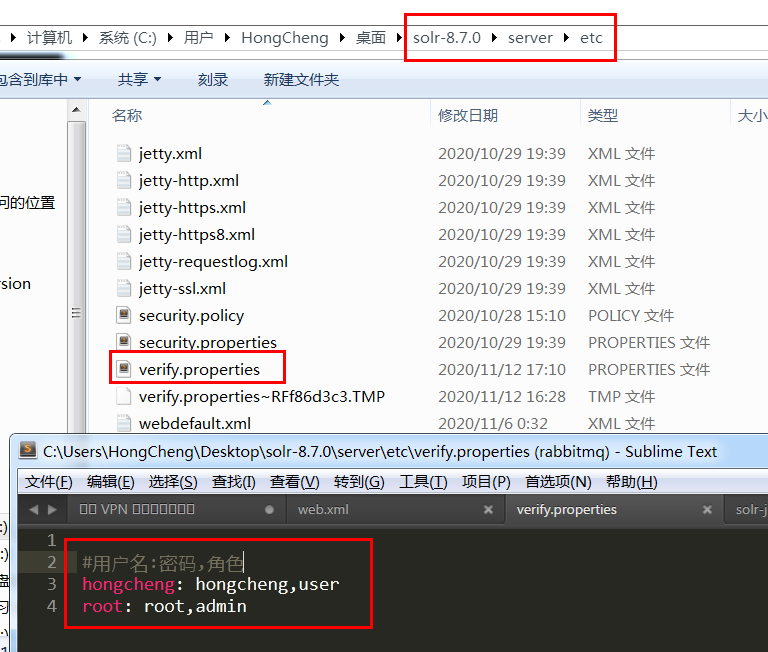
然后在 /server/contexts 目录中的 solr-jetty-context.xml 复制那段代码,文件名要和刚刚你建的文件名一致
<Get name="securityHandler">
<Set name="loginService">
<New class="org.eclipse.jetty.security.HashLoginService">
<Set name="name">verify—name</Set>
<Set name="config">
<SystemProperty name="jetty.home" default="." />/etc/verify.properties
</Set>
</New>
</Set>
</Get>
接着去 \server\solr-webapp\webapp\WEB-INF 目录中的 web.xml文件中注释掉选中的代码
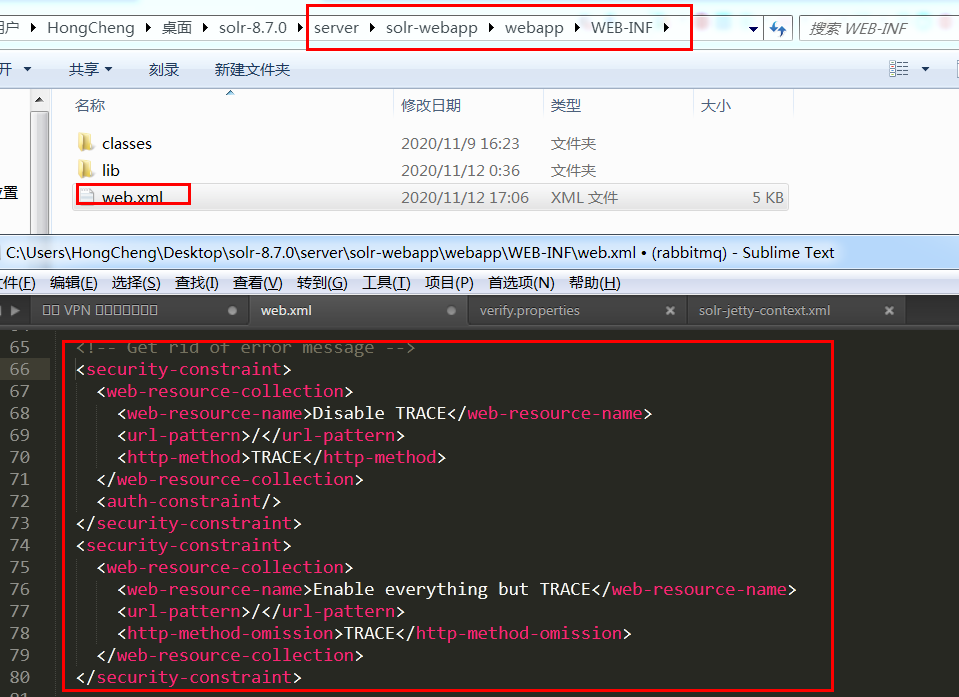
紧接着加上一段代码,指定资源认证
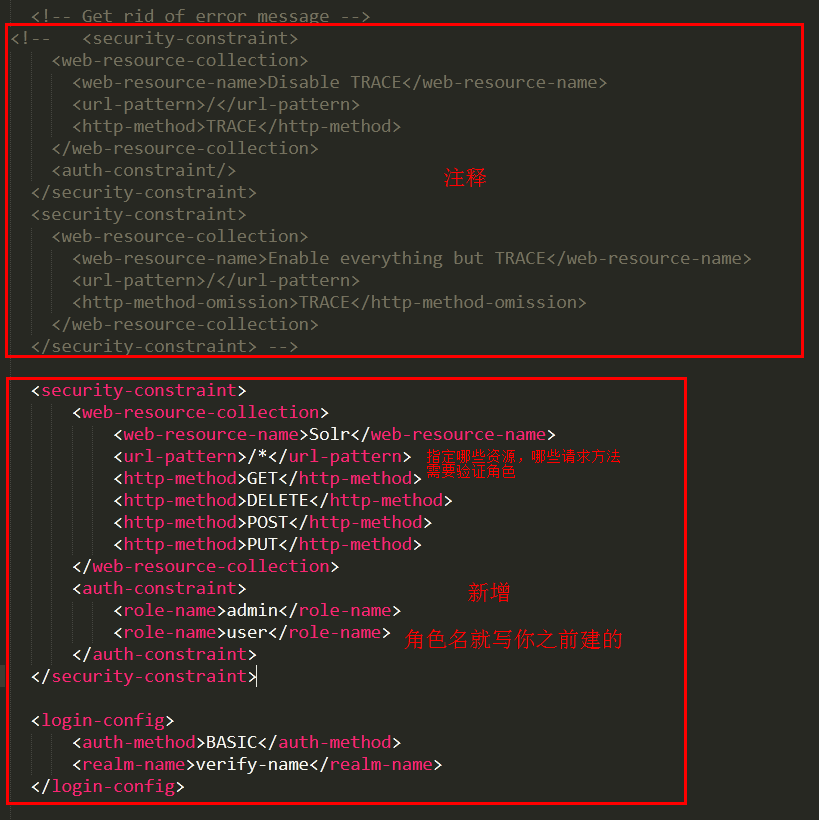
<security-constraint>
<web-resource-collection>
<web-resource-name>Solr</web-resource-name>
<url-pattern>/*</url-pattern>
<http-method>GET</http-method>
<http-method>DELETE</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
<role-name>user</role-name>
</auth-constraint>
</security-constraint> <login-config>
<auth-method>BASIC</auth-method>
<realm-name>verify-name</realm-name>
</login-config>
效果:

相关参考博客:
https://blog.csdn.net/u011561335/article/details/90695860
https://www.cnblogs.com/w1995w/p/10566218.html
整合Tomcat时开启认证:
https://www.cnblogs.com/anny0404/p/5570666.html
solr的管理界面功能:
Dashboard:
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息
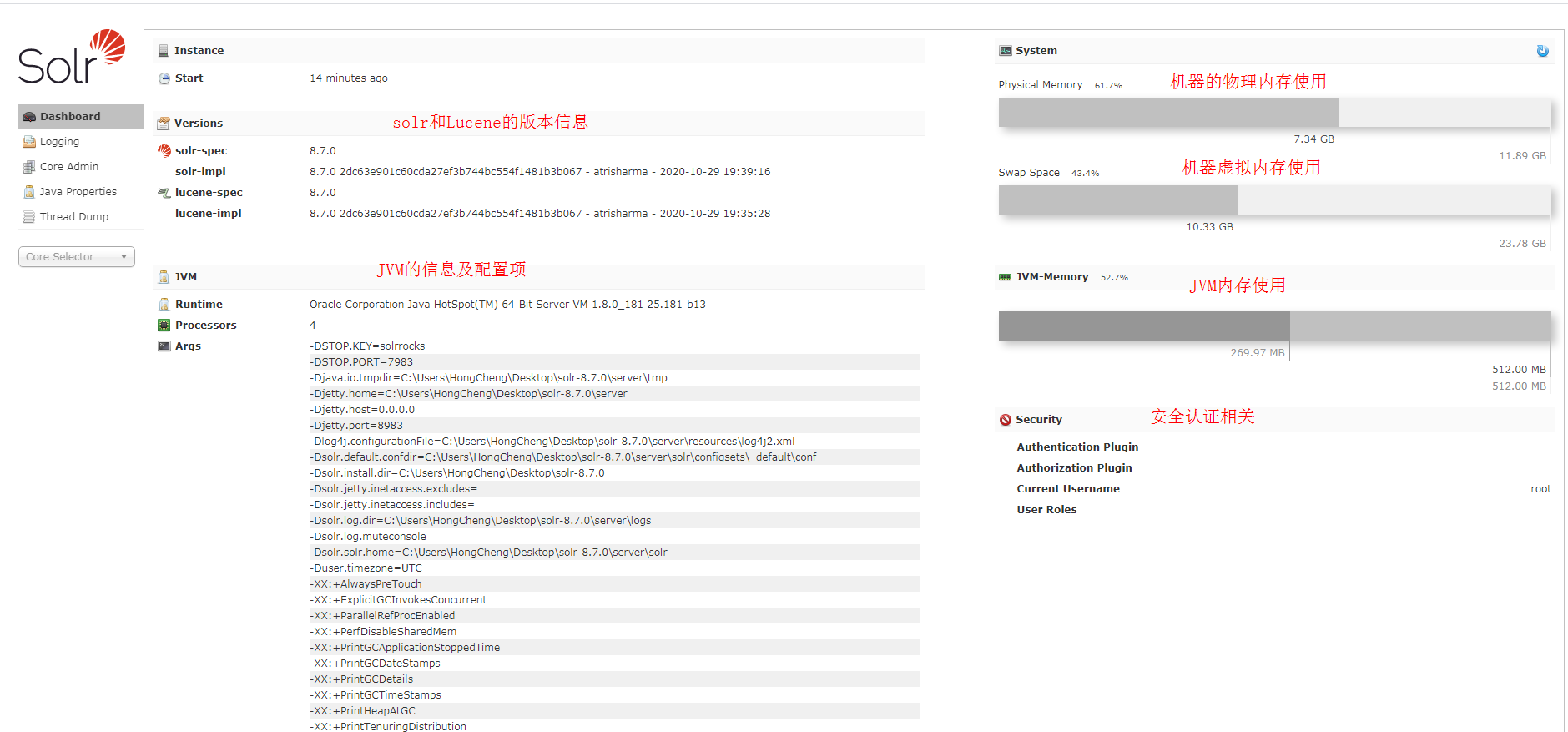
Logging:
日志信息,还可以修改记录的日志级别

