[DE] ML on Big data: MLlib
Pipeline的最终目的就是学会Spark MLlib,这里先瞧瞧做到心里有数:知道之后要学什么,怎么学。
首要问题
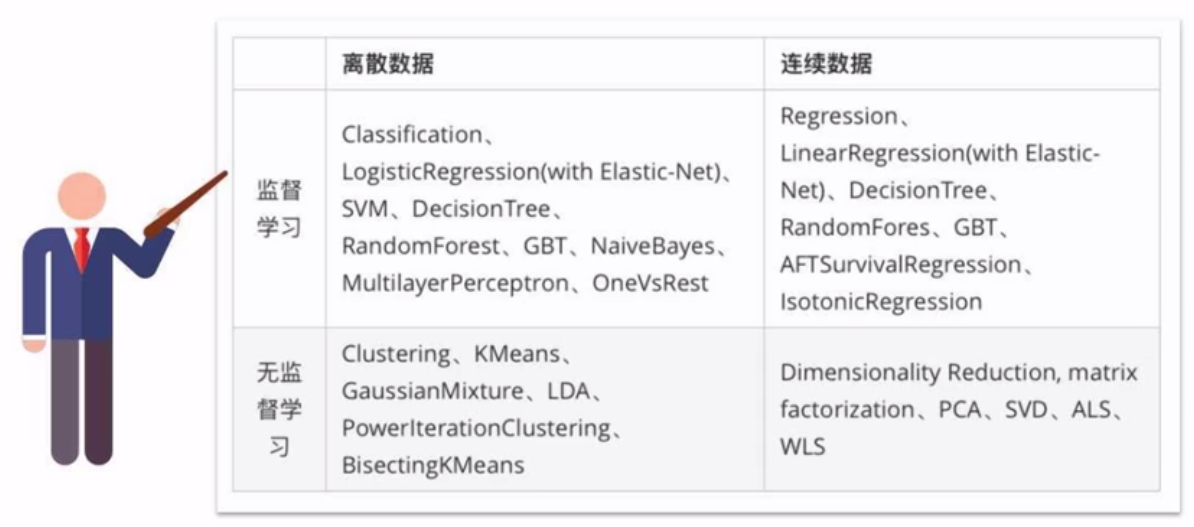
一、哪些机器学习算法可以并行实现?
四类算法:分类、回归、聚类、协同过滤
以及特征提取、降维、数据流管理功能。
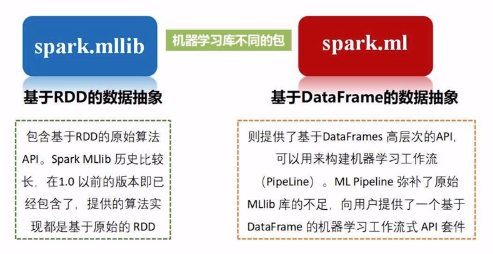
后者可以与Spark SQL完美结合,支持的算法如下:
二、何为机器学习流水线?
Spark SQL中的DataFrame作为数据集。
Transformer: 打上标签。
Estimator: 训练数据的算法。
parameter: 参数。
最后,通过接口将各个Transformer组装起来构成”数据流“。
>>> pipeline = Pipeline(stags=[stage1,stage2,stage3])
构建文本分类流水线
构建评估器
Tokenizer ----> HashingTF ----> Logistic Regression
参考:[ML] Naive Bayes for Text Classification
tokenizer = Tokenizer(inputCol = "text", outputCol = "words")
hashingTF = HashingTF(inputCol = tokenizer.getOutputCol(), outputCol = "feature")
lr = LogisticRegression(maxIter = 10, regParam = 0.001) # 得到一个评估器
pipeline = Pipeline(stages = [tokenizer, hashingTF, lr])
训练转换器
model = pipeline.fit(training)
测试模型
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"]) # 测试过程
prediction = moel.transform(test) # 展示测试结果
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print(...)
MLlib的算法教程
一、大数据文件加载
文件格式解析
part-00178-88b459d7-0c3a-4b84-bb5c-dd099c0494f2.c000.snappy.parquet
加载文件
1. 连接spark
2. 创建dataframe
2.1. 从变量创建
2.2. 从变量创建
2.3. 读取json
2.4. 读取csv
2.5. 读取MySQL
2.6. 从pandas.dataframe创建
2.7. 从列式存储的parquet读取
2.8. 从hive读取
3. 保存数据
3.1. 写到csv
3.2. 保存到parquet
3.3. 写到hive
3.4. 写到hdfs
3.5. 写到mysql
注意,这里的 “users.parquet” 是个文件夹!
# 读取example下面的parquet文件
file = r"D:\apps\spark-2.2.0-bin-hadoop2.7\examples\src\main\resources\users.parquet"
df = spark.read.parquet(file)
df.show()
查询数据
Spark2.1.0+入门:读写Parquet(DataFrame)(Python版)
>>> parquetFileDF = spark.read.parquet("file:///usr/local/spark/examples/src/main/resources/users.parquet"
>>> parquetFileDF.createOrReplaceTempView("parquetFile")
>>> namesDF = spark.sql("SELECT * FROM parquetFile")
>>> namesDF.rdd.foreach(lambda person: print(person.name))
Alyssa
Ben
二、AWS S3 文件处理
大文件一般都放在S3中,如何在本地远程处理呢?
