分布式任务队列 Celery —— 应用基础
目录
前文列表
分布式任务队列 Celery
分布式任务队列 Celery —— 详解工作流
前言
紧接前文,继续看 Celery 应用基础,下列样例依旧从前文 proj 中进行修改。
Celery 的周期(定时)任务
Celery 周期任务功能由 Beat 任务调度器模块支撑,Beat 是一个服务进程,负责周期性启动 beat_schedule 中定义的任务。
e.g.
# filename: app_factory.py
from __future__ import absolute_import
from celery import Celery
from kombu import Queue, Exchange
def make_app():
app = Celery('proj')
app.config_from_object('proj.celeryconfig')
default_exchange = Exchange('default', type='direct')
web_exchange = Exchange('task', type='direct')
app.conf.task_default_queue = 'default'
app.conf.task_default_exchange = 'default'
app.conf.task_default_routing_key = 'default'
app.conf.task_queues = (
Queue('default', default_exchange, routing_key='default'),
Queue('high_queue', web_exchange, routing_key='hign_task'),
Queue('low_queue', web_exchange, routing_key='low_task'),
)
# 设定 Beat 时区,默认为 UTC 时区
app.conf.timezone = 'Asia/Shanghai’
# 在 beat_schedule 中声明周期任务
app.conf.beat_schedule = {
# 周期任务 Friendly Name
'periodic_task_add': {
# 任务全路径
'task': 'proj.task.tasks.add’,
# 周期时间
'schedule': 3.0,
# 指定任务所需的参数
'args': (2, 2)
},
}
return app使用 -B 选择,表示启动 Celery Worker 服务进程的同时启动 Beat 模块。

NOTE 1:Beat 会把周期任务的时间表存储在 celerybeat-schedule 文件,在执行指令的当前目录生成。当 timezone 发生改变时,Beat 会根据 celerybeat-schedule 的内容自动调整计时方式。
NOTE 2:Beat 也支持 crontab 计时方式,十分简单易用。
e.g.
# filename: app_factory.py
from celery.schedules import crontab
…
app.conf.beat_schedule = {
'periodic_task_add': {
'task': 'proj.task.tasks.add’,
# 每隔一分钟周期执行
'schedule': crontab(minute='*/1'),
'args': (2, 2)
},
}Celery 的同步调用
Task.get 方法处理用于获取任务的执行结果之外,还能够用于实现 Celery 同步调用,以满足更多的应用场景。
e.g.
# filename: tasks.py
import time
from proj.celery import app
@app.task
def add(x, y, debug=False):
# Test sync invoke.
time.sleep(10)
for i in xrange(10):
print("Warting: %s s" % i)
if debug:
print("x: %s; y: %s" % (x, y))
return x + y同步调用任务 add
>>> from proj.task.tasks import add
>>> add.delay(2, 2).get()
4
因为直接调用了 get 方法,所以进程会被阻塞知道任务 add 返回结果为止。
Celery 结果储存
如果你对任务执行的结果非常关注,那么你可以使用数据库(e.g. Redis)来充当 Backend,从而将执行结果持久化。
e.g.
# 执行一个任务,并取得任务 id
>>> from proj.task.tasks import add
>>> result = add.delay(2, 2)
>>> result.status
u’SUCCESS'
>>> result.get()
4
>>> result.id
'65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab’进入 Redis 数据库,查看该任务对应的记录。
root@aju-test-env:~# redis-cli
127.0.0.1:6379>
# 查看 Redis 所有的 keys
127.0.0.1:6379> keys *
1) "celery-task-meta-da3f6f3d-f977-4b39-a795-eaa89aca03ec"
2) "celery-task-meta-38437d5c-ebd8-442c-8605-435a48853085”
...
35) "celery-task-meta-65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab"
...