Core :
core核心管理,类似与MySQL里面表的概念
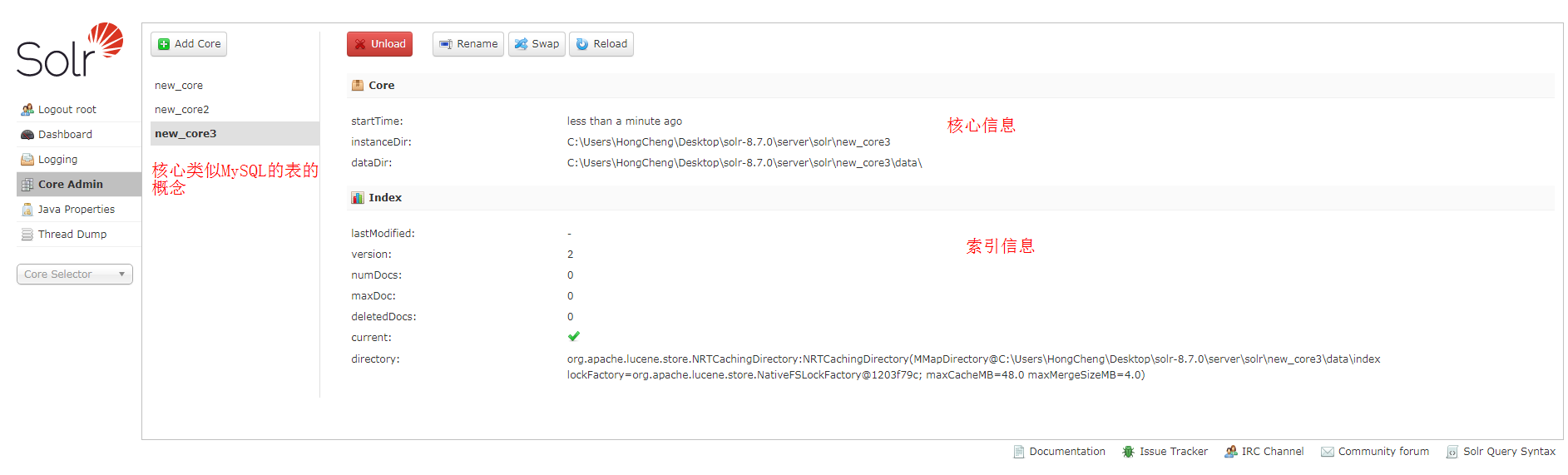
注意,新建一个core核心,不能简单的在页面上操作就行,需要在本地磁盘添加一些配置文件,否则就会报错。

首先你要去你的solr的home目录建一个文件夹,取名随意,建议和新core的名字一致
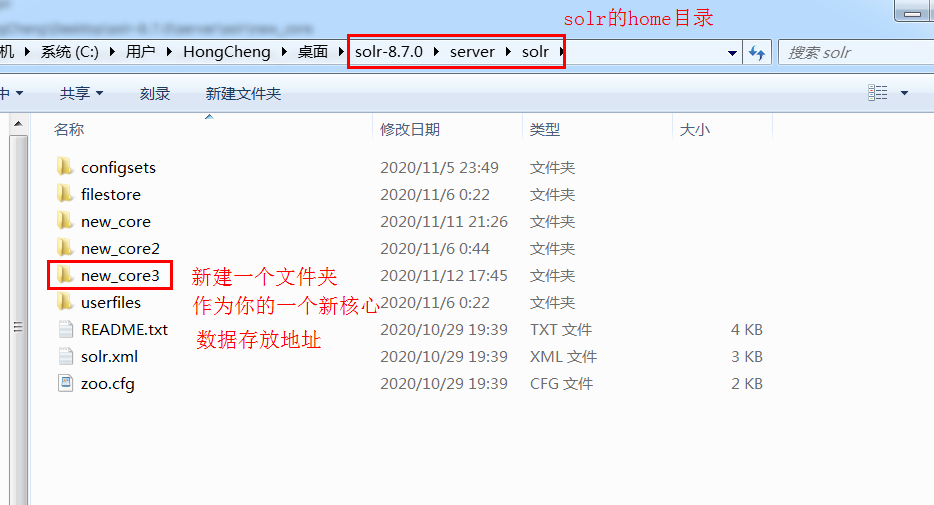
紧接着去 \server\solr\configsets\_default 目录里面复制conf这个文件夹,里面有必须的配置文件
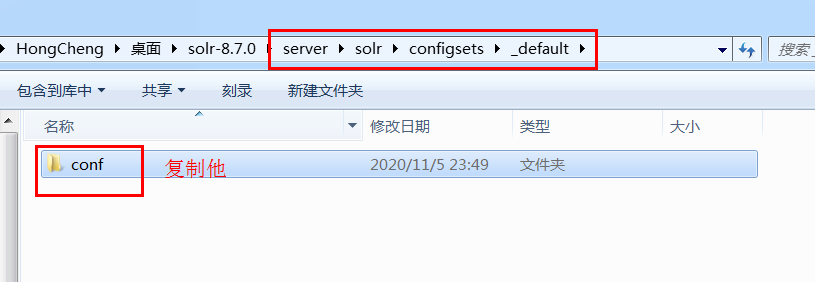
回到我们刚刚新建的目录,粘贴下去,重启solr

点击add core,然后刷新页面,就出现新的了


java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。

Tread Dump:
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。

Core selector
选择一个SolrCore进行详细操作
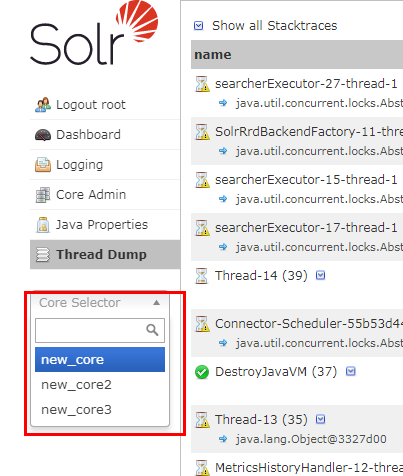
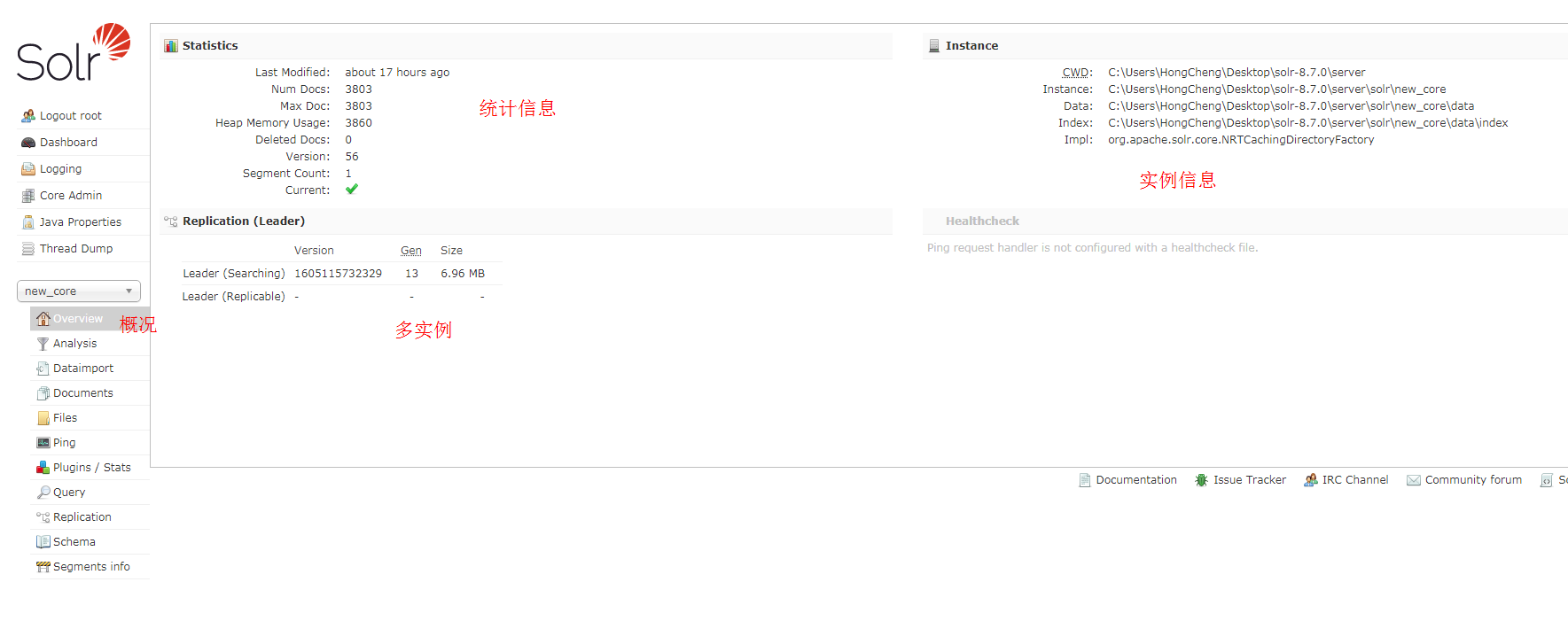
Overview:
概况
analysis:
通过此界面可以测试索引分析器和搜索分析器的执行情况

