【基础】字符编码-ASCII、Unicode、utf-8
一、各自背景
1. ASCII
ASCII 只有127个字符,表示英文字母的大小写、数字和一些符号。但由于其他语言用ASCII编码表示字节不够,例如:常用中文需要两个字节,且不能和ASCII冲突,中国定制了GB2312编码格式,相同的,其他国家的语言也有属于自己的编码格式。这导致了在多语言混合的文本中,显示出来会有乱码。
2. Unicode
由于每个国家的语言都有属于自己的编码格式,在多语言编辑文本中会出现乱码,这样Unicode应运而生,Unicode就是将这些语言统一到一套编码格式中。Unicode通常两个字节表示一个字符,而ASCII是一个字节表示一个字符,这样如果你编译的文本是全英文的,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
3. Utf-8
为了解决上述问题,又出现了把Unicode编码转化为“可变长编码”UTF-8编码,UTF-8编码将Unicode字符按数字大小编码为1-6个字节,英文字母被编码成一个字节,常用汉字被编码成三个字节,如果你编译的文本是纯英文的,那么用UTF-8就会非常节省空间,并且ASCII码也是UTF-8的一部分。
二、三者关系
搞清楚了ASCII、Unicode和UTF-8的背景,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
(1) 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
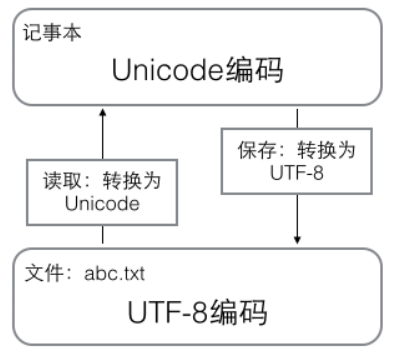
(2) 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
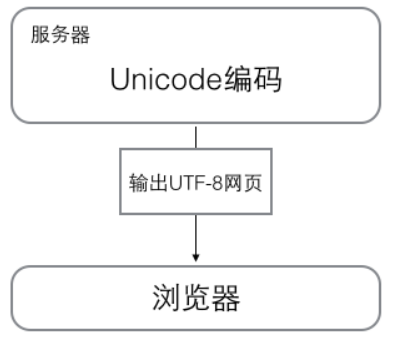
(3)浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
三、总结
utf-8变长编码意味着要判定长度时需要计算,在编辑时用会耗费额外的计算成本,为了提高运行速度可以使用Unicode。而存储为了节省空间,使用utf-8. 也就是说编辑时用Unicode减少判定时间,保存时用utf-8节省存储空间。
【基础】字符编码-ASCII、Unicode、utf-8的更多相关文章
- 字符编码 ASCII,Unicode和UTF-8的关系
转自:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143166410626 ...
- 字符编码 ASCII unicode UTF-8
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(b ...
- 彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, Utf-8
彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, U 1.ASCII: 0-127(128-255未使用),美国标准 2.IS0-8859-1(lati ...
- Python基础-字符编码与转码
***了解计算机的底层原理*** Python全栈开发之Python基础-字符编码与转码 需知: 1.在python2默认编码是ASCII, python3里默认是utf-8 2.unicode 分为 ...
- python基础-----字符编码
1.ASCII ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现 ...
- 字符编码ASCII、Unicode、GB
计算机的存储都是二进制的,那么我们平时看到的各种字符都需要通过按照一定的格式转换成为二进制才能在被计算机识别与处理.这个过程便成为编码.常见的编码方式有ASCII.Unicode.GB2312等. 1 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码 ASCII,Unicode 和 UTF-8 概念扫盲
今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步搞清楚. 下面就是我的笔记,主要用来整理自己的思 ...
- 字符编码 ASCII、Unicode和UTF-8的关系
摘抄自廖雪峰 教程 字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机 ...
随机推荐
- Android中的Coroutine协程原理详解
前言 协程是一个并发方案.也是一种思想. 传统意义上的协程是单线程的,面对io密集型任务他的内存消耗更少,进而效率高.但是面对计算密集型的任务不如多线程并行运算效率高. 不同的语言对于协程都有不同的实 ...
- Redisson 加锁原理
一.分布式加锁过程 RLock lock = redissonClient.getLock(REDISSON_DISTRIBUTE_KEY); lock.lock(); wireshark抓包可以看见 ...
- myisamchk 是用来做什么的?
它用来压缩 MyISAM 表,这减少了磁盘或内存使用. MyISAM Static 和 MyISAM Dynamic 有什么区别? 在 MyISAM Static 上的所有字段有固定宽度.动态 MyI ...
- maven-something
<!--dependencyManagement提供一种管理依赖版本好的方式--> <!-- 通常出现在项目的最顶层父POM,--> <!-- 可以让所有在子项目中引用的 ...
- 面试问题之C++语言:面向对象的三大特性
转载于:https://www.cnblogs.com/BEN-LK/p/10720249.html 面向对象的三大特性:封装.继承.多态 封装:就是把客观事物封装成抽象的类,并且类可以把自己的数据和 ...
- kafka consumer代码梳理
kafka consumer是一个单纯的单线程程序,因此相对于producer会更好理解些.阅读consumer代码的关键是理解回调,因为consumer中使用了大量的回调函数.参看kafka中的回调 ...
- jenkins-learning
常规的打包方式: 提交代码 拉去代码并打包:war包和jar包 上传到服务器 关闭当前程序 启动新的jar包 查看新的jar包是否起作用 jenkins自动化流程: CI(Continuous int ...
- tcp粘包问题原因及解决办法
1.粘包概念及产生原因 1.1粘包概念: TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾. 粘包可能由发送方造成,也可能由接收方造成. ...
- nginx静态资源服务器配置
编辑 nginx.conf server { listen 80; server_name file.youxiu326.xin; location /image/ { #访问 file.youxiu ...
- SVG中的坐标系统和坐标变换
视野和世界 2D绘图中很多人会有一个误区,就是我绘图的区域是一个矩形区域.无论新建一个画布还是创建了一个容器,心里都想象里面有一个矩形区域.其实,在SVG当中,矩形区域只是视野,是我们看到的部分.实际 ...