译:2. RabbitMQ Java Client 之 Work Queues (工作队列)
在上篇揭开RabbitMQ的神秘面纱一文中,我们编写了程序来发送和接收来自命名队列的消息。
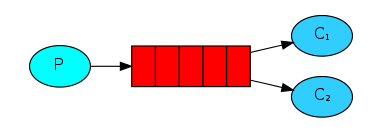
本篇我们将创建一个工作队列,工作队列背后的假设是每个任务都交付给一个工作者
本篇是译文,英文原文请移步:http://www.rabbitmq.com/tutorials/tutorial-two-java.html
前提:本教程假定RabbitMQ 已在标准端口(15672)上的localhost上安装并运行。如果您使用不同的主机,端口或凭据,则需要调整连接设置。
1. Work Queue 工作队列
工作队列(又称:任务队列)背后的主要思想是避免立即执行资源密集型任务,并且必须等待它完成。
相反,我们安排任务稍后完成。我们将任务封装 为消息并将其发送到队列。在后台运行的工作进程将弹出任务并最终执行作业。当您运行许多工作程序时,它们之间将共享任务。
这个概念在Web应用程序中特别有用,因为在短的HTTP请求窗口中无法处理复杂的任务。
如何理解上面这段话呢?
我们可以举个例子,假设用户有多个文件上传请求,然而Web应用对文件上传进行处理往往是一件比较耗时的操作,是无法立刻马上响应返回给客户端结果,这时候我们就需要一个工作队列来处理。
再比如生活中的买票,检票,大家都知道,当我们买票检票,大多需要排队一个一个处理,两者类似。
在上篇中我们发送了一个Hello World 信息,现在我们将发送复杂任务的字符串。
但是我们没有实际的应用场景,所以我们这里暂时使用 Thread.sleep() 函数来模拟PDF 文件上传实现延迟效果。
我们创建一个生产者(产生消息,发送消息的一方)发布新的任务,文件名称叫做NewTask.java:
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.MessageProperties; /***
* 生产者
* ********/
public class NewTask {
private static final String TASK_QUEUE_NAME = "task_queue"; public static void main(String[] argv) throws Exception { //创建和消息队列的连接
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel(); //第二个参数为true 确保关闭RabbitMQ服务器时执行持久化
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null); //从命令行发送任意消息
String message = getMessage(argv); //将消息标记为持久性 - 通过将MessageProperties(实现BasicProperties)设置为值PERSISTENT_TEXT_PLAIN。
channel.basicPublish("",
TASK_QUEUE_NAME,//指定消息队列的名称
MessageProperties.PERSISTENT_TEXT_PLAIN,//指定消息持久化
message.getBytes("UTF-8"));//指定消息的字符编码
//打印生产者发送成功的消息
System.out.println(" [x] Sent '" + message + "'"); //关闭资源
channel.close();
connection.close();
} /***
* 一些帮助从命令行参数获取消息
* @param strings 从命令行发送任意消息字符串
* */
private static String getMessage(String[] strings) {
if (strings.length < 1)
return "Hello World!";
return joinStrings(strings," ");
} /**
* 字符串数组
* @param delimiter 分隔符
* */
private static String joinStrings(String[] strings, String delimiter) {
int length = strings.length;
if (length == 0) return "";
StringBuilder words = new StringBuilder(strings[0]);
for (int i = 1; i < length; i++) {
words.append(delimiter).append(strings[i]);
}
return words.toString();
}
}
接下来我们创建我们的消费者(工作者),它需要为消息体中的每个点伪造一秒钟的工作。它将处理传递的消息并执行任务。
Worker.java
import java.io.IOException; import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Consumer;
import com.rabbitmq.client.DefaultConsumer;
import com.rabbitmq.client.Envelope; public class Worker { private static final String TASK_QUEUE_NAME = "task_queue"; public static void main(String[] argv) throws Exception { //和消息队列创建连接