# 通过任务 id,可以定位出任务在 Redis 中的 value
127.0.0.1:6379> GET 'celery-task-meta-65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab'
"{\"status\": \"SUCCESS\", \"traceback\": null, \"result\": 4, \"task_id\": \"65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab\", \"children\": []}"Celery 的监控
Celery Flower 是 Celery 官方推荐的监控工具,借助于 Celery Events 接口,Flower 能够实时监控 Celery 的 Worker、Tasks、Broker、并发池等重要对象。
- 安装 Flower
$ pip install flower- 开启 Celery Events
celery worker -A proj -E -l info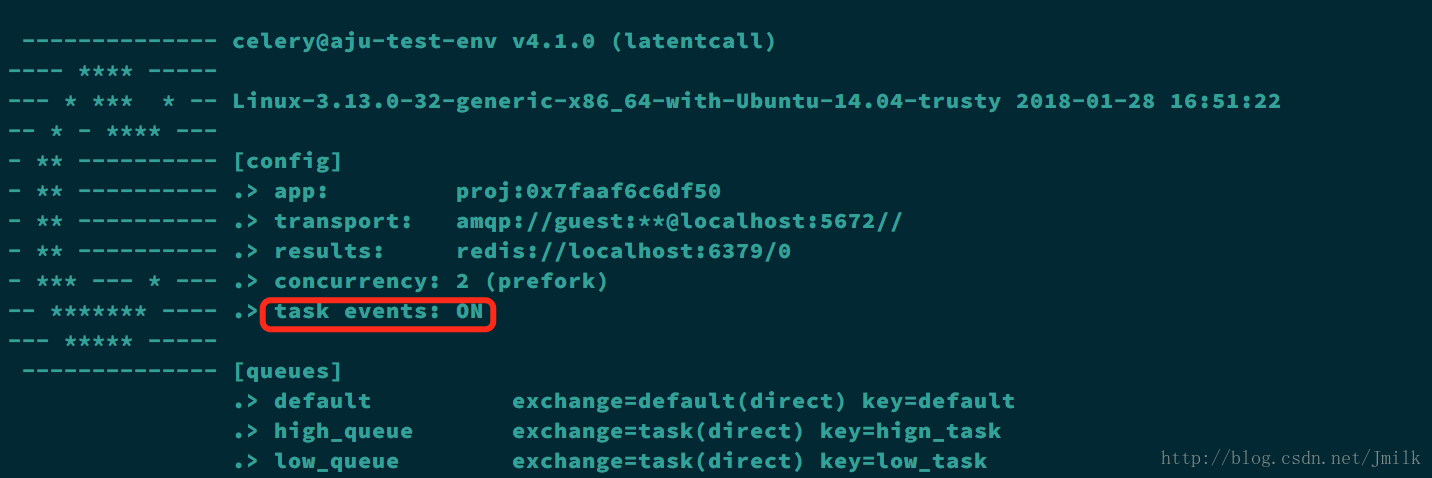
