day38--MySQL基础二
1、数据库连表
1.1, 一对多
使用外键做约束。注意:外键列的数据类型要一致。
命令的方式创建外键
CREATE table part1(
nid int not null auto_increment primary key,
caption VARCHAR(32) not null
)
CREATE TABLE person1(
nid int not null auto_increment,
name VARCHAR(32) not null,
email VARCHAR(32) not null,
part1_nid INT not null,
primary key (nid), -- 可用来创建联合主键
CONSTRAINT `fk_person1_part1` FOREIGN KEY (part1_nid) REFERENCES part1(nid)
)
连表操作:
#找到所有CEO部门的所有人员
SELECT person.`name`,part.caption from person LEFT JOIN part ON person.part_nid = part.nid WHERE part.caption = 'CEO'
a left join b on a.xx = b.xxx
#以A为主,将A中所有的数据都罗列出来,b表显示a表相关的数据
a right join b on a.xx = b.xxx
#以b为主,将b中所有的数据都罗列出来,A表显示b表相关的数据
a inner join b on a.xx = b.xxx
#自动忽略未建立连接的数据
eg:
SELECT
person.nid as pidl,
person.name as pname,
part.caption as cp,
color.title as title
FROM
person
LEFT JOIN part ON person.part_nid = part.nid
LEFT JOIN color on person.color_nid = color.nid
WHERE
part.caption = 'CEO' and color.title = 'red'
可以将 part、color 称之为字典表
**多对多
需要有第三张表来做关联
eg:
SELECT * from relation
left JOIN t_nan on relation.nan_nid = t_nan.nid
LEFT JOIN t_nv on relation.nv_nid = t_nv.nid
WHERE t_nan.`name` = 'alex'
2、SQL注入
发生场景
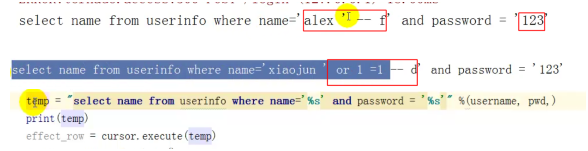
以上情况都会发生脚本执行的情况。
3、视图
虚拟表,
是一个虚拟表,通过对真实表的查询处理得到的一张临时虚拟表
创建视图:
CREATE VIEW v1 AS
SELECT relation.nid,t_nan.`name` as nan,t_nv.`name` as nv FROM relation
LEFT JOIN t_nan on relation.nan_nid = t_nan.nid
LEFT JOIN t_nv on relation.nv_nid = t_nv.nid
WHERE t_nan.`name` = 'alex'
or
CREATE VIEW v1 as SELECT 1
修改视图:
ALTER VIEW v1 as
SELECT * from person WHERE nid >5
删除视图:
drop VIEW v1;
5、存储过程
类似于函数,将逻辑存储在数据中
创建最简单的存储过程
DROP PROCEDURE if EXISTS proc_p1;
CREATE PROCEDURE proc_p1()
BEGIN
SELECT * from t_nan;
END
调用存储过程:
CALL proc_p1()
删除存储过程
drop PROCEDURE proc_p1;
示例:
delimiter $$
drop PROCEDURE if EXISTS proc_p1 $$
CREATE PROCEDURE proc_p1(
in i1 int,
out i2 INT
)
BEGIN
DECLARE d2 int DEFAULT 3;
if i1 = 1 THEN
set i2 = 100 + d2;
ELSEIF i2 = 2 THEN
set i2 = 200 + d2;
else
set i2 = 1000 + d2;
end IF;
end $$
delimiter ;
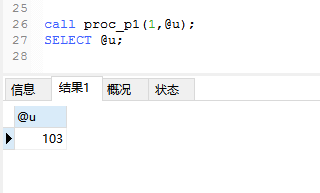
eg2:
delimiter $$
drop PROCEDURE if EXISTS proc_p1 $$
CREATE PROCEDURE proc_p1(
in i1 int,
INOUT ii INT,
out i2 INT
)
BEGIN
DECLARE d2 int DEFAULT 3;
set ii = ii + 1;
if i1 = 1 THEN
set i2 = 100 + d2;
ELSEIF i2 = 2 THEN
set i2 = 200 + d2;
else
set i2 = 1000 + d2;
end IF;
end $$
delimiter ;
4、
使用pysql调用存储过程
#!/usr/bin/envpython
#-*-coding:utf-8-*-
importpymysql
conn=pymysql.connect(host='10.10.8.12',port=3306,user='sysadmin',passwd='password01!',db='q2')
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)
#执行存储过程
row=cursor.callproc('proc_p1',(1,2,3))
#打印存储过程得查询结果
print(cursor.fetchall())
#获取存储过程的值
effect_row=cursor.execute("select@_proc_p1_0,@_proc_p1_1,@_proc_p1_2")
#取存储过程得返回值
result=cursor.fetchone()
print(result)
conn.commit()
cursor.close()
conn.close()
5、存储过程查询结果的传递

6、触发器