Dataimport:
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
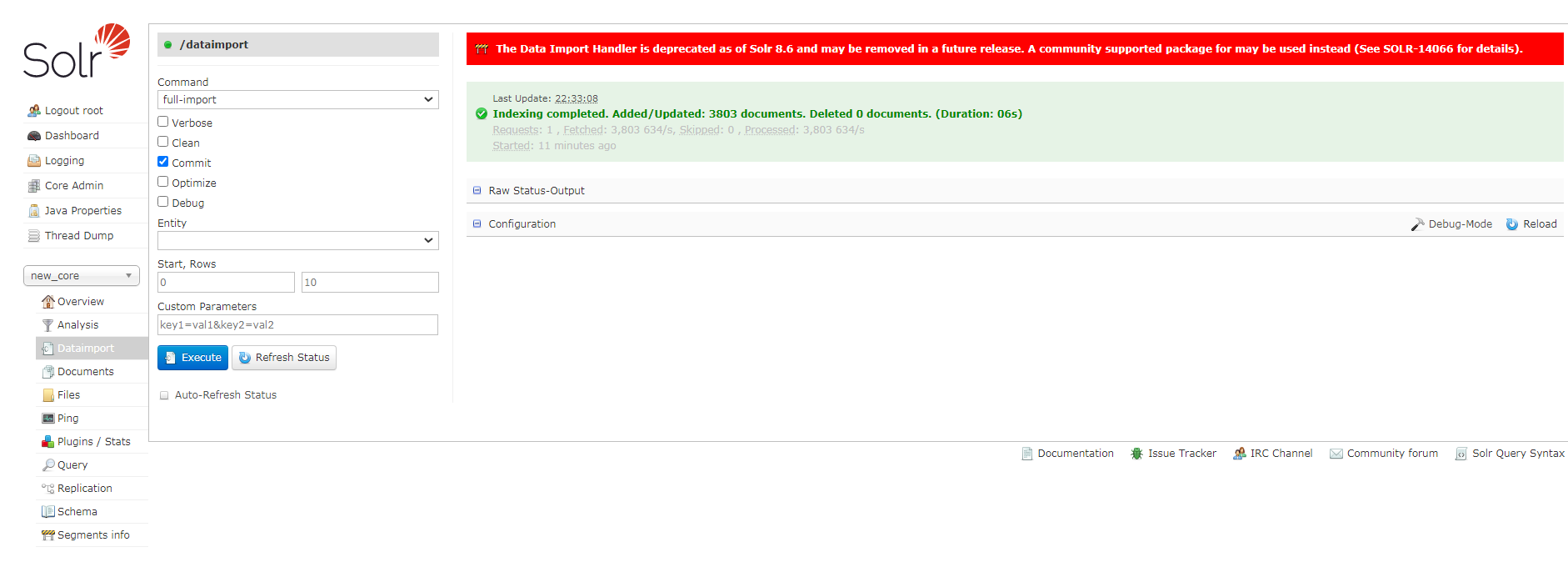
Documents:
通过此菜单可以创建索引、更新索引、删除索引等操作
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新
Files:
Plugins:
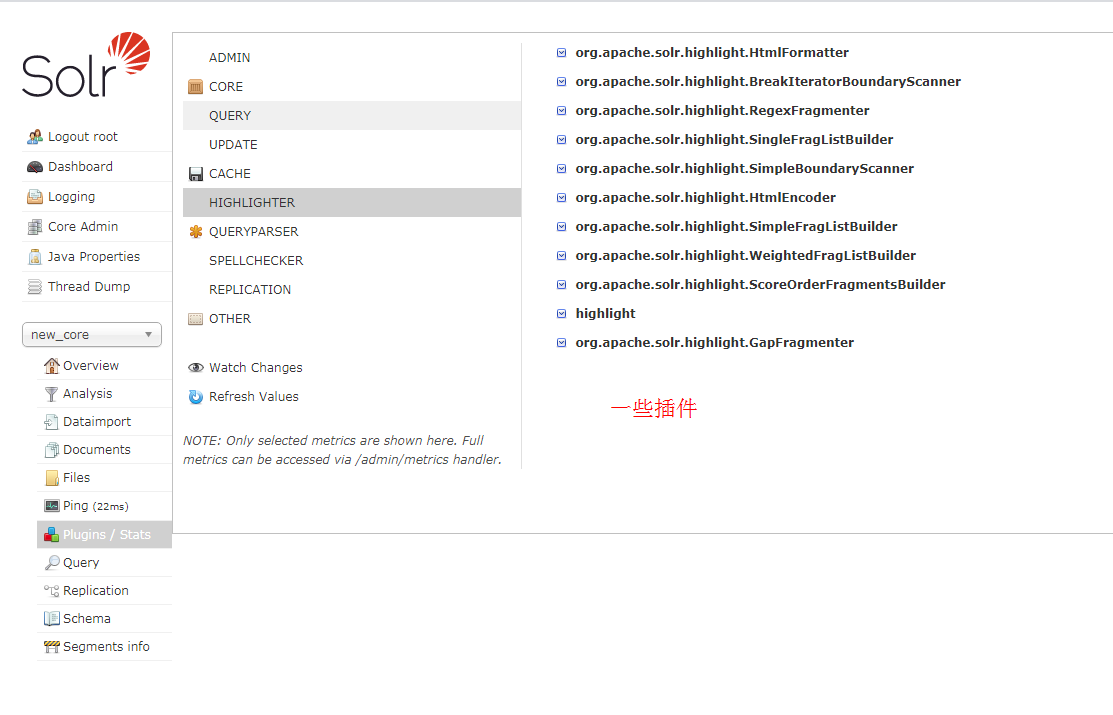
Query:
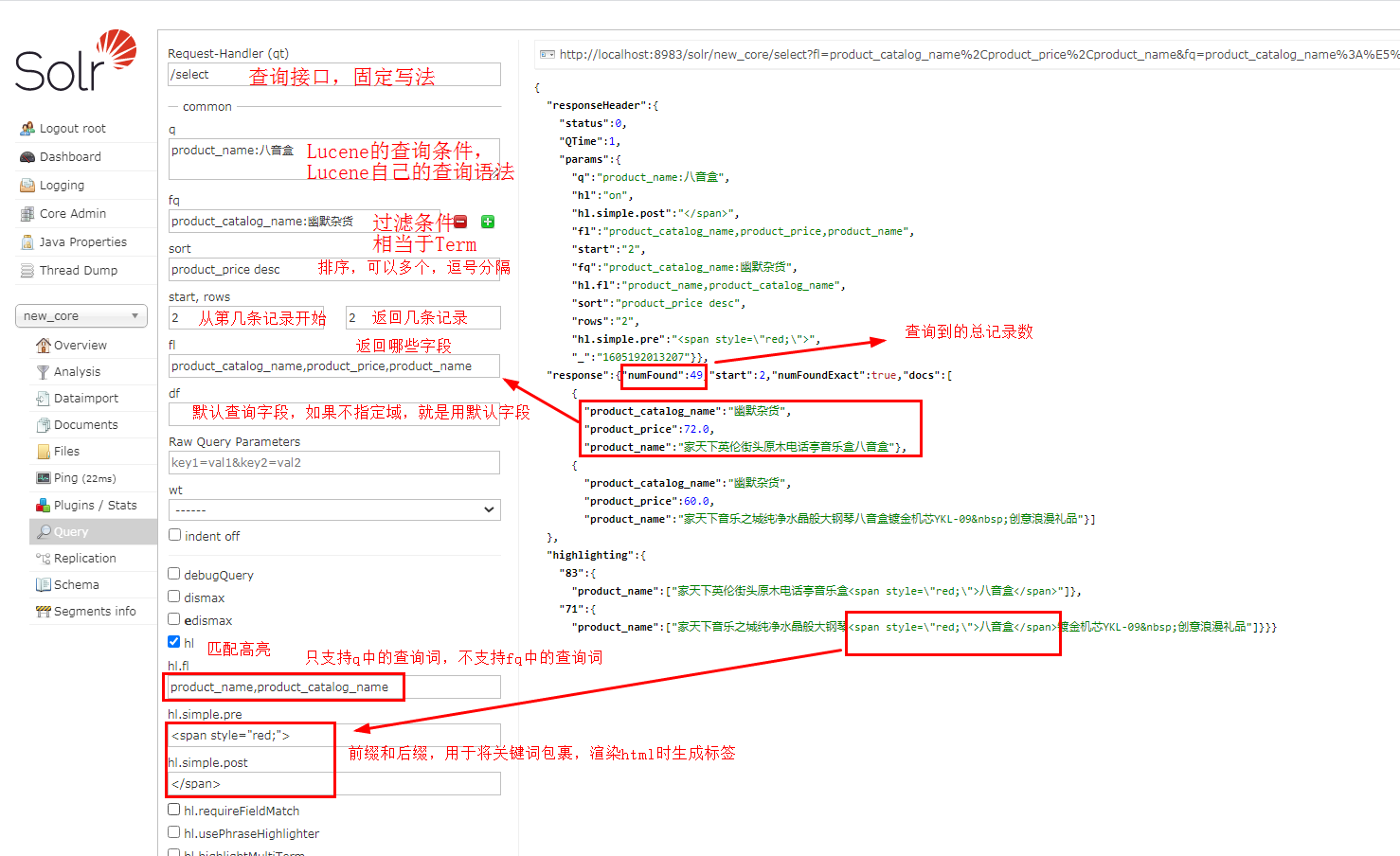
可以进行各种查询
Replication :