- 开启 RabbitMQ Management Plugin
$ rabbitmq-plugins enable rabbitmq_management
$ service rabbitmq-server restart- 启动 Flower,并指定 broker URL
>nbsp;celery flower -l info --broker_api=http://guest:guest@<rabbitmq_server_ip>:15672/api/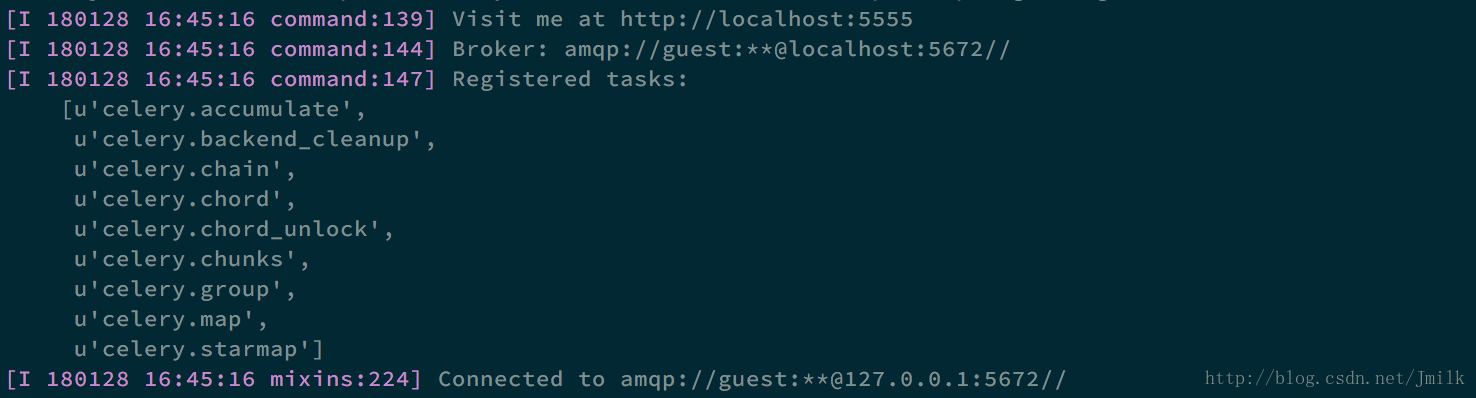
- 访问 Flower Web,浏览器打开
http://<flower_server_ip>:5555/dashboard
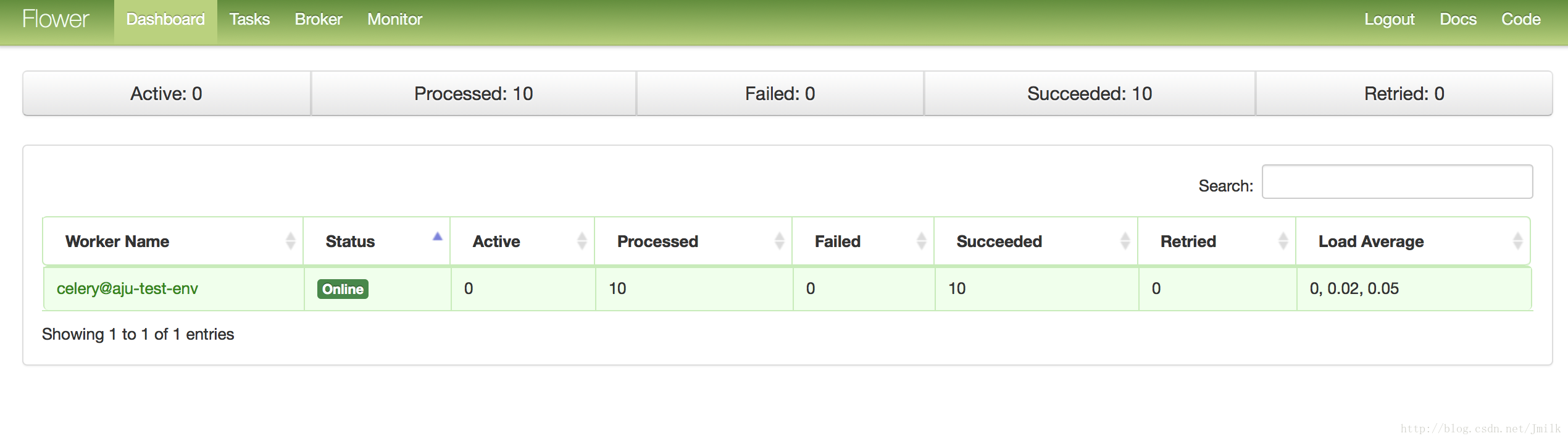
Celery 的调试
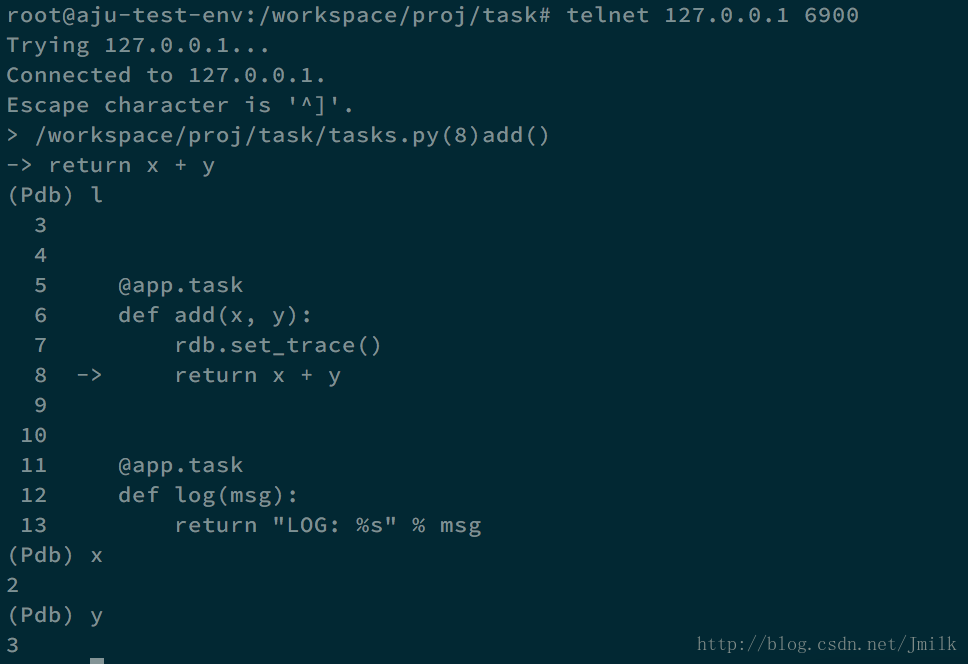
Celery 借助 telnet 可以支持远程 pdb 调试,非常方便。