其实AWS已经提供了方案:Amazon EMR
三、MLlib算法学习
Welcome to Spark Python API Docs!
Spark MLlib是Spark中专门用于处理机器学习任务的库,但在最新的Spark 2.0中,大部分机器学习相关的任务已经转移到Spark ML包中。
两者的区别在于MLlib是基于RDD源数据的,而ML是基于DataFrame的更抽象的概念,可以创建包含从数据清洗到特征工程再到模型训练等一系列机器学习工作。
所以,未来在用Spark处理机器学习任务时,将以Spark ML为主。
End.
[DE] ML on Big data: MLlib的更多相关文章
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- [AWS] 01 - What is Amazon EMR
[DE] ML on Big data: MLlib 关于 Amazon EMR 发布版本 利用 Amazon EMR 分析大数据 Amazon Athena 是一种交互式查询服务,让您能够轻松使用标 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- Spark的MLlib和ML库的区别
机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.其目标是使实际的机器学习可扩展和容易.在高层次上,它提供了如下工具: ML算法:通用学习算法,如分类,回归,聚类和协同过滤 特 ...
- [ML] LIBSVM Data: Classification, Regression, and Multi-label
数据库下载:LIBSVM Data: Classification, Regression, and Multi-label 一.机器学习模型的参数 模型所需的参数格式,有些为:LabeledPoin ...
- spark:ML和MLlib的区别
ML和MLlib的区别如下: ML是升级版的MLlib,最新的Spark版本优先支持ML. ML支持DataFrame数据结构和Pipelines,而MLlib仅支持RDD数据结构. ML明确区分了分 ...
- [DE] Pipeline for Data Engineering
How to build an ML pipeline for Data Science 垃圾信息分类 Ref:Develop a NLP Model in Python & Deploy I ...
- 【Repost】A Practical Intro to Data Science
Are you a interested in taking a course with us? Learn about our programs or contact us at hello@zip ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
随机推荐
- 小白学Python(7)——利用Requests下载网页图片、视频
安装 Requests 如果安装了Requests就已经可用了,否则要安装 Requests,只要在你的CMD中运行这个简单命令即可: pip install requests requests使用 ...
- 利用QGIS下载地图数据
这段时间做了一些利用地理信息进行定位导航的系列工作,其中很重要的一部分是如何获取到地图数据,比如道路的矢量图.某一区域的栅格图,我用到的主要工具是QGIS.QGIS是一个跨平台的免费应用,其中集成了对 ...
- Python day01 课堂笔记
今天是第一天学习Python课程,主要从计算机基础,Python的历史,环境 ,变量,常量,注释,用户交互,基础数据类型 ,简单的if条件语句和while循环语句这几个来学习,重点的掌握内容是pyth ...
- 高级脚本进阶—使用case的多功能选择性脚本
应用场景: 在应用脚本决解实际的运维问题时,单功能脚本有很多的不同应用环境,如不同的运行环境,不同的系统版本等,这时,就需要对脚本的功能进行选择,一个脚本实现多功能多版本系统的维护,以减少沟通成本,而 ...
- 常见rpm包和yum包命令
1.rpm包 在 安装.升级.卸载服务程序时要考虑到其他程序.库的依赖关系,在进行校验.安装. 卸载.查询.升级等管理软件操作时难度都非常大. RPM 机制则为解决这些问题而设计的.RPM 有点像 W ...
- <lable>标签
最近用各种框架的时候,发现很多平常自己写代码没注意到的标签和用法,在这里记录一下. 其实是很多细节方面需要注意的写法. <label> 定义:为input元素定义标注 label标签不会向 ...
- 从 View 的四个构造方法说起
View 类的四个构造函数 写过自定义 View 的都知道,View 有四个构造函数,一般大家都知道第一个构造方法是简单的在代码中new View 的时候调用的,第二个构造方法使用最广泛,是对应的生成 ...
- 使用jQuery.extend创建一个简单的选项卡插件
选项卡样式如图,请忽略丑陋的样式,样式可以随意更改 主要是基于jquery的extend扩展出的一个简单的选项卡插件,注意:这里封装的类使用的是es6中的class,所以不兼容ie8等低版本浏览器呦! ...
- Python 基础 2-3 列表的反转与排序
引言 列表是按照特定格式排序而成的,有时候这种排序方式我们并不喜欢,我们希望它可以按照我们的方式来进行正序或者倒序排序,或其他的排序方式 反转与排序 比如说我这里有一组列表,里面存放的全部都是数值,但 ...
- (五十三)c#Winform自定义控件-滚动文字
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kwwwvagaa/NetWinformControl 码云:ht ...