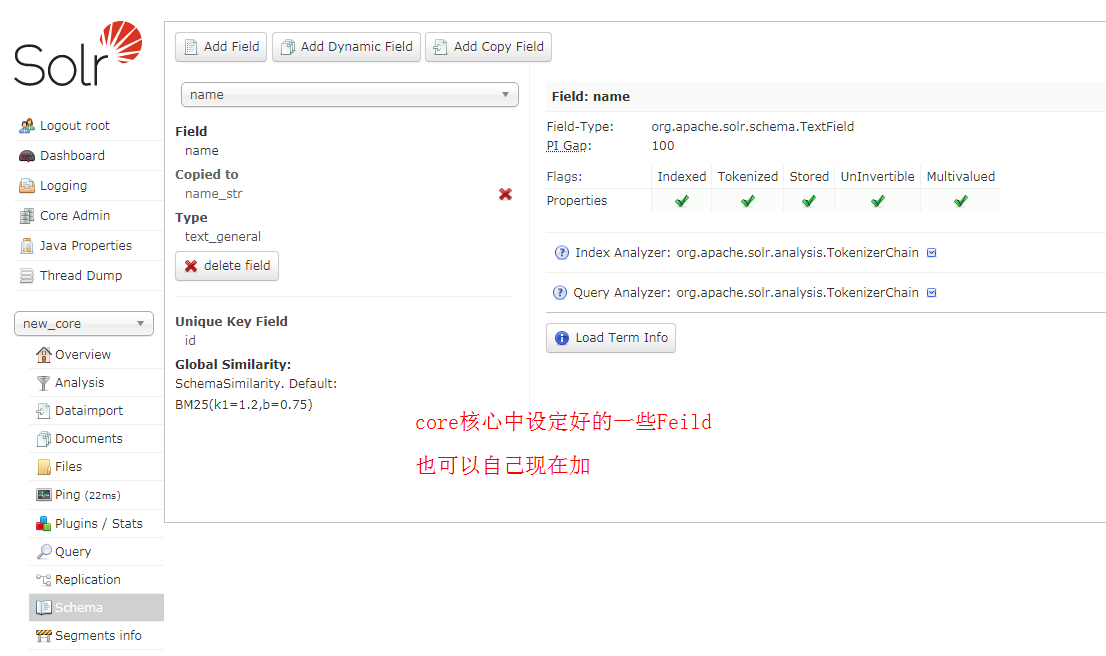
Schema:
配置ik分词器:
solr的管理界面基本就这样了
下面我们配置以下ik分词器
配置上和之前我们弄Lucene是一样的,这是官网地址 https://github.com/magese/ik-analyzer-solr
下载jar包放到 /WEB-INF/lib 文件夹中
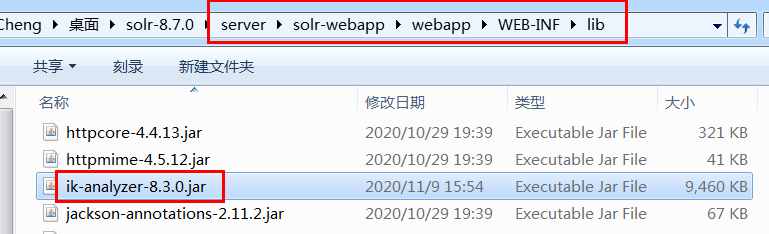
复制几个配置文件和词典到classes文件夹中
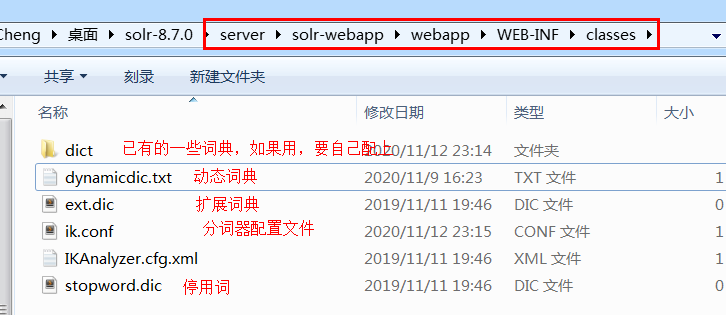
如果要用那几个词典的话,要自己加上

去你要使用ik分词器的core的约束文件上进行修改

加入以下这一段话
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
接下来你就可以自己给Field指定ik分词器了
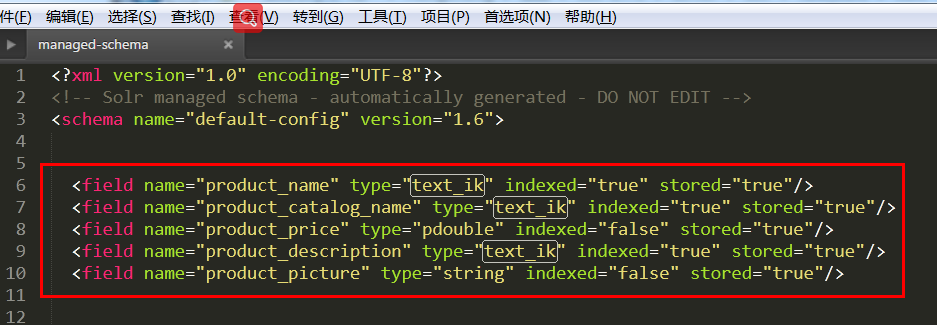
同时页面也会显示ik分词器了