# filename: tasks.py
from proj.celery import app
from celery.contrib import rdb
@app.task
def add(x, y):
# 设置断点
rdb.set_trace()
return x + y使用 celery.contrib 的 rdb 来设置断点,然后重启 Celery Worker 服务。
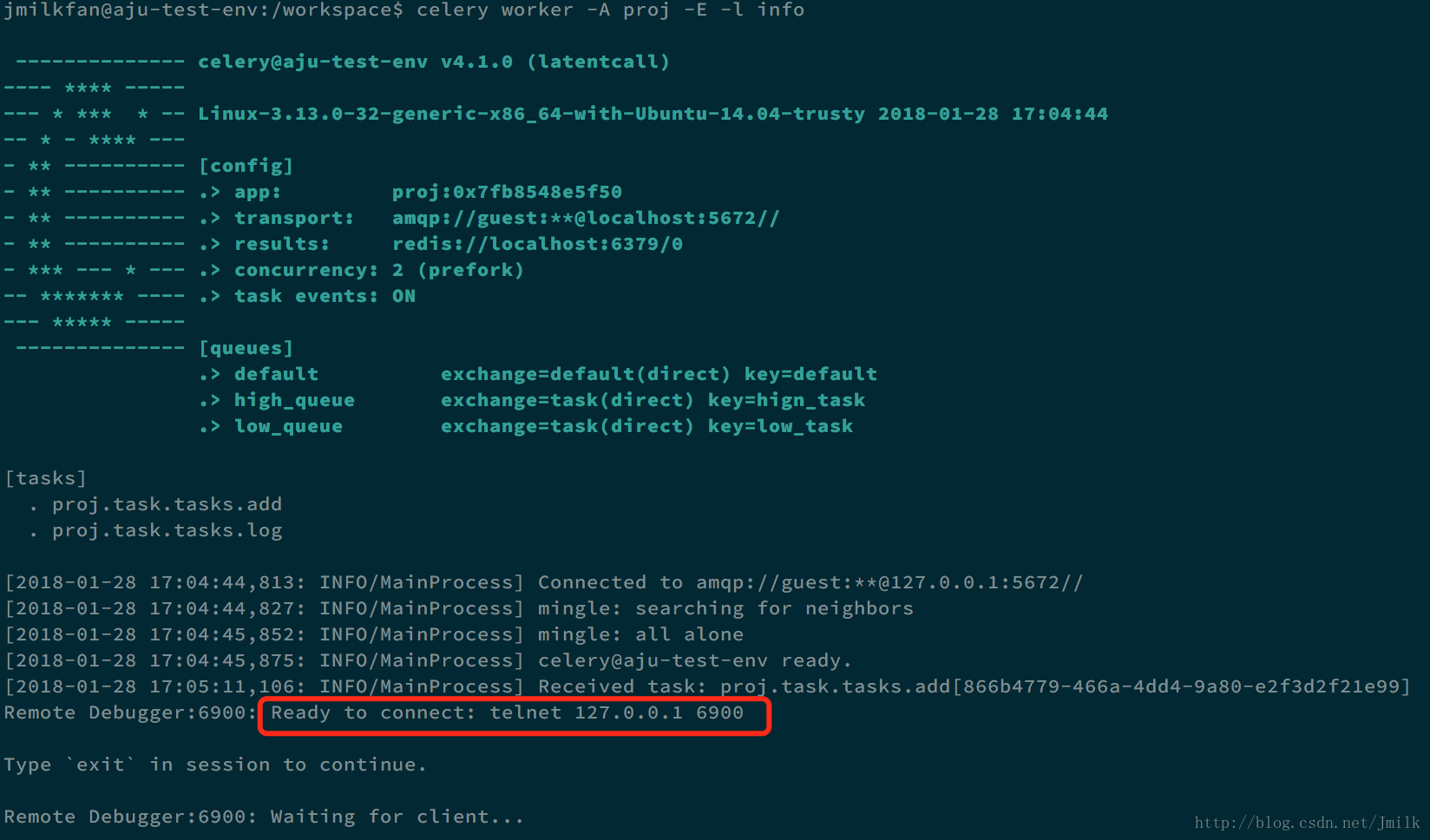
可以看见日志中提示了 telnet 远程连接的地址,所以打开另外一个终端,执行 telnet 指令即可完成连接,进入到非常熟悉的 pdb shell。
分布式任务队列 Celery —— 应用基础的更多相关文章
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
- 分布式任务队列 Celery —— 深入 Task
目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继承 前文列表 分布式任务队列 Celery 分布式任务队列 Celery -- 详解工作流 ...