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为
# 插入前
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 插入后
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 删除前
CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 删除后
CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新前
CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新后
CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END
delimiter //
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN IF NEW. NAME == 'alex' THEN
INSERT INTO tb2 (NAME)
VALUES
('aa')
END
END//
delimiter ;
eg2:
delimiter //
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
IF NEW. num = 666 THEN
INSERT INTO tb2 (NAME)
VALUES
(''),
('') ;
ELSEIF NEW. num = 555 THEN
INSERT INTO tb2 (NAME)
VALUES
(''),
('') ;
END IF;
END//
delimiter ;
删除:
DROP TRIGGER tri_after_insert_tb1;
触发:
insert into tb1(num) values(666)
demo
触发器有个特殊的值 old 、new
delimiter $$
drop TRIGGER if EXISTS tri_before_insert_color $$
CREATE TRIGGER tri_before_insert_color BEFORE INSERT on color for EACH ROW
BEGIN
INSERT INTO t_nan(name) VALUES(new.title);
END $$
delimiter ;
new可用来 获取插入的值
当做删除的数据时用old来获取
7、函数:
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。 LOWER(str)
变小写 UPPER(str)
变大写 LTRIM(str)
返回字符串 str ,其引导空格字符被删除。
RTRIM(str)
返回字符串 str ,结尾空格字符被删去。
SUBSTRING(str,pos,len)
获取字符串子序列 LOCATE(substr,str,pos)
获取子序列索引位置 REPEAT(str,count)
返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。
若 count <= 0,则返回一个空字符串。
若str 或 count 为 NULL,则返回 NULL 。
REPLACE(str,from_str,to_str)
返回字符串str 以及所有被字符串to_str替代的字符串from_str 。
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
RIGHT(str,len)
从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N)
返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str)
返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar ');
-> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx' 部分内置函数
常用函数
函数用select执行,内部没有结果集
8、事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。

pymysql 默认就是事务性得,只有所有得cursonr.execute 都执行成功后才会提交数据库
9、条件语句、循环预计
10、动态执行sql语句
写一个存储过程,将sql语句(带占位符)提交给存储过程
delimiter \\
DROP PROCEDURE IF EXISTS proc_sql \\
CREATE PROCEDURE proc_sql ()
BEGIN
declare p1 int;
set p1 = 11;
set @p1 = p1;
PREPARE prod FROM 'select * from person where nid > ?';
EXECUTE prod USING @p1;
DEALLOCATE prepare prod;
END\\
delimiter ;
CALL proc_sql();
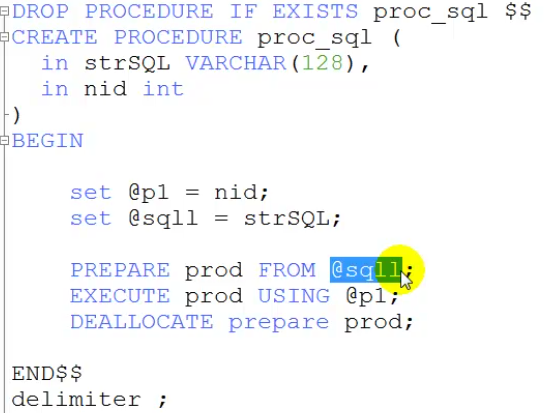
delimiter \\
DROP PROCEDURE IF EXISTS proc_sql \\
CREATE PROCEDURE proc_sql (
in strSQL VARCHAR(128),
in nid int
)
BEGIN
set @sqll = strSQL ;
set @p1 = nid;
PREPARE prod FROM @sqll;
EXECUTE prod USING @p1;
DEALLOCATE prepare prod;
END\\
delimiter ;
call proc_sql('select * from person where nid > ?',11) -- 实际测试发现不能防止注入
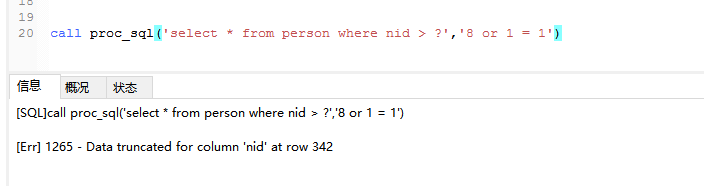

day38--MySQL基础二的更多相关文章
- 02 mysql 基础二 (进阶)
mysql 基础二 阶段一 表约束 1.not null 非空约束 例子: create table tb1( id int, name varchar(20) not null ); 注意 空字符不 ...