不过需要注意的是,那个core需要用ik分词器,那个core就需要配置,无法全局配置
solr配置文件:
有几个配置文件我们会经常用到,所以有必要了解下:
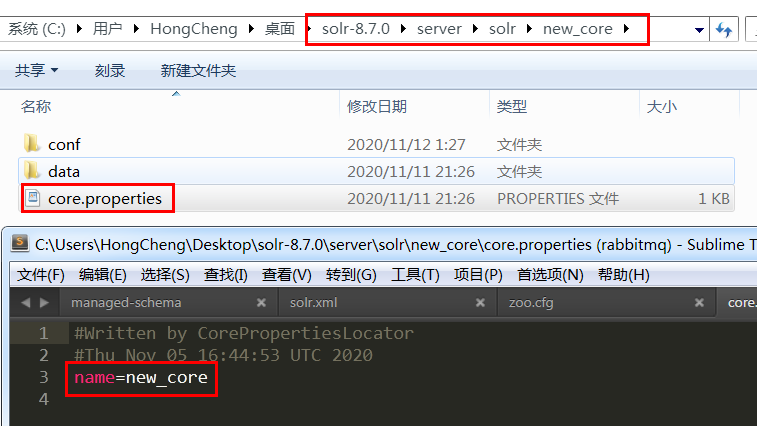
core.properties:
里面存放了核心的名字
solrconfig.xml:
这个类其实主要就是配置一些handler,下面是精简后的一些代码,像
/query
/update 这样的处理接口,也是在这里进行配置的,包括我们后期需要加的导入功能,也是要在这里加一个handler
<?xml version="1.0" encoding="UTF-8" ?>
<luceneMatchVersion>8.7.0</luceneMatchVersion>
<dataDir>${solr.data.dir:}</dataDir>
<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}" />
<codecFactory class="solr.SchemaCodecFactory" />
<indexConfig>
<lockType>${solr.lock.type:native}</lockType>
</indexConfig>
<jmx />
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
<int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}</int>
</updateLog>
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:15000}</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime>
</autoSoftCommit>
</updateHandler>
<query>
<maxBooleanClauses>${solr.max.booleanClauses:1024}</maxBooleanClauses>
<filterCache class="solr.FastLRUCache" size="512" initialSize="512" autowarmCount="0" />
<queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" />
<documentCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" />
<cache name="perSegFilter" class="solr.search.LRUCache" size="10" initialSize="0" autowarmCount="10" regenerator="solr.NoOpRegenerator" />
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<queryResultWindowSize>20</queryResultWindowSize>
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
</arr>
</listener>
<listener event="firstSearcher" class="solr.QuerySenderListener">
<arr name="queries">
</arr>
</listener>
<useColdSearcher>false</useColdSearcher>
</query>
<circuitBreakers enabled="true">
</circuitBreakers>
<requestDispatcher>
<httpCaching never304="true" />
</requestDispatcher>
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
</lst>
</requestHandler>
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
</lst>
</requestHandler>
<initParams path="/update/**,/query,/select,/spell">
<lst name="defaults">
<str name="df">_text_</str>
</lst>
</initParams>
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">text_general</str>
<lst name="spellchecker">
<str name="name">default</str>
<str name="field">_text_</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
<str name="distanceMeasure">internal</str>
<float name="accuracy">0.5</float>
<int name="maxEdits">2</int>
<int name="minPrefix">1</int>
<int name="maxInspections">5</int>
<int name="minQueryLength">4</int>
<float name="maxQueryFrequency">0.01</float>
</lst>
</searchComponent>
<requestHandler name="/spell" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="spellcheck.dictionary">default</str>
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">true</str>
<str name="spellcheck.count">10</str>
<str name="spellcheck.alternativeTermCount">5</str>
<str name="spellcheck.maxResultsForSuggest">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
<str name="spellcheck.maxCollationTries">10</str>
<str name="spellcheck.maxCollations">5</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
<searchComponent name="terms" class="solr.TermsComponent" />
<requestHandler name="/terms" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<bool name="terms">true</bool>
<bool name="distrib">false</bool>
</lst>
<arr name="components">
<str>terms</str>
</arr>
</requestHandler>
<searchComponent class="solr.HighlightComponent" name="highlight">
<highlighting>
<fragmenter name="gap" default="true" class="solr.highlight.GapFragmenter">
<lst name="defaults">
<int name="hl.fragsize">100</int>
</lst>
</fragmenter>
<fragmenter name="regex" class="solr.highlight.RegexFragmenter">
<lst name="defaults">
<int name="hl.fragsize">70</int>
<float name="hl.regex.slop">0.5</float>
<str name="hl.regex.pattern">[-\w ,/\n\"']{20,200}</str>
</lst>
</fragmenter>
<formatter name="html" default="true" class="solr.highlight.HtmlFormatter">
<lst name="defaults">
<str name="hl.simple.pre">
<![CDATA[<em>]]>
</str>
<str name="hl.simple.post">
<![CDATA[</em>]]>
</str>
</lst>
</formatter>
<encoder name="html" class="solr.highlight.HtmlEncoder" />
<fragListBuilder name="simple" class="solr.highlight.SimpleFragListBuilder" />
<fragListBuilder name="single" class="solr.highlight.SingleFragListBuilder" />
<fragListBuilder name="weighted" default="true" class="solr.highlight.WeightedFragListBuilder" />
<fragmentsBuilder name="default" default="true" class="solr.highlight.ScoreOrderFragmentsBuilder">
</fragmentsBuilder>
<fragmentsBuilder name="colored" class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre">
<![CDATA[
<b style="background:yellow">,<b style="background:lawgreen">,
<b style="background:aquamarine">,<b style="background:magenta">,
<b style="background:palegreen">,<b style="background:coral">,
<b style="background:wheat">,<b style="background:khaki">,
<b style="background:lime">,<b style="background:deepskyblue">]]>
</str>
<str name="hl.tag.post">
<![CDATA[</b>]]>
</str>
</lst>
</fragmentsBuilder>
<boundaryScanner name="default" default="true" class="solr.highlight.SimpleBoundaryScanner">
<lst name="defaults">
<str name="hl.bs.maxScan">10</str>
<str name="hl.bs.chars">.,!? </str>
</lst>
</boundaryScanner>
<boundaryScanner name="breakIterator" class="solr.highlight.BreakIteratorBoundaryScanner">
<lst name="defaults">
<str name="hl.bs.type">WORD</str>
<str name="hl.bs.language">en</str>
<str name="hl.bs.country">US</str>
</lst>
</boundaryScanner>
</highlighting>
</searchComponent>
<updateProcessor class="solr.UUIDUpdateProcessorFactory" name="uuid" />
<updateProcessor class="solr.RemoveBlankFieldUpdateProcessorFactory" name="remove-blank" />
<updateProcessor class="solr.FieldNameMutatingUpdateProcessorFactory" name="field-name-mutating">
<str name="pattern">[^\w-\.]</str>
<str name="replacement">_</str>
</updateProcessor>
<updateProcessor class="solr.ParseBooleanFieldUpdateProcessorFactory" name="parse-boolean" />
<updateProcessor class="solr.ParseLongFieldUpdateProcessorFactory" name="parse-long" />
<updateProcessor class="solr.ParseDoubleFieldUpdateProcessorFactory" name="parse-double" />
<updateProcessor class="solr.ParseDateFieldUpdateProcessorFactory" name="parse-date">
<arr name="format">
<str>yyyy-MM-dd['T'[HH:mm[:ss[.SSS]][z</str>
<str>yyyy-MM-dd['T'[HH:mm[:ss[,SSS]][z</str>
<str>yyyy-MM-dd HH:mm[:ss[.SSS]][z</str>
<str>yyyy-MM-dd HH:mm[:ss[,SSS]][z</str>
<str>[EEE, ]dd MMM yyyy HH:mm[:ss] z</str>
<str>EEEE, dd-MMM-yy HH:mm:ss z</str>
<str>EEE MMM ppd HH:mm:ss [z ]yyyy</str>
</arr>
</updateProcessor>
<updateProcessor class="solr.AddSchemaFieldsUpdateProcessorFactory" name="add-schema-fields">
<lst name="typeMapping">
<str name="valueClass">java.lang.String</str>
<str name="fieldType">text_general</str>
<lst name="copyField">
<str name="dest">*_str</str>
<int name="maxChars">256</int>
</lst>
<bool name="default">true</bool>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">booleans</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">pdates</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">plongs</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">pdoubles</str>
</lst>
</updateProcessor>
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema" default="${update.autoCreateFields:true}" processor="uuid,remove-blank,field-name-mutating,parse-boolean,parse-long,parse-double,parse-date,add-schema-fields">
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.DistributedUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
<queryResponseWriter name="json" class="solr.JSONResponseWriter">
<str name="content-type">text/plain; charset=UTF-8</str>
</queryResponseWriter>
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
</config>
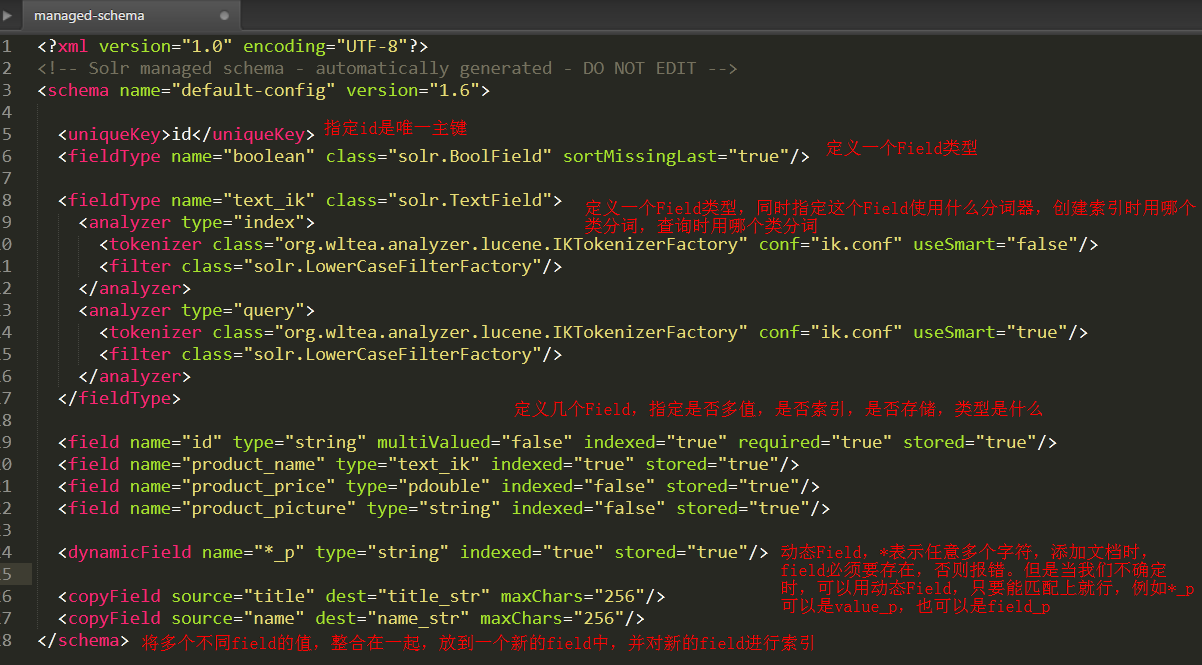
managed-schema:
这是一个约束文件,用于指定有哪些Field,Field是否索引、是否分析、是否存在、是否多值,用了哪些分词器
uniqueKey:指定一个field为主键,Lucene中为我们弄了个自增的id作为主键,但是solr选择将id放给我们自己决定。新增文档时必须指定id
fieldType:field类型,可以指定具体是用哪个类处理,是否使用分词器
field:定义一个field,相当于以前Lucene代码的 Field fileNameField = new TextField("file_name",fileName, Field.Store.YES);
dynamicField:可以使用通配符,当我们不确定field名字时,就可以用动态Field
copyField:拷贝Field,将多个field的值整合在一个新的field中,并对新的field进行索引,dest属性指定的目标field必须要是多值的,否则会报错
假设我们有这样的一个配置,title和name的值都会拷贝一份到content_text中
<field name="my_name" type="text_ik" indexed="true" stored="true"/>
<field name="my_title" type="text_ik" indexed="true" stored="true"/>
<field name="my_content_text" type="text_ik" indexed="true" stored="true" multiValued="true"/> <copyField source="my_name" dest="my_content_text" />
<copyField source="my_title" dest="my_content_text" /> 此时我插入一条文档
{
"id":"1",
"my_name":"张三",
"my_title":"法外狂徒"
}
那他实际最后会插入成
{
"id":"1",
"my_name":"张三",
"my_title":"法外狂徒",
"my_content_text":["张三", "法外狂徒"],
}
solr将以前Lucene的代码实现,改成了配置文件的形式
从数据库导入:
正常来说,没进行过任何配置的话,是没法使用导入功能的