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel(); //指定消息队列的名称
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C"); //在处理并确认前一个消息之前,不要向工作人员发送新消息。相反,它会将它发送给下一个仍然不忙的工人
int prefetchCount = 1 ;
channel.basicQos(prefetchCount);
//channel.basicQos(1); final Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String message = new String(body, "UTF-8"); System.out.println(" [x] Received '" + message + "'");
try {
doWork(message);
} finally {
System.out.println(" [x] Done");
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
};
//boolean autoAck = false;
//channel.basicConsume(TASK_QUEUE_NAME, autoAck, consumer);
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
} /*****
* 我们的假任务是模拟执行时间
* */
private static void doWork(String task) {
for (char ch : task.toCharArray()) {
if (ch == '.') {
try {
Thread.sleep(1000);
} catch (InterruptedException _ignored) {
Thread.currentThread().interrupt();
}
}
}
}
}
2. RabbitMQ 之循环调度
使用任务队列的一个优点是能够轻松地并行工作。如果我们正在积压工作积压,我们可以添加更多工作者,这样就可以轻松扩展。
首先,让我们尝试同时让两个工作者工作。他们都会从队列中获取消息,但究竟如何呢?让我们来看看。
我们选中Worker.java 右键,Run as -----> Java Application ,执行三次,启动三个实例。
这样一来就相当于有了三个工作者(消费者),
然后我们同理开始尝试多次运行生产者,NewTask.java,这样将产生多个任务

然后我们可以清楚在控制台看到这样的情况,
第一个Work.java

第二个Work.java

第三个work.java
Tips: 上面是worker.java 运行了三次,newTask 运行了四次。
也就是说任务有四个,按照循环调度算法,第一个循环到第二个循环,所以有了两个消息,而其他消息有了一个消息。
第一个work.java 的控制台收到了两条消息后继续等待收消息
第二个work.java 的控制台收到了一条消息后也继续等待接受消息
第三个work.java 的控制台也收到了 一条消息后继续等待接受消息
默认情况下,RabbitMQ将按顺序将每条消息发送给下一个消费者。
平均而言,每个消费者将获得相同数量的消息。这种分发消息的方式称为循环法。
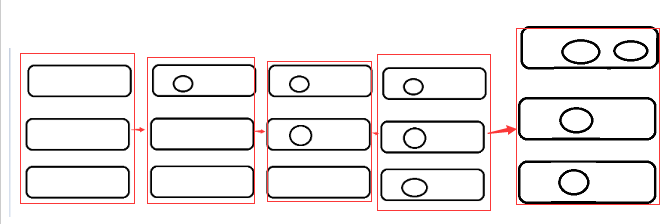
Tips: 一个圆圈待表收到的一个消息,一个矩形代表一个Worker 实例
3. Message acknowledgment 消息确认
虽然执行任务可能需要几秒钟,但是可能我们会好奇想知道如果其中一个消费者开始执行长任务并且仅在部分完成时死亡会发生什么。
使用我们当前的代码,一旦RabbitMQ向客户发送消息,它立即将其标记为删除。
在这种情况下,如果你直接关闭一个worker 实例,我们将丢失它刚刚处理的消息。我们还将丢失分发给这个特定工作者但尚未处理的所有消息。
但我们不想失去任何任务。如果一个worker 工作者实例死亡,我们希望将任务交付给另一名工作者Worker。
为了确保消息永不丢失,RabbitMQ支持 message acknowledgments. (消息确认)。
消费者(工作者)发回一个 ack(nowledgement)告诉RabbitMQ已收到,处理了特定消息,RabbitMQ可以自由删除它。
如果工作者死亡(其通道关闭,连接关闭或TCP连接丢失)而不发送确认,RabbitMQ将理解消息未完全处理并将重新排队。
如果其他消费者同时在线,则会迅速将其重新发送给其他消费者。这样你就可以确保没有消息丢失,即使Worker偶尔会死亡。
没有任何消息超时; 当消费者死亡时,RabbitMQ将重新发送消息。即使处理消息需要非常长的时间,也没关系。
默认情况下, Manual message acknowledgments 手动消息已打开。
在前面的示例中,第二个参数我们通过autoAck = true 标志明确地将它们关闭。
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
Tips: true 即autoAck 的值
一旦我们完成任务,第二个参数就应该将此标志设置为false并从工作人员发送适当的确认。