- 分布式任务队列 Celery
目录 目录 前言 简介 Celery 的应用场景 架构组成 Celery 应用基础 前言 分布式任务队列 Celery,Python 开发者必备技能,结合之前的 RabbitMQ 系列,深入梳理一下 ...
- [源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 分布式任务队列 Celery 之启动 Consumer 目录 [源码解析] 分布式任务队列 Celery 之启动 Consumer 0x00 摘要 0x01 综述 1.1 kombu.c ...
- [源码解析] 并行分布式任务队列 Celery 之 Task是什么
[源码解析] 并行分布式任务队列 Celery 之 Task是什么 目录 [源码解析] 并行分布式任务队列 Celery 之 Task是什么 0x00 摘要 0x01 思考出发点 0x02 示例代码 ...
- [源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat
[源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat 目录 [源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat 0 ...
- 分布式任务队列 Celery —— 详解工作流
目录 目录 前文列表 前言 任务签名 signature 偏函数 回调函数 Celery 工作流 group 任务组 chain 任务链 chord 复合任务 chunks 任务块 mapstarma ...
- [源码解析] 并行分布式任务队列 Celery 之 消费动态流程
[源码解析] 并行分布式任务队列 Celery 之 消费动态流程 目录 [源码解析] 并行分布式任务队列 Celery 之 消费动态流程 0x00 摘要 0x01 来由 0x02 逻辑 in komb ...
- [源码解析] 并行分布式任务队列 Celery 之 多进程模型
[源码解析] 并行分布式任务队列 Celery 之 多进程模型 目录 [源码解析] 并行分布式任务队列 Celery 之 多进程模型 0x00 摘要 0x01 Consumer 组件 Pool boo ...
随机推荐
- tab栏切换效果案例
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- SpringBoot项目中遇到的BUG
1.启动项目的时候报错 1.Error starting ApplicationContext. To display the auto-configuration report re-run you ...
- AndroidStudio Gradle手动下载和安装
操作流程概述: 下载好的压缩包和解压后的文件夹复制到gradle-5.5.1-all --->97z1ksx6lirer3kbvdnh7jtjg文件夹下,将gradle-5.5.1-all.zi ...
- 万兴神剪手 Wondershare Filmora v9.2.11.6 简体中文版
目录 1. 介绍 2. 简体中文9.2.1.10汉化版下载 3. 安装和激活说明 1. 介绍 万兴神剪手 Filmora 是一款界面简洁时尚.功能强大的视频编辑软件,它是深圳万兴科技公司近年来的代表作 ...
- 017-zabbix_proxy分布式监控部署
一.proxy分布式监控介绍 来源于zabbix官网: https://www.zabbix.com/documentation/3.4/zh/manual/distributed_monitorin ...
- zabbix命令之:zabbix_sender命令
zabbix server除了可以从客户端主动获取数据,客户端也可以主动将数据推送给服务端,客户端通过zabbix_sender指令来实现向服务端主动推送数据. 在zabbix客户端安装 配置yum源 ...
- 遗传算法的C语言实现(二)
上一次我们使用遗传算法求解了一个较为复杂的多元非线性函数的极值问题,也基本了解了遗传算法的实现基本步骤.这一次,我再以经典的TSP问题为例,更加深入地说明遗传算法中选择.交叉.变异等核心步骤的实现.而 ...
- puppet运维自动化之用户管理
系统管理员离不开账户管理,账户管理,密码管理,开发机器,测试机器,线上机器,都需要创建用户,并给与相关用户的权限.你如果要创建100个,1000个账户和密码,你会不会疯掉,如何在1分钟完成百上千个账户 ...
- pandas的corsstab
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=F ...
- API网关原理
1.API网关介绍 API网关是一个服务器,是系统的唯一入口.从面向对象设计的角度看,它与外观模式类似.API网关封装了系统内部架构,为每个客户端提供一个定制的API.它可能还具有其它职责,如身份验证 ...