所以我们需要进行一些配置。
首先我们要找到这两个jar包
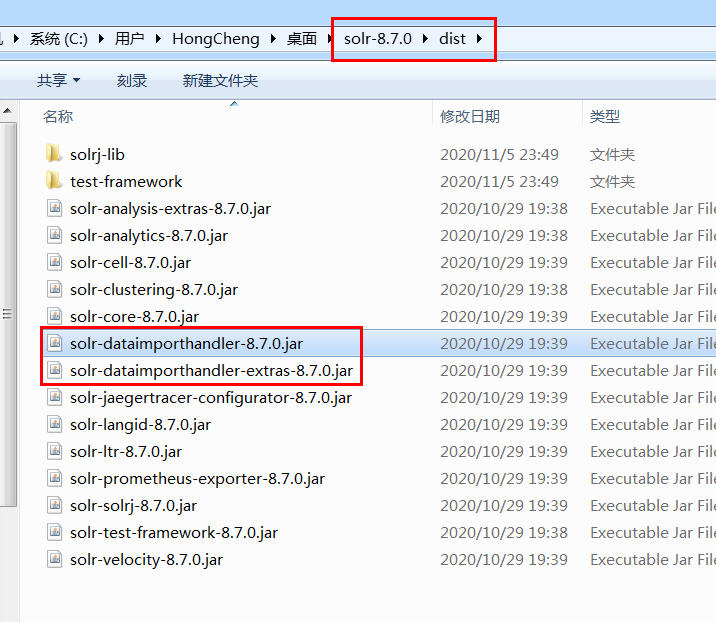
把他们复制到 \webapp\WEB-INF\lib 这里面。然后根据你要操作的数据库,导入对应的jdbc包,我用的是mysql
我有一堆数据

到你要配置导入的core的配置文件夹中,创建一个data-config.xml文件,文件名随意

<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sys?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8"
user="root"
password="root"/>
<document>
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document> </dataConfig>
然后修改solrconfig.xml,添加上导入的handler
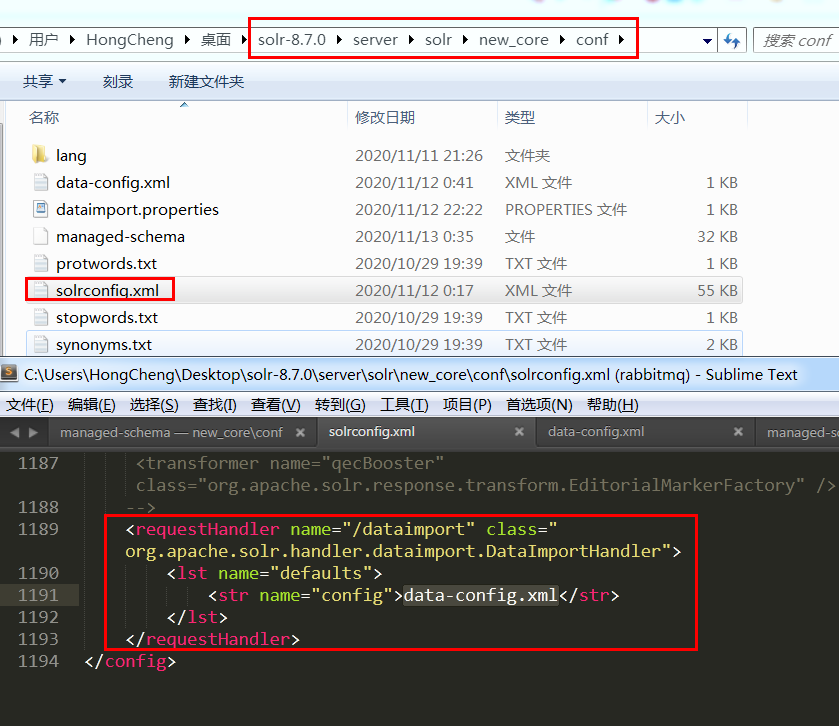
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
完了后就重启solr就可以用了
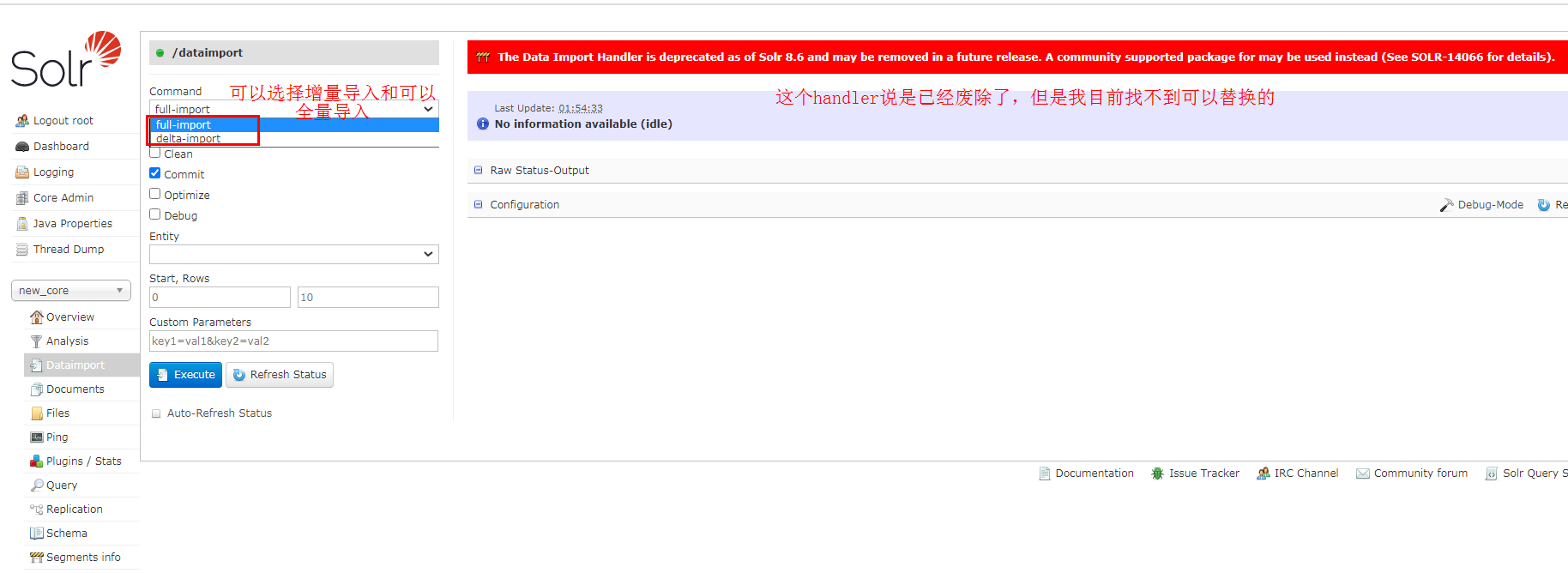
导入的可以参考官网这个文档:https://lucene.apache.org/solr/guide/8_7/uploading-structured-data-store-data-with-the-data-import-handler.html
管理界面增删改查:

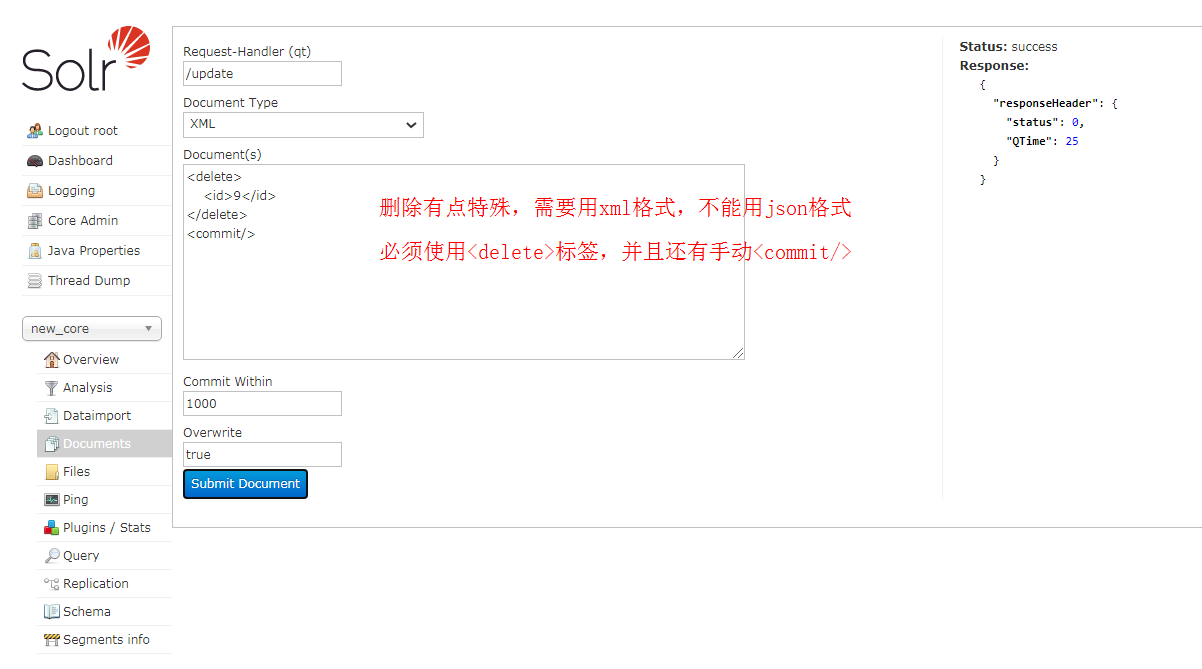
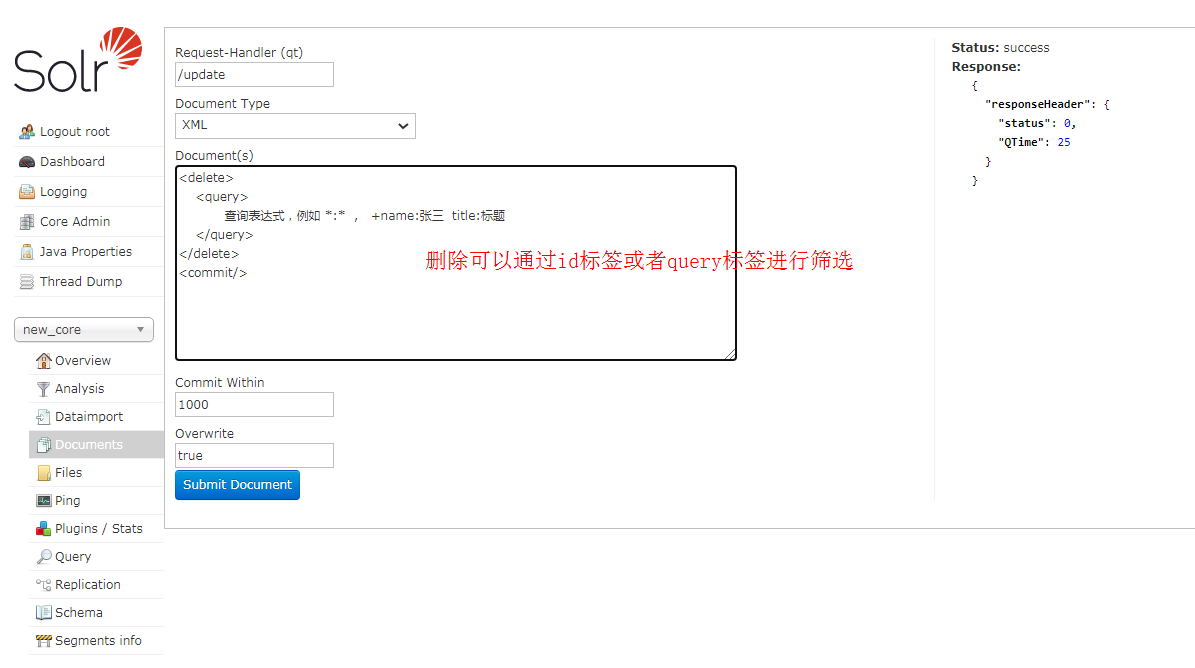
客户端增删改查:
有两个客户端,solrJ 和 Spring Data Solr ,下面我们两个都会讲到
solrJ :
先加依赖:
<!-- solrJ客户端 -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>8.7.0</version>
</dependency>
<!-- 编解码的依赖,如果solr没有开认证,可以不加 -->
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.14</version>
</dependency>
因为我自己solr开启了认证,所以url地址要加上用户名和密码
private final static String solrUrl = "http://root:root@127.0.0.1:8983/solr/new_core";
而且还要自己额外手动创建一个HttpClient
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient();
目前新版本中solr服务器加密码后,solrJ我只找到这样链接,如果还有别的方法,请留意告诉我一下,谢谢
package com.hongcheng.solrJ; import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.client.SystemDefaultHttpClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.beans.Field;
import org.apache.solr.client.solrj.impl.HttpClientUtil;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.solr.common.params.ModifiableSolrParams;
import org.apache.solr.common.params.MultiMapSolrParams;
import org.apache.solr.common.params.SolrParams;
import org.junit.jupiter.api.Test;
import org.springframework.util.IdGenerator; import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.UUID; class SolrJDemoTest { private final static String solrUrl = "http://root:root@127.0.0.1:8983/solr/new_core";
/**
* 添加文档
* 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
* 第2步:创建一个SolrInputDocument对象,然后添加域。
* 第3步:将SolrInputDocument添加到索引库。
* 第4步:提交。
* */
@Test
public void addDocument() throws IOException, SolrServerException {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrUrl)
.withHttpClient(httpclient)
.build();
// 第2步:创建一个SolrInputDocument对象,然后添加域。
SolrInputDocument document = new SolrInputDocument(); document.addField("id", UUID.randomUUID().toString().replace("-",""));
document.addField("my_name","老铁");
document.addField("my_title","666");
System.err.println(solrClient.getInvariantParams());
solrClient.add(document);
solrClient.commit(); solrClient.close();
} /**
* 把一个javabean添加进去
* */
@Test
public void addDocumentBean() throws IOException, SolrServerException {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrUrl)
.withHttpClient(httpclient)
.build(); solrClient.addBean(new User(UUID.randomUUID().toString().replace("-",""),"李四","群中恶霸")); solrClient.commit(); solrClient.close();
} /**
* 更新
* 其实并没有实际的更新方法,都是通过add方法添加,如果id值已经存在,就删除再添加
* */
@Test
public void updataDocument() throws IOException, SolrServerException {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrUrl)
.withHttpClient(httpclient)
.build(); solrClient.addBean(new User("e2d1cdb08857452ebd13a460d49e067f","李四","李四不是群中恶霸")); solrClient.commit(); solrClient.close();
} /**
* 删除
* */
@Test
public void daleteDocument() throws IOException, SolrServerException {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrUrl)
.withHttpClient(httpclient)
.build(); solrClient.addBean(new User("e2d1cdb08857452ebd13a460d49e067f","李四","李四不是群中恶霸")); solrClient.commit(); solrClient.close();
} /**
* 删除
* */
@Test
public void searchDocument() throws IOException, SolrServerException {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrUrl)
.withHttpClient(httpclient)
.build(); //创建一个query对象
SolrQuery query = new SolrQuery();
//设置查询条件,q是必须要填的,如果不填,会查不出来
query.setQuery("*:*");
//过滤条件,
query.setFilterQueries("product_catalog_name:幽默杂货");
//排序条件
query.setSort("product_price", SolrQuery.ORDER.asc);
//分页处理
query.setStart(0);
query.setRows(10);
query.setFields("id","product_name","product_price","product_catalog_name","product_description");
//设置默认搜索域
// query.set("df", "product_keywords");
//高亮显示
query.setHighlight(true);
//高亮显示的域
query.addHighlightField("product_name");
//高亮显示的前缀
query.setHighlightSimplePre("<span stype='color:red;'>");
//高亮显示的后缀
query.setHighlightSimplePost("</span>");
System.err.println(query);
//执行查询
QueryResponse queryResponse = solrClient.query(query);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
//遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
//取高亮显示
String productName = "";
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
List<String> list = highlighting.get(solrDocument.get("id")).get("product_name");
//判断是否有高亮内容
if (null != list) {
productName = list.get(0);
} else {
productName = (String) solrDocument.get("product_name");
} System.out.println(productName);
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture")); } solrClient.close();
} } @Getter
@Setter
@AllArgsConstructor
class User{
@Field("id")
private String id;
@Field("my_name")
private String name;
@Field("my_title")
private String title;
}
Spring Data Solr:
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
配置文件:
这两个是我们自己的自定义属性
spring:
data:
solr:
host: http://root:root@127.0.0.1:8983/solr #因为我自己solr服务开启了认证,所以这里我要加上用户名和密码
core: new_core
配置文件:
注入bean
package com.hongcheng.solrJ; import org.apache.http.impl.client.SystemDefaultHttpClient;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.core.SolrTemplate; @Configuration
public class SolrConfig {
@Value("${spring.data.solr.host}")
private String solrHost; @Value("${spring.data.solr.core}")
private String solrCore;
/**
* 配置SolrTemplate
*/
@Bean
public SolrTemplate solrTemplate() {
SystemDefaultHttpClient httpclient = new SystemDefaultHttpClient(); // 第1步:和Solr服务器建立连接。HttpSolrClient对象建立连接。
HttpSolrClient solrClient = new HttpSolrClient.Builder()
.withBaseSolrUrl(solrHost)
.withHttpClient(httpclient)
.build();
SolrTemplate template = new SolrTemplate(solrClient);
return template;
}
}
增删改查代码:
package com.hongcheng.springdatasolr; import com.hongcheng.solrJ.SolrConfig;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.apache.solr.client.solrj.beans.Field;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.solr.core.SolrTemplate;
import org.springframework.data.solr.core.query.*;
import org.springframework.data.solr.core.query.result.HighlightEntry;
import org.springframework.data.solr.core.query.result.HighlightPage; import javax.annotation.Resource;