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
使用此代码,我们可以确定即使您在处理消息时使用CTRL + C杀死一名Worker 实例,也不会丢失任何内容。
因为Worker死后不久,所有未经确认的消息将被重新传递。
确认必须在收到的交付的同一信道上发送。尝试使用不同的通道进行确认将导致通道级协议异常. 详情看 doc guide on confirmations 了解更多。
Forgotten acknowledgment 被遗忘的通知
错过basicAck是一个常见的错误。这是一个简单的错误,但后果是严重的。(也就是这句话如果忘了写,后果很严重,该消息将一直发送不出去)
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
当您的客户端退出时,消息将被重新传递(这可能看起来像随机重新传递),但RabbitMQ将会占用越来越多的内存,因为它无法释放任何未经处理的消息。
为了调试这种错误,您可以使用rabbitmqctl 来打印messages_unacknowledged字段
Linux 下:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Windows 下:
rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
4.Message durability 消息持久性
我们已经学会了如何确保即使消费者死亡,任务也不会丢失。但是如果RabbitMQ服务器停止,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非你告诉它不要。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久。
首先,我们需要确保RabbitMQ永远不会丢失我们的队列。为此,我们需要声明它是持久的:
boolean durable = true ;
channel.queueDeclare(“hello”,durable,false,false,null);
虽然此命令本身是正确的,但它在我们当前的设置中不起作用。
那是因为我们已经定义了一个名为hello的队列 ,这个队列不耐用。 RabbitMQ不允许您使用不同的参数重新定义现有队列,并将向尝试执行此操作的任何程序返回错误。
但是有一个快速的解决方法 - 让我们声明一个具有不同名称的队列,例如task_queue:
boolean durable = true ;
channel.queueDeclare(“task_queue”,durable,false,false,null);
此queueDeclare更改需要应用于生产者和消费者代码。
此时我们确信即使RabbitMQ重新启动,task_queue队列也不会丢失。
现在我们需要将消息标记为持久性 - 通过将MessageProperties(实现BasicProperties)设置为值PERSISTENT_TEXT_PLAIN。
Note on message persistence
将消息标记为持久性并不能完全保证消息不会丢失。虽然它告诉RabbitMQ将消息保存到磁盘,但是当RabbitMQ接受消息并且尚未保存消息时,仍然有一个短时间窗口。此外,RabbitMQ不会为每条消息执行fsync(2) - 它可能只是保存到缓存而不是真正写入磁盘。持久性保证不强,但对于我们简单的任务队列来说已经足够了。如果您需要更强的保证,那么您可以使用 发布者确认。
5. Fair dispatch 公平派遣
您可能已经注意到调度仍然无法完全按照我们的意愿运行。
例如,在有两个工人的情况下,当所有奇怪的消息都很重,甚至消息很轻时,一个工人将经常忙碌而另一个工作人员几乎不会做任何工作。
好吧,RabbitMQ对此一无所知,仍然会均匀地发送消息。
发生这种情况是因为RabbitMQ只是在消息进入队列时调度消息。
它不会查看消费者未确认消息的数量。它只是盲目地向第n个消费者发送每个第n个消息。

为了打败我们可以使用basicQos方法和 prefetchCount = 1设置。这告诉RabbitMQ不要一次向一个worker发送一条消息。或者,换句话说,在处理并确认前一个消息之前,不要向工作人员发送新消息。相反,它会将它发送给下一个仍然不忙的工人。
int prefetchCount = 1 ;
channel.basicQos(prefetchCount);
关于队列大小的说明
如果所有工作人员都很忙,您的队列就会填满。您将需要密切关注这一点,并可能添加更多工作人员,或者采取其他策略。
使用消息确认和prefetchCount,您可以设置工作队列。即使RabbitMQ重新启动,持久性选项也可以使任务生效。
本篇完~
译:2. RabbitMQ Java Client 之 Work Queues (工作队列)的更多相关文章
- 译:1. RabbitMQ Java Client 之 "Hello World"
这些教程介绍了使用RabbitMQ创建消息传递应用程序的基础知识.您需要安装RabbitMQ服务器才能完成教程 1. 打造第一个Hello World 程序 RabbitMQ是一个消息代理:它接受和转 ...
- 译:6.RabbitMQ Java Client 之 Remote procedure call (RPC,远程过程调用)
在 译:2. RabbitMQ 之Work Queues (工作队列) 我们学习了如何使用工作队列在多个工作人员之间分配耗时的任务. 但是如果我们需要在远程计算机上运行一个函数并等待结果呢?嗯,这 ...