- MySQL基础二
视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,并可以将其当作表来使用. SELECT * FROM ( SEL ...
- Mysql基础(二)
多表连接 #多表查询 /* sql99标准 等值连接 ①多表等值连接的结果为多表的交集部分 ② n个连接至少需要 n-1个连接 ③一般需要为表起别名 ④可以搭配前面介绍的所有子句的使用,比如排序,分组 ...
- MySQL 基础二 创建表格
1.界面创建 2.SQL创建 教程地址:http://blog.csdn.net/brucexia/article/details/53738596 提供学习视频下载 链接:http://pan.ba ...
- MySQL基础(二)——DDL语句
MySQL基础(二)--DDL语句 1.什么是DDL语句,以及DDL语句的作用 DDL语句时操作数据库对象的语句,这些操作包括create.drop.alter(创建.删除.修改)数据库对象. 2.基 ...
- { MySQL基础数据类型}一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型
MySQL基础数据类型 阅读目录 一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型 一 介绍 存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己 ...
- MySQL基础操作(二)
MySQL基础操作 一.视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,并可以将其当作表来使用.注意:使用视图时 ...
- MYSQL基础笔记(二)-SQL基本操作
SQL基本操作 基本操作:CRUD,增删改查 将SQL的基本操作根据操作对象进行分类: 1.库操作 2.表操作 3.数据操作 库操作: 对数据库的增删改查 新增数据库: 基本语法: Create da ...
- mysql基础知识语法汇总整理(二)
mysql基础知识语法汇总整理(一) insert /*insert*/ insert into 表名(字段列表) values(值列表); --蠕虫复制 (优点:快速复制数据,测试服务器压力) in ...
- MySQL基础知识
一.MySQL安装 MySQL的下载 http://dev.mysql.com/downloads/mysql/ MySQL版本选择 MySQL功能自定义选择安装 1.功能自定义选择 2.路径自定义选 ...
随机推荐
- testNG测试基础一
1.TestNG概念 TestNG:Testing Next Generation 下一代测试技术,是一套根据JUnit和Nunit思想构建的利用注释来强化测试功能的测试框架,可用来做单元测试,也可用 ...
- pm2部署node应用
背景: 很早就知道了pm2的强大功能,部署,多进程部署,负载均衡等等,但是一直没有取尝试使用,每次写完代码就没关心部署的事了.最近有空就想着把pm2的部署流程走一遍,顺便整理出来. 环境: 1.本地: ...
- repair table
mysql> show create table lixl;+-------+---------------------------------------------------------- ...
- Python对Excel操作详解
Python对Excel操作详解 文档摘要: 本文档主要介绍如何通过python对office excel进行读写操作,使用了xlrd.xlwt和xlutils模块.另外还演示了如何通过Tcl ...
- ffmeg过滤器介绍[转]
在ffmpeg中,进行反交错需要用到avfilter,即图像过滤器,ffmpeg中有很多过滤器,很强大,反交错的过滤器是yadif. 基本的过滤器使用流程是: 解码后的画面--->buffer过 ...
- SAP云平台CloudFoundry中的用户自定义变量
CloudFoundry应用的manifest.xml里的env区域,允许用户自定义变量,如下图5个变量所示. 使用cf push部署到CloudFoundry之后,在SAP Cloud Platfo ...
- POJ-3565 Ants---KM算法+slack优化
题目链接: https://vjudge.net/problem/POJ-3565 题目大意: 在坐标系中有N只蚂蚁,N棵苹果树,给你蚂蚁和苹果树的坐标.让每只蚂蚁去一棵苹果树, 一棵苹果树对应一只蚂 ...
- Android(java)学习笔记75:ListViewProject案例(ListView + BaseAdapter + CheckBox)
这个案例可能稍微复杂一点,我会讲述详细一点: 1. 首先是AndroidManifest.xml: <?xml version="1.0" encoding="ut ...
- python request下载文件时,显示进度以及网速
import requests import time def downloadFile(name, url): headers = {'Proxy-Connection':'keep-alive'} ...
- Oracle 分区表的索引、分区索引
对于分区表,可以建立不分区索引.也就是说表分区,但是索引不分区.以下着重介绍分区表的分区索引. 索引与表一样,也可以分区.索引分为两类:locally partition index(局部分区索引). ...