import java.util.List;
import java.util.Optional;
import java.util.UUID; @SpringBootTest(classes = SolrConfig.class)
public class SpringDataSolrDemoTest { @Resource
private SolrTemplate solrTemplate; /**
* 添加文档
* */
@Test
public void addDocument(){
solrTemplate.saveBean("new_core",new SpringDataSolrDemoTest.User(UUID.randomUUID().toString().replace("-",""),"李四","群中恶霸2222"));
solrTemplate.commit("new_core");
}
/**
* 根据id更新文档
* */
@Test
public void updateDocument(){
solrTemplate.saveBean("new_core",new SpringDataSolrDemoTest.User("d0e5d628b5724c9ab3d903ba1b88d683","李四","群中恶霸3333"));
solrTemplate.commit("new_core");
}
/**
* 根据id删除文档
* */
@Test
public void deleteDocumentById(){
solrTemplate.deleteByIds("new_core","d0e5d628b5724c9ab3d903ba1b88d683");
solrTemplate.commit("new_core");
}
/**
* 条件删除文档
* */
@Test
public void deleteDocumentByQuery(){
SolrDataQuery solrDataQuery = new SimpleQuery();
solrDataQuery.addCriteria(new Criteria("my_title").is("恶霸")); solrTemplate.delete("new_core",solrDataQuery);
solrTemplate.commit("new_core");
} /**
* 根据id查找文档
* */
@Test
public void searchById(){
Optional<Product> new_core = solrTemplate.getById("new_core", "4701", Product.class);
System.err.println(new_core.get());
solrTemplate.commit("new_core");
}
/**
* 条件查询文档
* */
@Test
public void searchByQuery(){
SimpleHighlightQuery simpleHighlightQuery = new SimpleHighlightQuery();
// 分页
simpleHighlightQuery.setPageRequest( PageRequest.of(0,10, Sort.Direction.ASC,"product_price"));
// 设置投影
simpleHighlightQuery.addProjectionOnField("id");
simpleHighlightQuery.addProjectionOnField("product_catalog_name");
simpleHighlightQuery.addProjectionOnField("product_name");
simpleHighlightQuery.addProjectionOnField("product_price");
// 设置条件
// 可以使用查询表达式
// simpleHighlightQuery.addCriteria(new Criteria().expression("product_catalog_name:餐具 AND product_name:水果 AND product_price:[10 TO 50}"));
// 也可以使用api
simpleHighlightQuery.addCriteria(new Criteria("product_catalog_name").is("餐具"))
.addCriteria(new Criteria("product_name").is("水果"))
.addCriteria(new Criteria("product_price").between(10,50,true,false)); // 设置高亮
HighlightOptions highlightOptions = new HighlightOptions();
highlightOptions.setSimplePrefix("<span style='color:red;'>");
highlightOptions.setSimplePostfix("</span>");
highlightOptions.addField("product_catalog_name","product_name");
simpleHighlightQuery.setHighlightOptions(highlightOptions); // 查询
HighlightPage<Product> new_core = solrTemplate.queryForHighlightPage("new_core", simpleHighlightQuery, Product.class);
// 打印结果
System.err.println("总记录数:" + new_core.getTotalElements());
for (Product product : new_core.getContent()) {
// 获取高亮部分,是不会合并到源文档中的
List<HighlightEntry.Highlight> highlights = new_core.getHighlights(product);
highlights.stream().forEach((highlight)->{
highlight.getSnipplets().forEach(System.err::print);
System.err.println();
});
System.err.println(product);
System.err.println();
}
} @Getter
@Setter
@AllArgsConstructor
class User{
@Field("id")
private String id;
@Field("my_name")
private String name;
@Field("my_title")
private String title;
} @Getter
@Setter
@ToString
@AllArgsConstructor
class Product{
@Field("id")
private String id;
@Field("product_catalog_name")
private String catalogName;
@Field("product_price")
private Double price;
@Field("product_name")
private String name;
@Field("product_description")
private String description;
@Field("product_picture")
private String picture;
} }
以上便是全部了,如果哪里写错了,请留言说明,我进行修改,谢谢。
solr全文检索学习的更多相关文章
- Solr的学习使用之(一)部署
Solr的主要功能是全文检索,该功能分为两个过程:创建索引和对索引进行搜索 一.心得体会 第一次写技术博客,这次写的基本上都是从网络上整理的来的,外加自己的一些实践,以后争取全部原创哈,都说写技术博客 ...
- solr课程学习系列-solr服务器配置(2)
本文是solr课程学习系列的第2个课程,对solr基础知识不是很了解的请查看solr课程学习系列-solr的概念与结构(1) 本文以windows的solr6服务器搭建为例. 一.solr的工作环境: ...
- SOLR (全文检索)
SOLR (全文检索) http://sinykk.iteye.com/ 1. 什么是SOLR 官方网站 http://wiki.apache.org/solr http://wiki.apach ...
- Elasticsearch 6.x版本全文检索学习之分布式特性介绍
1.Elasticsearch 6.x版本全文检索学习之分布式特性介绍. 1).Elasticsearch支持集群默认,是一个分布式系统,其好处主要有两个. a.增大系统容量,如内存.磁盘.使得es集 ...
- Elasticsearch 6.x版本全文检索学习之Search API
Elasticsearch 6.x版本全文检索学习之Search API. 1).Search API,实现对es中存储的数据进行查询分析,endpoind为_search,如下所示. 方式一.GET ...
- Solr的学习使用之(九)facet.pivot实战
facet.pivot自己的理解,就是按照多个维度进行分组查询,以下是自己的实战代码,按照newsType,property两个维度统计: public List<ReportNewsTypeD ...
- Solr的学习使用之(三)IKAnalyzer中文分词器的配置
1.为什么要配置? 1.我们知道要使用Solr进行搜索,肯定要对词语进行分词,但是由于Solr的analysis包并没有带支持中文的包或者对中文的分词效果不好,需要自己添加中文分词器:目前呼声较高的是 ...
- 全文检索学习历程目录结构(Lucene、ElasticSearch)
1.目录 (1) Apache Lucene(全文检索引擎)—创建索引:http://www.cnblogs.com/hanyinglong/p/5387816.html (2) Apache Luc ...
- solr全文检索原理及solr5.5.0 Windows部署
文章原理链接:http://blog.csdn.net/xiaoyu411502/article/details/44803859 自己稍微总结:全文检索主要有两个过程:创建索引,搜索索引 创建索引: ...
随机推荐
- MeteoInfoLab脚本示例:计算温度平流
需要温度和风场U/V分量格点数据,计算中主要用到cdiff函数,结果用GrADS验证一致.脚本程序: print 'Open data files...' f_air = addfile('D:/Te ...
- 提取swagger内容到csv表格,excel可打开
swagger生成的页面api接口统计,有几种方法 直接在前端用js提取出来,较麻烦(不推荐,不同版本的页面生成的标签有可能不一样,因此可能提取不出来) //apilet a = document.g ...
- Verilog基础入门——简单的语句块编写(一)
[题干] [代码] module top_module ( input in, output out ); assign out = ~in; endmodule 简单的实现一个非门
- gin+gorm 用户服务
package main import ( "fmt" "github.com/gin-gonic/gin" "github.com/jinzhu/g ...
- spring boot:用redis+redisson实现分布式锁(redisson3.11.1/spring boot 2.2)
一,为什么要使用分布式锁? 如果在并发时锁定代码的执行,java中用synchronized锁保证了线程的原子性和可见性 但java锁只在单机上有效,如果是多台服务器上的并发访问,则需要使用分布式锁, ...
- Python函数名的应用和新特性格式化输出
1.函数名指向的是函数的内存地址. def func(): print(123) print(func,type(func)) # <function func at 0x000000000 ...
- buuctf-misc-snake 详解
打开压缩包,里面一张蛇的图片,看的我是真恶心,看了看详细信息,没什么,然后我用formstlrb分离,然后有一个压缩包 以为还像往常一样,有伪加密或者简单加密,但是居然啥也没有,里面有两个文件,key ...
- 《NASA对N+3代先进飞行器概念设计最终报告》阅读笔记
民用航空的爆炸式增长已是未来的必然,灿烂的前景也意味着巨大的挑战,谁能发掘到未来技术的潜力,谁就能称霸下一个30年的天空! 文章目录 总概述 单双争霸 四点发现 方案分析 多维度分析 设计要求 品质因 ...
- django—视图相关
FBV与CBV FBV:function based view 基于函数的视图 CBV:class based view 基于类的视图 CBV的定义: from django.views imp ...
- .Net Core实现基于Quart.Net的任务管理
前段时间给公司项目升级.net框架,把原先的任务管理平台用.net core实现,现做如下整理: 一.实现思路 之前的实现也是参考了博客园中其他文章实现的思路: 一个任务定义一个实现IJob接口的类, ...