- 译:3.RabbitMQ Java Client 之 Publish/Subscribe(发布和订阅)
在上篇 RabbitMQ 之Work Queues (工作队列)教程中,我们创建了一个工作队列,工作队列背后的假设是每个任务都交付给一个工作者. 在这一部分,我们将做一些完全不同的事情 - 我们将向多 ...
- 译:4.RabbitMQ Java Client 之 Routing(路由)
在上篇博文 译:3.RabbitMQ 之Publish/Subscribe(发布和订阅) 我们构建了一个简单的日志系统 我们能够向许多接收者广播日志消息. 在本篇博文中,我们将为其添加一个功能 - ...
- 译:5.RabbitMQ Java Client 之 Topics (主题)
在 上篇博文 译:4.RabbitMQ 之Routing(路由) 中,我们改进了日志系统. 我们使用的是direct(直接交换),而不是使用只能进行虚拟广播的 fanout(扇出交换) ,并且有可能选 ...
- 五、RabbitMQ Java Client基本使用详解
Java Client的5.x版本系列需要JDK 8,用于编译和运行.在Android上,仅支持Android 7.0或更高版本.4.x版本系列支持7.0之前的JDK 6和Android版本. 加入R ...
- 译: 2. RabbitMQ Spring AMQP 之 Work Queues
在上一篇博文中,我们写了程序来发送和接受消息从一个队列中. 在这篇博文中我们将创建一个工作队列,用于在多个工作人员之间分配耗时的任务. Work Queues 工作队列(又称:任务队列)背后的主要思想 ...
- rabbitmq - java client lib一二事
由于不可抗因素, 需要给对接方撸一个client的demo.基于比较老的jdk. 所幸找到了这里:http://www.rabbitmq.com/releases/rabbitmq-java-clie ...
- RabbitMQ的使用(五)RabbitMQ Java Client简单生产者、消费者代码示例
pom文件: <dependencies> <dependency> <groupId>com.rabbitmq</groupId> <artif ...
随机推荐
- 51Nod 算法马拉松28 C题 栈 单调队列
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - 51Nod1952 题意概括 有一个栈,有3种操作: Ο 从栈顶加入一个元素 Ο 从栈底加入一个元素 Ο 从栈 ...
- C# 组件模组引用第三方组件问题
对接上一文章由于是动态加载指定程序集,会把当前目录下所有dll都加载进来.如果像sqlite这种第三组件调用了由C.C++非.net语言所以生成的Dll.因为自动生成的原因.会把非C#生成的dll都加 ...
- (python数据分析)第03章 Python的数据结构、函数和文件
本章讨论Python的内置功能,这些功能本书会用到很多.虽然扩展库,比如pandas和Numpy,使处理大数据集很方便,但它们是和Python的内置数据处理工具一同使用的. 我们会从Python最基础 ...
- Python学习——迭代器&生成器&装饰器
一.迭代器 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素.迭代器仅 ...
- BZOJ.2879.[NOI2012]美食节(费用流SPFA)
题目链接 /* 同"修车":对于每个厨师拆成p个点表示p个时间点,每个人向m个厨师每个时间点连边 这样边数O(nmp)+网络流 ≈O(nm*p^2)(假设SPFA线性) = GG ...
- 潭州课堂25班:Ph201805201 WEB 之 JS 第五课 (课堂笔记)
算数运算符 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- Flask启动原理,源码流程分析
1.执行Flask的实例对象.run()方法 from flask import Flask,request,session app = Flask(__name__) app.secret_key ...
- Redis的使用(待更新)
import redis #redis的使用 """ { "k1":"v1", 'names': ['把几个','鲁宁','把几个 ...
- 喵哈哈村的魔法考试 Round #14 (Div.2) 题解
喵哈哈村的四月半活动(一) 题解: 唯一的case,就是两边长度一样的时候,第三边只有一种情况. #include <iostream> #include <cstdio> # ...
- xtrabackup备份MySQL并主从同步
为什么要使用xtarbackup? mysqldump备份数据库的时候,会锁库锁表,导致业务服务的暂时停滞,数据库数量小还没有感觉,当数据超过几个G的时候,使用mysqldump会严重影响服务器性能, ...